【机器学习入门】1.1 绪论:从数据到智能的认知革命
引言:什么是机器学习?
想象一下,当你在邮箱中看到一封邮件时,系统能自动识别出它是垃圾邮件;当你在购物网站浏览商品时,平台能精准推荐你可能感兴趣的物品;当自动驾驶汽车行驶在道路上时,它能识别交通信号灯、行人与其他车辆。这些神奇的功能背后,都离不开一个核心技术 —— 机器学习。
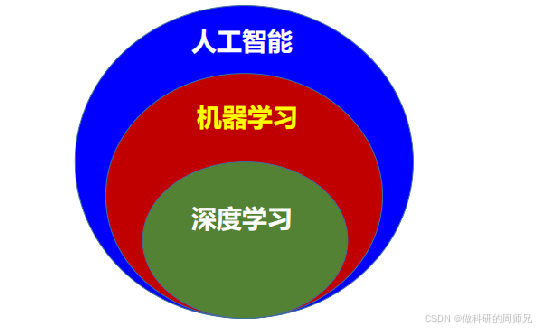
机器学习是人工智能领域的一个重要分支,它使计算机能够从数据中学习规律,无需人类显式编程即可完成特定任务。简单来说,机器学习就是让计算机像人类一样具有学习能力,通过对数据的分析和学习,不断改进自身性能,提高完成任务的准确性。
从学术角度定义,机器学习是研究如何使计算机系统通过经验自动改进性能的学科。这里的 "经验" 指的是计算机系统从数据中提取的信息,而 "改进性能" 则意味着系统在完成某项任务时的表现随着经验的积累而不断提高。
为了更好地理解机器学习,我们可以将其类比为学生学习的过程:数据就像是学生的课本和习题,机器学习算法就像是学生的学习方法,而训练模型的过程则像是学生做习题、巩固知识的过程。最终,经过训练的模型能够像掌握了知识的学生一样,解决从未见过的新问题。
机器学习的发展历程
机器学习的发展经历了一个漫长而曲折的过程,从早期的简单尝试到如今的深度学习热潮,每一步都凝聚着科学家们的智慧和努力。
推理期(20 世纪 50 年代~70 年代初)
这一时期的人工智能研究主要集中在逻辑推理能力上。1950 年,计算机科学之父艾伦・图灵在其著名论文《计算机器与智能》中提出了著名的 "图灵测试",探讨了机器具有智能的可能性,为机器学习的发展埋下了种子。
1956 年,达特茅斯会议正式提出了 "人工智能" 的概念,标志着人工智能作为一个独立学科的诞生。这一时期的研究主要基于符号逻辑,通过编写特定的规则来实现智能行为,而非让机器自主学习。
知识期(20 世纪 70 年代中期开始)
随着对人工智能研究的深入,科学家们意识到仅靠逻辑推理难以实现真正的智能。于是,研究重点转向了让机器能够获取和表示知识。
20 世纪 50 年代中后期,基于神经网络的 "连接主义" 学习开始出现,其中最具代表性的是感知机的提出。感知机是一种简单的神经网络模型,为后来的深度学习奠定了基础。
60-70 年代,基于逻辑表示的 "符号主义" 学习得到发展,如归纳学习系统、概念学习系统等。这些方法试图通过逻辑规则来表示和获取知识。
机器学习成为独立学科(20 世纪 80 年代)
1980 年夏,第一届机器学习研讨会在美国卡耐基梅隆大学举行,同年《策略分析与信息系统》期刊连出三期机器学习专辑。1983 年,《机器学习:一种人工智能途径》一书出版,对当时的机器学习研究进行了系统总结。1986 年,第一本机器学习专业期刊《Machine Learning》创刊。
这一系列事件标志着机器学习正式成为一个独立的学科领域。在这一时期,"从样例中学习" 成为研究的主流,涵盖了我们现在所说的监督学习和无监督学习等。决策树学习和基于逻辑的学习是当时符号主义学习的代表,而 BP 算法的重新发明则推动了连接主义学习的发展。
统计学习时代(20 世纪 90 年代中期~21 世纪初)
20 世纪 90 年代中期,随着统计学习理论的发展,机器学习进入了统计学习时代。其中最具代表性的技术是支持向量机(SVM)以及更一般的 "核方法"。
支持向量机由 Vapnik 等人在 20 世纪 60 年代提出,但直到 90 年代初才出现有效的求解算法,并在 90 年代中期的文本分类应用中展现出优越性能。这一时期,统计学习理论为机器学习提供了坚实的理论基础,使得机器学习算法的设计和分析更加系统化。
深度学习革命(21 世纪初至今)
21 世纪初,随着计算能力的提升和大数据时代的到来,连接主义学习以 "深度学习" 的名义重新崛起,并引发了人工智能领域的新一轮革命。
2012 年,多伦多大学的 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 提出的 AlexNet 深度神经网络在 ImageNet 图像识别竞赛中取得了突破性成绩,大幅降低了图像分类的错误率。AlexNet 的成功得益于卷积神经网络架构的使用和 GPU 计算能力的充分利用。
这一突破标志着深度学习时代的到来,此后,深度学习在计算机视觉、自然语言处理、语音识别等领域取得了一系列突破性进展,推动了人工智能技术的快速发展和广泛应用。
机器学习的核心任务与分类
机器学习的核心任务可以根据学习方式和问题类型进行分类。理解这些任务类型有助于我们选择合适的算法来解决实际问题。
按学习方式分类
1. 监督学习(Supervised Learning)
监督学习是最常见的机器学习任务之一。在监督学习中,训练数据包含输入和对应的期望输出(标签),算法通过学习输入与输出之间的映射关系,来预测新的未见过的数据的输出。
监督学习又可分为分类(Classification)和回归(Regression)任务:
- 分类任务:目标是将输入数据分为有限的几个类别。例如,垃圾邮件识别(垃圾邮件 / 正常邮件)、手写数字识别(0-9)等。
- 回归任务:目标是预测一个连续的数值输出。例如,房价预测、股票价格预测、气温预测等。
2. 无监督学习(Unsupervised Learning)
无监督学习与监督学习的主要区别在于,训练数据没有标签。算法需要从无标签的数据中发现隐藏的模式或结构。
无监督学习的主要任务包括:
- 聚类(Clustering):将相似的样本聚在一起,不同的样本分在不同的簇中。例如,客户分群、新闻主题聚类等。
- 降维(Dimensionality Reduction):在保留数据关键信息的前提下,减少数据的维度,便于可视化或提高后续学习任务的效率。例如,主成分分析(PCA)、t-SNE 等。
- 密度估计(Density Estimation):估计数据的概率分布。
3. 强化学习(Reinforcement Learning)
强化学习研究的是智能体如何在环境中通过试错来学习最优行为策略。智能体通过与环境的交互获得奖励信号,目标是最大化累积奖励。
强化学习在游戏 AI、机器人控制等领域取得了显著成功,如 AlphaGo 就是通过强化学习实现的。
按问题类型分类
除了按学习方式分类,机器学习任务还可以按问题类型分为:
- 分类问题:如前面提到的监督学习中的分类任务。
- 回归问题:如监督学习中的回归任务。
- 排序问题:如搜索引擎中的网页排序。
- 生成问题:生成符合特定分布的新数据,如生成逼真的图像、文本等。
机器学习的评估指标
评估模型的性能是机器学习流程中不可或缺的一步。不同的任务类型有不同的评估指标,选择合适的评估指标对于正确评价模型性能至关重要。
分类任务的评估指标
- 准确率(Accuracy):正确分类的样本数占总样本数的比例。这是最基本的评估指标,但在类别不平衡的情况下可能会产生误导。
- 精确度(Precision):预测为正类的样本中实际为正类的比例,关注预测为正类的准确性。
- 召回率(Recall):实际为正类的样本中被正确预测为正类的比例,反映模型识别所有正类的能力。
- F1 分数(F1 Score):精确度和召回率的调和平均值,综合考虑了模型的预测精度和覆盖率,特别适用于类别不平衡的情况。
- 混淆矩阵(Confusion Matrix):一个表格,展示了分类模型预测结果与真实标签之间的详细比较,可以从中计算出精确度、召回率等指标。
- ROC 曲线和 AUC 值:ROC 曲线通过描绘不同阈值下的真正率(TPR)与假正率(FPR)来评估二分类模型的性能。AUC 是 ROC 曲线下的面积,值越接近 1,表示模型性能越好。
回归任务的评估指标
- 均方误差(Mean Squared Error, MSE):预测值与真实值差值的平方的平均值。
- 均方根误差(Root Mean Squared Error, RMSE):MSE 的平方根,具有与原始数据相同的单位。
- 平均绝对误差(Mean Absolute Error, MAE):预测值与真实值差值的绝对值的平均值。
- 决定系数(R²):衡量模型解释数据变异的能力,取值范围为 0 到 1,越接近 1 表示模型拟合效果越好。
损失函数
损失函数是衡量模型预测结果与真实值之间差异的函数,是模型训练过程中优化的目标。不同的任务和算法会使用不同的损失函数:
- 分类任务常用交叉熵损失(Cross-Entropy Loss)。
- 回归任务常用均方误差损失(MSE)。
损失函数值的大小可以帮助我们了解模型的泛化能力,通常低损失值表明模型在未见过的数据上可能表现较好。
机器学习与相关学科的关系
机器学习是一门交叉学科,它与多个学科有着密切的联系,同时又有自己独特的研究对象和方法。
与人工智能的关系
机器学习是人工智能的一个重要分支,是实现人工智能的核心技术之一。人工智能的目标是让机器具有类似人类的智能,而机器学习则提供了让机器从数据中学习、不断改进性能的方法。可以说,机器学习是人工智能从概念走向实践的关键途径。
与统计学的关系
机器学习与统计学有着深厚的渊源。统计学研究如何收集、分析、解释数据,而机器学习则关注如何从数据中学习规律并做出预测。许多机器学习算法,如线性回归、逻辑回归、支持向量机等,都源于统计学理论。
然而,两者也存在差异:统计学家更注重理论分析和模型的可解释性,而计算机科学家(机器学习研究者)则更关注算法的效率和在实际问题中的表现。近年来,随着机器学习的发展,统计学和计算机科学的交叉越来越深入,形成了统计机器学习这一重要研究方向。
与计算机科学的关系
机器学习是计算机科学的一个重要研究领域,它依赖于计算机科学的多个分支,如算法设计、数据结构、编程语言等。同时,机器学习的发展也推动了计算机科学的进步,例如促进了并行计算、分布式系统等领域的发展。
计算机科学家为机器学习提供了强大的计算能力和高效的算法实现,使得许多复杂的机器学习模型能够在实际中得到应用。
与数据科学的关系
机器学习是数据科学的核心技术之一。数据科学关注如何从海量数据中提取有价值的信息,而机器学习则提供了实现这一目标的关键方法。通过机器学习算法,我们可以从数据中发现隐藏的模式、做出预测,为决策提供支持。
机器学习的应用场景
机器学习已经广泛应用于各个领域,深刻改变了我们的生活和工作方式。以下是一些典型的应用场景:
计算机视觉
计算机视觉是机器学习应用最成功的领域之一。通过深度学习算法,计算机可以实现图像分类、目标检测、人脸识别、图像分割等任务。这些技术被广泛应用于安防监控、自动驾驶、医疗影像诊断等领域。
2012 年 AlexNet 的成功正是在图像分类任务上取得的突破性进展,它开启了深度学习在计算机视觉领域的蓬勃发展。
自然语言处理
自然语言处理研究如何让计算机理解和生成人类语言。机器学习,特别是深度学习技术,极大地推动了自然语言处理的发展。现在,我们可以看到机器翻译、情感分析、文本摘要、问答系统等应用,这些都离不开机器学习算法的支持。
近年来,大型语言模型(如 ChatGPT)的出现更是将自然语言处理的能力提升到了新的高度。
推荐系统
推荐系统是机器学习在互联网领域的重要应用。通过分析用户的历史行为数据,机器学习算法可以预测用户的喜好,为用户推荐个性化的商品、电影、音乐等。推荐系统已经成为电商、视频平台、音乐应用等的核心功能之一。
金融领域
在金融领域,机器学习被用于信用评分、 fraud 检测、股市预测等任务。通过分析大量的金融数据,机器学习算法可以识别潜在的风险,帮助金融机构做出更明智的决策。
医疗健康
机器学习在医疗健康领域的应用也越来越广泛,如疾病诊断、药物研发、个性化医疗等。通过分析医疗影像、基因数据等,机器学习算法可以辅助医生做出更准确的诊断,加速新药研发过程。
初学者学习机器学习的常见误区
机器学习是一个充满魅力的领域,但对于初学者来说,很容易陷入一些学习误区。了解这些误区可以帮助我们更高效地学习。
误区一:试图掌握所有数学知识后再开始学习
很多初学者认为必须先精通线性代数、概率论、微积分等数学知识才能开始学习机器学习。事实上,这种做法很容易导致半途而废。
虽然数学是机器学习的基础,但我们并不需要在开始阶段就掌握所有相关数学知识。更有效的学习方法是在学习机器学习的过程中,根据需要逐步补充相关的数学知识。这样的学习方式更有目的性,也更能保持学习的动力。
误区二:将深度学习作为入门第一课
深度学习是当前机器学习领域的热点,很多初学者被其强大的性能所吸引,希望从深度学习开始学习机器学习。然而,这并不是一个好主意。
深度学习模型通常比较复杂,具有明显的 "黑箱" 特性,初学者很难理解其内部原理。此外,深度学习的理论和技术还在快速发展变化中,且对计算资源要求较高,不太适合初学者入门。
更合理的学习路径是从传统的机器学习算法开始,如线性回归、决策树、支持向量机等,打好基础后再学习深度学习。
误区三:收集过多的学习资料
机器学习的学习资料非常丰富,很容易让初学者陷入 "收集癖",下载大量的书籍、课程视频等,但真正深入学习的却很少。
机器学习发展迅速,知识更新快。在入门阶段,建议选择少量近期出版的、口碑良好的资料进行学习,避免被过时的知识误导。例如,很多 10 年前的深度学习教材还在推荐 Sigmoid 作为默认激活函数,而现在 ReLU 及其变种已经成为主流。
误区四:忽视实践
机器学习是一门实践性很强的学科,仅仅学习理论知识是远远不够的。很多初学者花费大量时间阅读书籍和论文,但很少动手编程实现算法、处理实际数据。
事实上,只有通过实践,我们才能真正理解机器学习算法的原理和应用场景。建议初学者从简单的项目开始,逐步积累实践经验。
机器学习入门学习路线
对于初学者来说,制定一个合理的学习路线至关重要。以下是一个循序渐进的学习路径建议:
阶段一:基础知识准备
- 数学基础:重点学习线性代数(矩阵运算、特征值分解等)、概率论与数理统计(概率分布、期望、方差等)、微积分(导数、偏导数、梯度等)。不需要一开始就追求深入理解,随着学习的深入再逐步巩固。
- 编程基础:学习 Python 编程语言,掌握 NumPy、Pandas、Matplotlib 等数据处理和可视化库。Python 是机器学习领域最常用的编程语言,这些库可以帮助我们高效地处理数据和实现算法。
阶段二:核心算法学习
- 经典机器学习算法:从简单的算法开始,如线性回归、逻辑回归、k 近邻(k-NN)、决策树等,理解其原理和应用场景。
- 模型评估与选择:学习交叉验证、正则化等模型评估和选择方法,理解如何避免过拟合和欠拟合。
- 进阶算法:学习支持向量机、随机森林、梯度提升树(GBDT、XGBoost 等)等更复杂的算法,了解它们的优缺点和适用场景。
阶段三:深度学习入门
- 神经网络基础:学习神经网络的基本原理,如感知机、多层神经网络、激活函数、反向传播算法等。
- 深度学习框架:学习使用一个深度学习框架,如 TensorFlow 或 PyTorch,实现简单的神经网络模型。
- 经典深度学习模型:学习卷积神经网络(CNN)、循环神经网络(RNN)等经典模型,了解它们在计算机视觉、自然语言处理等领域的应用。
阶段四:实践与项目
- 数据集练习:使用公开数据集(如 MNIST、Iris、Boston Housing 等)练习实现和调优机器学习算法。
- 小型项目:完成一些小型项目,如房价预测、图像分类、情感分析等,将所学知识应用到实际问题中。
- 参与竞赛:可以尝试参加一些机器学习竞赛(如 Kaggle),在实践中提高自己的能力。
推荐学习资源
- 在线课程:Andrew Ng 的机器学习课程是经典的入门课程,深入浅出地讲解了机器学习的基本概念和算法。对于深度学习,可以学习 Stanford 大学的 CS231n(计算机视觉)和 CS224n(自然语言处理)课程。
- 书籍:入门阶段可以阅读《机器学习实战》、《Python 机器学习》等实践类书籍;理论方面,周志华老师的《机器学习》(俗称 "西瓜书")和李航老师的《统计学习方法》是很好的选择。
- 开源项目:研究和学习 GitHub 上的开源机器学习项目,了解实际应用中的最佳实践。
- 学术会议:关注顶级机器学习会议(如 NeurIPS、ICML、KDD 等)的论文,了解领域的最新进展。
总结与展望
机器学习作为一门快速发展的交叉学科,已经成为推动人工智能进步的核心力量。从早期的逻辑推理到如今的深度学习,机器学习经历了数十年的发展历程,每一次突破都离不开理论研究和技术创新的双重驱动。
机器学习的核心在于让计算机从数据中自主学习规律,其主要任务包括监督学习、无监督学习和强化学习等。通过选择合适的评估指标,我们可以客观地评价模型的性能,不断改进算法。
对于初学者来说,学习机器学习需要避免陷入追求完美数学基础、盲目跟风深度学习等误区。合理的学习路径应该是循序渐进的,从基础知识和经典算法入手,逐步深入到复杂模型和实际应用。
展望未来,机器学习将在更多领域发挥重要作用,如自动驾驶、个性化医疗、智能城市等。同时,我们也面临着可解释性、公平性、隐私保护等方面的挑战。这些挑战不仅需要技术上的创新,还需要跨学科的合作和全社会的共同努力。
作为初学者,加入机器学习的旅程可能会面临挑战,但只要保持好奇心和学习热情,通过理论学习和实践积累,一定能够逐步掌握这门令人兴奋的技术,为未来的智能时代贡献自己的力量。记住,最好的学习方法是动手实践 —— 选择一个感兴趣的问题,找到合适的数据,尝试用机器学习算法来解决它。在这个过程中,你会不断发现问题、解决问题,逐步成长为一名优秀的机器学习实践者。