李沐-第十章-训练Seq2SeqAttentionDecoder报错
问题
系统: win11
显卡:5060
CUDA:12.8
pytorch:2.7.1+cu128
pycharm:2025.2
训练带有注意力机制的编码器-解码器网络时,
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)encoder = d2l.Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)net = EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
会报错unpack错误.
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[8], line 118 decoder = Seq2SeqAttentionDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)10 net = d2l.EncoderDecoder(encoder, decoder)
---> 11 train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)Cell In[7], line 41, in train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device)39 bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0], device=device).reshape(-1, 1)40 dec_input = torch.cat([bos, Y[:,:-1]], 1)
---> 41 Y_hat, _ = net(X, dec_input, X_valid_len)42 l = loss(Y_hat, Y, Y_valid_len)43 l.sum().backward()ValueError: too many values to unpack (expected 2)
分析
排查发现d2l包里面的EncoderDecoder定义和教材中不同.
d2l包里面的定义:
class EncoderDecoder(d2l.Classifier):"""The base class for the encoder--decoder architecture.Defined in :numref:`sec_encoder-decoder`"""def __init__(self, encoder, decoder):super().__init__()self.encoder = encoderself.decoder = decoderdef forward(self, enc_X, dec_X, *args):enc_all_outputs = self.encoder(enc_X, *args)dec_state = self.decoder.init_state(enc_all_outputs, *args)# Return decoder output onlyreturn self.decoder(dec_X, dec_state)[0]def predict_step(self, batch, device, num_steps,save_attention_weights=False):"""Defined in :numref:`sec_seq2seq_training`"""batch = [d2l.to(a, device) for a in batch]src, tgt, src_valid_len, _ = batchenc_all_outputs = self.encoder(src, src_valid_len)dec_state = self.decoder.init_state(enc_all_outputs, src_valid_len)outputs, attention_weights = [d2l.expand_dims(tgt[:, 0], 1), ], []for _ in range(num_steps):Y, dec_state = self.decoder(outputs[-1], dec_state)outputs.append(d2l.argmax(Y, 2))# Save attention weights (to be covered later)if save_attention_weights:attention_weights.append(self.decoder.attention_weights)return d2l.concat(outputs[1:], 1), attention_weights
教材的定义(9.6.3):
class EncoderDecoder(nn.Module):def __init__(self, encoder, decoder, **kwargs):super(EncoderDecoder, self).__init__(**kwargs)self.encoder = encoderself.decoder = decoderdef forward(self, enc_X, dec_X, *args):enc_outputs = self.encoder(enc_X, *args)dec_state = self.decoder.init_state(enc_outputs, *args)return self.decoder(dec_X, dec_state)解决方法
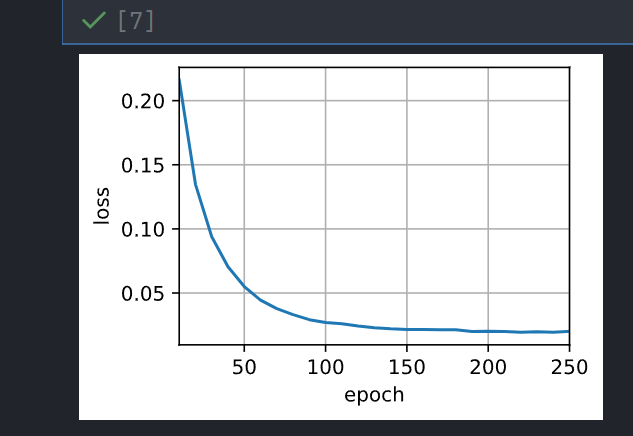
使用教材中的EncoderDecoder定义, 正常训练不报错.
训练结果: