李沐-第十章-实现Seq2SeqAttentionDecoder时报错
问题
系统: win11
显卡:5060
CUDA:12.8
pytorch:2.7.1+cu128
pycharm:2025.2
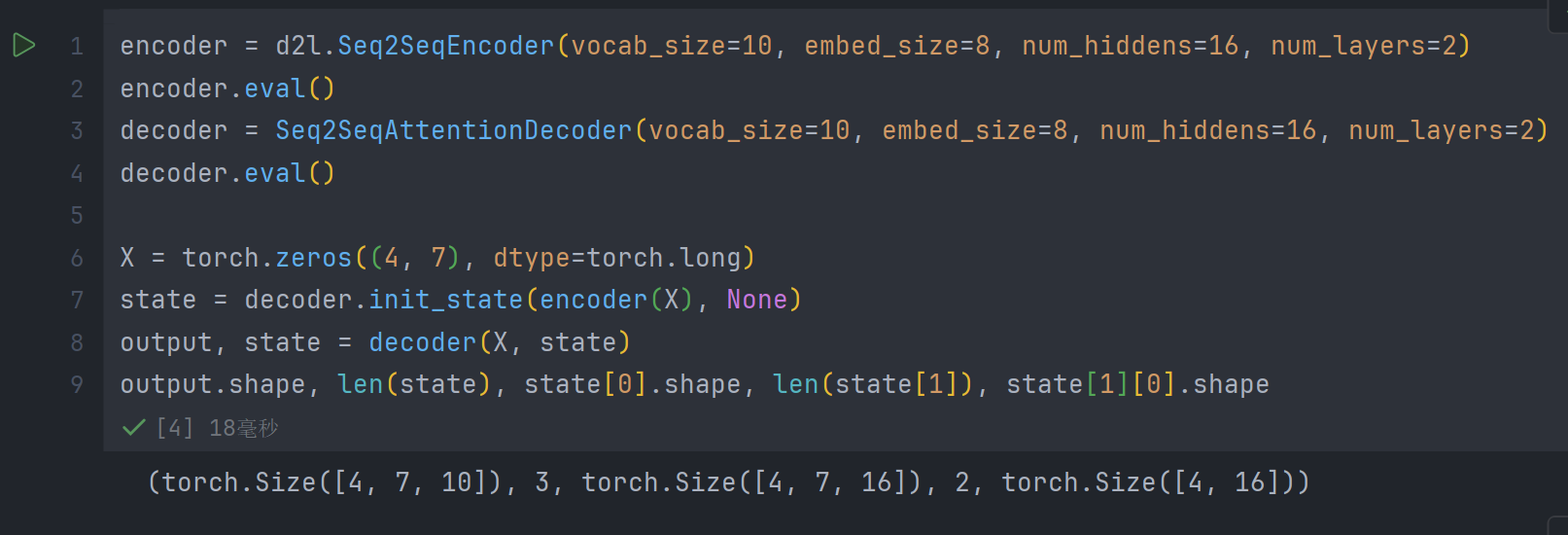
实现Seq2SeqAttentionDecoder后, 运行:
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
decoder.eval()X = torch.zeros((4, 7), dtype=torch.long)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
会报错AdditiveAttention.__init__()输入参数个数不正确:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[4], line 31 encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)2 encoder.eval()
----> 3 decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)4 decoder.eval()6 X = torch.zeros((4, 7), dtype=torch.long)Cell In[3], line 4, in Seq2SeqAttentionDecoder.__init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout, **kwargs)2 def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):3 super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
----> 4 self.attention = d2l.AdditiveAttention(num_hiddens, num_hiddens, num_hiddens, dropout)5 self.embedding = nn.Embedding(vocab_size, embed_size)6 self.rnn = nn.GRU(embed_size+num_hiddens, num_hiddens, num_layers, dropout=dropout)TypeError: AdditiveAttention.__init__() takes 3 positional arguments but 5 were given
分析
经排查, 是d2l包里面的AdditiveAttention定义和教材中的不一致问题.
d2l包里面的定义:
class AdditiveAttention(nn.Module):"""Additive attention.Defined in :numref:`subsec_batch_dot`"""def __init__(self, num_hiddens, dropout, **kwargs):super(AdditiveAttention, self).__init__(**kwargs)self.W_k = nn.LazyLinear(num_hiddens, bias=False)self.W_q = nn.LazyLinear(num_hiddens, bias=False)self.w_v = nn.LazyLinear(1, bias=False)self.dropout = nn.Dropout(dropout)def forward(self, queries, keys, values, valid_lens):queries, keys = self.W_q(queries), self.W_k(keys)# After dimension expansion, shape of queries: (batch_size, no. of# queries, 1, num_hiddens) and shape of keys: (batch_size, 1, no. of# key-value pairs, num_hiddens). Sum them up with broadcastingfeatures = queries.unsqueeze(2) + keys.unsqueeze(1)features = torch.tanh(features)# There is only one output of self.w_v, so we remove the last# one-dimensional entry from the shape. Shape of scores: (batch_size,# no. of queries, no. of key-value pairs)scores = self.w_v(features).squeeze(-1)self.attention_weights = masked_softmax(scores, valid_lens)# Shape of values: (batch_size, no. of key-value pairs, value# dimension)return torch.bmm(self.dropout(self.attention_weights), values)
教材中的定义:
class AdditiveAttention(nn.Module):def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):super(AdditiveAttention, self).__init__(**kwargs)self.W_k = nn.Linear(key_size, num_hiddens, bias=False)self.W_q = nn.Linear(query_size, num_hiddens, bias=False)self.w_v = nn.Linear(num_hiddens, 1, bias=False)self.dropout = nn.Dropout(dropout)def forward(self, queries, keys, values, valid_lens):queries, keys = self.W_q(queries), self.W_k(keys)features = queries.unsqueeze(2) + keys.unsqueeze(1)scores = self.w_v(features).squeeze(-1)self.attention_weights = masked_softmax(scores, valid_lens)return torch.bmm(self.dropout(self.attention_weights), values)解决方法
使用教材中的AdditiveAttention定义, 粘贴到d2l/pytorch.py, 替换原定义. 可以正常运行.