【大模型LLM学习】Data Agent学习笔记
【大模型LLM学习】Data Agent学习笔记
- 1 常用Agent编排框架
- 1.1 ReAct
- 1.2 Plan-and-execute
- 1.3 Reasoning WithOut Observations
- 1.4 LLMCompiler
- 2 ModelScope的Data Agent实现
- 2.1 执行流程
- 2.1.1 规划阶段
- 2.1.2 执行阶段
- 2.1.3 执行效果
- Reference
1 常用Agent编排框架
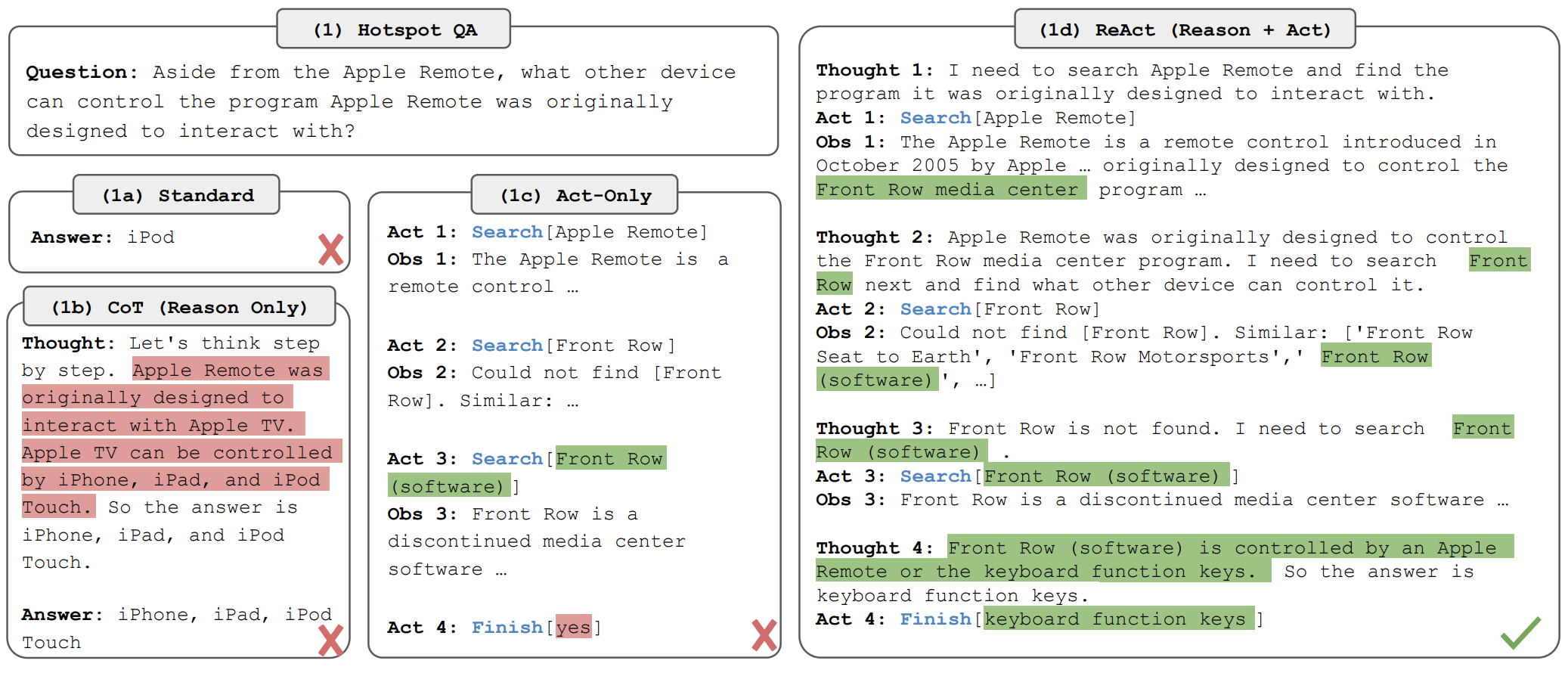
1.1 ReAct
- question -> (think -> action -> observation)… -> think -> result的循环
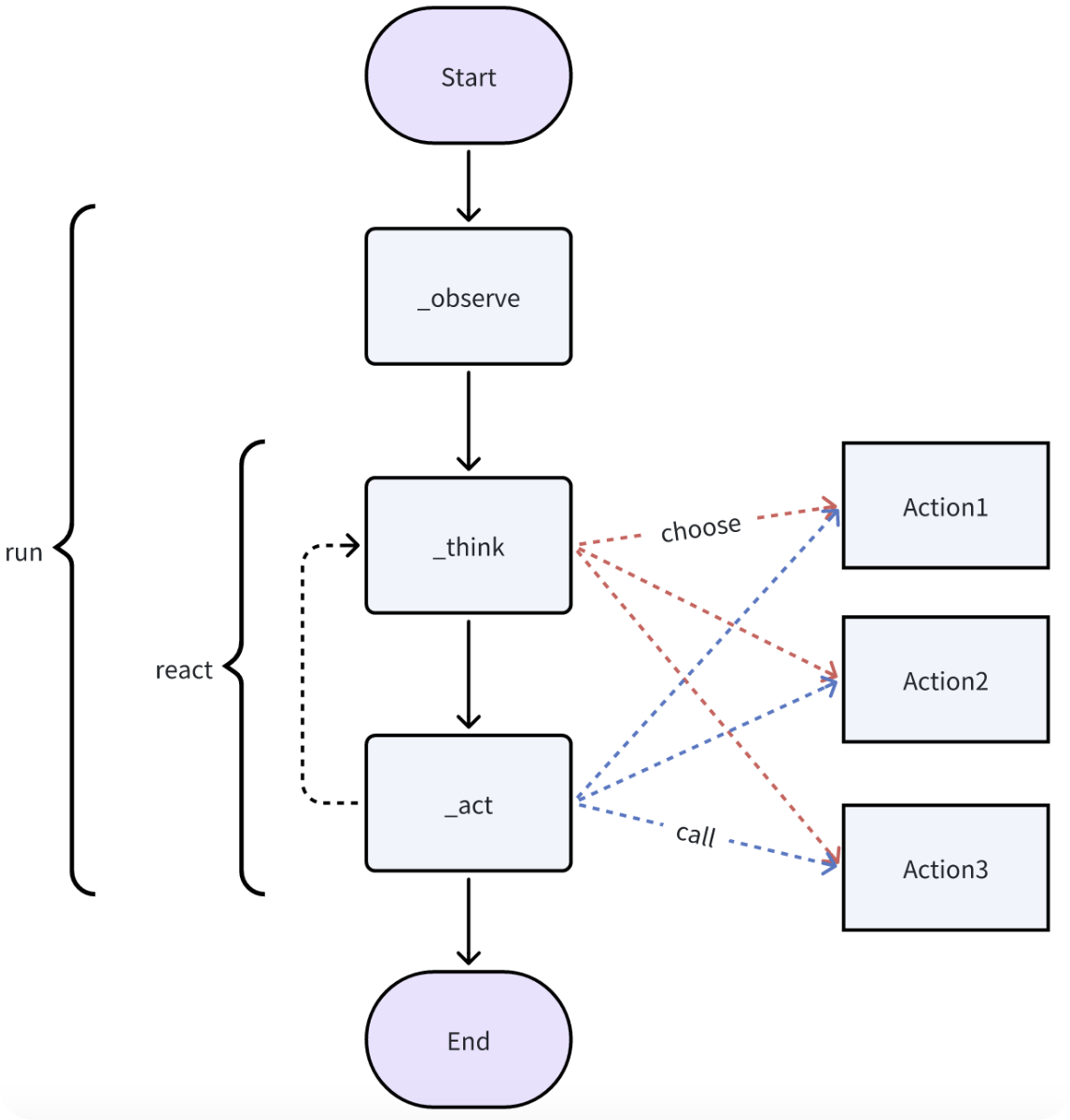
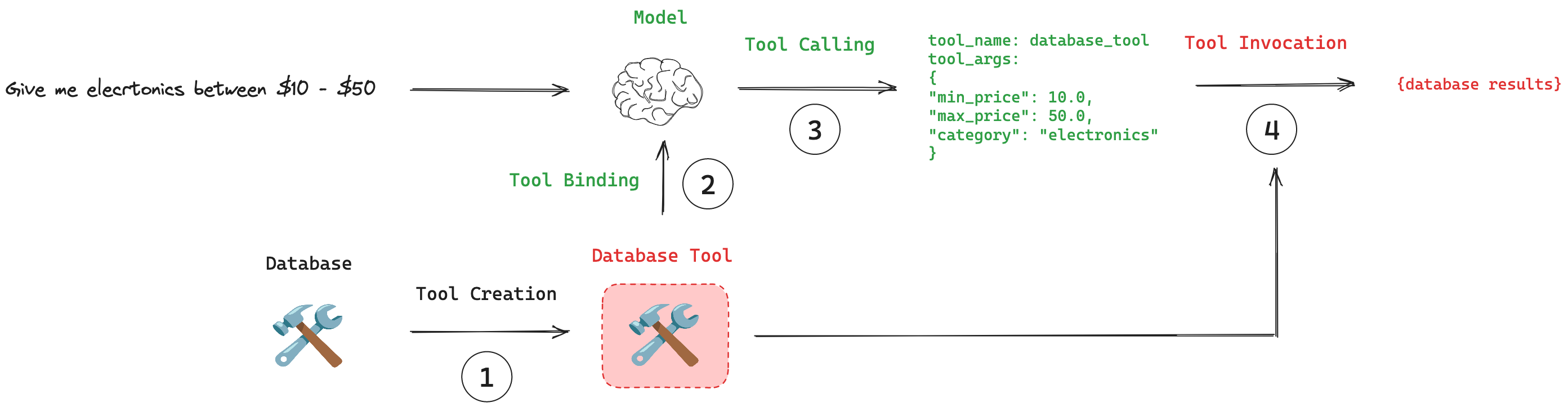
- 调用工具的过程包括把工具绑定到LLM上,提取出function call的函数名和函数参数,调用function,得到结果
- 一个具体的ReAct的示例
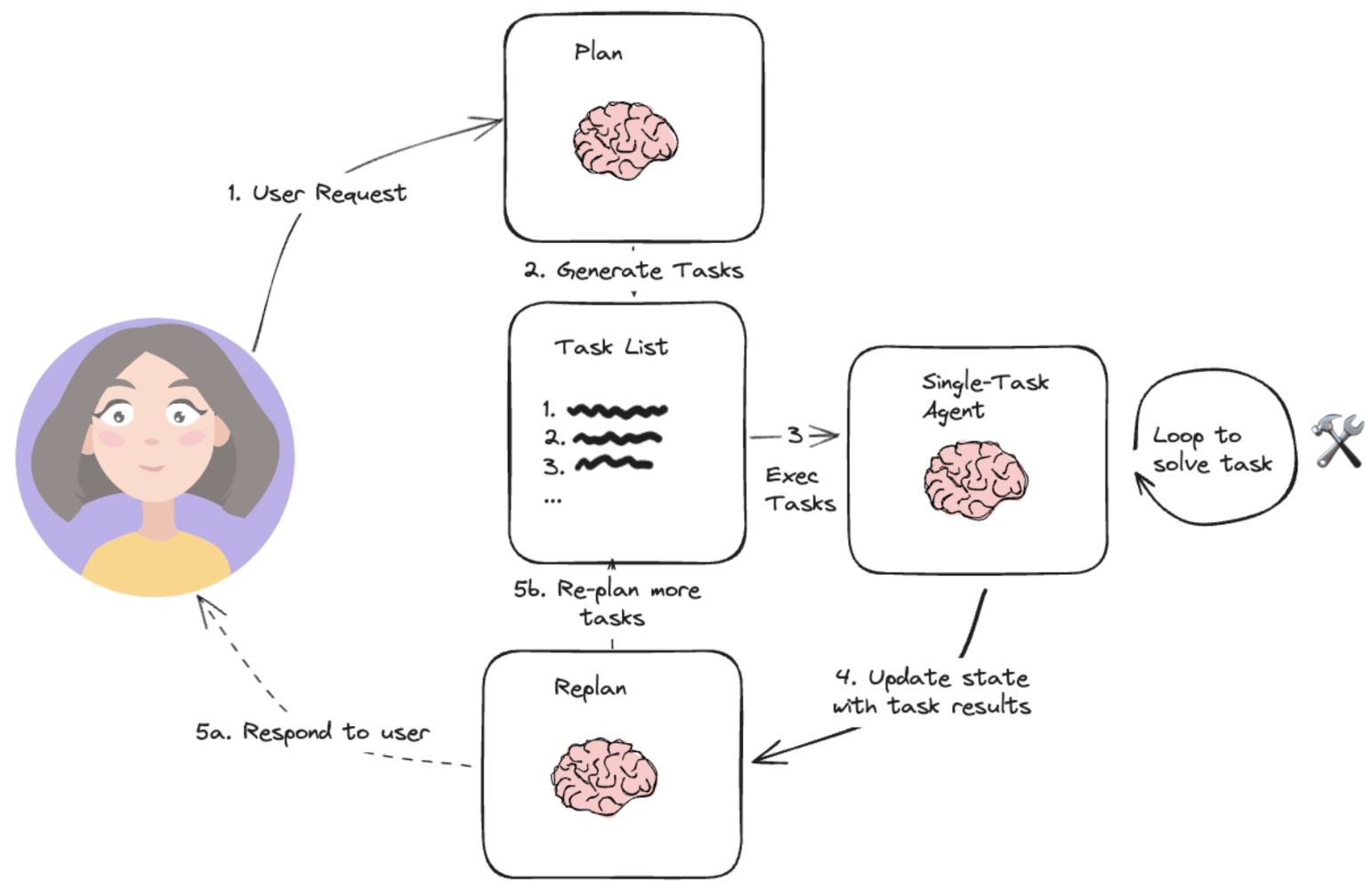
1.2 Plan-and-execute
框架步骤:
- 任务计划:代理接收用户输入的任务描述,进行语义理解,将任务分解为多个可执行子任务
- 子任务调度:基于任务之间的依赖关系和优先级,智能调度子任务的执行顺序
- 任务执行:每个子任务分配给特定的模块执行
- 重新规划:判断任务结果质量是否满足要求,或者需要再次规划执行
- 结果整合:汇总各子任务的结果,形成最终输出,并反馈给用户
优点:
- 任务拆分后,子任务难度下降
- 子任务合并为最后结果才需要调用最大的模型
- 中间可以小模型+部分并行(原始的没有并行)
- 任务成功率提升,确定性增加,一定可以返回一个结果(结果可能不准确,比较适合开放性问题)
问题:
- Replan模块可以限制一个最大重新规划的次数,防止一直死循环以及超长上下文;Replan需要精细化设计
- 总会有输出,但是最终输出结果可能不准确
1.3 Reasoning WithOut Observations
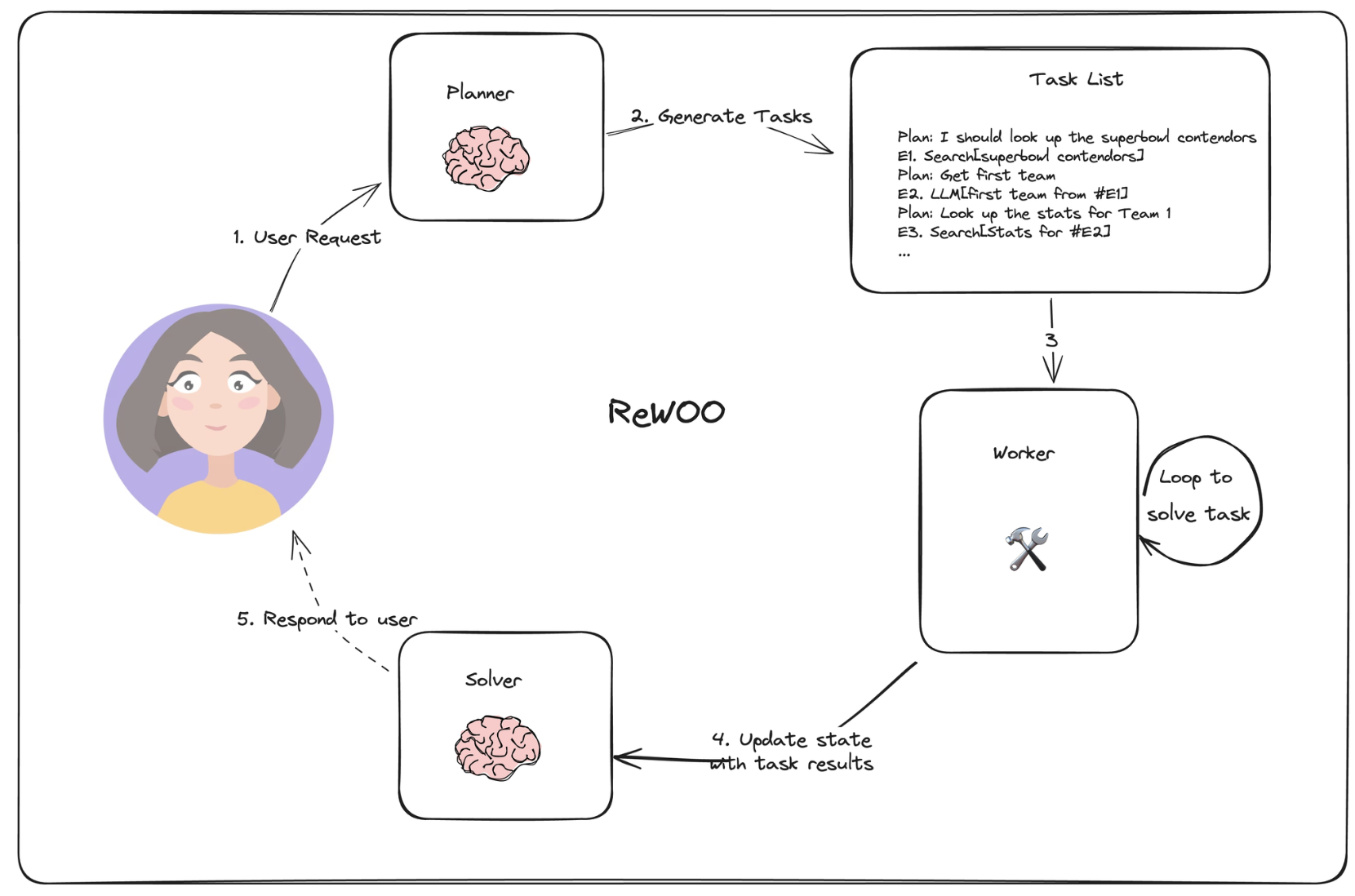
- 一个完成的流程示例,首先给出一个plan list,然后通过完成任务做填空题,填充"#E"字段
Plan: I need to know the teams playing in the superbowl this year
E1: Search[Who is competing in the superbowl?]
Plan: I need to know the quarterbacks for each team
E2: LLM[Quarterback for the first team of #E1]
Plan: I need to know the quarterbacks for each team
E3: LLM[Quarter back for the second team of #E1]
Plan: I need to look up stats for the first quarterback
E4: Search[Stats for #E2]
Plan: I need to look up stats for the second quarterback
E5: Search[Stats for #E3]
- 优点:一次性生成plan,不需要每次replan,迭代完成任务来填充"#E",然后最后根据填好的list给出最后的回答,不需要每次replan
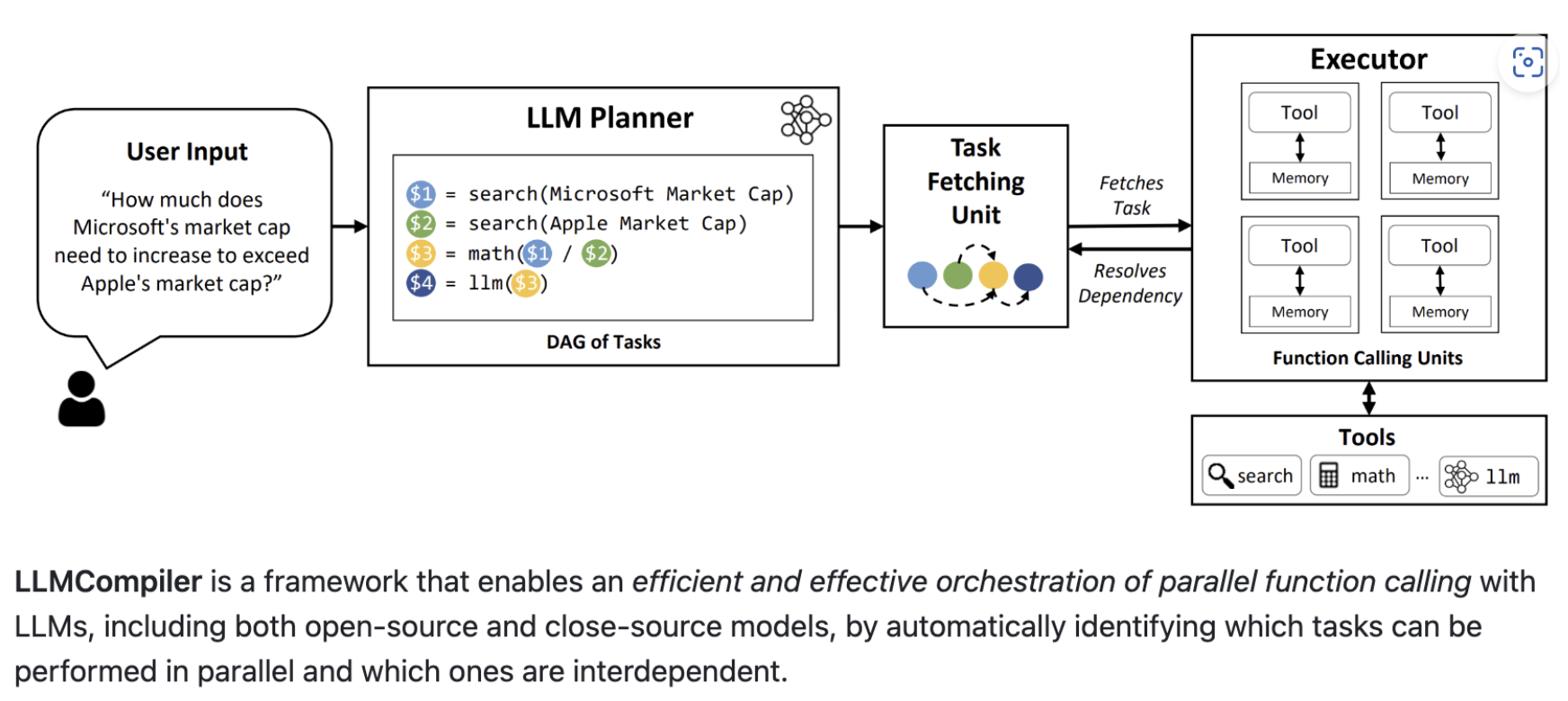
1.4 LLMCompiler
- 把任务间的依赖关系理清楚,前置项完成的子任务就可以开始进行并行调用节约运行时间
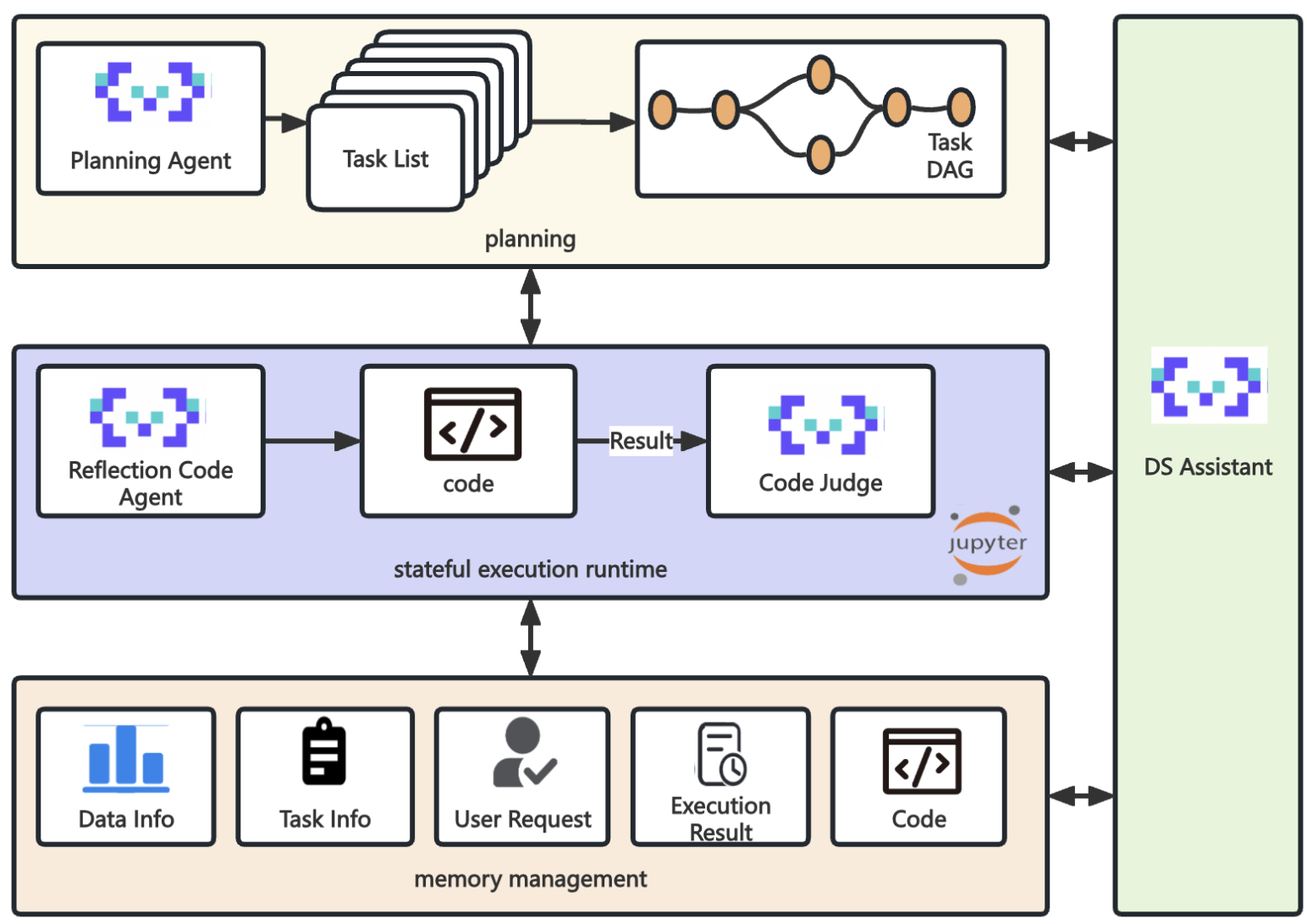
2 ModelScope的Data Agent实现
使用生成代码并执行的方式来执行一部分任务,整套系统包含4个主要模块:
- Plan模块:负责根据用户的需求生成一系列Task列表,并对task先后顺序进行拓扑排序
- Execution 模块:负责任务的具体执行,保存任务执行结果
- Memory management 模块:负责记录任务中间执行结果,代码,数据详情等信息
- DS Assistant:作为整个系统的大脑,负责调度整个系统的运转
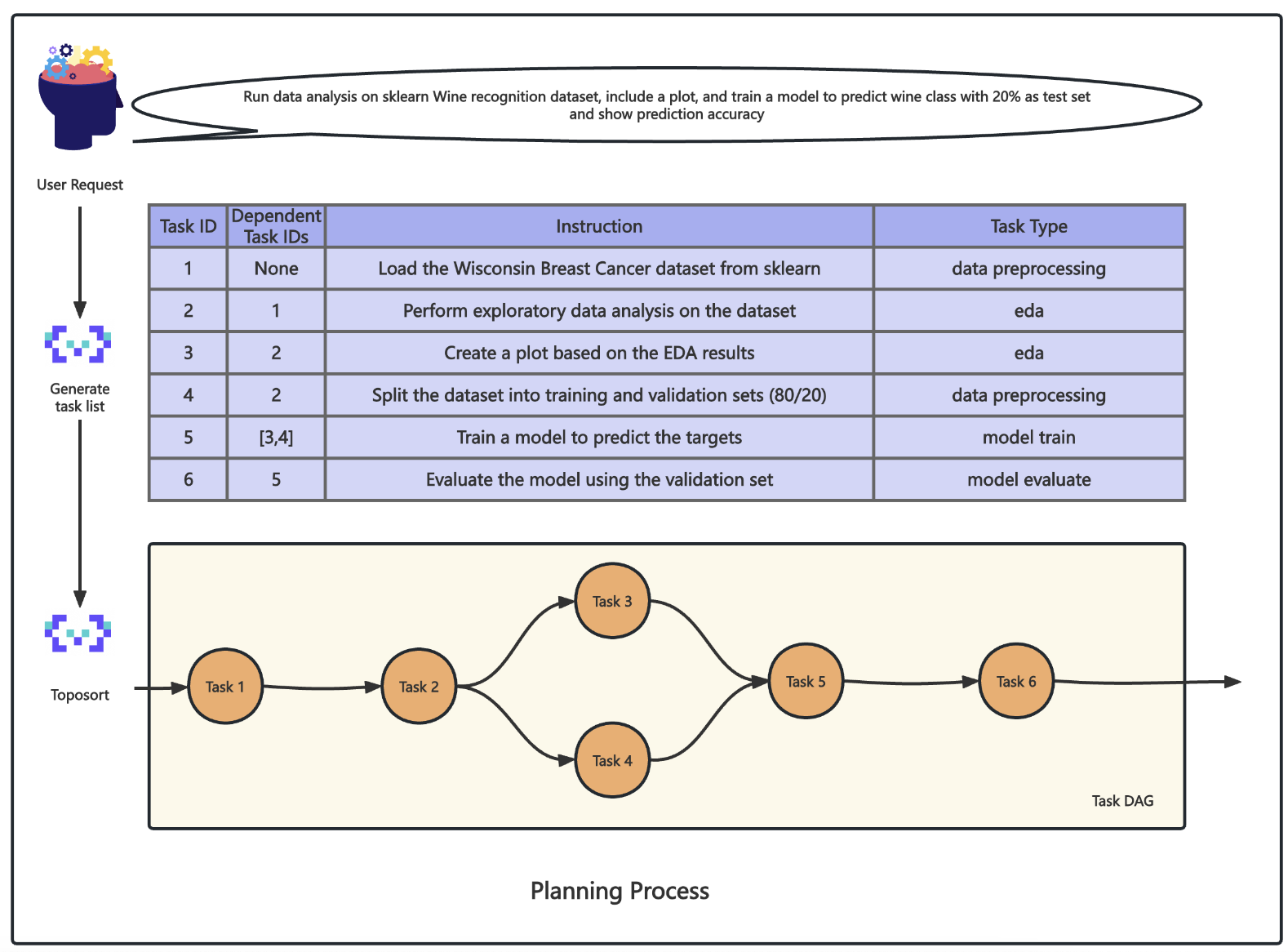
2.1 执行流程
2.1.1 规划阶段
在这一阶段,DS Assistant根据用户输入的复杂数据科学问题,自动将其分解为多个子任务。这些子任务根据依赖关系和优先级顺序调度,确保执行顺序符合逻辑且高效。
2.1.2 执行阶段
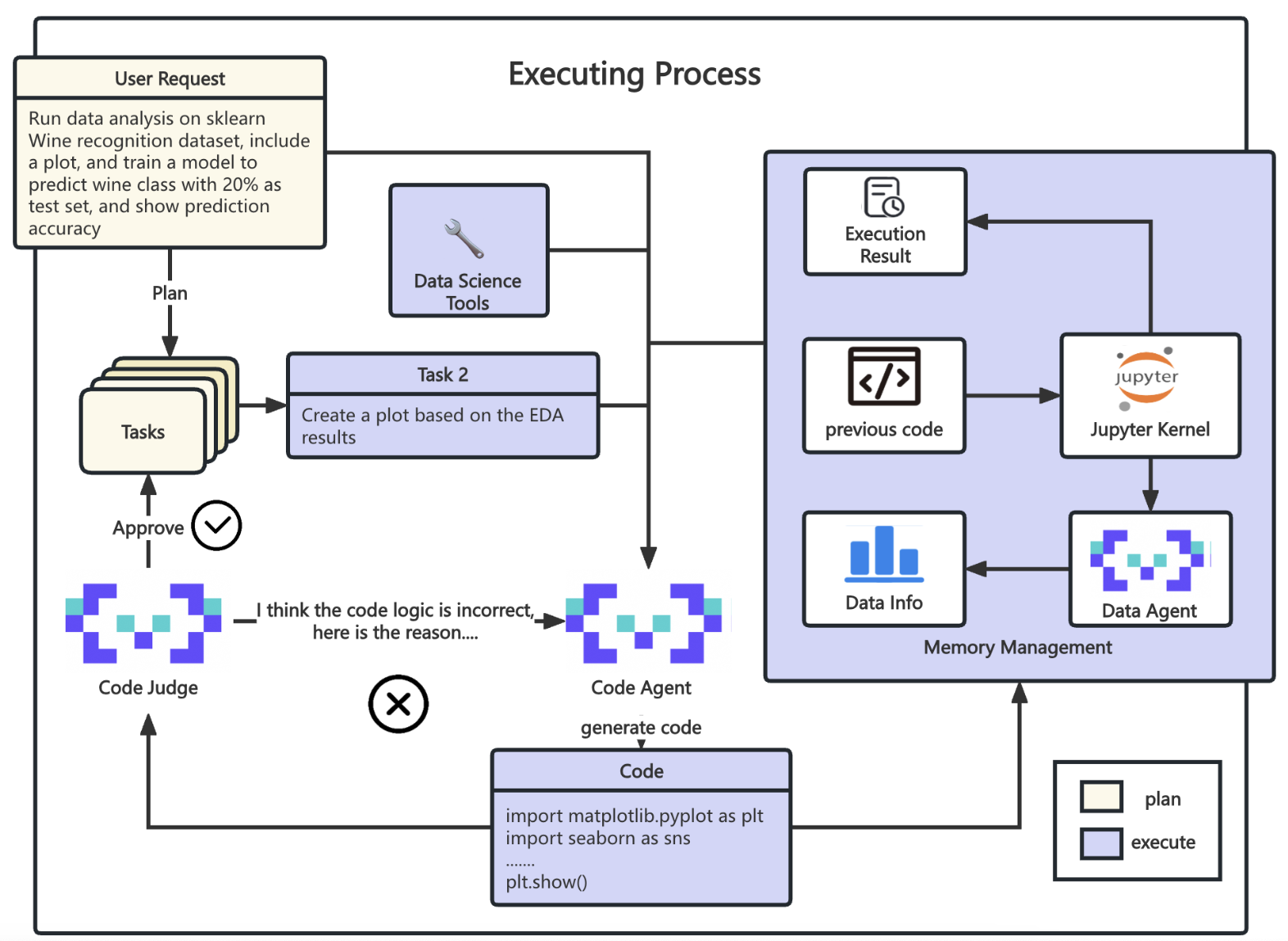
2.1.3 执行效果
主要需要关注关注时间开销和token消耗,在几个经典的kaggle数据集上
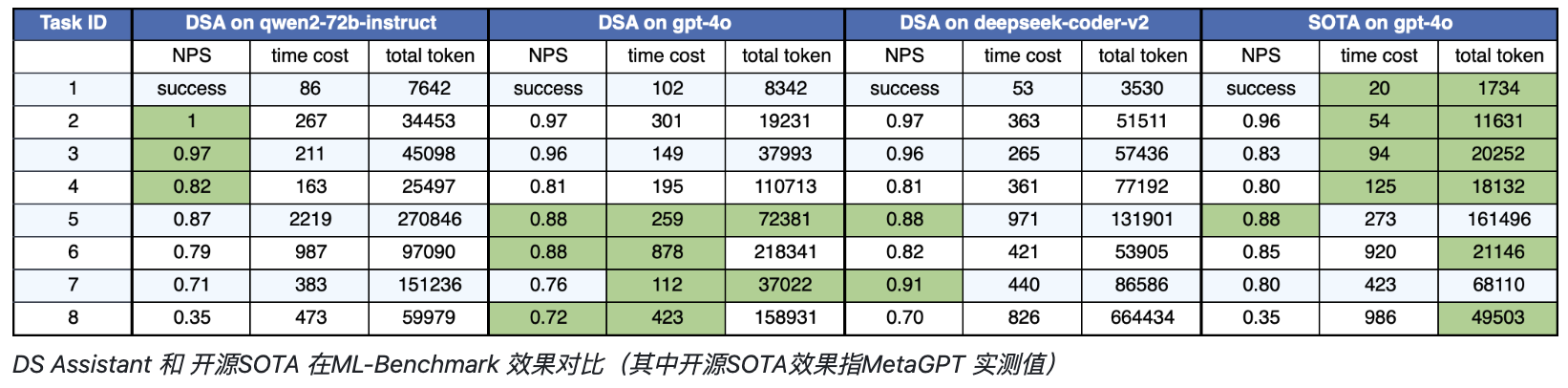
- 效果上,完成一个机器学习任务token和时间开销都不高,SOTA指的是MetaGPT的Data Interpreter,执行时间大部分在15分钟以内,token开销大部分在20W 的token以内,如果是qwen系列不到1元,如果是gpt-4o大约14元
Reference
- langchain的plan agent: https://blog.langchain.com/planning-agents/
- ms-agent: https://github.com/modelscope/ms-agent/blob/release/0.8/docs/source/agents/data_science_assistant.md