机械学习综合练习项目
数据集合完整项目文件已经上传
一、项目介绍
案例介绍 案例是针对“红酒.csv”数据集,在红葡萄酒质量分析的场景 中,利用多元线性回归来探索红葡萄酒的不同化学成分如何共同 影响其质量评分。在建立线性回归模型之后,当给出了红葡萄酒 的新的一组化学成分的数据,我们可以利用模型预测红葡萄酒的 质量评分。 在一些情况下,我们需要使用没有用于拟合模型的新数据进 行预测。我们可以利用红葡萄酒成分的一个新的观测,并根据这 些新成分预测葡萄酒的质量评分。 1.1数据集名称: 红酒.csv 1.2数据集介绍: 该数据集记录了某款红葡萄酒的不同化学成分(基于物理化 学测试)以及质量评分(基于品酒师感官)数据,是纯文本格式, 共有11个特征变量,对应数据文件的前11列,和1个需要预测 变量,对应数据文件的第12列,具体描述如下: 特征变量(描述红酒的化学成分): 第1列:固定酸度 第2列:挥发性酸度 第3列:柠檬酸 第4列:残糖 第5列:氯化物 第6列:游离二氧化硫 第7列:总二氧化硫 第8列:密度 第9列:PH值 第10列:硫酸盐 第11列:酒精 效预测(输山)变量: 第12列:质量评分(0到10) 需要注意的是数据集“红酒.csv”中的缺失值用NA表示。 二、案例分析基本要求 2.1.数据理解 2.1.1分析数据集的基本结构,查询并输出数据的前10行和 后10行。 2.1.2识别并输出数据集中所有变量的类型 2.2.数据清洗 2.2.1缺失值处理,利用多种补缺方式处理 2.3数据鳖理 2.3.1根据数据清洗结果对数据集转化并生成新的数据集 2.3.2数据标准化 2.3.3数据集随机分割3/4用于训练,1/4用于测试 2.1数掘分析 2.4.1探索性数据分析,提供可视化结果 2.4.2描述性数据分析,提供可视化结果 2.5回归预测分析 2.5.1建立分类模型 2.5.2分析模型可靠性 2.5.3误差分析 2.5.4模型參数检验 2.5.5报告分类结果2.6数据可视化 2.6.1产生并输出表格:二维/三维表格 2.6.2产生并输出图形:柱状图,条形图,饼图等 2.7新数据预测 假设,有以下关于葡萄酒成分的一个新的观测: 7.9,0.43,0.21,1.6,0.106,10.0,37.0,0.9966,3.17,0.91,9.5,5 7.1.0.71.0.0.1.9.0.08.14.0.35.0.0.9972.3.47.0.55.9.4.5 7.8.0.645.0.0.2.0.0.082.8.0.16.0.0.9964.3.38.0.59.9.8.6 请恨据这些成分预测红葡萄酒的质量评分。 三、分析报告提纲 项目概述,分析目标,运用方法概述,结果分析,结论等, 你的分析报告中必须包含基本要求中的内容,但不仪限于基本要 求,可白行增加分析内容。
二、部分实现代码
数据处理主函数:
import pandas as pd
import fill_datadata = pd.read_csv(r"W:\学徒\工程\2\机器学习\数据清理作业\红酒.csv",encoding='GBK')
#检测缺失值
null_num = data.isnull()
null_total = null_num.sum()# 获取全部特征数据
X_whole = data.drop("质量评分", axis=1)
y_whole = data.质量评分 # 获取全部标签数据# 将数据中的中文标签转换为字符for column_name in X_whole.columns:X_whole[column_name] = pd.to_numeric(X_whole[column_name], errors='coerce')#Z标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_whole_z = scaler.fit_transform(X_whole)
X_whole = pd.DataFrame(X_whole_z, columns=X_whole.columns)#数据拆分
from sklearn.model_selection import train_test_split
x_train_w,x_test_w,y_train_w,y_test_w = train_test_split(X_whole,y_whole,test_size=0.3,random_state=0)#数据空缺填充
#1、、、只保留完整数据
# x_train_fill,y_train_fill = fill_data.cca_train_fill(x_train_w, y_train_w)
# x_test_fill, y_test_fill = fill_data.cca_test_fill(x_train_fill, y_train_fill, x_test_w, y_test_w)#2、平均值填充
# x_train_fill,y_train_fill = fill_data.mean_train_fill(x_train_w,y_train_w)
# x_test_fill, y_test_fill = fill_data.mean_test_fill(x_train_fill, y_train_fill, x_test_w, y_test_w)#中位数填充
# x_train_fill,y_train_fill = fill_data.median_train_fill(x_train_w,y_train_w)
# x_test_fill, y_test_fill = fill_data.median_test_fill(x_train_fill, y_train_fill, x_test_w, y_test_w)#众数填充
# x_train_fill,y_train_fill = fill_data.mode_train_fill(x_train_w,y_train_w)
# x_test_fill, y_test_fill = fill_data.mode_test_fill(x_train_fill, y_train_fill, x_test_w, y_test_w)#线性回归填充
# x_train_fill,y_train_fill = fill_data.lr_train_fill(x_train_w,y_train_w)
# x_test_fill, y_test_fill = fill_data.lr_test_fill(x_train_fill, y_train_fill, x_test_w, y_test_w)
# null_num = x_train_fill.isnull()#随即森林填充
# x_train_fill,y_train_fill = fill_data.rf_train_fill(x_train_w,y_train_w)
# x_test_fill, y_test_fill = fill_data.rf_test_fill(x_train_fill, y_train_fill, x_test_w, y_test_w)#smote算法实现数据集的拟合,解决样本不均衡
from imblearn.over_sampling import SMOTE
oversampler = SMOTE(k_neighbors=1, random_state=42)
os_x_train, os_y_train = oversampler.fit_resample(x_train_fill, y_train_fill)#数据保存为excel文件
data_train = pd.concat([os_y_train, os_x_train], axis=1).sample(frac=1, random_state=0)
data_test = pd.concat([y_test_fill, x_test_fill], axis=1)# data_train.to_excel(r'./temp_data/3、训练数据集[缺失值删除].xlsx', index=False)
# data_test.to_excel(r'./temp_data/3、测试数据集[缺失值删除].xlsx', index=False)# data_train.to_excel(r'./temp_data/2、训练数据集[平均值填充].xlsx', index=False)
# data_test.to_excel(r'./temp_data/2、测试数据集[平均值填充].xlsx', index=False)# data_train.to_excel(r'./temp_data/3、训练数据集[中位数填充].xlsx', index=False)
# data_test.to_excel(r'./temp_data/3、测试数据集[中位数填充].xlsx', index=False)# data_train.to_excel(r'./temp_data/4、训练数据集[众数填充].xlsx', index=False)
# data_test.to_excel(r'./temp_data/4、测试数据集[众数填充].xlsx', index=False)# data_train.to_excel(r'./temp_data/3、训练数据集[线性回归填充].xlsx', index=False)
# data_test.to_excel(r'./temp_data/3、测试数据集[线性回归填充].xlsx', index=False)# data_train.to_excel(r'./temp_data/6、训练数据集[随机森林填充].xlsx', index=False)
# data_test.to_excel(r'./temp_data/6、测试数据集[随机森林填充].xlsx', index=False)数据填充函数:
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression#--------------------------考虑包含完整行的数据------------------------------#
def cca_train_fill(train_data,train_label):'''CCA(Complete Case Analysis)只考虑包含完整数据的行'''data = pd.concat([train_data, train_label], axis=1)data = data.reset_index(drop=True)df_filled = data.dropna()return df_filled.drop('质量评分', axis=1),df_filled.质量评分
def cca_test_fill(train_data,train_label, test_data,test_label):data = pd.concat([test_data, test_label], axis=1)data = data.reset_index(drop=True)df_filled = data.dropna()return df_filled.drop('质量评分', axis=1), df_filled.质量评分#----------------使用平均值的方法对数据进行填充----------------def mean_train_method(data):# 使用该类别每列的均值替换缺失值return data.fillna(data.mean())def mean_train_fill(train_data, train_label):# 合并特征和标签,方便按照类别分组处理data = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)# 遍历每个类别(假设类别编号为 0,1,2,3),# 对每个类别单独进行均值填充filled = [mean_train_method(data[data['质量评分'] == i]) for i in range(3,9)]# 将所有类别数据拼接在一起,并重新排序索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回特征数据和对应标签return df_filled.drop('质量评分', axis=1), df_filled['质量评分']def mean_test_method(train_data, test_data):# 用训练集该类别的均值填充对应类别的测试集缺失值return test_data.fillna(train_data.mean())def mean_test_fill(train_data, train_label, test_data, test_label):# 合并特征和标签,方便操作train_all = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)test_all = pd.concat([test_data, test_label], axis=1).reset_index(drop=True)# 按类别分别取出训练集和测试集,并进行均值填充filled = [mean_test_method(train_all[train_all['质量评分'] == i], # 当前类别的训练数据test_all[test_all['质量评分'] == i] # 当前类别的测试数据)for i in range(3,9)]# 拼接所有类别的数据,并重新排序索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回填充后的测试特征数据和标签return df_filled.drop('质量评分', axis=1), df_filled['质量评分']#-------------------------------使用中位数的方法对数据进行填充-----------------------------------
def median_train_method(data):# 获取每列的中位数,并用其填充缺失值fill_values = data.median()return data.fillna(fill_values)def median_train_fill(train_data, train_label):# 合并特征数据和标签数据data = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)# 按照“矿物类型”分类,每一类数据使用中位数填充filled = [median_train_method(data[data['质量评分'] == i]) for i in range(3,9)]# 将填充后的数据拼接起来,并重置索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回填充后的数据和矿物类型标签return df_filled.drop('质量评分', axis=1), df_filled['质量评分']def median_test_method(train_data, test_data):# 使用训练集的中位数填充测试集的缺失值fill_values = train_data.median()return test_data.fillna(fill_values)def median_test_fill(train_data, train_label, test_data, test_label):# 合并训练集和测试集的特征数据和标签train_all = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)test_all = pd.concat([test_data, test_label], axis=1).reset_index(drop=True)# 按“矿物类型”进行分类filled = [median_test_method(train_all[train_all['质量评分'] == i], # 当前类别的训练数据test_all[test_all['质量评分'] == i] # 当前类别的测试数据)for i in range(3,9)]# 拼接所有类别的数据,并重新索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回填充后的测试数据和矿物类型标签return df_filled.drop('质量评分', axis=1), df_filled['质量评分']#----------------使用众数的方法对数据进行填充----------------
def mode_train_method(data):# 获取每列的众数,如果有多个众数,选择第一个fill_values = data.apply(lambda x: x.mode().iloc[0] if len(x.mode()) > 0 else None)# 使用众数填充缺失值return data.fillna(fill_values)def mode_train_fill(train_data, train_label):# 合并特征数据和标签数据data = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)# 按照“矿物类型”分类并分别填充filled = [mode_train_method(data[data['质量评分'] == i]) for i in range(3,9)]# 将填充后的数据拼接起来,并重置索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回填充后的数据和矿物类型标签return df_filled.drop('质量评分', axis=1), df_filled['质量评分']def mode_test_method(train_data, test_data):# 使用训练集的众数填充测试集的缺失值fill_values = train_data.apply(lambda x: x.mode().iloc[0] if len(x.mode()) > 0 else None)return test_data.fillna(fill_values)def mode_test_fill(train_data, train_label, test_data, test_label):# 合并训练集和测试集的特征数据和标签train_all = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)test_all = pd.concat([test_data, test_label], axis=1).reset_index(drop=True)# 按“矿物类型”进行分类filled = [mode_test_method(train_all[train_all['质量评分'] == i], # 当前类别的训练数据test_all[test_all['质量评分'] == i] # 当前类别的测试数据)for i in range(3,9)]# 拼接所有类别的数据,并重新索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回填充后的测试数据和矿物类型标签return df_filled.drop('质量评分', axis=1), df_filled['质量评分']# -----------线性回归算法实现训练数据集,测试数据集的填充----------
def lr_train_fill(train_data,train_label):'''使用线性回归填充训练数据集中的缺失值,主要是基于这样一个思想:特征和目标变量之间存在一定的关系,因此可以利用这种关系对缺失的特征进行预测。以下是使用线性填充缺失值的一般步骤:1、首先,确定哪些特征包含缺失值。2、对于包含缺失值的特征,将其作为目标变量,而其他特征(可以包括原始的目标变量)作为输入特征。注意,如果多个特征都有缺失值,通常建议按照缺失值的数量从小到大进行处理。因为缺失值较少的特征对预测的要求较低,准确性可能更高。3、在处理某个特征的缺失值时,将该特征中的已知值(即非缺失值)作为训练集,而缺失值作为需要预测的目标。此时,其他特征的相应值作为输入特征。4、使用线性回归模型进行训练,并对缺失值进行预测。5、将预测得到的值填充到原始数据中的相应位置。6、重复上述步骤,直到处理完所有包含缺失值的特征。需要注意的是,使用线性回归填充缺失值时,可能会受到模型选择和过拟合等因素的影响。因此,在实际应用中,建议对数据进行适当的预处理,如特征选择、异常值处理等,以提高填充的准确性和稳定性。同时,也可以使用交叉验证等方法来评估填充的效果。'''train_data_all = pd.concat([train_data, train_label], axis=1)train_data_all = train_data_all.reset_index(drop=True)train_data_X = train_data_all.drop('质量评分', axis=1)null_num = train_data_X.isnull().sum() # 查看每个特中存在空数据的个数null_num_sorted = null_num.sort_values(ascending=True) # 将空数据的类别从小到大进行排序filling_feature = [] # 用来存储需要传入模型的特征名称for i in null_num_sorted.index:filling_feature.append(i)if null_num_sorted[i] != 0: # 当前特征是否有空缺的内容。用来判断是否开始训练模型X = train_data_X[filling_feature].drop(i, axis=1) # 构建训练集y = train_data_X[i] # 构建测试集row_numbers_mg_null = train_data_X[train_data_X[i].isnull()].index.tolist() # 获取空数据对应行号X_train = X.drop(row_numbers_mg_null) # 非空的数据作为训练数据集y_train = y.drop(row_numbers_mg_null) # 非空的标签作为训练标签X_test = X.iloc[row_numbers_mg_null] # 空的数据作为测试数据集regr = LinearRegression() # 创建线性回归模型regr.fit(X_train, y_train) # 训练模型y_pred = regr.predict(X_test) # 使用模型进行预测train_data_X.loc[row_numbers_mg_null, i] = y_predprint('完成训练数据集中的{}列数据的填充'.format(i))return train_data_X, train_data_all['质量评分']def lr_test_fill(train_data,train_label, test_data,test_label):'''使用随机森林算法对测试数据集中缺失的数据进行填充,主要是基于这样一个思想:根据已经填充后的训练数据集建立模型,来补充空缺的测试数据集。'''train_data_all = pd.concat([train_data,train_label], axis=1)train_data_all = train_data_all.reset_index(drop=True)test_data_all = pd.concat([test_data, test_label], axis=1)test_data_all = test_data_all.reset_index(drop=True)train_data_X = train_data_all.drop('质量评分', axis=1) #多余。test_data_X = test_data_all.drop('质量评分', axis=1)null_num = test_data_X.isnull().sum()null_num_sorted = null_num.sort_values(ascending=True)filling_feature = []for i in null_num_sorted.index:filling_feature.append(i)if null_num_sorted[i] != 0:y_train = train_data_X[i]X_test = test_data_X[filling_feature].drop(i, axis=1)row_numbers_mg_null = test_data_X[test_data_X[i].isnull()].index.tolist()X_train = train_data_X[filling_feature].drop(i, axis=1).drop(row_numbers_mg_null) # 非空的训练数据集y_train = y_train.drop(row_numbers_mg_null) # 非空的训练标签X_test = X_test.iloc[row_numbers_mg_null] # 空的测试数据集regr = RandomForestRegressor() # 创建随机森林回归模型regr.fit(X_train, y_train) # 训练模型y_pred = regr.predict(X_test) # 使用模型进行预测test_data_X.loc[row_numbers_mg_null, i] = y_pred # pandas.loc[3,4]print(f'完成测试数据集中的{i}列数据的填充')return train_data_X, train_data_all['质量评分']#-----------随机森林算法实现训练数据集、测试数据集的填充-----------
def rf_train_fill(train_data,train_label):train_data_all = pd.concat([train_data, train_label], axis=1)train_data_all = train_data_all.reset_index(drop=True)#data数据行号存在混乱(因随机抽取70%的数train_data_X = train_data_all.drop('质量评分', axis=1)null_num = train_data_X.isnull().sum() #查看每个种中存在空数据的个数null_num_sorted = null_num.sort_values(ascending=True)#将空数据的类别从小到大进行排序filling_feature = []for i in null_num_sorted.index:filling_feature.append(i)if null_num_sorted[i] != 0:X = train_data_X[filling_feature].drop(i, axis=1)y = train_data_X[i]row_numbers_mg_null = train_data_X[train_data_X[i].isnull()].index.tolist()# 获取空数据对应行号 row_numX_train = X.drop(row_numbers_mg_null) # 非空的数据作为训练数据集y_train = y.drop(row_numbers_mg_null) # 非空的标签作为训练标签X_test = X.iloc[row_numbers_mg_null] # 空的数据作为测试数据集regr = RandomForestRegressor(n_estimators=100, random_state=42) # 创建随机森林回归模型regr.fit(X_train, y_train) # 训练模型y_pred = regr.predict(X_test) # 使用模型进行预测 y_pred: [-0.02019263]train_data_X.loc[row_numbers_mg_null, i] = y_pred# loc和iloc的区别: iloc[行号,列号] loc[行名, 列名],例如iloprint('完成训练数据集中的{}列数据的填充'.format(i))return train_data_X, train_data_all['质量评分']def rf_test_fill(train_data,train_label, test_data,test_label):'''使用随机森林算法对测试数据集中缺失的数据进行填充,主要是基于这样一个思想:根据已经填充后的训练数据集建立模型,来补充空缺的测试数据集。'''train_data_all = pd.concat([train_data,train_label], axis=1)train_data_all = train_data_all.reset_index(drop=True)test_data_all = pd.concat([test_data, test_label], axis=1)test_data_all = test_data_all.reset_index(drop=True)train_data_X = train_data_all.drop('质量评分', axis=1) #多余。test_data_X = test_data_all.drop('质量评分', axis=1)null_num = test_data_X.isnull().sum()null_num_sorted = null_num.sort_values(ascending=True)filling_feature = []for i in null_num_sorted.index:filling_feature.append(i)if null_num_sorted[i] != 0:y_train = train_data_X[i]X_test = test_data_X[filling_feature].drop(i, axis=1)row_numbers_mg_null = test_data_X[test_data_X[i].isnull()].index.tolist()X_train = train_data_X[filling_feature].drop(i, axis=1).drop(row_numbers_mg_null) # 非空的训练数据集y_train = y_train.drop(row_numbers_mg_null) # 非空的训练标签X_test = X_test.iloc[row_numbers_mg_null] # 空的测试数据集regr = RandomForestRegressor(n_estimators=100, random_state=42)regr.fit(X_train, y_train) # 训练模型y_pred = regr.predict(X_test) # 使用模型进行预测test_data_X.loc[row_numbers_mg_null, i] = y_pred # pandas.loc[3,4]print(f'完成测试数据集中的{i}列数据的填充')return train_data_X, train_data_all['质量评分']使用多种模型训练
import pandas as pd
import numpy as np
from sklearn.metrics import r2_score
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor, AdaBoostRegressor
from sklearn.svm import SVR
import xgboost as xgb
import os# 数据处理方法与对应文件路径
directory = {'删除不完整数据行': ['temp_data/1、训练数据集[缺失值删除].xlsx', 'temp_data/1、测试数据集[缺失值删除].xlsx'],'中位数填充': ['temp_data/3、训练数据集[中位数填充].xlsx', 'temp_data/3、测试数据集[中位数填充].xlsx'],'众数填充': ['temp_data/4、训练数据集[众数填充].xlsx', 'temp_data/4、测试数据集[众数填充].xlsx'],'平均值填充': ['temp_data/2、训练数据集[平均值填充].xlsx', 'temp_data/2、测试数据集[平均值填充].xlsx'],'线性回归预测填充': ['temp_data/5、训练数据集[线性回归填充].xlsx', 'temp_data/5、测试数据集[线性回归填充].xlsx'],'随机森林预测填充': ['temp_data/6、训练数据集[随机森林填充].xlsx', 'temp_data/6、测试数据集[随机森林填充].xlsx']
}def train_evaluate_model(model, train_x, train_y, test_x, test_y):model.fit(train_x, train_y)train_pred = model.predict(train_x)test_pred = model.predict(test_x)return r2_score(train_y, train_pred), r2_score(test_y, test_pred)def load_data(train_path, test_path):train_data = pd.read_excel(train_path)test_data = pd.read_excel(test_path)train_x = train_data.drop('质量评分', axis=1)train_y = train_data['质量评分']test_x = test_data.drop('质量评分', axis=1)test_y = test_data['质量评分']return train_x, train_y, test_x, test_y, train_data, test_datadef main():# 创建结果保存目录if not os.path.exists('模型结果'):os.makedirs('模型结果')all_results = []models = {'LinearRegression': LinearRegression(),'RandomForestRegressor': RandomForestRegressor(),'SVR': SVR(),'AdaBoostRegressor': AdaBoostRegressor(),'XGBRegressor': xgb.XGBRegressor()}for method in directory:train_path, test_path = directory[method]try:train_x, train_y, test_x, test_y, train_data, test_data = load_data(train_path, test_path)# 保存原始数据信息data_info = {'处理方法': method,'训练集样本数': len(train_data),'测试集样本数': len(test_data),'特征列数': train_x.shape[1]}for model_name, model in models.items():train_r2, test_r2 = train_evaluate_model(model, train_x, train_y, test_x, test_y)print(f"{method} - {model_name}: 训练R^2 = {train_r2:.6f}, 测试R^2 = {test_r2:.6f}")print(model.predict([[7.3,0.45,0.36,5.9,0.074,12,87,0.9978,3.33,0.83,10.5]]))# 保存单条结果result = {'处理方法': method,'模型名称': model_name,'训练集R²': train_r2,'测试集R²': test_r2,'训练集样本数': len(train_data),'测试集样本数': len(test_data)}all_results.append(result)# 保存预测结果test_data[f'{model_name}_预测值'] = model.predict(test_x)# 保存带预测值的测试集数据test_data.to_excel(f'模型结果/{method}_测试集带预测值.xlsx', index=False)except FileNotFoundError as e:print(f"文件未找到,跳过 {method} 方法: {e}")continue# 转换为DataFrame并保存汇总结果results_df = pd.DataFrame(all_results)results_df.to_excel('模型结果/回归模型结果汇总.xlsx', index=False)results_df.to_csv('模型结果/回归模型结果汇总.csv', index=False)print("\n结果保存完成:")print("1. 各处理方法的测试集带预测值数据已保存到 '模型结果' 文件夹")print("2. 所有模型性能汇总已保存为 Excel 和 CSV 格式")if __name__ == "__main__":main()
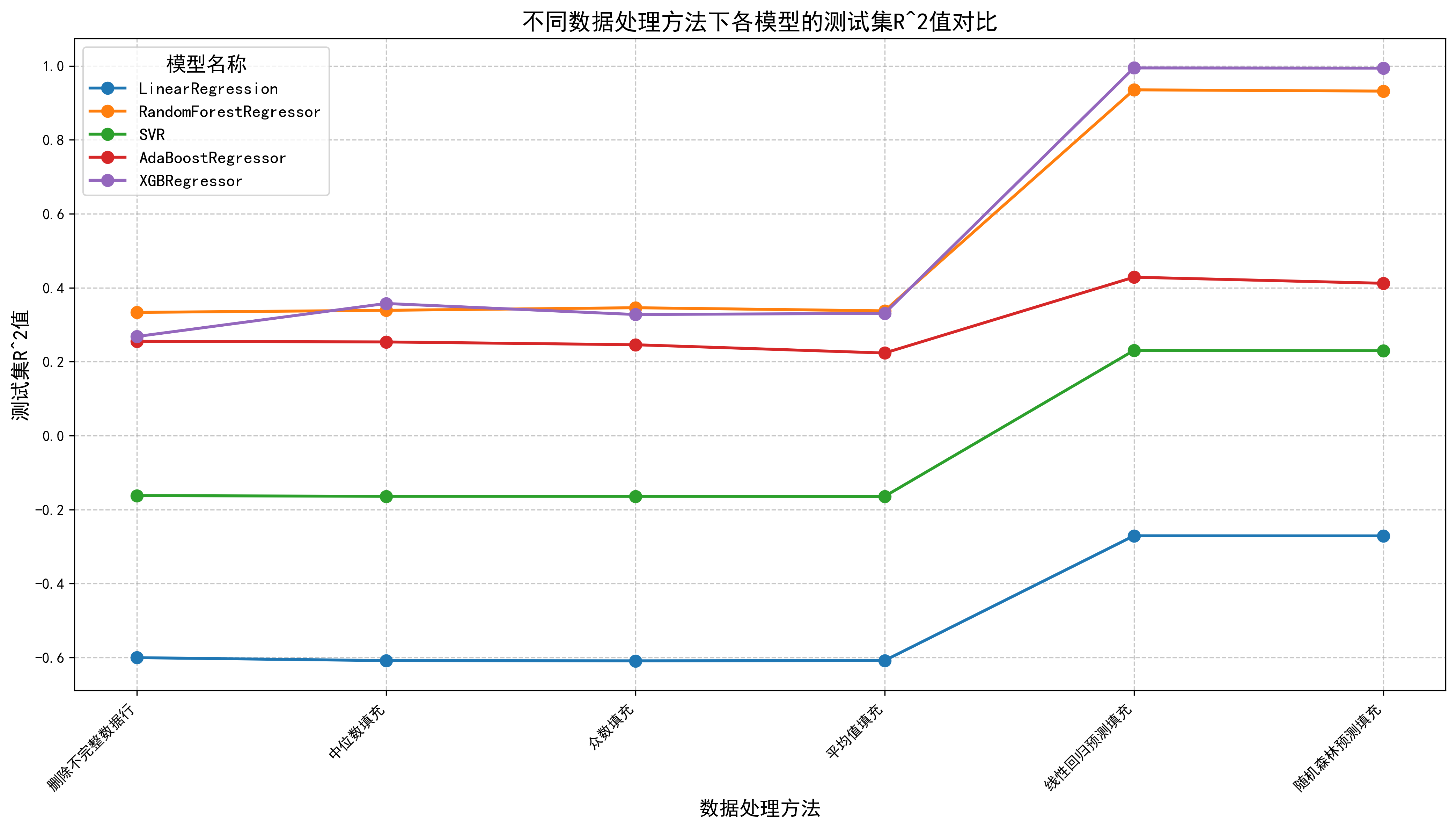
输出R^2(这里用回归做的,效果也还可以,但这还是个分类问题,回归到代码是给你们提供思路,后续会出一期分类的答案博客)
import pandas as pd
import numpy as np
from sklearn.metrics import r2_score
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor, AdaBoostRegressor
from sklearn.svm import SVR
import xgboost as xgb
import os# 数据处理方法与对应文件路径
directory = {'删除不完整数据行': ['temp_data/1、训练数据集[缺失值删除].xlsx', 'temp_data/1、测试数据集[缺失值删除].xlsx'],'中位数填充': ['temp_data/3、训练数据集[中位数填充].xlsx', 'temp_data/3、测试数据集[中位数填充].xlsx'],'众数填充': ['temp_data/4、训练数据集[众数填充].xlsx', 'temp_data/4、测试数据集[众数填充].xlsx'],'平均值填充': ['temp_data/2、训练数据集[平均值填充].xlsx', 'temp_data/2、测试数据集[平均值填充].xlsx'],'线性回归预测填充': ['temp_data/5、训练数据集[线性回归填充].xlsx', 'temp_data/5、测试数据集[线性回归填充].xlsx'],'随机森林预测填充': ['temp_data/6、训练数据集[随机森林填充].xlsx', 'temp_data/6、测试数据集[随机森林填充].xlsx']
}def train_evaluate_model(model, train_x, train_y, test_x, test_y):model.fit(train_x, train_y)train_pred = model.predict(train_x)test_pred = model.predict(test_x)return r2_score(train_y, train_pred), r2_score(test_y, test_pred)def load_data(train_path, test_path):train_data = pd.read_excel(train_path)test_data = pd.read_excel(test_path)train_x = train_data.drop('质量评分', axis=1)train_y = train_data['质量评分']test_x = test_data.drop('质量评分', axis=1)test_y = test_data['质量评分']return train_x, train_y, test_x, test_y, train_data, test_datadef main():# 创建结果保存目录if not os.path.exists('模型结果'):os.makedirs('模型结果')all_results = []models = {'LinearRegression': LinearRegression(),'RandomForestRegressor': RandomForestRegressor(),'SVR': SVR(),'AdaBoostRegressor': AdaBoostRegressor(),'XGBRegressor': xgb.XGBRegressor()}for method in directory:train_path, test_path = directory[method]try:train_x, train_y, test_x, test_y, train_data, test_data = load_data(train_path, test_path)# 保存原始数据信息data_info = {'处理方法': method,'训练集样本数': len(train_data),'测试集样本数': len(test_data),'特征列数': train_x.shape[1]}for model_name, model in models.items():train_r2, test_r2 = train_evaluate_model(model, train_x, train_y, test_x, test_y)print(f"{method} - {model_name}: 训练R^2 = {train_r2:.6f}, 测试R^2 = {test_r2:.6f}")print(model.predict([[7.3,0.45,0.36,5.9,0.074,12,87,0.9978,3.33,0.83,10.5]]))# 保存单条结果result = {'处理方法': method,'模型名称': model_name,'训练集R²': train_r2,'测试集R²': test_r2,'训练集样本数': len(train_data),'测试集样本数': len(test_data)}all_results.append(result)# 保存预测结果test_data[f'{model_name}_预测值'] = model.predict(test_x)# 保存带预测值的测试集数据test_data.to_excel(f'模型结果/{method}_测试集带预测值.xlsx', index=False)except FileNotFoundError as e:print(f"文件未找到,跳过 {method} 方法: {e}")continue# 转换为DataFrame并保存汇总结果results_df = pd.DataFrame(all_results)results_df.to_excel('模型结果/回归模型结果汇总.xlsx', index=False)results_df.to_csv('模型结果/回归模型结果汇总.csv', index=False)print("\n结果保存完成:")print("1. 各处理方法的测试集带预测值数据已保存到 '模型结果' 文件夹")print("2. 所有模型性能汇总已保存为 Excel 和 CSV 格式")if __name__ == "__main__":main()
绘制图像
import pandas as pd
import matplotlib.pyplot as plt
import os# 设置中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题def plot_regression_results():# 检查结果文件是否存在result_file = "模型结果/回归模型结果汇总.xlsx"if not os.path.exists(result_file):print(f"错误:未找到结果文件 {result_file}")print("请先运行模型训练代码生成结果文件")return# 读取结果数据df = pd.read_excel(result_file)# 创建图形plt.figure(figsize=(14, 8))# 按模型分组绘制折线图for model in df['模型名称'].unique():model_data = df[df['模型名称'] == model]plt.plot(model_data['处理方法'], model_data['测试集R²'],marker='o', label=model, linewidth=2, markersize=8)# 设置图表属性plt.title('不同数据处理方法下各模型的测试集R^2值对比', fontsize=16)plt.xlabel('数据处理方法', fontsize=14)plt.ylabel('测试集R^2值', fontsize=14)plt.xticks(rotation=45, ha='right') # 旋转x轴标签,避免重叠plt.grid(linestyle='--', alpha=0.7)plt.legend(title='模型名称', fontsize=12, title_fontsize=14)# 调整布局plt.tight_layout()# 保存图表if not os.path.exists('模型结果/图表'):os.makedirs('模型结果/图表')plt.savefig('模型结果/图表/各模型测试集R²对比折线图.png', dpi=300, bbox_inches='tight')print("折线图已保存至:模型结果/图表/各模型测试集R²对比折线图.png")# 显示图表plt.show()if __name__ == "__main__":plot_regression_results()