让机器人“想象”未来?VLN导航迎来“理解力”新升级
导读
在复杂未知的环境中,让机器人“听懂指令”并找到目标,一直是视觉语言导航(VLN)研究中的关键挑战。想象一下,机器人接到一句话:“走到客厅的沙发旁边”,它不仅要理解这句话的含义,还要将沿途看到的视觉信息转化为判断路线的依据。然而,目前的导航系统往往陷入“细节泥潭”——捕捉了过多的几何细节却忽视了整体语义结构,同时语言与视觉之间的对齐也存在偏差,导致导航行为容易偏离指令要求。
为了解决这一问题,本文提出了一种新的导航策略,核心在于两项创新机制:递归视觉想象(RVI)与自适应语言对齐(ALG)。RVI 能够帮助机器人逐步总结沿途的视觉变化,把握语义场景的整体结构;而 ALG 则提升了指令理解的精度,使机器人能更精准地将语言与所处环境对应起来。在多个标准任务中,这一策略显著优于当前主流方法,展示了从“记忆”与“对齐”双向提升导航智能的潜力。
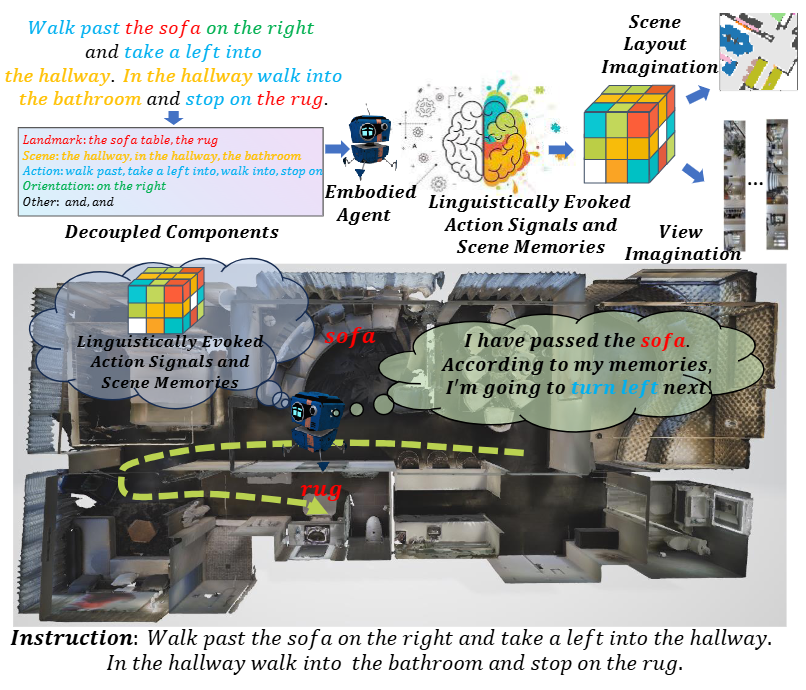
图1|该视觉语言导航(VLN)智能体会将一条导航指令解耦为多个组成部分,包括地标(landmarks)、场景(scenes)、动作(actions)、朝向(orientations)以及其他信息(others),并将这些成分自适应地与隐式场景表示(ISR)中的高层次场景先验进行对齐。经过预训练的ISR能够为导航提供所需的“思维能力”,包括视角想象和场景布局想象两种关键机制
论文出处:arXiv25
论文标题:Recursive Visual Imagination and Adaptive LinguisticGrounding for VisionLanguage Navigation
论文作者:Bolei Chen, Jiaxu Kang, Yifei Wang, Ping Zhong*, Qi Wu, Jianxin Wang

自然语言交互是具身人工智能长期追求的目标,因为它被认为是最直观的人机沟通方式之一。近年来,视觉语言导航(Vision Language Navigation, VLN)研究逐渐兴起,旨在让机器人在陌生的三维场景中,根据语言指令导航至目标物体或远处区域。现有的VLN方法已经在场景表示(Scene Representation)、视觉语言对齐、预训练辅助任务等方面取得了显著进展。它们普遍通过构建结构化的视觉表示,结合跨模态对齐方式,将视觉观测与语言指令对应起来,从而指导导航行为。
一些方法尝试将视觉特征投影到鸟瞰图或三维场景中,以保留精细的几何结构和语义信息,但这种表示往往过于冗余,反而干扰了语言与视觉的准确对应。相比之下,人类在导航中更关注地标语义与空间关系,而非细节纹理。研究还发现,冗余的视觉细节容易引起对语言指令的误解,导致导航行为偏离预期轨迹。传统的交叉注意机制很难在复杂场景中实现精确的指令对齐,进一步限制了导航策略的表现。
为此,本文提出一种新的导航策略,通过递归视觉想象(Recursive Visual Imagination, RVI)构建隐式场景表示(Implicit Scene Representation, ISR),并结合自适应语言对齐(Adaptive Linguistic Grounding, ALG)机制提升导航理解能力。RVI通过建模历史轨迹中的视觉变化,强化对未来视觉趋势的感知与当前语义布局的推理;ALG则借助语法分析与自监督学习,将不同语言成分(如地标、方向、动作)分别对齐至相应的记忆结构中。通过这些设计,智能体具备了“回忆过去、想象未来、理解当前”的导航思维能力。实验结果表明,该方法在VLN任务上取得了领先的表现,验证了RVI与ALG机制的有效性。
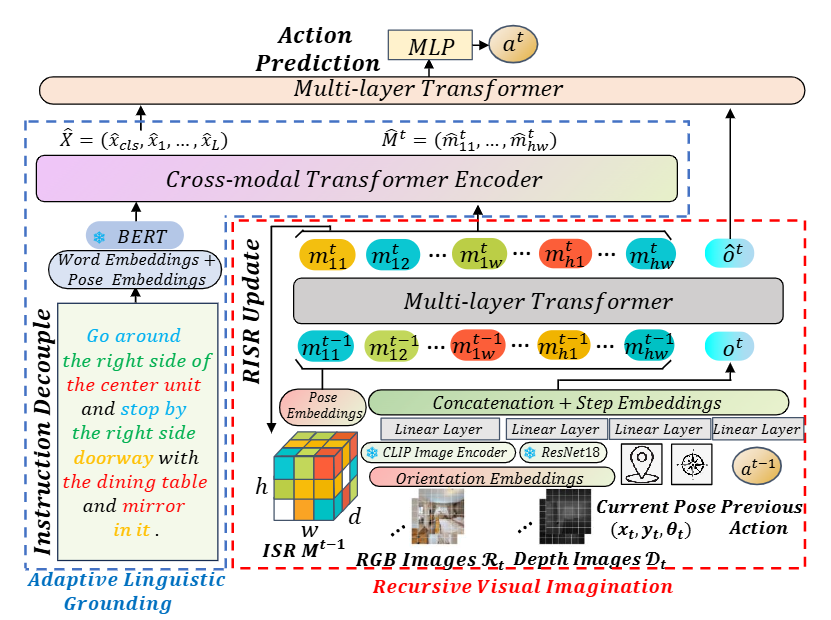
图2|全文方法总览:该方法将场景表示(SR)学习视为一个序列建模问题,并在完整的导航轨迹上训练一个联合的状态-动作Transformer模型。

本研究提出的导航策略核心在于两项关键机制:递归视觉想象(Recursive Visual Imagination, RVI)和自适应语言对齐(Adaptive Linguistic Grounding, ALG)。前者用于从隐式场景表示(Implicit Scene Representation, ISR)中提取高层语义布局,后者则负责将语言指令中的各类成分与ISR中的神经栅格精细对齐。
1. 递归视觉想象(RVI)
RVI包含三项子任务:
● 视图想象(View Imagination, VI):从当前帧出发,想象未来若干时间步中可能的视觉状态,而不是简单地预测未来帧。方法上,模型使用CLIP对历史图像进行编码,并通过Transformer网络查询特定姿态下的潜在视觉记忆。为了建模不确定的未来,该模块还引入两个MLP网络分别学习先验与后验分布,通过KL散度约束提升对未来变化的建模能力。
● 场景布局想象(Scene Layout Imagination, SLI):预测当前位置周围的语义地标和它们的空间分布。该任务使用一个多层感知器(MLP)从ISR中预测语义地图,并以二值交叉熵损失作为监督信号。
● 视觉语义预测(Visual Semantic Prediction, VSP):作为辅助任务,模型基于当前观测预测可见物体的类别及其占比,从而提高对语义特征的感知能力。
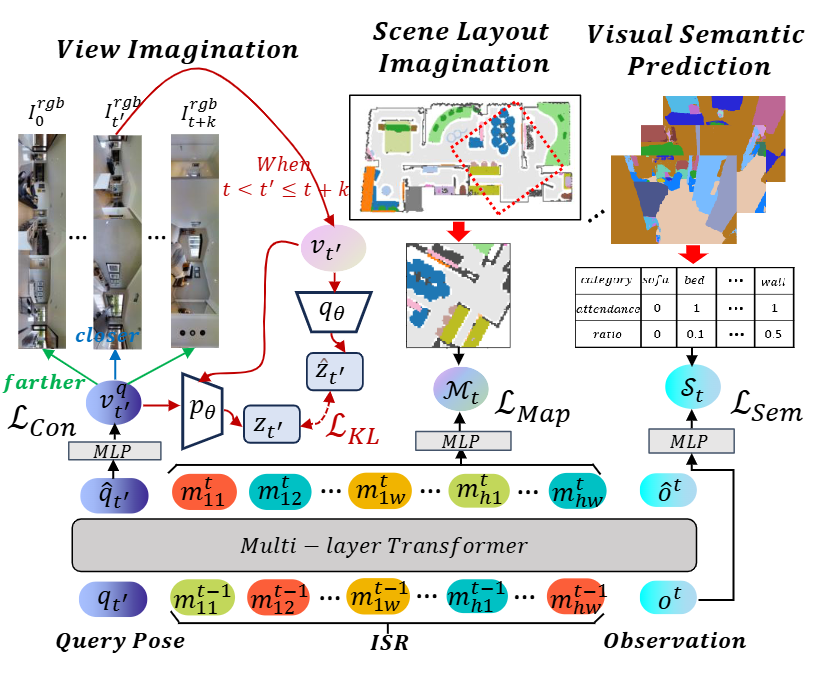
图3|图示展示了递归视觉想象(RVI)的三个核心模块,包括视角想象、场景布局想象以及视觉语义预测。
2. 自适应语言对齐(ALG)
ALG的目标是在不同时间动态调整语言与场景记忆之间的对齐方式,包括三个关键环节:
● 指令解耦(Instruction Decoupling):将语言指令解析为五类语义成分(地标、场景、动作、方向、其他),并将其位置编码为标签向量。通过跨模态注意力机制,模型为每类成分提取独立的语言特征,同时保留整体语义上下文。
● 导航进度跟踪(VLN Progress Tracking):通过一个MLP预测每个指令成分的执行进度,并结合当前位置与目标点之间的距离作为监督信号,从而动态突出已完成与待完成的指令内容。
● 位置与语义对齐(Position & Semantic Alignment):利用Transformer最后一层的注意力矩阵作为亲和度矩阵,自动匹配指令成分与ISR神经栅格之间的位置和语义关联。该模块采用两个损失函数:
○ 位置对齐损失:使ISR的关注位置与当前执行阶段的语言重点区域一致;
○ 语义对齐损失:通过对比学习强化地标与场景的语义相似性,同时拉远与动作、方向等成分的距离。
此外,该机制也支持反向操作,即将ISR主动关注于动作或方向等成分,在不同任务情境中实现灵活切换。
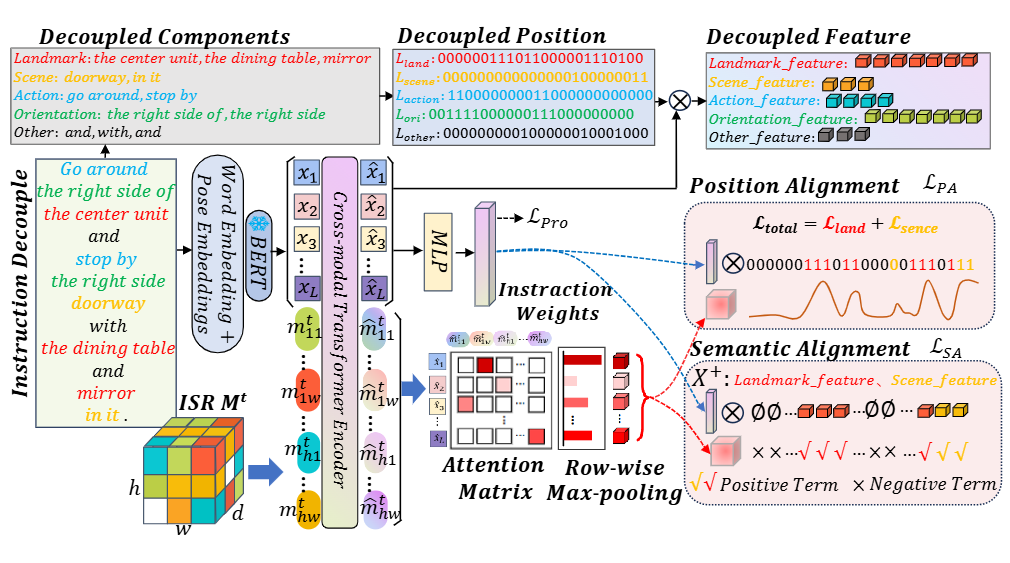
图4|图示展示了自适应语言对齐(ALG)模块的组成部分,包括指令解耦、导航进度跟踪以及语言对齐机制。
3. 预训练与微调策略
在预训练阶段,作者使用大规模轨迹数据进行行为克隆训练,采用交叉熵损失并对行为切换位置加权。总损失函数结合了动作预测、视觉预测(VI、SLI、VSP)和语言对齐模块的损失项。预训练完成后,利用 DAgger 策略进行微调,使模型能够更好适应与专家数据分布不同的测试场景。

实验设置与实现细节
本文在两个主流任务上验证所提出的导航策略:
1. R2R-CE:该数据集基于Matterport3D环境构建,包含90个真实场景与5,611条最短路径轨迹。评估主要集中在Val-Unseen和Test两个子集,均为训练阶段未见的场景。成功导航的定义为:机器人最终停下的位置距离目标点不超过3米。
2. Habitat ObjectNav:使用Habitat平台与MP3D数据集,包含21种目标类别,目标指令形式为“Please navigate to [object] and stay within 1 m of it.” 成功判定标准为停在目标1米内。
选择这两个任务的原因在于它们都要求智能体执行连续控制动作,更贴近实际应用场景,对语义建图和指令理解提出了更高要求。
评估指标包括:
● SR(Success Rate):成功率;
● OSR(Oracle SR):轨迹上任意点接近目标的频率;
● SPL(Success weighted by Path Length):在保证成功率的同时,衡量路径效率。
模型实现参数方面,Transformer采用4层、8头注意力结构,ISR尺寸设为 $10 \times 10$,通道维度为512,其他关键超参如对比损失温度,想象步长,训练使用AdamW优化器,预训练100轮,微调50轮,分别在1张和4张3090显卡上完成。
与现有方法的对比
在R2R-CE任务上,作者与包括CM2、GridMM、ETPNav、Ego2-Map、GELA在内的多种导航模型进行了比较。相比之下,本文提出的基于隐式神经栅格的场景建模(ISR)与自适应语言对齐机制(ALG)在Val-Unseen和Test子集上都实现了最高性能。特别地,与通过TSR辅助未来视图预测的DREAMWALKER相比,本方法无需额外的结构建图模块,具有更好的可扩展性与导航效率。
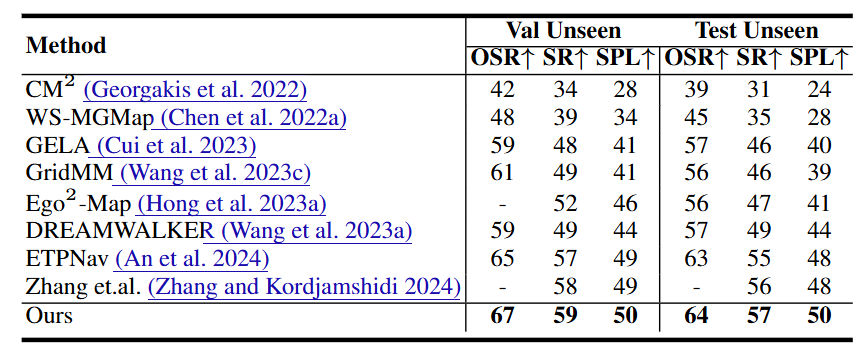
图5|R2RCE数据集实验结果
在ObjectNav任务中,本文方法同样超越了如HOZe++、NaviFormer(基于语义网格图)、VLFM(视觉特征场)、Ego2-Map、ECL、T-Diff等方法。值得注意的是,T-Diff采用轨迹扩散建模,SG-Nav引入大模型常识知识增强,但二者都未能取得与本文相当的性能。这表明,本文的视觉想象模块与语言对齐机制在需要细粒度控制的任务中具有更强的表现力。
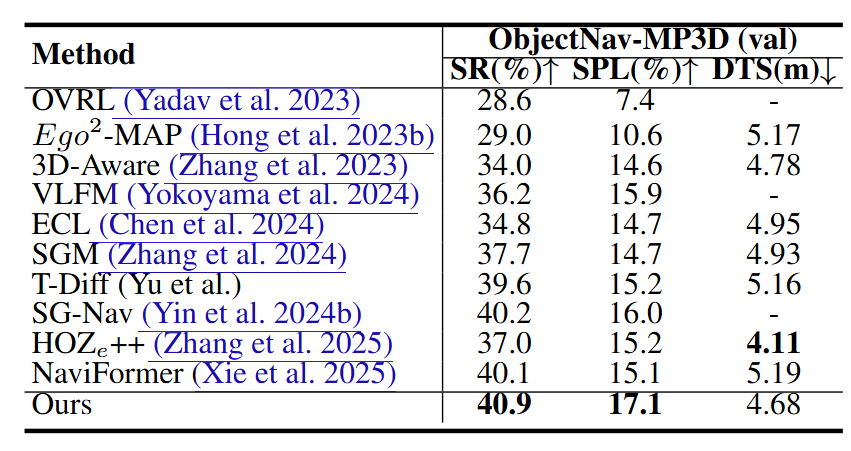
图6|MP3DObjNav数据集实验结果
消融实验分析
为探究各模块的有效性,作者设计了一系列消融实验。结果显示:
● 三项RVI子模块(视觉对比损失、KL损失、语义地图预测)均能单独提升性能;
● ALG模块中的位置对齐与语义对齐显著增强了SR、OSR、SPL等指标;
● 导航进度跟踪是ALG有效运行的关键,若移除该模块将导致性能显著下降。
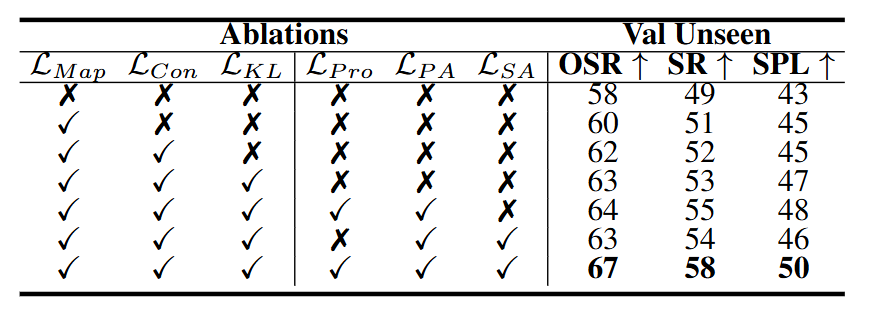
图7|消融实验结果
诊断分析与鲁棒性验证
● 指令跟踪效果分析:实验可视化发现,进度跟踪模块成功学会了根据导航进展调整对不同指令部分的关注程度,尤其能突出已执行的地标或动作相关语义。
● 超参敏感性分析:作者测试了视觉想象步长和ISR尺寸的不同设定。结果表明,视觉想象步长为20、ISR为10时性能最佳,但整体表现对这些参数不敏感,说明方法具有良好的鲁棒性。
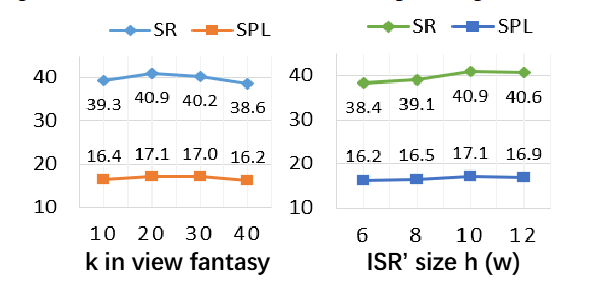
图8|超参数分析结果

本文聚焦于视觉语言导航(VLN)任务中的场景表示与指令理解问题。在场景表示方面,作者提出使用隐式场景表示(ISR)替代冗余的几何细节,从而让智能体学会建模视觉变化的规律与语义布局。换句话说,本文主张赋予导航智能体两种关键能力:(1)回忆过去、预测未来;(2)想象当前周围环境的语义结构。在语言理解方面,作者提出将ISR与指令中的不同组成部分进行位置级与语义级的自适应对齐,以替代模糊的视觉-语言匹配方式。丰富的对比实验与消融实验验证了所提方法在准确性与泛化能力上的优越性。未来,作者计划将多模态大模型引入零样本VLN场景,进一步提升智能体的泛化能力。