Maxwell学习笔记
Maxwell
最新不知道记录些什么,本来说是写一个整理浏览器书签的笔记,浏览器的书签实在太乱了,注册了太多官网的账号,收藏了好多别人写的博客文章,资源等等,有用的没用的好几百个,有的时候找起来太费时间了。想用一些工具去分类整理一下的,但是没有找到合适的产品。所以就没写成,于是乎就整理了一下之前写的关于maxwell数据同步的笔记。
一、Maxwell简介
Maxwell是一款开源的MySQL数据同步工具,通过实时读取MySQL的binlog日志,将数据变更以JSON格式发送至Kafka、RabbitMQ等流数据处理平台,支持全量与增量同步,适用于各种ETL、缓存维护等场景。
官网地址:https://maxwells-daemon.io/
核心优点:
- 轻量级:无需依赖额外组件,直接输出JSON数据,简化下游处理。
- 易用性:相比Canal等工具,无需编写客户端解析数据。
- 灵活性:支持按库、表、列分区,解决数据倾斜问题。
二、Maxwell原理
Maxwell的工作原理是实时读取MySQL数据库的二进制日志(Binlog),从中获取变更数据,再将变更数据以JSON格式发送至Kafka等流处理平台。
Maxwell伪装为MySQL的从库(Slave),通过主从复制协议捕获binlog事件,解析后转换为JSON格式输出
输出说明
maxwell输出数据格式有三种。对应得json中type分别为insert,update,delete。插入删除格式如下,不同的是type,更新时或多出一个old属性记录更改前的数据值。
{"database":"test","table":"test","type":"insert","ts":1477053217,"xid":23396,"commit":true,"data":{"id":1,"name":'zs'}
}
| 字段 | 解释 |
|---|---|
| database | 变更数据所属的数据库 |
| table | 表更数据所属的表 |
| type | 数据变更类型 |
| ts | 数据变更发生的时间 |
| xid | 事务id |
| commit | 事务提交标志,可用于重新组装事务 |
| data | 对于insert类型,表示插入的数据;对于update类型,标识修改之后的数据;对于delete类型,表示删除的数据 |
| old | 对于update类型,表示修改之前的数据,只包含变更字段 |
二进制日志
在MySQL中,二进制日志(Binary Log)是一种用于记录所有修改了数据库数据的操作(不包括SELECT和SHOW这类操作)的日志文件。它主要用于复制和数据恢复。启用二进制日志可以帮助你进行数据的复制和恢复,尤其是在使用MySQL复制或进行数据灾难恢复时。
主从复制
MySQL的主从复制就是,通过主数据库的二进制日志去建立一个与主数据库环境一样的从数据库。
主从应用场景
- 做数据库的热备:主数据库服务器故障后,可切换到从数据库继续工作。
- 读写分离:主数据库只负责业务数据的写入操作,而多个从数据库只负责业务数据的查询工作,在读多写少场景下,可以提高数据库工作效率。
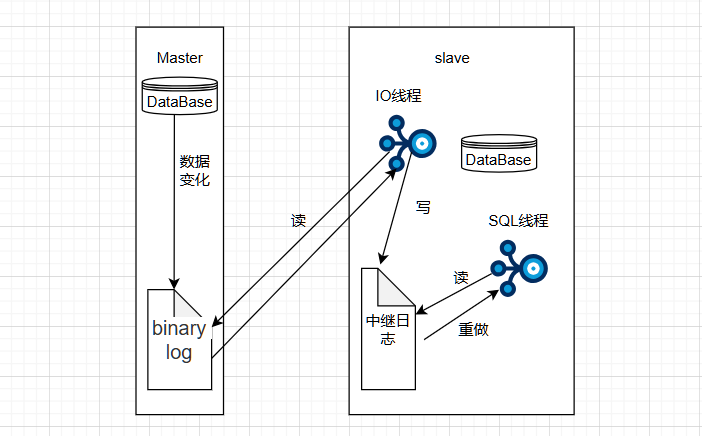
主从复制原理
- Master主库将数据变更记录,写到二进制日志(binary log)中
- Slave从库向mysql master发送dump协议,将master主库的binary log 通过IO线程将它写入中继日志(relay log)
- Slave从库的SQL线程解析中继日志中的事件并执行,完成数据同步
主从复制如下图:
三、Maxwell部署
maxwell官方提供了多种安装方式,源码,docker等。在安装Maxwell前需要配置MySQL。
配置MySQL
1、启用MySQL的binlog,修改MySQL的配置文件如下 /etc/my.cnf
[mysqld]
#数据库id
server-id = 1
#启动binlog,该参数的值会作为binlog的文件名
log-bin=mysql-bin
#binlog类型,maxwell要求为row类型
binlog_format=row
#启用binlog的数据库,需根据实际情况作出修改
binlog-do-db=test
binlog的类型有三种分别为row,statement和mixed
row:基于行,Binlog会记录每次写操作后被操作行记录的变化。优点是保持数据的绝对一致性。缺点是占用较大空间。
statement:基于语句,Binlog会记录所有写操作的SQL语句,包括insert、update、delete等。优点是节省空间。缺点是有可能造成数据不一致,例如insert语句中包含now()函数。
mixed:混合模式,默认是statement,如果SQL语句可能导致数据不一致,就自动切换到row。
Maxwell要求MySQL的binlog必须是row模式。
修改完配置以后需要重启数据库服务。
2、创建Maxwell数据库用户
Maxwell需要在MySQL中存储其运行过程中的所需的一些数据,包括binlog同步的断点位置(Maxwell支持断点续传)等等,故需要在MySQL为Maxwell创建数据库及用户。
CREATE DATABASE maxwell; #创建数据库set global validate_password_policy=0; #设置密码的安全级别
set global validate_password_length=4;CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell'; 创建maxwell用户并为其赋予权限
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
安装运行
源码安装
curl -sLo - https://github.com/zendesk/maxwell/releases/download/v1.41.2/maxwell-1.41.2.tar.gz \| tar zxvf -
cd maxwell-1.41.2
该软件是使用Java开发的,会依赖Java的环境,再此之前需要安装Java的环境
在解压完以后,可以直接用过bin目录中的脚本文件启动maxwell。
bin/maxwell --user='maxwell' --password='XXXXXX' --host='127.0.0.1' --producer=stdout
以上dome是指将数据库的数据直接通过maxwell同步以后,输出到控制台。该项一般只是做测试使用
或者是直接通过命令行去启动一个将数据同步到kafka的进程
bin/maxwell --user='maxwell' --password='XXXXXX' --host='127.0.0.1' \--producer=kafka --kafka.bootstrap.servers=localhost:9092 --kafka_topic=maxwell
–user: 数据库的用户名
–password:数据库的密码
–host:数据库所在服务器的ip地址
–producer=指定将数据同步到哪里,例如:kafka、nats、pubsub、bigquery、rabbitmq、redis等
1、若是同步到kafka需要指定kafka集群的ip和端口号,以及主题
2、若是将数据同步到Google Cloud Pub/Sub平台需要指定pubsub_project_id和主题
所需要同步的平台根据官方给出的信息配置即可。
上面是通过命令行的方式去同步的数据,接下介绍的是使用maxwell配置文件去启动守护进程将数据同步到kafka。
log_level=info
producer=kafka #指定将数据同步到kafka
kafka.bootstrap.servers=192.168.128.4:9092,192.168.128.5:9092 #kafka集群的地址,可以写多个#kafka topic配置
kafka_topic= kafka_topic_name #kafka集群中的主题名# mysql的信息
host=192.168.128.16 #MySQL所在服务器IP
user=maxwell #MySQL用户名
password=maxwell #MySQL密码
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
若是自己搭建kafka需要注意的是2.8版本以下的kafka是依赖于zookeeper的所以需要在linux上安装zookeeper。
kafka_topic: 可以静态配置,如maxwell_test,或者是直接使用动态配置去%{database}_%{table}。则在kafka中的主题名为"数据库名 下划线 表名" 如:trade_order。
配置完成后启动maxwell,在启动前确保kafak集群已经启动。
/bin/maxwell --config maxwell/config.properties --daemon
通过该命令启动maxwell以后,会在后台新建一个名叫maxwell的守护程序,可以 ps -ef | grep maxwell 去查看。也可以用过jps去查看。启动完成后,就会实时同步增量数据。
maxwell没有写停止的脚本,只能通过kill去杀掉后台进程,停止maxwell。
ps -ef | grep maxwell | grep -v grep | grep maxwell | awk '{print $2}' | xargs kill -9
或者是直接使用docker去快速部署一个maxwell应用,将MySQL的数据同步到kafka
docker run -it --rm zendesk/maxwell bin/maxwell --user=$MYSQL_USERNAME \--password=$MYSQL_PASSWORD --host=$MYSQL_HOST --producer=kafka \--kafka.bootstrap.servers=$KAFKA_HOST:$KAFKA_PORT --kafka_topic=maxwell
kafka消息队列也可以使用docker快速搭建这里省略
有时只有增量数据是不够的,我们可能需要使用到MySQL数据库中从历史至今的一个完整的数据集。这就需要在进行增量同步之前,先进行一次历史数据的全量同步。这样就能保证得到一个完整的数据集。
Maxwell提供了bootstrap功能来进行历史数据的全量同步
bin/maxwell-bootstrap --database 数据库名 --table 表名 --config maxwell/config.properties
同步json中我们可以发现,type有bootstrap-start、bootstrap-insert、bootstrap-complete三种类型,其中bootstrap-start与bootstrap-complete是bootstrap开始和结束的标志,不包含任何数据,数据都存在于type为bootstrap-insert的类型中。