【深度学习】骨干网络(Backbone)
骨干网络(Backbone)就是一个深度神经网络中的“核心特征提取器”。
它就像人体的脊柱和中枢神经,负责从原始输入数据(如图片、文本、声音)中提取出越来越抽象和有用的特征(Feature),然后将这些特征传递给其他的“子网络”去完成具体的任务。
一、Backbone理解
一个生动的比喻:汽车零件检测流水线
想象一个自动化工厂要检测汽车图片中的零件(如车轮、车窗、车灯)。
- 原始输入:一张完整的汽车图片。
- 骨干网络(Backbone):就像流水线上的核心质检员团队。
- 第一个质检员(浅层网络)只看非常局部的细节,比如“这里有一条边缘是直的还是弯的?”“这里有个颜色块”。
- 第二个质检员(更深一层)会看稍微复杂的东西,比如“这几个边缘组合起来像个圆形”“这些颜色块组合像个纹理”。
- 后续的质检员(更深的层)看的东西越来越抽象:“哇,这个圆形的东西旁边有辐条,这很可能是个车轮!”“这个纹理和形状组合起来像车窗!”
- 最终,这个骨干网络团队输出了一份详细的“特征报告”,描述了图片中可能存在哪些高级部件以及它们的位置信息。
- 任务头(Head):流水线末端的专项工作组。
- 分类头(Classification Head):拿到“特征报告”后,直接得出结论:“这是一辆SUV”。
- 检测头(Detection Head):根据报告里描述的部件位置和类别,在图片上画出框并写上标签:“这里是车轮,这里是车窗”。
- 分割头(Segmentation Head):会更精细地标出每个像素属于哪个部件。
在这个比喻中,骨干网络(Backbone) 就是那个通用的、强大的核心质检团队,它不关心最终任务是分类还是检测,只负责产出高质量的特征。而任务头(Head) 是专门为特定任务定制的,负责根据特征做出最终决策。
技术性定义和关键点
- 核心功能:特征提取。它通过一系列卷积层、池化层、注意力机制等操作,将原始数据转换为多层次、多尺度的特征表示。
- 通常都是预训练模型:骨干网络很少从零开始训练(Scratch Training)。通常会在一个超大的数据集(如 ImageNet)上进行预训练,学习到强大的通用特征提取能力。然后,我们可以把这种能力迁移(Transfer Learning) 到自己的特定任务上(比如医学图像分析、卫星图像识别),只需要微调(Fine-tuning)即可,大大节省了时间和数据。
- 输出:骨干网络通常会输出一个或多个特征图(Feature Maps),这些特征图包含了输入数据的关键信息,供下游任务使用。
- 与“头部(Head)”的关系:
- Backbone + Head 是构建现代深度学习模型的标准范式。
- Backbone 是通用的,可以 plug-and-play(即插即用)。
- Head 是任务特定的,结构小巧灵活。
常见的骨干网络例子
- CNN 时代:
- VGGNet:结构简单,堆叠的 3x3 卷积,证明了“深度”的重要性。
- ResNet:引入了“残差连接”,解决了极深网络难以训练的问题,是里程碑式的作品,至今仍在广泛使用。
- DenseNet:每一层都与前面所有层相连,特征复用率极高。
- Transformer 时代:
- ViT (Vision Transformer):将用于NLP的Transformer架构引入计算机视觉,将图像切块进行处理,取得了巨大成功。
- Swin Transformer:引入了“滑动窗口”机制,让ViT能更高效地处理不同尺度的图像,成为新一代强大的骨干网络。
总结
| 特性 | 骨干网络 (Backbone) | 任务头 (Head) |
|---|---|---|
| 角色 | 特征提取专家 | 决策专家 |
| 功能 | 从数据中提取通用、多层次的特征 | 利用特征完成具体任务(分类、检测等) |
| 是否预训练 | 几乎总是 | 通常从零开始训练或轻微微调 |
| 通用性 | 高,一个骨干可用于多种任务 | 低,专为特定任务设计 |
| 例子 | ResNet, ViT, Swin Transformer | 几个全连接层(分类)、RPN网络(检测) |
所以,当“我们用ResNet-50作为骨干网络,在上面加了一个检测头来做目标检测”时,就是在利用ResNet-50强大的预训练特征提取能力,来为检测任务服务。
二、Backbone演进历程
Backbone 的结构主要随着深度学习领域的核心架构思想演变而发展。下图清晰地展示了这一演进历程:
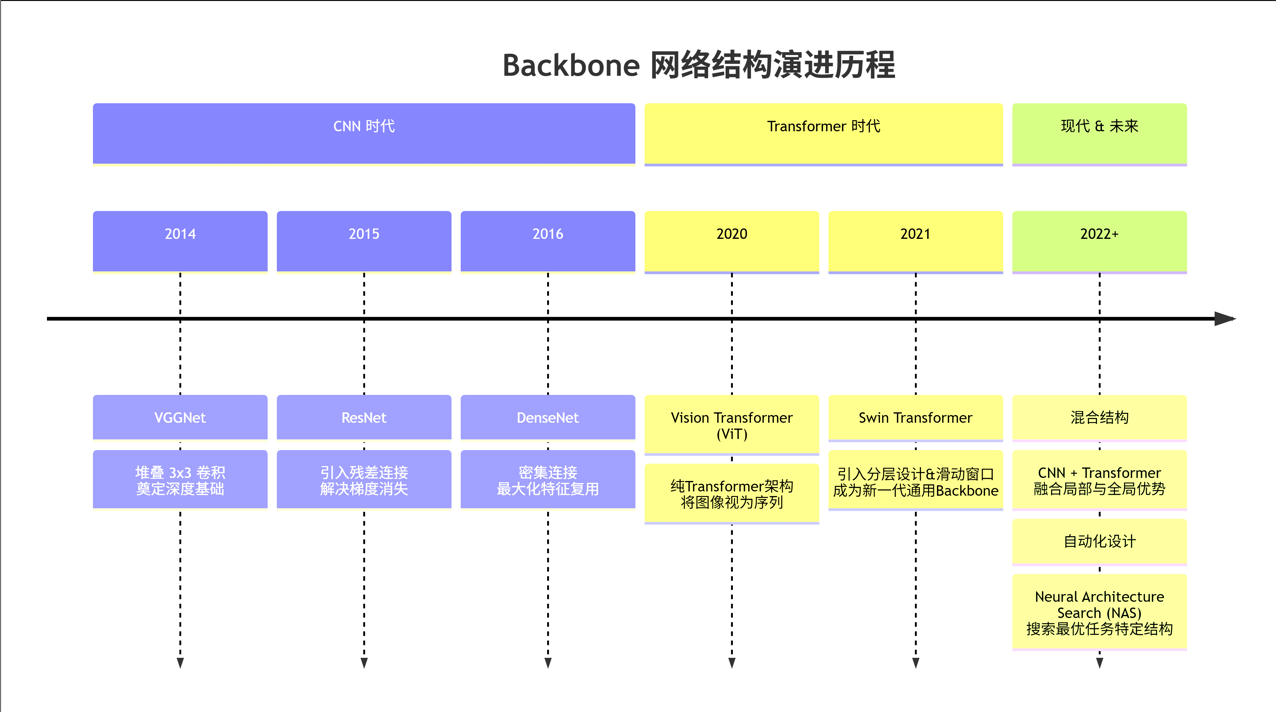
下面我们对这些主流的“结构范式”进行详细解释:
1. 基于卷积神经网络(CNN)的经典结构
这是最传统和成熟的一类,主要用于处理图像数据,其核心结构单元是卷积层和池化层。
- VGG式结构:非常直筒的结构。重复使用多个连续的 3x3 卷积层,然后接一个池化层进行下采样(降低分辨率、增加通道数),如此反复堆叠。
- 特点:结构简单、规整。但参数量大,后期训练较慢。
- ResNet式结构:引入了残差块(Residual Block) 和跳跃连接(Shortcut Connection)。这是里程碑式的设计,解决了深层网络的梯度消失问题,让网络可以做到上百层甚至上千层。
- 特点:这是目前最常用、最通用的Backbone结构之一(如ResNet-50, ResNet-101)。
- DenseNet式结构:比ResNet的连接更“密集”。每个层都会接收其前面所有层的输出作为输入,并将其输出传递给后面所有层。
- 特点:特征复用率极高,参数更高效,但更消耗显存。
2. 基于Transformer的结构
这类结构源自自然语言处理(NLP),后来被迁移到计算机视觉(CV)中,成为了新一代的Backbone霸主。
- ViT(Vision Transformer)结构:将输入图像切分成一个个图像块(Patch),然后将这些图像块视为类似NLP中的“词令牌(Token)”,直接送入标准的Transformer编码器(包含多头自注意力机制和前馈神经网络)中进行处理。
- 特点:打破了CNN的归纳偏置(局部性、平移不变性),依赖大规模数据预训练,在数据充足时性能极强。
- Swin Transformer结构:ViT的改进版。引入了分层结构和滑动窗口机制,使其可以像CNN一样逐步融合多尺度特征,并且计算复杂度大幅降低。
- 特点:结合了Transformer的强大表征能力和CNN的多尺度特性,成为了新一代通用的Backbone。
3. 基于神经架构搜索(NAS)的结构
这类结构没有“人造”的固定设计,而是让算法在巨大的搜索空间里自动寻找针对特定任务和硬件的最优结构。
- 代表:EfficientNet, NASNet, RegNet等。
- 特点:性能通常非常顶尖,但搜索过程计算成本极高,结构本身可解释性较差。最终搜索出来的结构往往也是由卷积、注意力等已知模块组合而成。
4. 混合结构(CNN + Transformer)
为了取长补短,将CNN的局部特征提取优势与Transformer的全局建模能力相结合。
- 代表:CoAtNet, UniFormer等。
- 特点:在浅层使用CNN提取局部细节特征,在深层使用Transformer建模全局依赖关系。这种结构目前非常流行。
总结:如何选择Backbone的结构?
虽然没有固定结构,但有最佳实践。选择Backbone时通常考虑:
- 任务类型:处理图像首选CNN或Vision Transformer变体;处理序列数据(文本、语音)首选Transformer。
- 数据量:数据量巨大时,ViT等Transformer架构潜力更大;数据量较少时,利用ImageNet预训练好的ResNet等CNN架构是更稳妥的选择。
- 硬件资源:移动端部署需要选择轻量级Backbone(如MobileNet, ShuffleNet,或搜索出的EfficientNet);服务器端则更追求性能,可以选择ResNet、Swin Transformer等大型模型。
- 性能与效率的权衡:在速度、精度、模型大小之间做取舍。