VAREdit:深度解读
这是一篇刚挂上Arxiv的好文,在翻阅的时候正好翻到,很有价值现在分享给诸位。
本文也仅作分享用途。
名称:Visual Autoregressive Modeling for Instruction-Guided Image Editing、
作者:Qingyang Mao, Qi Cai, Yehao Li, Yingwei Pan, Mingyue Cheng, Ting Yao, Qi Liu, Tao Mei
Arxiv链接:[2508.15772] Visual Autoregressive Modeling for Instruction-Guided Image Editing
TL;DR(要点速读)
-
范式转变:把“按指令编辑图像”从扩散模型的全局去噪,改为 视觉自回归(VAR) 的 “下一尺度预测(next-scale prediction)”。这种因果、可组合的生成机制更易做到“只改该改的地方”。
-
关键设计:SAR(Scale-Aligned Reference):只在 Transformer 第1层自注意力 注入与当前目标尺度 匹配 的源图像条件特征,解决“用细尺度条件去指导粗尺度预测”的失配问题。
-
效率与效果:在标准基准上 GPT-Balance 分数比主流扩散编辑方法高 30%+;512×512 编辑 1.2s,比相近规模的 UltraEdit 快 2.2×(论文报告)。官方仓库给出多尺度与多模型尺⼨下更细的时延与对比表。
-
开源可用:提供 512 / 1024 分辨率模型与推理脚本,可快速上手。
背景和动机:
指令式图像编辑 需要“精准修改 + 其他区域尽可能不动”。扩散模型虽在视觉质量上表现强,但其 全局去噪 容易让未编辑区域受到牵连,出现“不必要的变化”;同时多步采样带来 推理耗时。相对地,视觉自回归(VAR) 将图像视作 离散视觉 token/特征 的序列,按 粗→细 多尺度 自回归预测,天然具备 因果约束 与 可组合性,更契合“局部受控、全局保持”的编辑目标。
方法总览:
VAREdit 把 Instruction-guided Editing 形式化为 多尺度目标特征的条件自回归生成:
给定 源图像 与 文本指令,模型 逐尺度 预测“目标图像的多尺度特征/残差”,再解码成编辑后的图像。
核心挑战:如何在各尺度有效注入“源图像条件”? 论文发现 用最细尺度的源特征去指导更粗尺度的目标预测 常常不奏效,因此提出 SAR 模块:只在 第1层 self-attention 注入 与当前目标尺度匹配 的源特征,其余层则使用最细尺度的全局条件信息,兼顾 对齐 与 计算开销。
模型结构:
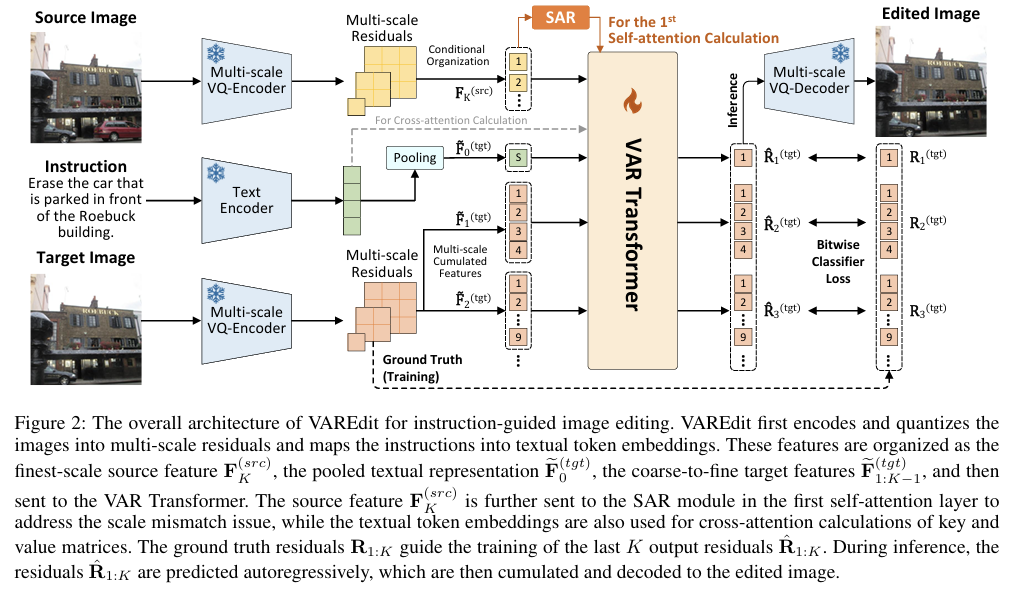
-
输入三元组
-
Target 多尺度序列:把目标图像在多个尺度上的特征/残差 按尺度展平 + 位置编码 + 尺度编码,在训练中用 teacher forcing 做自回归预测;推理时则自回归生成。
-
Source 条件特征:不拼到自回归序列里,而是作为 K/V 条件库 由 SAR 在第1层 self-attention 按尺度注入。
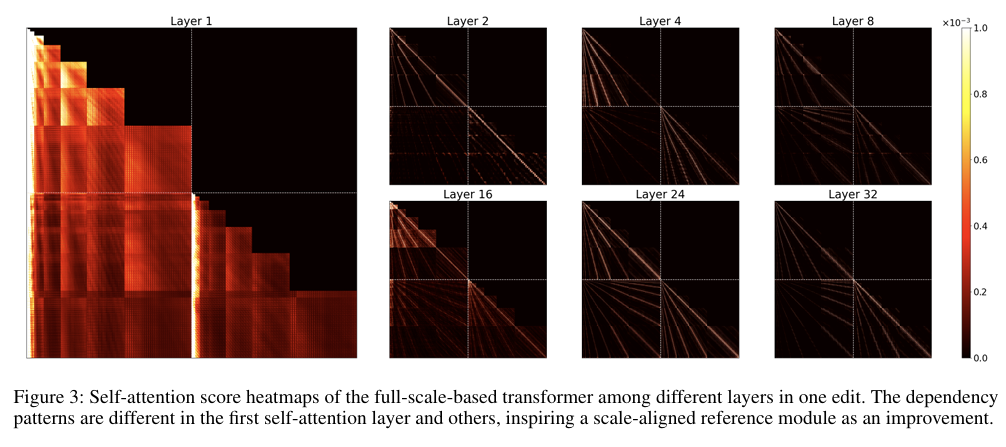
第一层self-attention导致了不同尺度图像的模糊 -
指令文本:文本编码得到句向量/序列,经 cross-attention 注入,使编辑“按指令行事”。
-
-
注意力掩码:对目标序列使用 causal mask,保证“只能看见过去,不偷看未来”。
-
层级安排:第1层 self-attn + SAR(尺度对齐),后续层保留(通常)最细尺度的全局源条件;每层后接 FFN 提升表征。
注:以上是论文框架在 Transformer 层级的职责划分与条件注入策略;模型将“下一尺度预测”作为基本递进单元。
训练流程
目标:在 Source + Instruction 条件下,学会 逐尺度 预测 Target 的特征/残差序列。
Step-by-Step:
1.数据准备
样本三元组:原图像、编辑后的目标图像、自然语言指令
编码:
原图像--------------->多尺度原特征(按照尺度组织)
目标图像------------>多尺度目标特征/残差(按尺度组织,作为监督)
指令------------------>文本嵌入(供cross-attention使用)
2.序列组织
- 将各尺度Target的token展平成统一序列(包含pos/scale embedding)
- teacher forcing:给定前缀token,预测下一个
- 因果编码:保证自回归训练一致性
3.条件注入
SAR(Scale-Aligned Reference):
在第一层Self-attention注入与当前目标尺度匹配的souce特征(K/V)
Cross-Attention:
注入指令文本条件
其余深层仅保留最细尺度的全局源条件,降低代价。
4.目标函数
-
将 Transformer 输出映射到该位置的 离散/量化视觉单元(token/bit-planes/索引等)的分类预测,采用 分类/交叉熵 类型监督;
-
多尺度联合反传(按尺度/位置平均或加权)。
具体 token 化与损失形态依赖实现;论文主体强调“多尺度目标特征的自回归预测”与 “SAR 的尺度对齐”。
5.优化与正则(工程建议)
-
Scheduled Sampling(可选):缓解纯 teacher-forcing 的暴露偏差;
-
Label Smoothing / Entmax(可选):平滑头部类的过拟合;
-
Scale-wise Curriculum(可选):先学粗层,再放开细层。
属工程经验,论文未强制要求。
5.推理流程
目标:只给 源图像 + 指令,逐尺度自回归生成 目标特征,再解码成编辑图像。
Step-by-Step:
-
源图像编码 → 得到 多尺度 Source 条件;指令编码 → 文本嵌入。
-
生成 F₁(最粗/下一个尺度):从起始 token 开始自回归,SAR 注入 F₁ 的 Source 条件 + 文本条件。
-
生成 F₂、F₃…(更细尺度):以已生成的粗尺度为上下文,SAR 注入对应尺度的 Source 条件,继续自回归。
-
解码:把多尺度目标特征/残差送入解码器/重建器,得到最终 Edited Image。
6.实验与表现

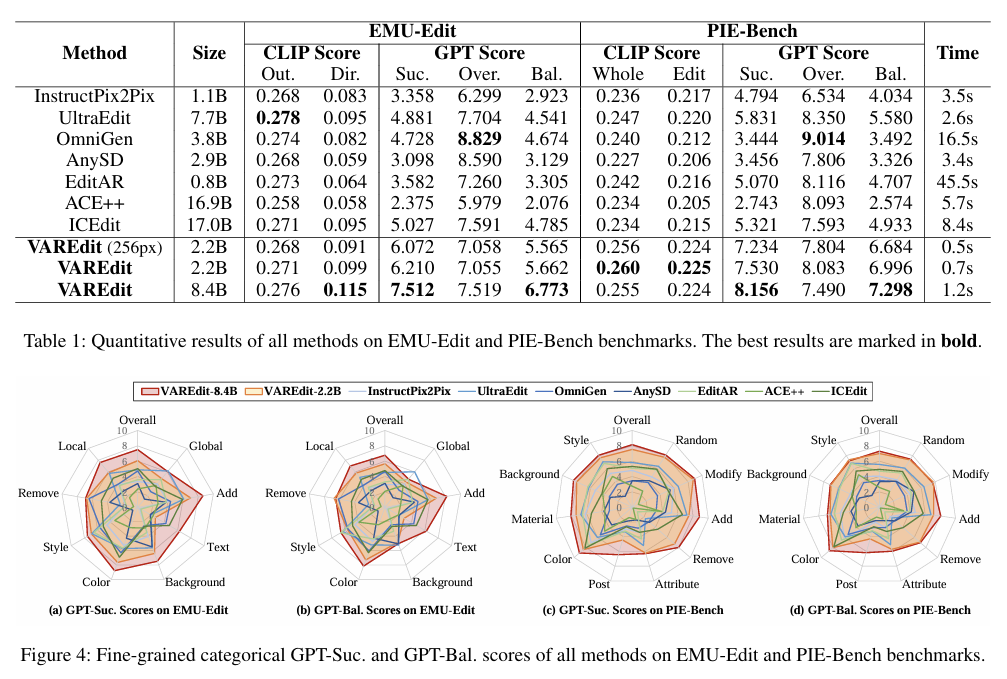
-
编辑遵从性:在公开基准上,VAREdit 的 GPT-Balance 分数比代表性扩散编辑方法 高 30%+。
-
速度:512×512 编辑 1.2 秒,2.2× 于相近规模的 UltraEdit(论文报告);官方仓库还报告了不同模型尺⼨/分辨率下的详细时间与多方法对比(如 EMU-Edit Bal., PIE-Bench Bal.)。
-
实现入口:官方 GitHub 提供 8B-512 / 8B-1024 等变体与推理脚本,可本地快速试跑
7.设计抉择与使用建议
-
为什么只在第1层注入 SAR?
第1层进行尺度对齐,既能最大化影响后续因果建模,又能节省计算;深层保留 最细尺度的全局源条件 作为稳定先验。 -
序列组织:分层 vs 混合
实践中更推荐 “逐尺度生成 + 因果掩码”:先把粗尺度预测完整,再进入更细尺度,收敛稳定、语义更连贯。 -
训练技巧
-
先 冻结文本编码器/视觉编码器,只训 Transformer 主干与输出头;
-
逐步 放开 finer-scale,或使用 scale-wise curriculum;
-
结合 Top-k / Nucleus 采样与温度退火,控制多样性与遵从性。
-
-
评测
论文报告 GPT-Balance 指标与速度;开源仓库包含 EMU-Edit / PIE-Bench 的平衡分数与多方法对比表,可作为落地评估基线。
8.小结
VAREdit 用 视觉自回归 + 下一尺度预测 重塑了“按指令编辑”的建模方式,并以 SAR 解决了 源条件的尺度注入 这一关键痛点:
它在 遵从性(少改不该改的地方)与 效率(一步到位的多尺度自回归)上取得均衡,提供了 强可复现的开源实现 与 明确的速度/效果证据,值得在实际系统中逐步替代部分扩散式编辑链路。
参考与资源:
论文:Visual Autoregressive Modeling for Instruction-Guided Image Editing(2025-08-21)。作者:Qingyang Mao 等。
代码与模型:HiDream-ai/VAREdit(README 含基准表、时延与快速上手示例)。
背景:Scalable Image Generation via Next-Scale Prediction(VAR, NeurIPS 2024)
相关:Training-Free Text-Guided Image Editing with VAR(AREdit)