【OpenAI】ChatGPT-4o-latest 真正的多模态、长文本模型的详细介绍+API的使用教程!
文章目录
- ChatGPT-4o-latest 详解
- 一、模型架构与基础参数
- 核心架构
- 参数规模
- 二、上下文窗口与处理能力
- 窗口尺寸
- Tokens 计算方式
- 三、训练数据与知识覆盖
- 数据规模与来源
- 数据时效性与预处理
- 四、多模态处理能力
- 视觉处理
- 音频处理
- 五、性能与效率参数
- 响应速度
- 计算效率
- 六、模型特点
- 七、如何获取ChatGPT-4o-latest 模型API
- 通过“OpenAI官网”获取API Key(国外)
- 1、访问OpenAI官网
- 2、生成API Key
- 3、使用 OpenAI API代码
- 通过“能用AI”获取API Key(国内)
- 1、访问能用AI工具
- 2、生成API Key
- 3、使用OpenAI API的实战教程
- (1).可以调用的模型
- (2).Python示例代码(基础)
- (3).Python示例代码(高阶)
- 更多文章
ChatGPT-4o-latest 详解
ChatGPT-4o-latest 作为领先的人工智能模型,以其卓越的性能和多模态处理能力引领行业发展。本文将深入解析其核心参数、模型架构、训练数据、多模态处理能力及应用领域,帮助您全面了解这一前沿技术。
一、模型架构与基础参数
核心架构
- 基于 Transformer v3 改进版架构,引入稀疏注意力机制(Sparse Attention),动态聚焦关键信息,提升长文本处理效率。
- 96 层 Encoder-Decoder 结构:
- Encoder 负责信息编码;
- Decoder 专注生成任务;
- 各层采用残差连接与层归一化(Layer Normalization),缓解梯度消失。
- 多头注意力机制:128 个注意力头,捕捉不同维度的语义关联(语法、逻辑、情感等),增强理解能力。
参数规模
- 总参数约 1750 亿 个。
- 组成比例:
- 注意力层参数约 45%;
- 前馈神经网络参数约 50%;
- 其他辅助参数约 5%。
- 采用混合精度训练(FP16 主,关键层保留 FP32),兼顾性能与计算资源。

二、上下文窗口与处理能力
窗口尺寸
- 输入上下文窗口最大支持 128,000 tokens(约 9.6 万字中文或 12.8 万字英文),可处理长篇小说、学术论文、多轮对话等。
- 输出窗口最大支持 16,384 tokens(约 1.2 万字中文),支持生成完整报告、代码文档等。
- 动态窗口机制:自动调整窗口优先级,优先保留关键信息。
Tokens 计算方式
- 中文以字/词为单位(1 汉字 ≈ 1 token,1 词语 ≈ 1-3 tokens)。
- 英文以子词(Subword)为单位(如 “unhappiness” 拆分为 “un-happi-ness”,计 3 tokens)。
- 多模态 token 转换:
- 图像:512×512 像素图片 ≈ 800-1200 tokens;
- 音频:1 分钟语音(16kHz)≈ 1500-2000 tokens。
三、训练数据与知识覆盖
数据规模与来源
- 总数据量:超过 200TB 文本 + 50TB 图像 + 30TB 音频。
- 文本来源:
- 书籍(学术专著、小说、科普)约 30%;
- 网页(新闻、论坛、博客)约 40%;
- 专业文档(论文、财报、法律)约 20%;
- 对话数据(人工标注、公开语料)约 10%。
- 多语种覆盖:支持 50+ 种语言,高资源语言占 70%,低资源语言通过迁移学习增强。
数据时效性与预处理
- 知识截止日期:2025 年 4 月,涵盖最新科研、新闻、文化事件。
- 预处理流程:
- 去重,保留唯一信息;
- 过滤有害与虚假内容,人工+AI双重审核;
- 多模态数据对齐(图片-文字-音频三元组)。
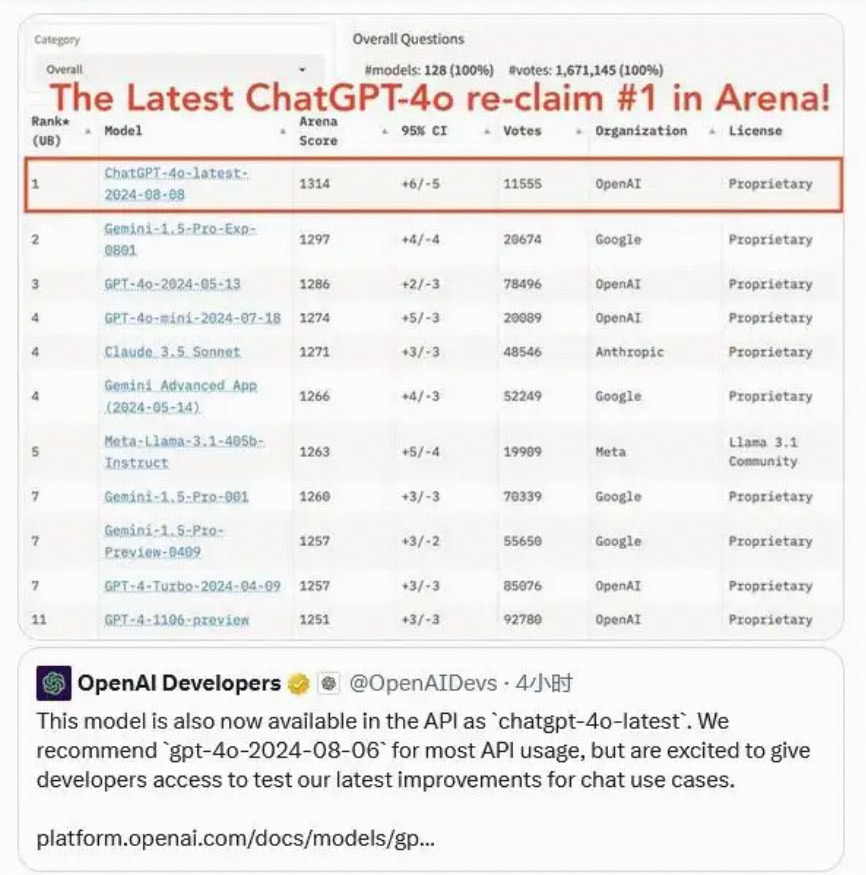
四、多模态处理能力
视觉处理
- 支持最高分辨率 1024×1024 像素,兼容 JPG、PNG、PDF 等格式。
- 采用改进版 Vision Transformer(ViT)模型,将图像分割为 16×16 像素 patch,编码为视觉 tokens 与文本融合。
- 视觉任务支持:
- 物体、场景识别;
- OCR 精度达 98.5%;
- 图表数据提取准确率超过 92%。
音频处理
- 支持 16kHz-48kHz 采样率,兼容 MP3、WAV、AAC 格式,最长单次输入 30 分钟。
- 语音识别(ASR):
- MLS 基准测试词错误率(WER)较 Whisper-v3 降低 18%;
- 低资源语言(如印地语)WER 降低 25%。
- 语音合成(TTS):
- 支持 200+ 种语音风格;
- 语速可调(0.5-2.0 倍);
- 自然度评分(MOS)达 4.8/5.0。
五、性能与效率参数
响应速度
- 文本交互平均响应时间 320 毫秒,短句最快 150 毫秒。
- 音频交互延迟 232 毫秒,接近人类对话实时性。
- 图像交互延迟约 800 毫秒(含图像解析时间)。
计算效率
- 单轮文本交互消耗 0.5-2 TFLOPS,视输入长度而定。
- 多模态交互(文本+图像+音频)消耗 5-10 TFLOPS。
- 支持 INT8 量化部署,性能保持 95%,内存占用降低 60%,适配移动端。
六、模型特点
- 多模态处理:支持文本、音频、图像任意组合输入与输出,灵活应对复杂交互场景。
- 快速响应:平均响应时间低,支持实时流畅对话。
- 强大语言能力:
- 0 次 COT MMLU 测试得分 88.7%;
- 5 次无 COT MMLU 测试得分 87.2%;
- 支持 50+ 种语言,中文、英文、日语表现优异。
- 音频与视觉理解:语音识别和翻译能力领先,视觉感知准确,支持复杂视觉信息解析。
七、如何获取ChatGPT-4o-latest 模型API
通过“OpenAI官网”获取API Key(国外)
1、访问OpenAI官网
在浏览器中输入OpenAI官网的地址,进入官方网站主页。
https://www.openai.com
- 点击右上角的“Sign Up”进行注册,或选择“Login”登录已有账户。
- 完成相关的账户信息填写和验证,确保账户的安全性。
登录后,导航至“API Keys”部分,通常位于用户中心或设置页面中。
2、生成API Key
- 在API Keys页面,点击“Create new key”按钮。
- 按照提示完成API Key的创建过程,并将生成的Key妥善保存在安全的地方,避免泄露。🔒

3、使用 OpenAI API代码
现在你已经拥有了 API Key 并完成了充值,接下来是如何在你的项目中使用 GPT-4.0 API。以下是一个简单的 Python 示例,展示如何调用 API 生成文本:
import openai
import os# 设置 API Key
openai.api_key = os.getenv("OPENAI_API_KEY")# 调用 GPT-4.0 API
response = openai.Completion.create(model="gpt-4.0-turbo",prompt="鲁迅与周树人的关系。",max_tokens=100
)# 打印响应内容
print(response.choices[0].text.strip())
通过“能用AI”获取API Key(国内)
针对国内用户,由于部分海外服务访问限制,可以通过国内平台“能用AI”获取API Key。
1、访问能用AI工具
在浏览器中打开能用AI进入主页
https://ai.nengyongai.cn/register?aff=PEeJ
登录后,导航至API管理页面。
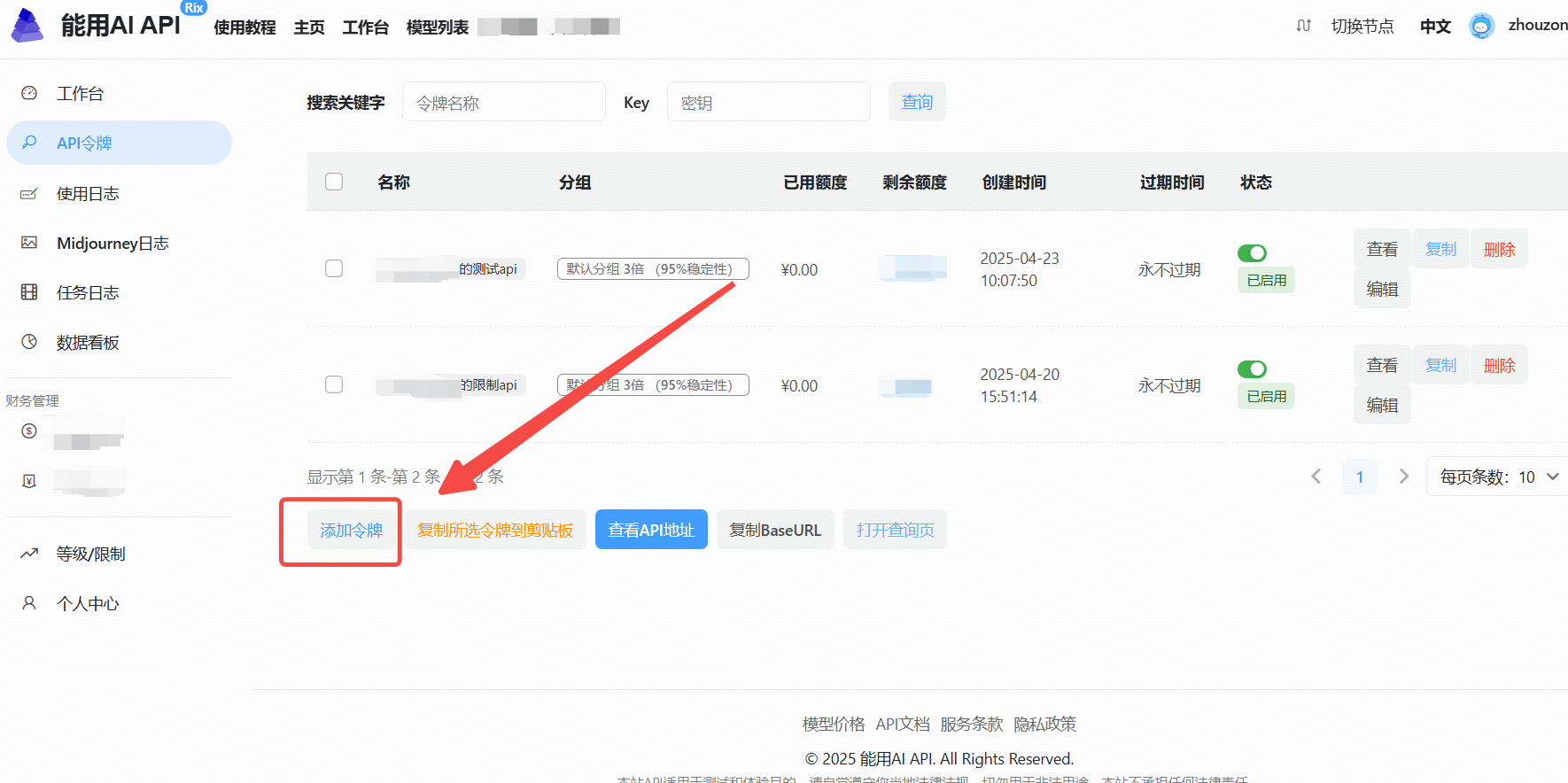
2、生成API Key
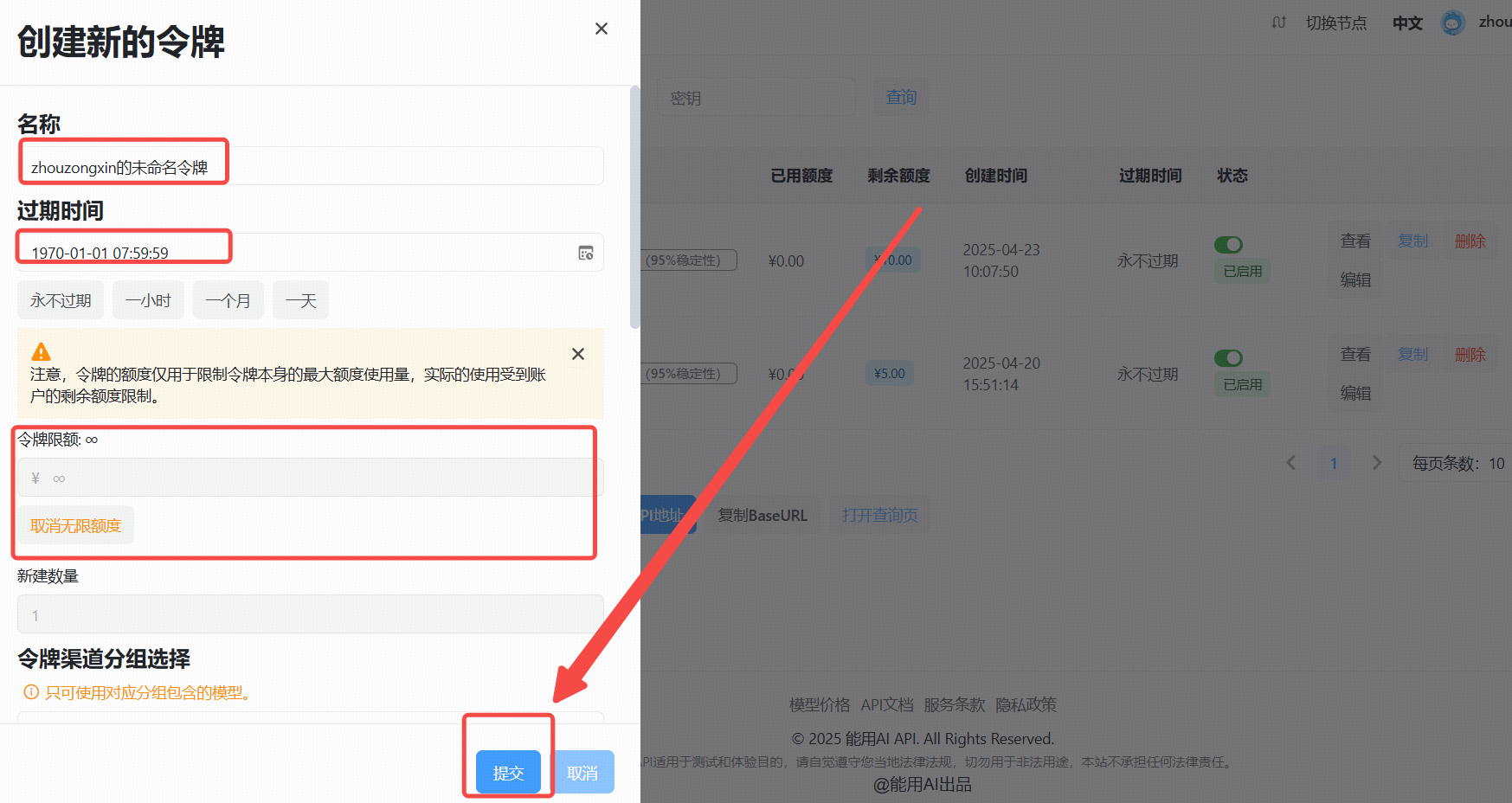
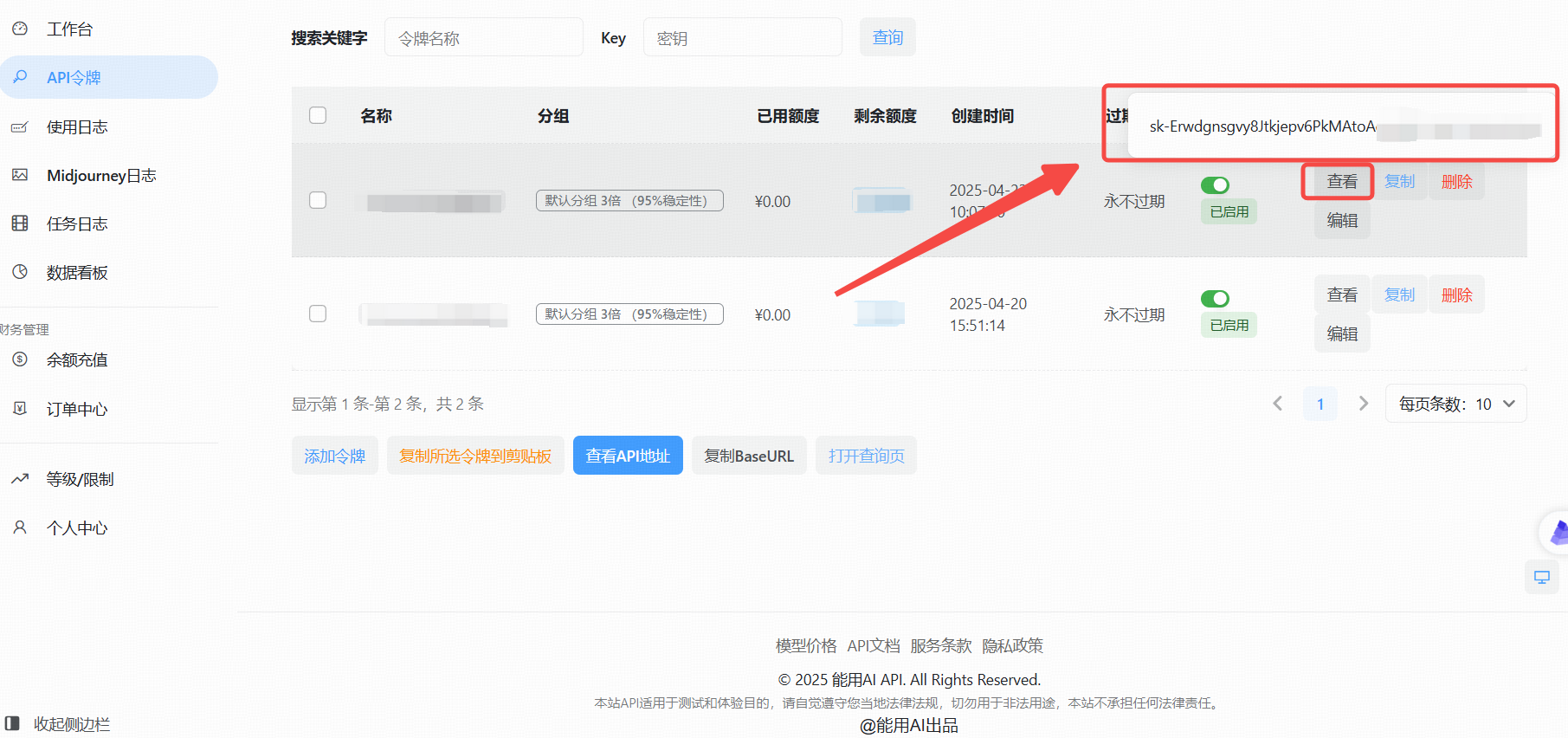
- 点击“添加令牌”按钮。
- 创建成功后,点击“查看KEY”按钮,获取你的API Key。
3、使用OpenAI API的实战教程
拥有了API Key后,接下来就是如何在你的项目中调用OpenAI API了。以下以Python为例,详细展示如何进行调用。
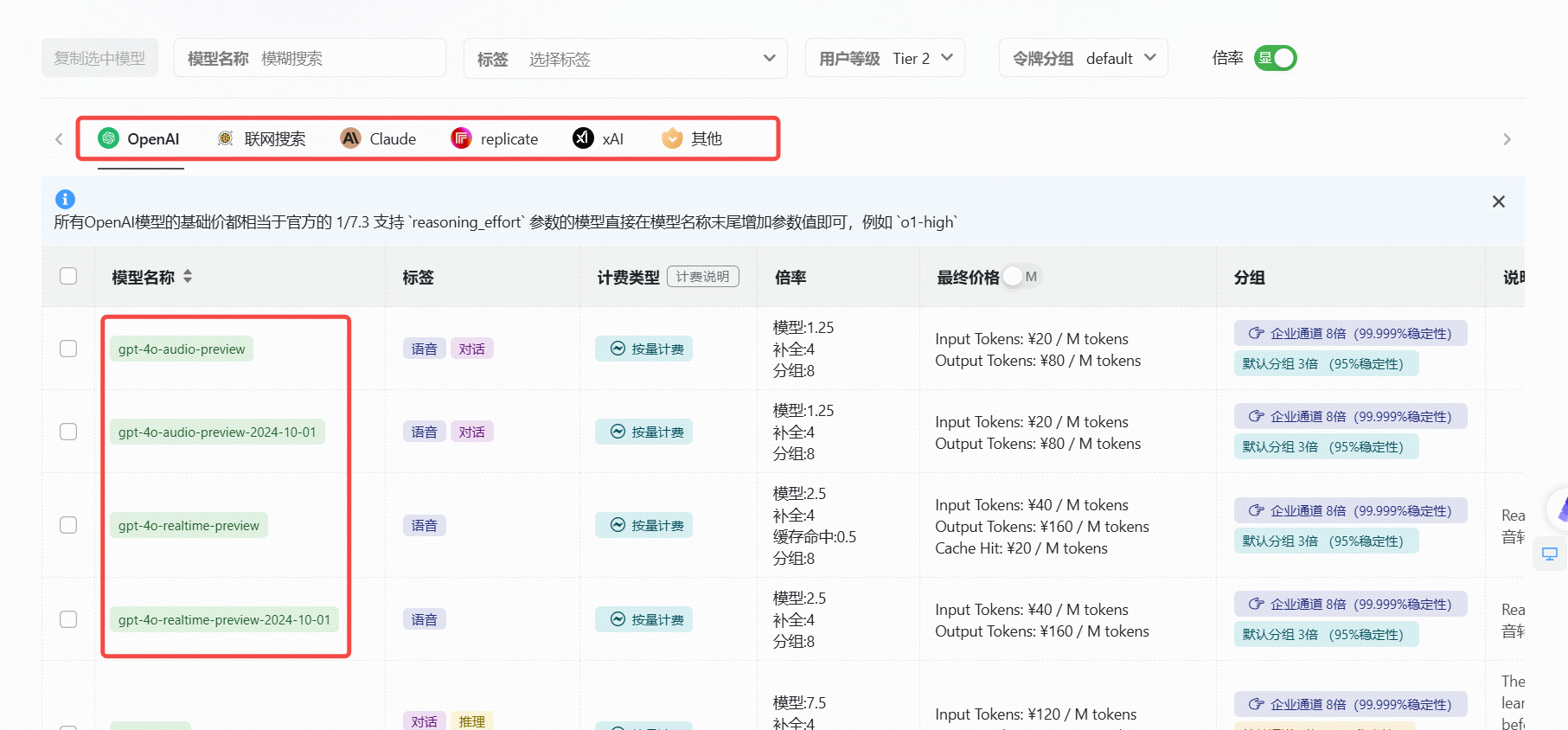
(1).可以调用的模型
gpt-3.5-turbo
gpt-3.5-turbo-1106
gpt-3.5-turbo-0125
gpt-3.5-16K
gpt-4
gpt-4-1106-preview
gpt-4-0125-preview
gpt-4-1106-vision-preview
gpt-4-turbo-2024-04-09
gpt-4o-2024-05-13
gpt-4-32K
claude-2
claude-3-opus-20240229
claude-3-sonnet-20240229
(2).Python示例代码(基础)
基本使用:直接调用,没有设置系统提示词的代码
from openai import OpenAI
client = OpenAI(api_key="这里是能用AI的api_key",base_url="https://ai.nengyongai.cn/v1"
)response = client.chat.completions.create(messages=[# 把用户提示词传进来content{'role': 'user', 'content': "鲁迅为什么打周树人?"},],model='gpt-4', # 上面写了可以调用的模型stream=True # 一定要设置True
)for chunk in response:print(chunk.choices[0].delta.content, end="", flush=True)
在这里插入代码片
(3).Python示例代码(高阶)
进阶代码:根据用户反馈的问题,用GPT进行问题分类
from openai import OpenAI# 创建OpenAI客户端
client = OpenAI(api_key="your_api_key", # 你自己创建创建的Keybase_url="https://ai.nengyongai.cn/v1"
)def api(content):print()# 这里是系统提示词sysContent = f"请对下面的内容进行分类,并且描述出对应分类的理由。你只需要根据用户的内容输出下面几种类型:bug类型,用户体验问题,用户吐槽." \f"输出格式:[类型]-[问题:{content}]-[分析的理由]"response = client.chat.completions.create(messages=[# 把系统提示词传进来sysContent{'role': 'system', 'content': sysContent},# 把用户提示词传进来content{'role': 'user', 'content': content},],# 这是模型model='gpt-4', # 上面写了可以调用的模型stream=True)for chunk in response:print(chunk.choices[0].delta.content, end="", flush=True)if __name__ == '__main__':content = "这个页面不太好看"api(content)

通过这段代码,你可以轻松地与OpenAI GPT-4.0模型进行交互,获取所需的文本内容。✨
更多文章
【IDER、PyCharm】免费AI编程工具完整教程:ChatGPT Free - Support Key call AI GPT-o1 Claude3.5
【VScode】VSCode中的智能编程利器,全面揭秘ChatMoss & ChatGPT中文版