【数据结构】-5- 顺序表 (下)
一、集合框架
这是 Java 集合框架(Java Collections Framework)的核心继承关系树状图
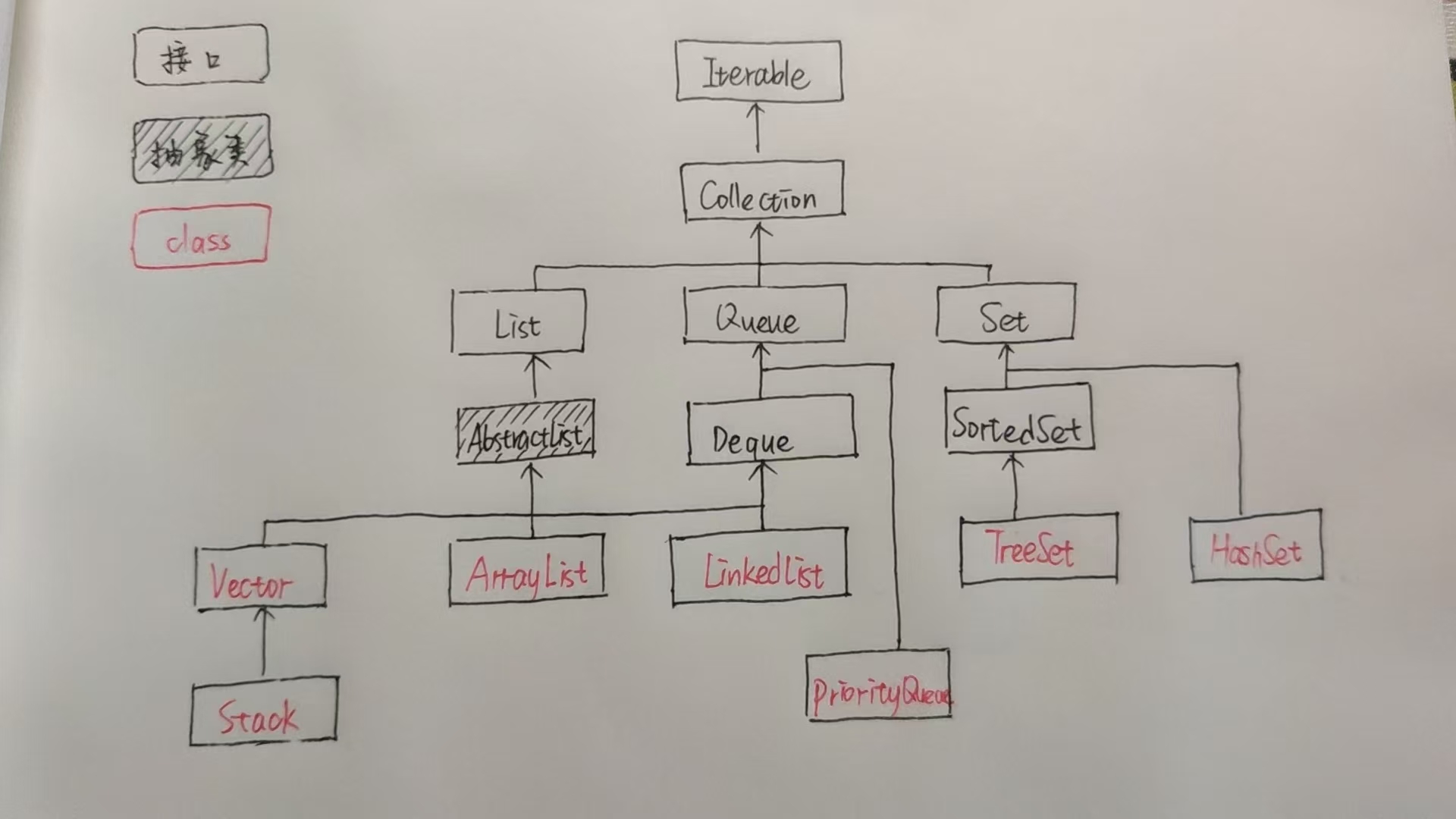
1. 最顶层:Iterable(接口)
- 作用:所有 “可迭代” 的集合(如
List、Set、Queue)都必须实现它,提供遍历元素的能力(通过iterator()方法生成迭代器)。 - 关键方法:
Iterator<T> iterator()→ 返回迭代器,用于遍历集合元素。
2. 第二层:Collection(接口)
- 地位:Java 集合框架的根接口(除
Map体系外,所有集合都直接 / 间接继承它)。 - 定义:规范了集合的基础行为(增、删、查、遍历等),是所有单列集合(单个元素存储)的 “通用契约”。
- 关键方法:
add(E e):添加元素remove(Object o):删除元素contains(Object o):判断是否包含元素size():获取元素个数iterator():获取迭代器(继承自Iterable)
3. 第三层:三大子接口(List、Queue、Set)
Collection 派生出三个核心子接口,代表三种不同的集合特性:
(1)List(接口)
- 特点:有序、可重复(元素按插入顺序排列,允许存重复值)。
- 典型实现类:
ArrayList:基于动态数组,查询快(下标访问O(1))、增删慢(需移动元素)。LinkedList:基于双向链表,增删快(改变指针O(1))、查询慢(需遍历链表)。Vector:古老实现(线程安全,但性能差,已被ArrayList替代)。Stack:继承Vector,实现栈结构(后进先出,LIFO)。
(2)Queue(接口)
- 特点:队列特性(通常 “先进先出,FIFO”,但部分实现支持优先级)。
- 典型实现类:
LinkedList:同时实现List和Queue,作为链表队列使用。PriorityQueue:优先队列(元素按优先级排序,不严格遵循插入顺序)。Deque(子接口):双端队列(两端都可增删),LinkedList也实现了它。
(3)Set(接口)
- 特点:无序、不可重复(元素无顺序,且 equals 相等的元素只能存一个)。
- 典型实现类:
HashSet:基于哈希表(HashMap实现),增删查快(平均O(1)),无序。TreeSet:基于红黑树,元素自动排序(需实现Comparable),查询慢(O(log n))。SortedSet(子接口):规范 “有序 Set” 行为,TreeSet实现它。
4. 抽象类(AbstractList)
- 作用:简化集合实现,为
List接口的实现类提供通用逻辑(如部分方法默认实现)。 - 典型继承:
ArrayList、LinkedList都继承它,避免重复写add、remove等基础逻辑。
⭐ 核心设计思想
接口分层:
Iterable定义 “可遍历” 能力 →Collection定义 “集合基础行为” → 子接口(List/Queue/Set)细化特性。- 解耦 “通用行为” 和 “具体特性”,方便扩展(如新增集合类型只需实现接口)。
实现类分工:
- 不同实现类(
ArrayList/LinkedList/HashSet等)针对不同场景优化(数组查快、链表增删快、哈希表去重等)。 - 开发时根据需求选实现类(查多改少用
ArrayList;增删多用LinkedList;去重用Set)。
- 不同实现类(
复用与扩展:
- 抽象类(如
AbstractList)封装通用逻辑,减少实现类代码量。 - 接口(如
Deque继承Queue)扩展功能,让集合支持更多特性(双端操作)。
- 抽象类(如
⭐ 典型应用场景
- 存有序可重复数据 → 选
List(如ArrayList存学生名单,允许重复姓名)。 - 存无序不可重复数据 → 选
Set(如HashSet存用户 ID,避免重复)。 - 需队列 / 栈行为 → 选
Queue/Stack(如PriorityQueue实现任务优先级调度)。
掌握这张图,就能清晰理解 Java 集合的体系脉络,开发时也能更合理地选集合类型~
二、集合和数组区别
你观察得很敏锐!ArrayList 底层确实是用数组实现的(顺序表本质),但 “集合转数组” 的操作依然有其必要性,核心原因在于 “集合的抽象特性” 与 “数组的具体特性” 之间的差异,具体可以从三个角度理解:
⭐ 接口与实现的分离:集合是 “抽象容器”,数组是 “具体存储”
ArrayList 虽然底层用数组存储,但它对外暴露的是 List 接口的抽象方法(如 add、get、size 等),隐藏了数组的具体实现细节(比如扩容逻辑、下标管理等)。
这种 “抽象” 带来了便利(比如无需手动管理容量),但也限制了对底层数组的直接操作。例如:
- 你不能直接用
ArrayList调用数组特有的工具方法(如Arrays.sort()、Arrays.binarySearch()); - 某些 API 或框架可能只接收
Object[]类型的参数(而非List集合)。
此时,toArray() 的作用就是 “打破抽象”,将集合中 “隐藏的数组元素” 提取出来,转换为可直接操作的数组对象,以便使用数组的特性或兼容外部需求。
⭐ 功能场景的差异:集合擅长 “动态管理”,数组擅长 “静态操作”
ArrayList 作为集合,核心优势是 动态管理数据(自动扩容、简化增删逻辑);而数组的优势是 静态高效操作(如固定长度下的快速遍历、使用 Arrays 工具类的各种功能)。
举两个典型场景:
需要使用数组工具类:
Arrays类提供了大量便捷方法(排序、二分查找、填充等),但这些方法的参数必须是数组。例如,要对ArrayList中的元素排序,直接操作集合不方便,但转成数组后就很简单:List<Integer> list = new ArrayList<>(Arrays.asList(3, 1, 2)); Integer[] arr = list.toArray(new Integer[0]); // 转数组 Arrays.sort(arr); // 用数组工具排序 System.out.println(Arrays.toString(arr)); // [1, 2, 3]需要固定长度的不可变结构:
集合是 “动态的”(可以随时add/remove元素),而有时我们需要一个 “固定不变的快照”(比如传递数据时不希望被修改)。数组的长度固定,转成数组后可以避免误操作导致的元素变化:Object[] arr = list.toArray(); // 数组长度固定为3 // 此时即使修改原集合,数组也不受影响 list.add("西瓜"); System.out.println(arr.length); // 仍为3(数组长度不变)
⭐ 类型系统的限制:集合的泛型与数组的 “具体化”
ArrayList 虽然通过泛型(如 List<String>)保证了元素类型安全,但这种泛型是 编译时检查,运行时会被擦除(类型擦除)。而数组是 “具体化类型”(运行时也能确定类型),两者在类型处理上有差异。
例如,当需要将集合元素传递给一个 “要求具体类型数组” 的方法时(如 void process(String[] strs)),直接传 List<String> 会编译报错,必须通过 toArray(String[]) 转换为具体类型的数组:
process在编译检查时会确定里面的参数是不是string类型数组,但是List<String>里面会被擦除,无法判断是不是确切的String类型,编译会报错。
// 定义一个接收 String[] 参数的方法
public static void process(String[] strs) {for (String s : strs) {System.out.println(s);}
}// 调用方法时,必须将 List<String> 转为 String[]
List<String> list = new ArrayList<>(Arrays.asList("a", "b"));
process(list.toArray(new String[0])); // 正确:传递 String[] 数组
总结
ArrayList 底层用数组实现,但它作为 “集合” 提供的是更高层次的抽象功能(动态管理)。而 toArray() 的作用是 在需要时 “降级” 到数组层面,利用数组的特性(工具类支持、固定长度、具体类型)来满足特定场景需求。
简单说:集合是 “包装好的数组”,方便日常使用;toArray() 是 “拆包装” 的工具,让我们在需要时能直接操作里面的 “数组内核”。
三、toArray()
在 Java 集合框架中,toArray() 是 Collection 接口(所有集合类的顶层接口,如 ArrayList、LinkedList、HashSet 等都实现了它) 定义的核心方法,作用是 将集合中的所有元素,转换为一个「数组」并返回,本质是实现「集合 → 数组」的类型转换。
[1] 核心作用:集合转数组的 “桥梁”
集合(如 ArrayList)是动态存储结构(大小可自动扩容),而数组是静态存储结构(初始化后大小固定)。
当需要用数组的方式操作集合元素(比如兼容某些只接收数组参数的方法、或需要数组的高效随机访问特性)时,toArray() 就是两者之间的关键桥梁。
// 1. 创建一个集合,存入元素
List<String> list = new ArrayList<>();
list.add("苹果");
list.add("香蕉");
list.add("橙子");// 2. 调用 toArray(),将集合转为数组
Object[] fruitArray = list.toArray();// 3. 遍历数组(此时可以用数组的操作方式处理原集合元素)
for (Object fruit : fruitArray) {System.out.println(fruit); // 输出:苹果、香蕉、橙子
}
在代码 Object[] fruitArray = list.toArray(); 中,toArray() 方法括号里没有 new Object[0],是因为调用的是 无参的 toArray() 方法,而不是带参数的 toArray(T[] a) 方法。这两个方法的设计目的和返回值有本质区别:
1. 无参 toArray():直接返回 Object[] 数组
无参的 toArray() 方法是 Collection 接口定义的默认实现,它的行为是:
- 返回值固定为
Object[]类型,无论集合的泛型是什么(即使是List<String>,返回的也是Object[])。 - 内部会创建一个新的
Object[]数组,并将集合中的元素复制进去。
因此,当我们写 list.toArray() 时,不需要传入任何参数,方法会自动创建并返回一个 Object[] 数组,所以代码中直接写成 list.toArray() 即可,无需 new Object[0]。
2. 带参 toArray(T[] a):需要传入数组参数
另一个重载方法 toArray(T[] a) 的作用是 返回指定类型的数组(如 String[]、Integer[]),而非默认的 Object[]。此时需要传入一个数组参数(如 new String[0]),目的是:
- 告诉方法 “我需要返回什么类型的数组”(参数的类型决定了返回数组的类型)。
- 例如
list.toArray(new String[0])会返回String[]类型,而不是Object[]。
3. 为什么这里不需要 new Object[0]?
因为代码的需求是 获取 Object[] 类型的数组,而无参 toArray() 正好直接返回 Object[],完全满足需求。此时如果画蛇添足地传入 new Object[0],写成:
Object[] fruitArray = list.toArray(new Object[0]); // 多余的参数
虽然功能上没问题(返回的也是 Object[]),但参数是多余的 —— 无参方法已经能实现同样的效果,传入参数反而增加了代码的冗余。
[2] 两种常用重载形式(重点区分)
toArray() 有两个核心重载方法,用法和返回值差异很大,实际开发中需根据需求选择:
| 方法签名 | 返回值类型 | 核心特点 | 适用场景 |
|---|---|---|---|
Object[] toArray() | Object[] | 固定返回 Object 类型数组,无论集合泛型是什么 | 仅需 “遍历元素”,不关心元素具体类型时(但有类型转换风险,需谨慎) |
<T> T[] toArray(T[] a) | 传入的数组类型 T[] | 可指定返回数组的具体类型(如 String[]、Integer[]),避免后续强制类型转换 | 需要明确数组类型(如调用需 String[] 参数的方法),是更常用、更安全的方式 |
(1)无参 toArray():返回 Object[]
- 特点:无论原集合的泛型是
String、Integer还是其他类型,返回的数组元素类型都是Object(因为数组的编译时类型是Object[])。 - 注意:不能直接将返回的
Object[]强制转为具体类型数组(如String[]),会触发ClassCastException(类型转换异常)。
List<String> list = new ArrayList<>();
list.add("a");
// 错误!Object[] 不能直接强转 String[]
String[] arr = (String[]) list.toArray(); // 运行时抛 ClassCastException
(2)带参 toArray(T[] a):返回指定类型数组
- 特点:传入一个 “指定类型的数组” 作为参数,方法会根据该数组的类型,返回一个同类型的数组(存储集合元素),避免类型转换风险。
- 内部逻辑:
- 如果传入的数组
a大小 ≥ 集合元素个数:直接将集合元素填入数组a,多余位置填null,返回a本身; - 如果传入的数组
a大小 < 集合元素个数:创建一个 “和a同类型、大小等于集合元素个数” 的新数组,填入元素后返回新数组。
- 如果传入的数组
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");// 方式1:传入一个大小足够的数组(推荐,避免创建新数组)
String[] arr1 = new String[list.size()];
arr1 = list.toArray(arr1); // 返回 String[],可直接使用// 方式2:传入一个空数组(简洁,JDK 1.8+ 常用)
String[] arr2 = list.toArray(new String[0]); // 内部会创建大小为 2 的新 String[]// 遍历数组(无需强制转换,类型安全)
for (String s : arr2) {System.out.println(s); // 输出 a、b
}
[3] 关键注意点(避坑)
(1)无参 toArray() 的类型限制
再次强调:无参方法返回的 Object[] 只能存 Object 类型,不能强转具体类型数组。若需具体类型,必须用带参 toArray(T[] a)。
(2)返回数组是 “新数组” 还是 “原集合底层数组”?
- 对于
ArrayList:toArray()返回的是复制后的新数组,修改数组元素不会影响原集合(因为数组和集合底层存储的是两个独立的数组)。List<Integer> list = new ArrayList<>(); list.add(10); Integer[] arr = list.toArray(new Integer[0]); arr[0] = 20; // 修改数组元素 System.out.println(list.get(0)); // 输出 10(原集合无变化) - 对于其他集合(如
Vector):逻辑类似,均返回 “元素副本的数组”,避免外部通过数组修改集合内部状态。
(3)集合元素为 null 时的处理
若集合中包含 null 元素,toArray() 会将 null 也存入数组(数组允许 null),遍历数组时需注意判空,避免 NullPointerException。
List<String> list = new ArrayList<>();
list.add("a");
list.add(null); // 集合允许存 null
String[] arr = list.toArray(new String[0]);
System.out.println(arr[1]); // 输出 null
四、List 接口常用方法
一、增(添加元素)
boolean add(E e)- 功能:在顺序表末尾插入元素(尾插)。
- 逻辑:检查容量 → 数组末尾赋值 →
size++。 - 示例:
ArrayList<Integer> list = new ArrayList<>(); list.add(10); // 末尾插入10,size 变为1
void add(int index, E element)- 功能:在指定下标
index处插入元素,后续元素后移。 - 逻辑:检查下标合法性 → 扩容(如需) → 从
index开始后移元素 → 插入新值 →size++。 - 注意:
index范围[0, size](允许末尾插入,对应index=size)。 - 示例:
list.add(1, 20); // 在索引1处插入20,原索引1及之后元素后移
- 功能:在指定下标
boolean addAll(Collection<? extends E> c)- 功能:把另一个集合
c的元素全部尾插到当前表。 - 逻辑:遍历集合
c,逐个尾插元素;若插入成功(至少一个),返回true。 - 示例:
List<Integer> other = Arrays.asList(30, 40); list.addAll(other); // 末尾插入30、40,size 增加2
- 功能:把另一个集合
二、删(删除元素)
E remove(int index)- 功能:删除指定下标
index处的元素,返回被删元素;后续元素前移。 - 逻辑:检查下标合法性 → 保存被删元素 → 从
index+1开始前移元素 →size--→ 返回被删值。 - 示例:
int removed = list.remove(1); // 删除索引1的元素,返回该元素
- 功能:删除指定下标
boolean remove(Object o)- 功能:删除第一个遇到的元素
o(基于equals比较),删除成功返回true。 - 逻辑:遍历查找第一个与
o相等的元素 → 找到则删除(后续元素前移) → 返回是否删除成功。 - 注意:若存储自定义对象,需重写
equals保证比较逻辑正确。 - 示例:
list.remove(Integer.valueOf(20)); // 删除第一个值为20的元素
- 功能:删除第一个遇到的元素
三、改(修改元素)
E set(int index, E element)- 功能:将下标
index处的元素替换为element,返回原元素。 - 逻辑:检查下标合法性 → 保存原元素 → 赋值新元素 → 返回原元素。
- 示例:
int old = list.set(1, 25); // 索引1的元素改为25,返回原元素
- 功能:将下标
四、查(获取 / 查找元素)
E get(int index)- 功能:获取下标
index处的元素。 - 逻辑:检查下标合法性 → 直接返回数组对应位置的值(时间复杂度
O(1))。 - 示例:
int val = list.get(1); // 获取索引1处的元素值
- 功能:获取下标
boolean contains(Object o)- 功能:判断元素
o是否存在于表中(基于equals遍历比较)。 - 逻辑:遍历表,用
equals比较元素;找到则返回true,否则false。 - 注意:自定义对象需重写
equals,否则比较地址而非内容。 - 示例:
boolean has = list.contains(25); // 判断25是否在表中
- 功能:判断元素
int indexOf(Object o)- 功能:返回第一个
o所在的下标(基于equals遍历);不存在返回-1。 - 逻辑:遍历表,找到第一个与
oequals的元素,返回其下标。 - 示例:
int idx = list.indexOf(25); // 找25第一次出现的下标
- 功能:返回第一个
int lastIndexOf(Object o)- 功能:返回最后一个
o所在的下标(反向遍历,基于equals);不存在返回-1。 - 逻辑:从表末尾往前遍历,找到第一个与
oequals的元素,返回其下标。 - 示例:
int lastIdx = list.lastIndexOf(25); // 找25最后一次出现的下标
- 功能:返回最后一个
五、工具操作
void clear()- 功能:清空顺序表(元素个数置 0,数组引用可保留或重置,不同实现可能有差异)。
- 逻辑:
size = 0(或额外把数组元素置null,帮助 GC 回收)。 - 示例:
list.clear(); // 清空后 size=0,元素全被移除
List<E> subList(int fromIndex, int toIndex)- 功能:截取从
fromIndex(含)到toIndex(不含)的子表,返回新List。 - 逻辑:创建新
List,遍历原表对应区间,复制元素;子表与原表共享底层数组(修改子表会影响原表,需注意)。 - 示例:
List<Integer> sub = list.subList(1, 3); // 截取索引1、2的元素,生成子表
- 功能:截取从
六、方法调用关系 & 核心特点
- 依赖关系:增删操作常依赖扩容(如
add时检查容量)、元素移动(插入 / 删除时数组拷贝);查找依赖equals(自定义对象需重写)。 - 时间复杂度:
- 尾插 / 尾删(不扩容时):
O(1); - 指定位置增删(需移动元素):
O(n); - 查找(遍历):
O(n); - 下标访问(
get/set):O(1)。
- 尾插 / 尾删(不扩容时):
- 适用场景:适合频繁按下标访问、尾插操作;若需大量中间增删,优先选链表(如
LinkedList)。
五、 Java 集合的迭代器(Iterator)遍历机制
一、迭代器的作用:“指针” 式遍历集合
迭代器(Iterator)是 Java 集合框架中用于安全遍历集合元素的工具,它像一个 “移动的指针”,依次访问集合中的每个元素。
核心优势:
- 支持在遍历中安全删除元素(避免普通
for循环遍历删除时的ConcurrentModificationException); - 统一了各类集合的遍历方式(
List、Set、Queue都能用迭代器遍历)。
二、代码执行流程
假设 list 是一个 List<Integer>,存储元素 [1, 2, 3],代码:
Iterator<Integer> it = list.iterator(); // 1. 获取迭代器
while (it.hasNext()) { // 2. 检查是否有下一个元素System.out.println(it.next() + " "); // 3. 获取并移动到下一个元素
}
1. 获取迭代器:list.iterator()
- 作用:创建一个与
list关联的迭代器对象it,初始时指向集合第一个元素之前(类似指针在数组下标-1的位置)。
2. 检查是否有下一个元素:it.hasNext()
- 作用:判断迭代器当前位置之后是否还有未访问的元素。
- 执行逻辑:
- 第一次调用:指针在
-1,检查到下标0有元素(1),返回true。 - 第二次调用:指针在
0(已访问1),检查到下标1有元素(2),返回true。 - 第三次调用:指针在
1(已访问2),检查到下标2有元素(3),返回true。 - 第四次调用:指针在
2(已访问3),检查到下标3无元素,返回false,结束循环。
- 第一次调用:指针在
3. 获取并移动指针:it.next()
- 作用:返回当前指针位置的下一个元素,并将指针向后移动一位(“自动向下执行” 的本质)。
- 执行逻辑:
- 第一次
it.next():返回下标0的元素1,指针移动到0→1之间(指向1之后)。 - 第二次
it.next():返回下标1的元素2,指针移动到1→2之间。 - 第三次
it.next():返回下标2的元素3,指针移动到2→3之间。
- 第一次
三、迭代器的 “指针” 模型(对应图中结构)
图中右侧的 “竖排方框” 代表集合 list 的元素(1、2、3),it 是迭代器指针,执行流程对应:
- 初始状态:
it指向第一个元素(1)之前(无具体位置,逻辑上在-1)。 - 第一次
hasNext():检测到1存在 → 进入循环 →next()返回1,指针移动到1之后。 - 第二次
hasNext():检测到2存在 → 进入循环 →next()返回2,指针移动到2之后。 - 第三次
hasNext():检测到3存在 → 进入循环 →next()返回3,指针移动到3之后。 - 第四次
hasNext():检测到无元素 → 退出循环。
四、迭代器的关键特点
- 单向遍历:只能从前往后遍历,无法回退(若需回退,用
ListIterator子接口)。 - 快速失败(fail-fast):遍历中若集合被修改(如
list.add/list.remove),会立即抛出ConcurrentModificationException,避免脏读。 - 与集合状态绑定:迭代器遍历的是创建时集合的 “快照”(但如果是
ArrayList等基于数组的集合,遍历中修改会触发快速失败)。
五、对比普通 for 循环遍历
虽然 for-each 本质也是迭代器遍历,但手动用 Iterator 的优势在于:
- 支持遍历中删除元素(
it.remove(),安全且不会报错); - 更灵活(可控制遍历过程,比如跳过某些元素)。
示例:遍历中删除元素(安全写法)
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {Integer num = it.next();if (num == 2) {it.remove(); // 安全删除当前元素}
}
理解迭代器的 “指针移动” 模型后,就能掌握集合遍历的底层逻辑,遇到遍历相关的问题(如并发修改异常)也能快速定位啦~