elasticsearch的使用
elasticsearch的使用
elasticsearch中文文档
参考文档:ElasticSearch (ES从入门到精通一篇就够了) - 不吃紫菜 - 博客园
什么是Elasticsearch?
Elasticsearch 是一种分布式文档存储。Elasticsearch 不用列数据行存储信息,而是存储已序列化为 JSON 文档的复杂数据结构。当一个文档被存储时,它会被索引并且在接近实时的1秒钟内被完全可搜索。Elasticsearch 使用一种称之为倒排索引的数据结构,支持非常快的全文搜索。
正向索引和倒排索引
正向索引
适合通过索引来检索数据,且检索速度快,但是如果是模糊检索会很慢,需要全国表扫描
比如有一张商品表
| id | product_name | price |
| 1 | 小米手机 | 8900 |
| 2 | 华为手机 | 9000 |
| 3 | 小米手环 | 3999 |
如果进行索引检索也就是id查询的话速度很快,但是大部分情况比如购物网站的搜索栏都是模糊检索,比如
select * from product where product_name like ‘%手机%’
检索流程
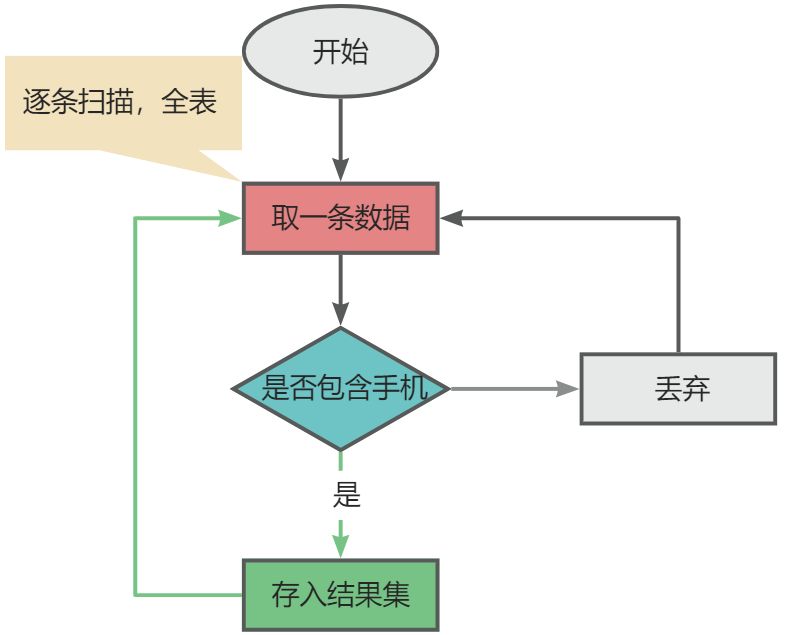
如果数据量很大的话检索速度将很慢,完全无法满足现在大数据量的时代
倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
假如有一个文档集,一条数据就是一个文档,文档保存的时候会生成对应的词条

检索流程
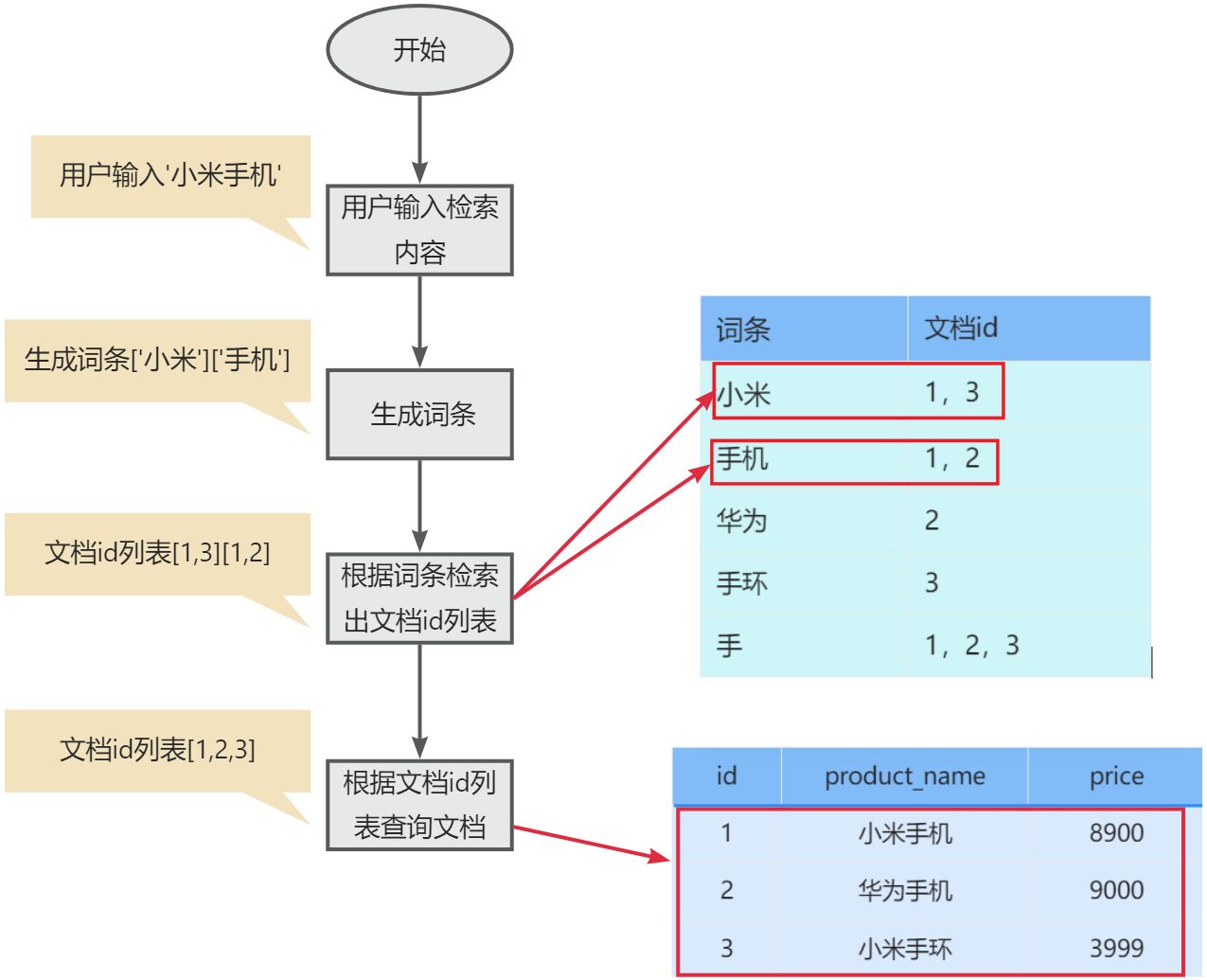
词条它是唯一的可以创建索引,当我们模糊匹配‘手机’时,会根据词条手机查询文档id列表,提供文档id列表查询文档,两次查询是索引查询,不需要全表扫描,速度很快.
正向和倒排对比
概念区别:
- 正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
- 而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
优缺点:
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
Elasticsearch的核心概念
索引
es索引是es组织文档的方式,是文档的集合,网上很多人都说es索引就类似于Mysql的数据库,但我认为它更像是一张数据表。这个索引下面可以存储文档集合,就行一张表里面可以存储很多行数据。
文档
文档是es中可搜索的最小单位,es的文档由一个或多个字段组成,类似于关系型数据库中的一行记录,但es的文档是以JSON进行序列化并保存的,每个JSON对象由一个或多个字段组成,字段类型可以是布尔,数值,字符串、二进制、日期等数据类型。
每一个文档,除了保存我们写入进行的文档原始数据外,也有文档自己的元数据,这些元数据,用于标识文档的相关信息。
es每个文档都有唯一的id,这个id可以由我们自己指定,也可以由es自动生成。
总而言之
索引可被认作一种文档的优化集合,且每个文档都是字段的集合,字段是包含你数据的键值对。默认情况下,Elasticsearch 索引每个字段中的所有数据,且每个被索引的字段有一个专用的优化数据结构。例如,文本字段被存储在倒排索引中,数字和地理字段存储在 BKD 树 中。使用每个字段的数据结构来聚集和返回搜索结果是让 Elasticsearch 如此快的原因。
Elasticsearch简单操作
Elasticsearch 提供一种简单、一致的 REST API,用于管理你的集群以及索引和搜索数据。用于测试目的,你可以轻松地从命令行或者在 Kibana 中通过开发者控制台提交请求。Elasticsearch REST API 支持结构化查询、全文查询以及结合二者的复杂查询。
Elasticsearch 聚合可以让你你能实时分析和可视化数据
注意:本文示例都是在kinbana里面测试的,你也可以通过PostMan和ApiPost进行测试给elasticsearch发送请求完成测试
索引操作API
创建索引
put /<索引名称>示例:

删除索引
Delete /<索引名称>示例:

获取索引
GET /<索引名称>示例:

索引别名
索引别名是用于引用一个或多个现有索引的辅助名称。大多数 Elasticsearch API 接受索引别名代替索引。
添加或修改别名:
POST /_aliases
{"actions" : [{ "add" : { "index" : "索引名称", "alias" : "别名" } },//添加别名{ "remove" : { "index" : "索引名称", "alias" : "别名" } },//移除别名{ "remove_index": { "index": "test" } } //移除索引]
}其它
还有很多其他索引操作API,可以看elasticsearch中文文档

文档操作API
查询体query的组成
参考文章:Elasticsearch 基本使用(五)查询条件匹配方式(query & query_string)_es条件查询-CSDN博客
query 查询主要分为以下几大类:
- 全文查询(Full Text Queries)
- 词项级查询(Term-level Queries)
- 复合查询(Compound Queries)
- 地理位置查询(Geo Queries)
- 特殊查询(Specialized Queries)
- 嵌套和父子文档查询
1. 全文查询(Full Text Queries)
- match:最基本的全文查询类型,会对查询文本进行分词处理。
{"query": {"match": {"字段名称": {"query": "",//查询文本"operator": "and", // 表示必须包含所有词项 默认为 or"minimum_should_match": "", // 至少匹配词项的百分比"fuzziness": "AUTO", // 模糊匹配级别 AUTO或0-2"analyzer": "standard"//指定分析器}}}
}
- match_phrase :精确匹配整个短语,保持词项顺序。
{"query": {"match_phrase": {"字段名称": {"query": "",//查询文本"slop": 2, // 允许词项间最多间隔几个词"analyzer": "english"//指定分析器}}}
}
- match_phrase_prefix:短语前缀匹配,最后一个词项做前缀匹配。
{"query": {"match_phrase_prefix": {"字段名称": {"query": "",//查询文本"max_expansions": 1, // 最多扩展几个前缀匹配项"slop": 1//允许的词项间隔距离}}}
}
- multi_match:在多个字段上执行全文搜索
{"query": {"multi_match": {"query": "",//查询文本"fields": ["字段1名称^4", "字段2名称", "字段3名称^2"], // 指定需要执行全文搜索的字段,以及字段权重"type": "best_fields", // 最佳匹配字段得分"tie_breaker": 0.3 // 其他匹配字段得分权重}}
}
- query_string:支持Lucene查询语法。
常用语法元素:
field:value指定字段搜索AND/OR/NOT逻辑操作+必须包含-必须不包含*通配符~模糊搜索[TO]范围搜索- simple_query_string:更健壮的 query_string 简化版。
2. 词项级查询(Term-level Queries)
- term :精确匹配单个词项。
{"query": {"term": {"字段名称": {"value": "字段值","boost": 1.5 // 权重提升}}}
}
或者直接
{"query": {"term": {"字段名称": "字段值"}}
}
- terms:匹配多个精确词项,相当于 SQL 中的 IN 查询。
{"query": {"terms": {"字段名称": ["值1", "值2", "值3"],"boost": 2.0 //权重或省略}}
}
- range:范围查询,支持数值、日期和IP地址。
{"query": {"range": {"字段名称": {"gte": 最小值,"lt": 最大值}}}}
}
- exists:查找包含指定字段的文档。
{"query": {"exists": {"field": "字段名称"}}
}
- prefix:前缀匹配查询
{"query": {"prefix": {"字段名称": {"value": "前缀","rewrite": "constant_score" // 重写方法 默认constant_score}}}
}
- wildcard:通配符查询,支持 * (匹配多个字符) 和 ? (匹配单个字符)
{"query": {"wildcard": {"字段名称": {"value": "匹配规则", 比如 ab*d:匹配所有以ab开头的结尾的,a?d:匹配a开头b结尾且之间子隔一个字符"boost": 1.0,//设置权重"rewrite": "scoring_boolean"}}}
}
- regexp :正则表达式匹配
{"query": {"regexp": {"字段名称": {"value": "正则表达式","flags": "ALL",//允许使用的表达式操作符"max_determinized_states": 10000}}}
}
- fuzzy :模糊查询,允许一定程度的拼写错误
{"query": {"fuzzy": {"字段名称": {"value": "字段值","fuzziness": "2", // 允许字符的差异个数:AUTO,0,1,2"prefix_length": 3 // 表示前几个字符必须精确匹配}}}
}
3. 复合查询(Compound Queries)
| 子句 | 描述 | 影响评分 | 使用场景 |
| must | 相当于 "and" | 是 | 主要查询条件 |
| should | 相当于 "or" | 是 | 次要条件或增强相关性 |
| must_not | 相当于 "not" | 否 | 排除条件 |
| filter | 相当于 "where" | 否 | 过滤条件 |
- bool :组合多个查询条件
比如:查询主题为javaSE并且日期大于"2025-01-01",文章类型为技术型或者内容包含java的正常的未删除的博文
{"query": {"bool": {"must": [{ "match": { "title": "javaSE" } },{ "range": { "date": { "gte": "2025-01-01" } } }],"should": [{ "match": { "content": "java" } },{ "term": { "category": "技术" } }],"must_not": [{ "term": { "status": "正常" } }],"filter": [{ "term": { "del_statu": "未删除" } }],"minimum_should_match": 1,"boost": 1.0}}
}
- boosting:降低某些文档的得分
- constant_score:固定分数查询,通常与 filter 一起使用。
- dis_max:取子查询中的最高分,适用于"最佳字段"匹配场景
{"query": {"dis_max": {"queries": [{ "match": { "title": "Elasticsearch" } },{ "match": { "content": "Elasticsearch" } },{ "match": { "abstract": "Elasticsearch" } }]}}
}
4. 地理位置查询(Geo Queries)
- geo_distance:距离范围内搜索
{"query": {"geo_distance": {"distance": "10km",//相当于指定半径半径"distance_type": "arc", //范围类型,距离"location": { //相当于圆心"lat": ,//经度"lon": //纬度},"validation_method": "STRICT"}}
}
- geo_bounding_box :矩形范围内搜索
{"query": {"geo_bounding_box": {"location": {"top_left": { //左上角的经纬度"lat": ,"lon": },"bottom_right": {//右下角的经纬度"lat": ,"lon": }},"validation_method": "COERCE"}}
}
- geo_polygon:多边形范围内搜索
{"query": {"geo_polygon": {"location": {"points": [ //点列表,点连成一个封闭的多边形{ "lat": , "lon": },{ "lat": , "lon": },...]},"validation_method": "IGNORE_MALFORMED"}}
}
5. 特殊查询(Specialized Queries)
- more_like_this:查找相似文档
- script:脚本查询
- pinned:固定某些文档在结果顶部
6. 嵌套和父子文档查询
- nested:嵌套对象查询
- has_child :子文档查询
- has_parent :父文档查询
Filter
filter跟query在使用上是类似的可以bool,rang,term,terms等查询
Query与Filter的区别
| 特性 | Query(查询上下文) | Filter(过滤上下文) |
| 评分影响 | 计算 _score(影响排序) | 不计算 _score(仅过滤) |
| 性能 | 较慢(需计算评分) | 更快(无评分计算,结果可缓存) |
| 缓存机制 | 不缓存 | 结果缓存,加速重复查询 |
| 使用场景 | 全文搜索、模糊匹配 | 精确匹配、范围过滤、存在性检查 |
Query vs Filter 的底层机制
评分(_score)计算
- Query:使用 TF-IDF、BM25 等算法计算文档相关性。
- Filter:仅返回匹配的文档,所有文档 _score 默认为 0(或忽略)。
缓存机制
- Query:不缓存结果,每次查询都重新计算评分。
- Filter:结果会被 Elasticsearch 自动缓存,后续相同条件的查询直接复用缓存,大幅提升性能。
Query与Filter使用建议
对精确匹配、范围过滤等场景,使用 filter 提升性能。例如:term, range, exists。
仅对需要评分的内容使用 Query:如全文搜索、模糊匹配时使用 must 或 should
利用缓存优化高频过滤条件:将频繁使用的条件(如分类、状态)放在 filter 中。
避免混合评分与非评分逻辑:将过滤条件与评分逻辑分离,确保性能最优。
单文档 API
添加文档
POST /<索引名称>/_doc/ ;//直接添加文档,文档id自动生成
PUT /<索引名称>/_doc/<_ID>;//指定文档id添加文档,如果文档id已经存在就覆盖文档,版本号+1
PUT /<索引名称>/_create/<_ID> //指定文档id添加文档,如果文档id已经存在就报错
POST /<索引名称>/_create/<_ID>//指定文档id添加文档,如果文档id已经存在就报错示例:
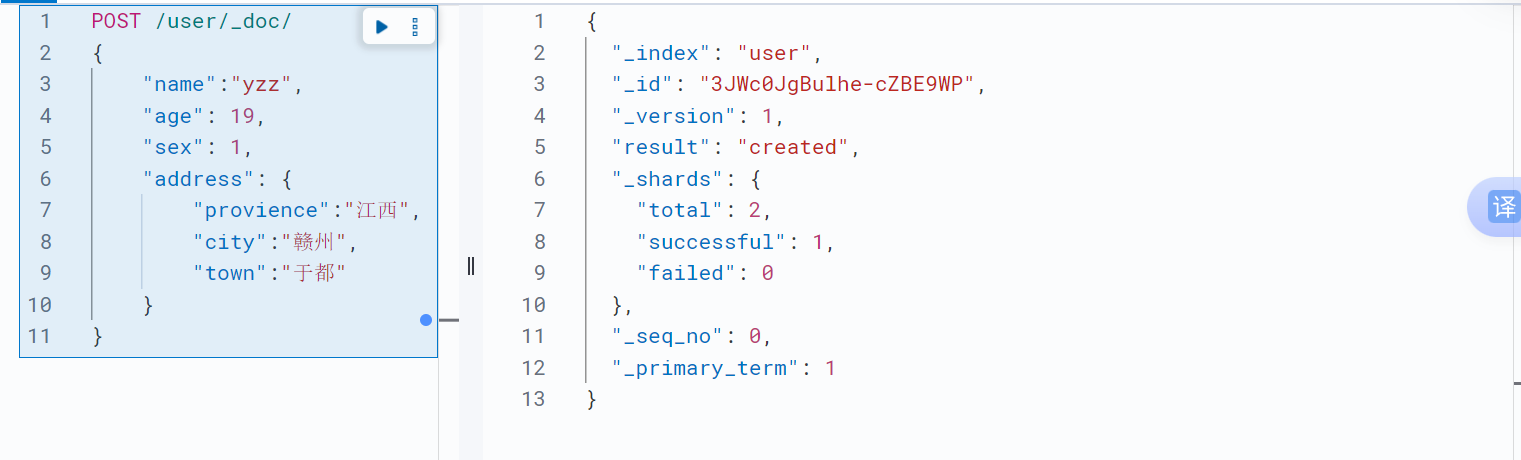
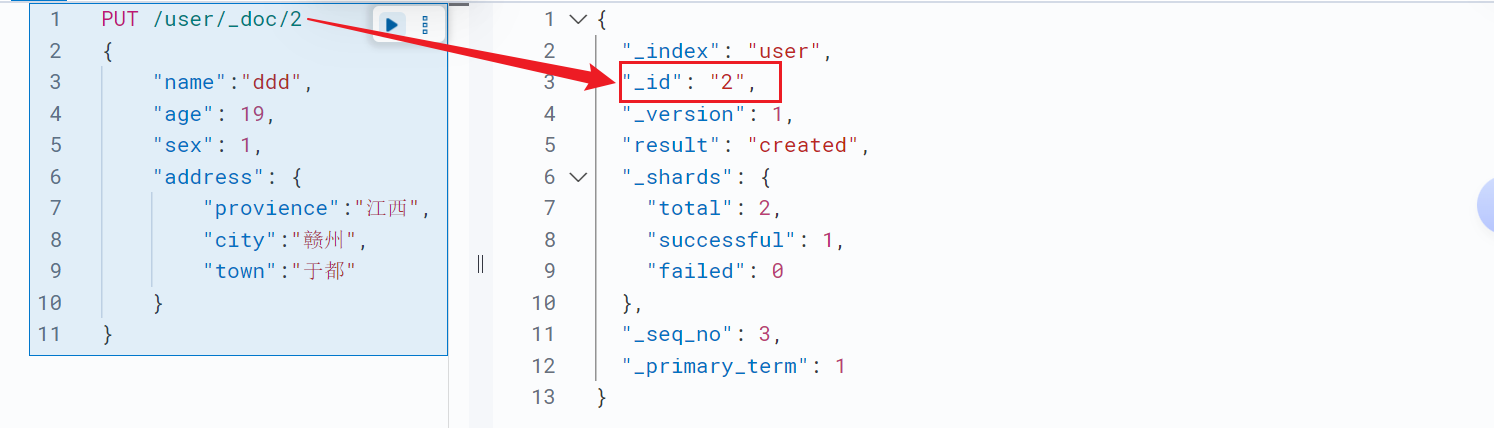
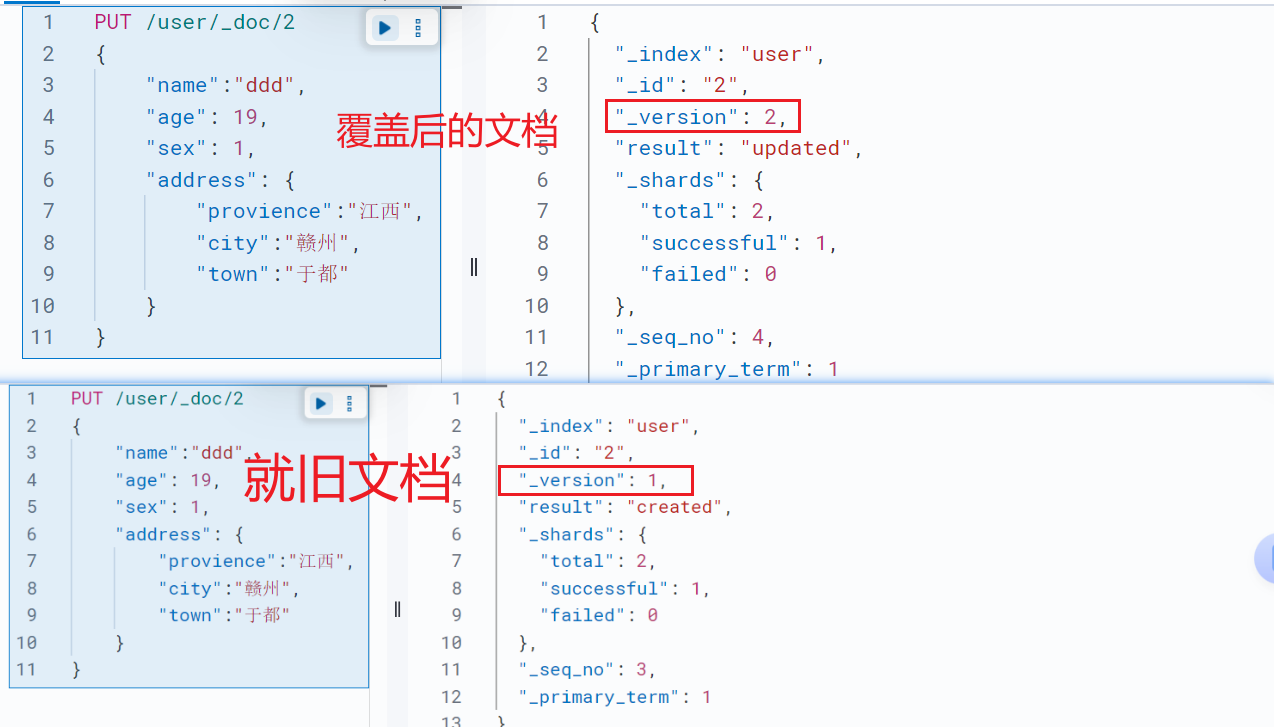
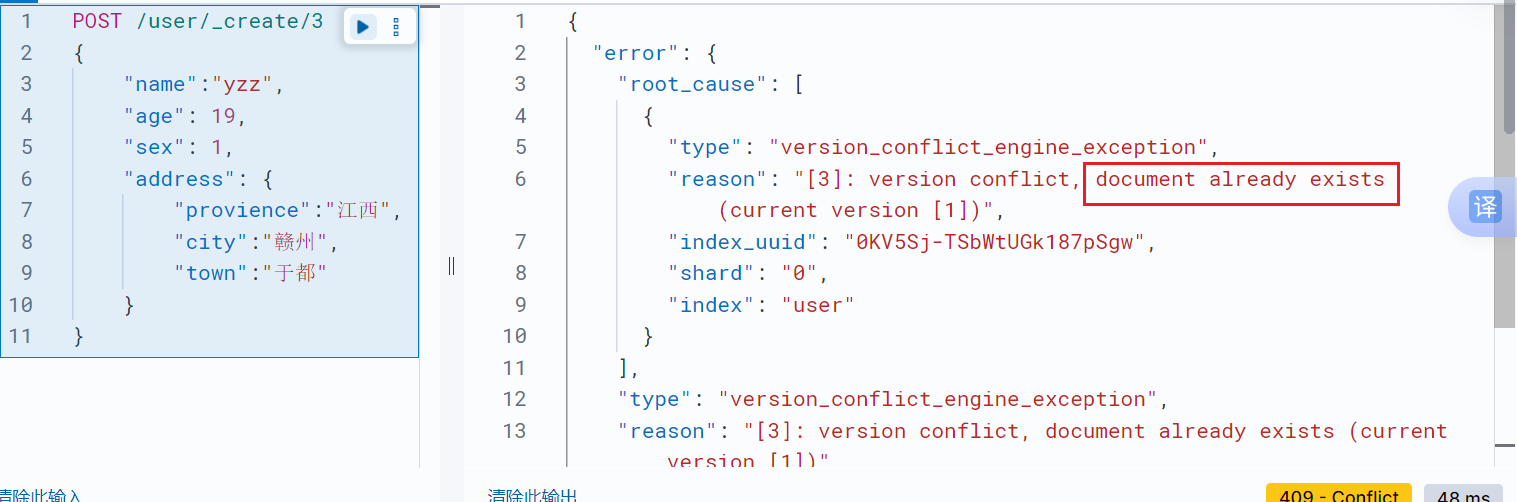
id获取文档
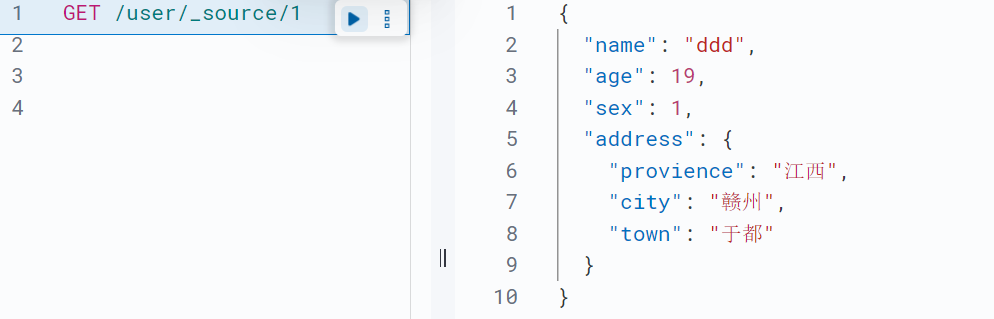
GET <索引名称>/_doc/<_id>;//通过文档id获取文档内容包括文档元数据HEAD <索引名称>/_doc/<_id>;//判断索引里是否存在对应id的文档GET <索引名称>/_source/<_id>;//通过文档id获取文档内容不包括元数据HEAD <索引名称>/_source/<_id>;判断索引里是否存在对应id的文档数据示例:
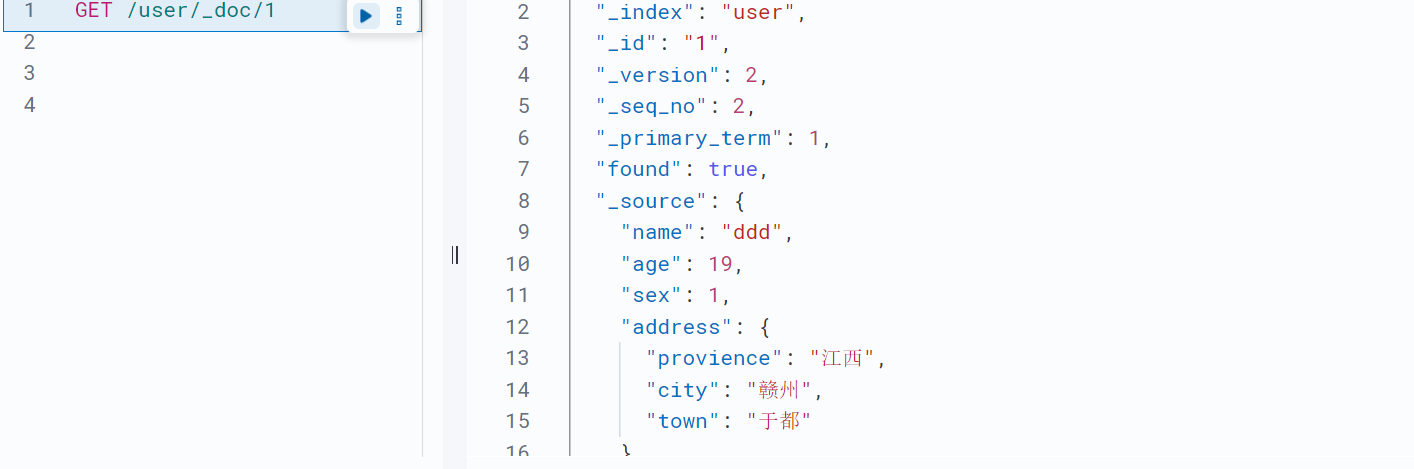
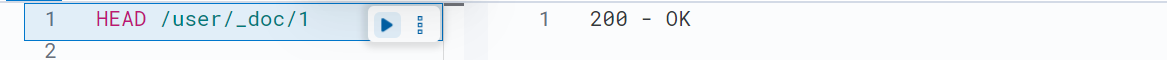
![]()
更新文档
POST /<索引名称>/_update/<_id> ;//根据id更新文档内容
{
"script"://通过脚本更新,比如可以给文档添加计算器
"doc":{}//更新问档数据的一部分,如果script和doc同时存在doc会被覆盖不起作用
}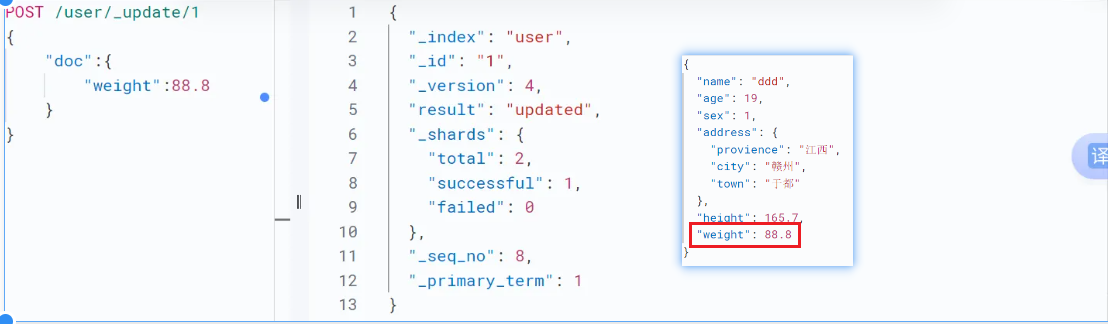
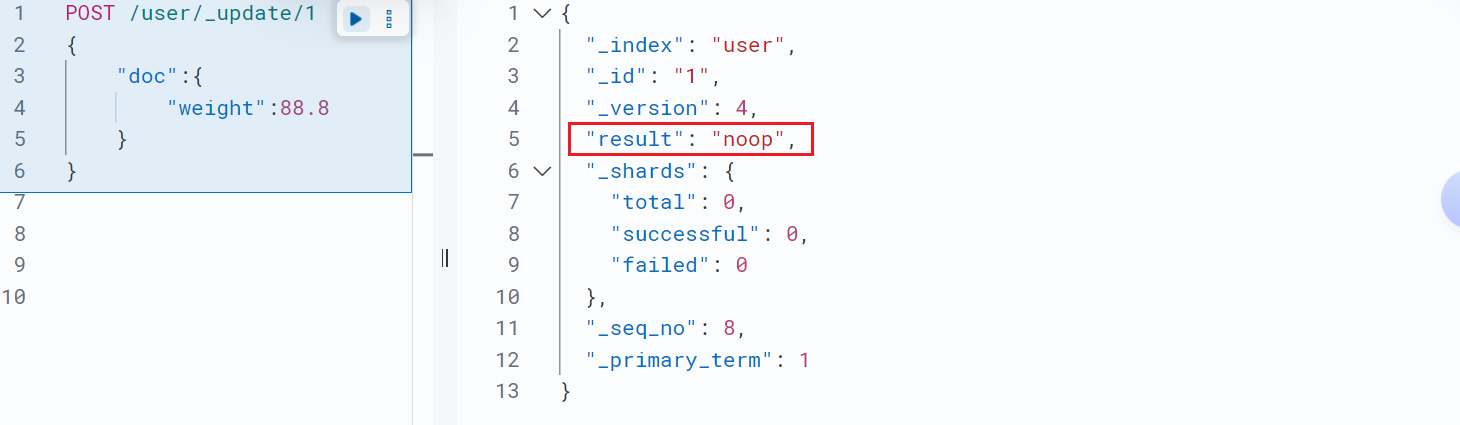
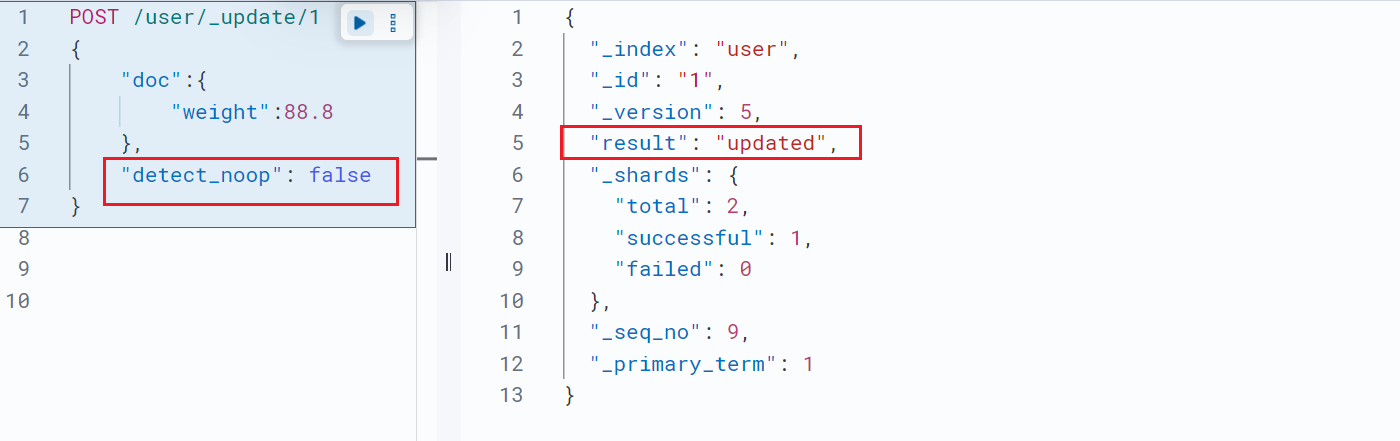
如果旧文档里面不存在要更新的字段,该字段就会被添加到文档里面,如果存在就更新字段的值,如果跟新的值和就文档一样就返回noop,表示没有更新的内容。可以通过设置 "detect_noop": false 来禁用此行为:
比如我点击再次运行:
更新插入
POST <索引名称>/_update/<_id>
{"doc": {//文档数据},"doc_as_upsert": true //设置为true表示文档id不存在时就插入,存在就更新
}通过管道来查询更新
创建管道
PUT _ingest/pipeline/<管道名称>
{"description" : "管道描述","processors" : [{}//管道操作,比如set,join,sort等等]
}查询更新/查询执行管道操作
POST /user/_update_by_query?pipeline=<管道名称>
{"query": {"指定查询类型": {"查询字段": "查询值"}}//查询条件}示例,把名字为‘yzz’的用户年龄变成30岁
PUT _ingest/pipeline/set-age
{"description" : "sets age","processors" : [ {"set" : {"field": "age","value": "30"}}]
}POST /user/_update_by_query?pipeline=set-age
{"query": {"term": {"name": "yzz"}} }删除文档
DELETE /<索引名称>/_doc/<_id> //根据id删除文档POST //<索引名称>/_delete_by_query
{"query": {}//查询条件
}多文档 API
按id检索多个文档
GET /_mget //可以检索不同索引下的多个文档
{
"docs": [{"_index": "索引名称","_id": "1" //文档id},{"_index": "索引名称","_id": "2" //文档id}]
}GET /<索引名称>/_mget //指定索引下检索
{
"docs": [{"_id": "1"},{"_id": "2"}]
}批量增删改
POST /_bulkPOST /<索引名称>/_bulkPOST _bulk
{ "update" : {"_id" : "1", "_index" : "index1", "retry_on_conflict" : 3} }
{ "doc" : {"field" : "value"} }
{ "update" : { "_id" : "0", "_index" : "index1", "retry_on_conflict" : 3} }
{ "script" : { "source": "ctx._source.counter += params.param1", "lang" : "painless", "params" : {"param1" : 1}}, "upsert" : {"counter" : 1}}
{ "update" : {"_id" : "2", "_index" : "index1", "retry_on_conflict" : 3} }
{ "doc" : {"field" : "value"}, "doc_as_upsert" : true }
{ "update" : {"_id" : "3", "_index" : "index1", "_source" : true} }
{ "doc" : {"field" : "value"} }
{ "update" : {"_id" : "4", "_index" : "index1"} }
{ "doc" : {"field" : "value"}, "_source": true}其他
搜索操作API
搜索API
GET /<索引名称>/_search
{"query": {}
}GET /_searchPOST /<索引名称>/_search
{"query": {}
}POST /_search多重搜索API
GET <索引名称>/_msearch
{ }
{"query" : {"match" : { "message": "this is a test"}}}
{"index": "my-index-000002"}
{"query" : {"match_all" : {}}}其他