JUC之Fork/Join
文章目录
- 一、核心摘要: 分而治之的并行之道
- 二、框架的核心组件与API
- 2.1 ForkJoinPool: 专为F/J设计的线程池
- 2.2 ForkJoinTask<V>: 代表一个可并行执行的任务
- 2.3 fork(), join(), invoke()
- 2.4 核心组件
- 三、工作窃取(Work-Stealing)为何高效?
- 3.1 传统线程问题
- 3.2 Fork/Join的解决方案
- 3.3 核心优势
- 四、核心API
- 4.1 ForkJoinPool
- 4.2 ForkJoinTask<V>
- 4.3 RecursiveTask<V>
- 4.4 RecursiveAction
- 五、示例代码
- 5.1 RecursiveTask 进行数组求和(有返回值)
- 5.2 RecursiveAction 处理无返回值任务(数组排序)
- 5.3 文件夹大小计算
- 5.4 使用流程总结【重要】
- 5.4.1 准备阶段
- 5.4.2 执行阶段 (在 `compute()` 方法中)
- 5.4.3 收发阶段
- 5.4.4 关键代码模板(以 `RecursiveTask` 为例)
- 5.4.5 核心要点与最佳实践
- 六、最佳实践与注意事项
- 6.1 ForkJoinPool.commonPool() vs 自定义池
- 6.2 异常处理
- 6.3 注意事项
- 6.4 性能调优建议
- 6.4 与其它并发工具对比
- 6.5 总结
一、核心摘要: 分而治之的并行之道
Fork/Join 框架是 Java 7 引入的一个用于并行执行任务的高效框架。它的核心设计思想源自著名的 “分治”(Divide-and-Conquer) 算法和 “工作窃取”(Work-Stealing) 算法。
- 大量细小的任务会带来巨大的调度开销。
- 任务之间可能存在父子依赖关系,需要相互等待
Fork/Join 的解决方案:
- Fork (分解): 将一个大的计算任务递归地分解(fork)成若干个足够小的、可以并行执行的子任务。
- Join (合并): 等待所有子任务执行完毕,然后将它们的结果合并(join)起来,得到最终结果。
其高效性的秘诀在于背后精妙的工作窃取(Work-Stealing)调度算法
✅ 适用于:可以递归分解的计算密集型任务,如归并排序、快速排序、矩阵运算、树遍历等。
二、框架的核心组件与API
2.1 ForkJoinPool: 专为F/J设计的线程池
这是框架的核心执行器。它不同于普通线程池,内部每个工作线程(Worker Thread)都维护着一个双端队列(Deque)。
- 工作方式: 线程对自己队列中的任务使用 LIFO(后进先出) 的方式执行(
push/pop)。这有利于优先处理最新的(通常也是更小的)任务,提高缓存命中率。 - 窃取方式: 当某个线程自己的队列为空时,它会随机从其他线程的队列尾部使用 FIFO(先进先出) 的方式“窃取”一个任务来执行(
poll)。这减少了线程间的竞争,因为大多数时候线程都在操作自己的队列。
// 创建ForkJoinPool的两种常用方式
ForkJoinPool commonPool = ForkJoinPool.commonPool(); // 使用JVM通用的公共池(推荐)
ForkJoinPool customPool = new ForkJoinPool(4); // 创建指定并行级别(线程数)的自定义池
2.2 ForkJoinTask: 代表一个可并行执行的任务
这是一个抽象类,我们通常使用它的两个子类:
RecursiveAction: 用于没有返回值的任务(例如排序、遍历)。RecursiveTask<V>: 用于有返回值的任务(例如求和、查找)。
你的计算任务需要继承这两个类之一,并重写其 compute() 方法。compute() 方法是 Fork/Join 框架的逻辑核心。
2.3 fork(), join(), invoke()
fork(): 将一个新创建的子任务异步地提交到当前线程所属的ForkJoinPool中执行(实际上是放入自己的工作队列)。join(): 等待子任务执行完成并获取其结果。如果任务抛出异常,join()会抛出ExecutionException。invoke(): 同步地开始执行当前任务,并等待完成返回结果。它等价于先fork()再join(),但通常更高效一些,因为它会直接在当前线程开始计算。
工作窃取算法的流程可以可视化如下:
flowchart TDsubgraph Thread1[工作线程1]direction LRDQ1[双端队列<br>Head -> Task D<br>Task C<br>Task B<br>Tail -> Task A]T1[线程1]T1 -- LIFO pop/push<br>处理最新任务 --> DQ1endsubgraph Thread2[工作线程2<br>(队列已空)]direction LRDQ2[双端队列<br>空]T2[线程2]endT2 -- FIFO poll<br>从其他队列尾部窃取 --> DQ1T2 --> ST[窃取Task A成功<br>并开始执行]
2.4 核心组件
| 组件 | 说明 |
|---|---|
ForkJoinPool | 线程池,管理 ForkJoinWorkerThread,实现工作窃取(Work-Stealing) |
ForkJoinTask | 任务抽象类,有 RecursiveAction 和 RecursiveTask 两个子类 |
RecursiveAction | 无返回值的任务(类似 Runnable) |
RecursiveTask | 有返回值的任务(类似 Callable) |
| 工作窃取 | 空闲线程从其他线程的队列尾部窃取任务,提高负载均衡 |
三、工作窃取(Work-Stealing)为何高效?
3.1 传统线程问题
- 所有线程共享一个任务队列,存在竞争。
- 某些线程可能很忙,而其他线程空闲
3.2 Fork/Join的解决方案
- 每个
ForkJoinWorkerThread拥有自己的双端队列(Deque)。 - 自己提交的任务放入队列头部。
- 空闲时,从其他线程的队列尾部窃取任务。
- 优势:减少竞争,提高 CPU 利用率。
3.3 核心优势
- 减少竞争:
- 每个线程主要操作自己的双端队列,只有在窃取时才会访问别人的队列。
- 窃取行为发生在队列的尾部,而线程自身消费在队列的头部。这种设计进一步减少了数据竞争的可能性。
- 充分利用资源:
- 传统线程池中,如果某个线程因为其任务依赖其他任务而阻塞,整个线程就会闲置。
- 在 Fork/Join 中,一个线程如果无事可做(自己的队列空了),它不会闲着,而是主动去帮其他线程干活。这确保了 CPU 核心始终处于忙碌状态,最大化吞吐量。
- 负载均衡:
- 工作窃取自动实现了负载均衡。繁忙的线程会有很多任务,而空闲的线程会主动从繁忙的线程那里分担任务,无需中央调度器干预。
四、核心API
4.1 ForkJoinPool
ForkJoinPool 是 Fork/Join 框架的核心线程池,负责管理工作线程和任务队列。
- 线程池实现,继承自
AbstractExecutorService。 - 通常使用
ForkJoinPool.commonPool()或自定义实例。
// 使用公共池(推荐大多数场景)
ForkJoinPool pool = ForkJoinPool.commonPool();// 或创建自定义池
ForkJoinPool customPool = new ForkJoinPool(4); // 4 个工作线程// 完整构造方法
ForkJoinPool pool = new ForkJoinPool(int parallelism, // 并行度ForkJoinWorkerThreadFactory factory, // 线程工厂Thread.UncaughtExceptionHandler handler, // 异常处理器boolean asyncMode // 异步模式
);
- 并行度(parallelism):默认等于 CPU 核心数,代表期望的并发线程数
- 异步模式(asyncMode):默认为 false,设置为 true 时,任务队列采用 FIFO 顺序
ava 8 引入了一个公共的 ForkJoinPool 实例,可以通过 ForkJoinPool.commonPool() 获取,适用于大多数场景.
// 使用公共 ForkJoinPool
ForkJoinPool commonPool = ForkJoinPool.commonPool();
commonPool.invoke(task);
4.2 ForkJoinTask
- 抽象类,核心方法:
fork():异步执行任务,不阻塞。join():等待任务完成并获取结果(阻塞)。invoke():提交并等待结果(同步)。
4.3 RecursiveTask
- 用于有返回值的递归任务。
4.4 RecursiveAction
- 用于无返回值的递归任务。
五、示例代码
5.1 RecursiveTask 进行数组求和(有返回值)
这是一个经典的演示用例,将一个大数组的求和任务分解为多个小任务。
package cn.tcmeta.forkjoin;import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import java.util.Random;/*** 使用Fork/Join框架计算大型数组的和* 继承RecursiveTask<Long>,表示这是一个有返回值的任务*/
public class ForkJoinSumCalculator extends RecursiveTask<Long> {// 实际工作的数组private final long[] numbers;// 子任务处理的起始和结束位置private final int start;private final int end;// 不再分解任务的阈值(序列化处理的数组大小)public static final long THRESHOLD = 10_000;/*** 公共构造函数,用于创建主任务*/public ForkJoinSumCalculator(long[] numbers) {this(numbers, 0, numbers.length);}/*** 私有构造函数,用于递归创建子任务*/private ForkJoinSumCalculator(long[] numbers, int start, int end) {this.numbers = numbers;this.start = start;this.end = end;}/*** 核心方法,定义任务的计算逻辑:分解和合并*/@Overrideprotected Long compute() {int length = end - start;// 如果任务足够小,则直接序列化计算,不再分解if (length <= THRESHOLD) {return computeSequentially();}// 分解任务:将大数组一分为二int split = start + length / 2;ForkJoinSumCalculator leftTask =new ForkJoinSumCalculator(numbers, start, split); // 左半部分子任务ForkJoinSumCalculator rightTask =new ForkJoinSumCalculator(numbers, split, end); // 右半部分子任务// 异步执行左子任务(将其推入工作队列)leftTask.fork();// 同步执行右子任务(允许递归分解),同时当前线程可以继续处理// Long rightResult = rightTask.compute(); // 另一种写法:直接递归调用computeLong rightResult = rightTask.invoke(); // 使用invoke更高效// 等待左子任务完成并获取其结果Long leftResult = leftTask.join();// 合并子任务的结果return leftResult + rightResult;}/*** 序列化计算指定范围内数组的和*/private long computeSequentially() {long sum = 0;for (int i = start; i < end; i++) {sum += numbers[i];}// System.out.println(Thread.currentThread().getName() + " computing " + start + " to " + (end-1));return sum;}// 测试代码public static void main(String[] args) {// 创建一个大型数组int arraySize = 10_000_000;long[] numbers = new long[arraySize];Random rand = new Random();for (int i = 0; i < arraySize; i++) {numbers[i] = rand.nextInt(100);}// 使用ForkJoinPool公共池ForkJoinPool pool = ForkJoinPool.commonPool();// 创建主计算任务ForkJoinSumCalculator task = new ForkJoinSumCalculator(numbers);// 记录开始时间long startTime = System.currentTimeMillis();// 提交任务到池并获取最终结果(invoke是同步调用)Long result = pool.invoke(task);long duration = System.currentTimeMillis() - startTime;System.out.println("Fork/Join sum: " + result);System.out.println("Time taken: " + duration + "ms");// 验证结果(序列化计算一次以确保正确性)long seqSum = 0;for (long num : numbers) {seqSum += num;}System.out.println("Expected sum: " + seqSum);System.out.println("Results match: " + (result.equals(seqSum)));}
}
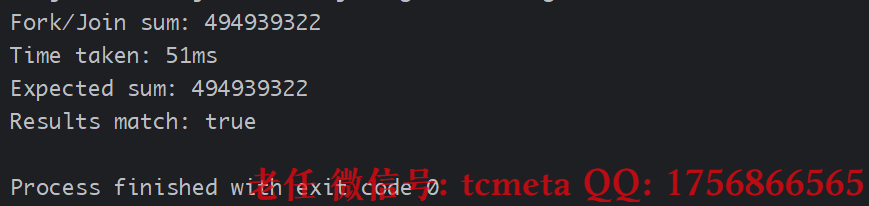
关键点说明
- 阈值(THRESHOLD): 选择合适的阈值至关重要。太小会导致过度分解,增加调度开销;太大会导致并行度不足。需要通过测试来权衡。
- 递归分解:
compute方法中递归地创建新的子任务。 fork()与join()的顺序: 先fork左任务,然后直接计算(invoke)右任务,最后join左任务。这个顺序可以最大化并行性。- 结果合并: 子任务的结果通过简单的加法合并
5.2 RecursiveAction 处理无返回值任务(数组排序)
虽然Java标准库有更高效的并行排序,但我们可以用 RecursiveAction 实现一个简单的并行快速排序来演示。
package cn.tcmeta.forkjoin;import java.util.Arrays;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
import java.util.Random;/*** 使用RecursiveAction实现一个简单的并行快速排序*/
public class ParallelQuickSort extends RecursiveAction {private final int[] array;private final int low;private final int high;private static final int THRESHOLD = 1000; // 序列化排序的阈值public ParallelQuickSort(int[] array) {this(array, 0, array.length - 1);}private ParallelQuickSort(int[] array, int low, int high) {this.array = array;this.low = low;this.high = high;}@Overrideprotected void compute() {if (high - low <= THRESHOLD) {// 任务足够小,直接序列化排序Arrays.sort(array, low, high + 1); // 注意Arrays.sort的toIndex是exclusivereturn;}// 否则,进行分区操作int pivotIndex = partition(array, low, high);// 递归创建子任务处理分区两侧ParallelQuickSort leftTask = new ParallelQuickSort(array, low, pivotIndex - 1);ParallelQuickSort rightTask = new ParallelQuickSort(array, pivotIndex + 1, high);// 同时invokeAll提交所有子任务,并等待它们完成invokeAll(leftTask, rightTask);}/*** 快速排序的分区函数(Lomuto分区方案)*/private int partition(int[] array, int low, int high) {int pivot = array[high];int i = low;for (int j = low; j < high; j++) {if (array[j] <= pivot) {swap(array, i, j);i++;}}swap(array, i, high);return i;}private void swap(int[] array, int i, int j) {int temp = array[i];array[i] = array[j];array[j] = temp;}public static void main(String[] args) {int size = 10_000_000;int[] array = new int[size];Random rand = new Random();for (int i = 0; i < size; i++) {array[i] = rand.nextInt(size);}int[] arrayCopy = Arrays.copyOf(array, array.length);ForkJoinPool pool = new ForkJoinPool();// 并行排序long startTime = System.currentTimeMillis();pool.invoke(new ParallelQuickSort(array));long parallelTime = System.currentTimeMillis() - startTime;System.out.println("Parallel sort time: " + parallelTime + "ms");// 验证排序是否正确System.out.println("Is sorted: " + isSorted(array));// 序列化排序对比startTime = System.currentTimeMillis();Arrays.sort(arrayCopy);long sequentialTime = System.currentTimeMillis() - startTime;System.out.println("Sequential sort time: " + sequentialTime + "ms");System.out.println("Speedup: " + (sequentialTime / (double) parallelTime));}private static boolean isSorted(int[] array) {for (int i = 0; i < array.length - 1; i++) {if (array[i] > array[i + 1]) {return false;}}return true;}
}
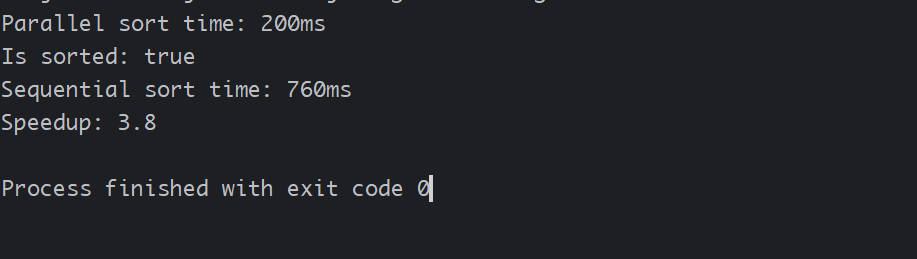
关键点说明
RecursiveAction: 因为排序是原地操作,不需要返回结果。invokeAll(): 这是一个方便的静态方法,用于提交多个子任务并等待它们全部完成。它比按顺序调用fork()和join()更高效。- 注意同步: 在这个例子中,所有任务都在操作同一个数组的不同部分。你必须确保任务之间处理的区间没有重叠,否则会导致数据竞争和错误。
5.3 文件夹大小计算
计算指定文件夹下所有文件的总大小:
package cn.tcmeta.forkjoin;import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;/*** 计算文件夹总大小的 Fork/Join 任务*/
public class FolderSizeTask extends RecursiveTask<Long> {private File folder;public FolderSizeTask(File folder) {this.folder = folder;}@Overrideprotected Long compute() {// 如果是文件,直接返回文件大小if (folder.isFile()) {return folder.length();}// 如果是文件夹,获取所有子文件/子文件夹File[] files = folder.listFiles();if (files == null) { // 无法访问的文件夹return 0L;}List<FolderSizeTask> tasks = new ArrayList<>();long totalSize = 0;for (File file : files) {FolderSizeTask task = new FolderSizeTask(file);tasks.add(task);// 拆分任务(fork)// System.out.printf("线程名称: 【%s】 , msg: %s \n", Thread.currentThread().getName(), " 执行任务了~~~");task.fork();}// 合并所有子任务的结果for (FolderSizeTask task : tasks) {totalSize += task.join();}return totalSize;}public static void main(String[] args) {// 计算当前项目目录的大小File folder = new File(".");ForkJoinPool pool = ForkJoinPool.commonPool();FolderSizeTask task = new FolderSizeTask(folder);long startTime = System.currentTimeMillis();long size = pool.invoke(task);long endTime = System.currentTimeMillis();System.out.println("文件夹总大小: " + size + " 字节");System.out.println("计算耗时: " + (endTime - startTime) + "ms");pool.shutdown();}
}
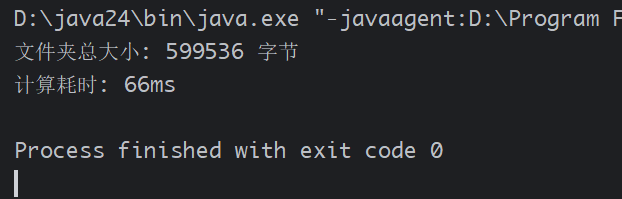
5.4 使用流程总结【重要】
Fork/Join 框架的使用遵循一个清晰、模式化的流程,核心思想是 “分而治之” 。其工作流程可以精炼地概括为以下图表,然后再展开详细说明:
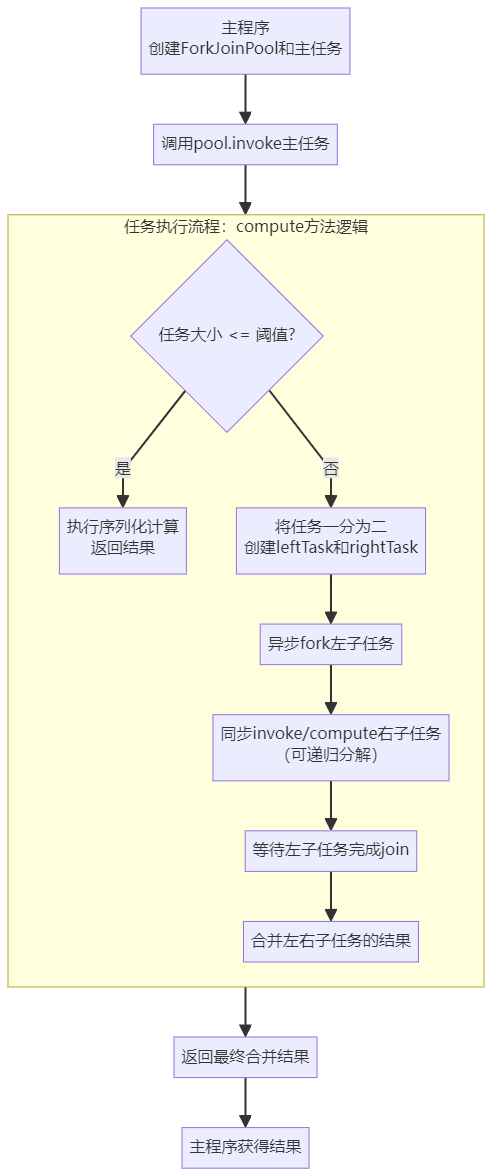
5.4.1 准备阶段
- 定义计算任务 (Define the Task)
- 创建一个类,继承
RecursiveTask<V>(有返回值)或RecursiveAction(无返回值)。 - 核心:重写
compute()方法,在其中实现任务分解和合并的逻辑。 - 在任务类中定义:
- 数据范围: 用于处理问题的某个子集(如数组的起始和结束索引)。
- 阈值 (THRESHOLD): 一个关键常量,决定任务何时小到可以顺序执行而不再分解。
- 创建一个类,继承
- 创建线程池 (Create the ForkJoinPool)
- 通常使用
ForkJoinPool.commonPool()获取 JVM 管理的通用公共池。 - 或者,使用
new ForkJoinPool(int parallelism)创建一个指定并行级别的自定义池。
- 通常使用
5.4.2 执行阶段 (在 compute() 方法中)
这是一个递归过程,每一步都遵循以下决策图:
- 判断是否达到阈值 (Check Threshold)
- 在
compute()方法开始,首先判断当前任务的大小是否小于或等于预设的阈值。 - 如果“是”:直接执行序列化计算,返回结果。这是递归的基准情况 (base case)。
- 如果“否”:继续执行步骤 4,进行任务分解。
- 分解任务 (Split the Task)
- 将当前大任务合理地分割成两个(或多个)更小的子任务。
- 通常是通过创建当前任务类的两个新实例,每个实例负责原问题的一个子集(如左半部分和右半部分)。
- 异步提交子任务 (Fork the Sub-tasks)
- 调用其中一个子任务的
.fork()方法。该方法会将其异步地提交到工作线程队列中,等待执行。 - 最佳实践:通常先
fork一个任务,然后直接处理另一个任务。
- 同步处理并等待结果 (Join and Combine)
- 对于另一个子任务,可以调用
.invoke()或.compute()来同步地在当前线程处理它(这允许递归分解)。 - 调用之前通过
fork()提交的子任务的.join()方法。该方法会阻塞当前线程,直到该子任务计算完成并返回结果。 - 最后,将各个子任务的结果合并成一个整体结果。
简化 API: 对于两个子任务,可以使用 invokeAll(subTask1, subTask2) 方法来替代 fork+join 的组合,它更简洁且在某些情况下更高效。
5.4.3 收发阶段
- 启动并获取最终结果 (Invoke the Main Task)
- 在主程序中,将第一步创建好的主任务提交给
ForkJoinPool。 - 调用
pool.invoke(mainTask)来同步地启动执行并获取最终结果。也可以使用pool.submit(mainTask).join()。
- 关闭线程池 (Shutdown the Pool - Optional)
- 如果是自定义的
ForkJoinPool,使用完后应调用pool.shutdown()。 - 如果使用的是
commonPool,通常不需要也不应该关闭它。
5.4.4 关键代码模板(以 RecursiveTask 为例)
// 1. 定义任务
class MyTask extends RecursiveTask<ResultType> {private static final int THRESHOLD = ...; // 定义阈值private final DataType data;private final int start;private final int end;MyTask(DataType data, int start, int end) {this.data = data;this.start = start;this.end = end;}@Overrideprotected ResultType compute() {// 2. 判断是否达到阈值if ((end - start) <= THRESHOLD) {// 3. 执行基准计算return computeSequentially();}// 4. 分解任务int mid = (start + end) / 2;MyTask leftTask = new MyTask(data, start, mid);MyTask rightTask = new MyTask(data, mid, end);// 5. 异步提交左任务leftTask.fork();// 6. 同步计算右任务 (递归发生在这里)ResultType rightResult = rightTask.compute(); // 或 rightTask.invoke()// 6. 等待左任务完成并获取结果ResultType leftResult = leftTask.join();// 6. 合并结果return combine(leftResult, rightResult);}private ResultType computeSequentially() { ... }private ResultType combine(ResultType l, ResultType r) { ... }
}// 主程序
public class Main {public static void main(String[] args) {DataType data = ...;// 7. 创建线程池和主任务ForkJoinPool pool = ForkJoinPool.commonPool();MyTask mainTask = new MyTask(data, 0, data.length);// 7. 启动并获取结果ResultType result = pool.invoke(mainTask);System.out.println("Result: " + result);// 8. 自定义池需要关闭// pool.shutdown();}
}
5.4.5 核心要点与最佳实践
- 阈值的选择至关重要:需要通过测试和性能分析来找到最佳值。太小则任务管理开销大,太大则无法充分利用并行。
- 避免阻塞操作:Fork/Join 框架设计用于计算密集型任务,不要在
compute()中执行 I/O 或同步阻塞操作。 - 任务独立性:确保子任务之间没有共享的可变状态,或者使用线程安全的方式访问共享状态。
fork()与join()的顺序:- 先
fork一个任务,然后对另一个任务调用compute或invoke,最后join第一个任务。这种顺序可以减少线程的等待时间。 - 使用
invokeAll可以简化代码并优化执行。
- 先
- 结果合并:合并操作应该是相对轻量级的,否则它可能成为新的性能瓶颈。
- 异常处理:子任务中的异常会在调用
join()时被包装成ExecutionException抛出,需要在主线程中捕获和处理。
六、最佳实践与注意事项
6.1 ForkJoinPool.commonPool() vs 自定义池
| 对比项 | commonPool | 自定义 ForkJoinPool |
|---|---|---|
| 创建方式 | ForkJoinPool.commonPool() | new ForkJoinPool(n) |
| 线程数 | 默认为 Runtime.getRuntime().availableProcessors() - 1 | 可自定义 |
| 适用场景 | 大多数通用并行任务 | 需要隔离、控制线程数的场景 |
| 风险 | 所有使用 commonPool 的代码共享线程,可能相互影响 | 资源隔离,更可控 |
| 关闭 | 无法手动关闭 | 可调用 shutdown() |
✅ 建议:
- 简单并行计算 → 使用
commonPool- 关键业务、长时间运行任务 → 使用自定义池,避免影响其他组件。
6.2 异常处理
ForkJoinTask 中的异常会被封装为 RuntimeException,可通过 get() 或 join() 抛出。
try {long result = task.join(); // 可能抛出 ExecutionException
} catch (CompletionException e) {Throwable cause = e.getCause();if (cause instanceof IllegalArgumentException) {System.err.println("任务参数错误: " + cause.getMessage());}
}
6.3 注意事项
- 避免阻塞操作: Fork/Join 框架设计用于
计算密集型任务。如果在任务中执行 I/O 或同步操作,会阻塞工作线程,严重影响框架性能。 - 谨慎选择阈值: 阈值的选择需要在任务分解开销和并行收益之间取得平衡。通常需要通过性能测试来确定最佳值。
- 任务独立性: 确保子任务是独立的,避免共享可变状态。如果必须共享,请使用线程安全的结构或同步机制。
- 避免不必要的拆分: 不要在
compute()方法中创建不会被使用的子任务(例如,在条件分支中创建了任务但没fork),这会浪费资源。 - 异常处理:
ForkJoinTask可能会抛出异常。join()方法会抛出ExecutionException,你需要调用getCause()来获取原始异常。 - 调试: Fork/Join 任务的调试可能比较困难,因为执行是异步和并发的。使用有意义的线程名称和良好的日志记录会有帮助。
6.4 性能调优建议
- 合理设置阈值(THRESHOLD)
- 太小:任务拆分过细,开销大。
- 太大:并行度不足。
- 建议:根据任务类型和 CPU 核心数调整。
- 避免阻塞操作
- Fork/Join 适用于计算密集型任务。
- 避免在
compute()中进行 I/O、数据库操作等阻塞调用。
- 监控与诊断
- 使用
pool.getStealCount()查看任务窃取次数。 - 使用 JMX 监控
ForkJoinPool状态。
- 使用
6.4 与其它并发工具对比
| 特性 | Fork/Join 框架 | ExecutorService | CompletionService |
|---|---|---|---|
| 适用场景 | CPU 密集型、可拆分任务 | 通用任务执行 | 按完成顺序获取结果 |
| 任务调度 | 工作窃取算法 | 线程池调度 | 基于 ExecutorService |
| 并行效率 | 高(针对可拆分任务) | 中 | 中 |
| 编程复杂度 | 较高 | 低 | 中 |
| 结果合并 | 自动支持 | 手动处理 | 按完成顺序 |
6.5 总结
| 特性 | 说明 |
|---|---|
| 核心思想 | 分而治之(Fork & Join) |
| 核心机制 | 工作窃取(Work-Stealing)算法 |
| 关键类 | ForkJoinPool, RecursiveTask, RecursiveAction |
| 优势 | 高效利用多核,减少线程竞争 |
| 适用 | 可递归分解的计算密集型任务 |
| 注意 | 避免阻塞操作,合理设置阈值 |
💡 一句话总结:
Fork/Join 框架是 Java 中实现高效并行计算的“瑞士军刀”,它通过“分而治之”和“工作窃取”两大利器,让开发者能够轻松写出高性能的并行程序。
往期资源获取:
链接: https://pan.baidu.com/s/1imlp_hLQqhuIdTbLpgwuGg 提取码: dq5r