python + unicorn + xgboost + pytorch 搭建机器学习训练平台遇到的问题
1.背景
前段时间,使用 python + unicorn + xgboost + pytorch 写了一个机器学习训练平台的后端服务,
根据公司开发需要,需具备两种需求:1. 可以本地加载使用;2.支持web服务,
2. 使用本地加载使用
2.1 问题
针对第一种方式,为避免客户安装使用python 环境,因此将项目打包成.exe ,使用pyinstaller 进行打包,但
1.遇到体积大的问题,于是根据网上建议,使用为目创建虚拟环境,同时根据requiremnts ,将本项目所用的包全部放在虚拟环境下,最终2G 项目被打包成800兆,项目可在window上启动;
2.项目启动后,测试发现,使用.exe (onedir)项目启动效率比使用vscode 启动项目,要低非常多,大概降低5-6倍;
后来使用各种方法:
1. 网上说,除了pyinstaller 外,可使用Nuitka 编译打包,但经过测试,发现没有作用;
2.尝试使用嵌入式 Python + 脚本启动(性能 100%),经测试发现,效果还是不行;
3.使用Conda 安装带 MKL 的完整环境 ,测试发现:效果还是差;
那么到底是什么影响打包成.exe 的性能变差呢?
1.XGBoost 的 n_jobs=-1 会 spawn N 个子进程(Windows 必然 spawn);
2.每个子进程启动时:
初始化新的 Python 解释器
走 PyInstaller runtime hook 重定向模块搜索路径
重新加载
numpy,scipy,xgboost等.pyd(C++ 库初始化)
3.所有这些步骤在源码 + fork (linux)下几乎是 0 成本,但在 spawn(window) 下是全量重复执行;
4.模型越大、并行核心数越多,额外开销就越大
2.2 解决办法
针对于window 的.exe ,
os.environ['OMP_NUM_THREADS'] = '1'
os.environ['OPENBLAS_NUM_THREADS'] = '1'
os.environ['MKL_NUM_THREADS'] = '1'
os.environ['VECLIB_MAXIMUM_THREADS'] = '1'
os.environ['NUMEXPR_NUM_THREADS'] = '1'
torch.set_num_threads(1)
xgboost(n_jobs=1)
3. 支持web 服务
3.1 问题
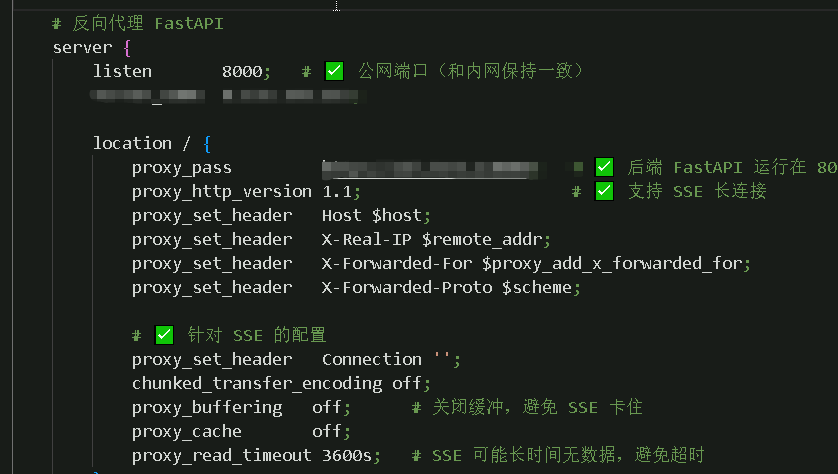
对于fastapi + unicorn + xgboost + pytorch ,其实更适合用于web 项目,因此,我将项目拷贝到服务器
在服务器上使用nginx 反向代理
但这里遇到2个问题:
问题1:针对本地加载,我接口端口用的是8000,因此接口都是
http:://127.0.0.1:8000/ 接口名
而我使用web 端口之后,nginx 默认使用80端口,因此,对内网代理转发后,会变成
http::// 公网id :80(可省略)/接口名,导致,和前端对接的时候,前端需要根据是本地pc 部署还是web 部署 使用不同的接口
问题2:
在训练过程中的数据发送,选择sse 方式,因此需要在nginx 配置sse
3.2 解决方案
对于web 端,内网端口改成8080 (或者其他非8000端口),然后nginx 监听端口从80 改成8000,
C:\nginx\nginx-1.28.0>start nginx.exe
C:\nginx\nginx-1.28.0>nginx -s reload
C:\nginx\nginx-1.28.0>nginx -s quit