开源大模型如何选择?GPT-OSS综合评估
记录下一些结论:
通过对OpenAI的GPT-OSS模型(20B和120B参数,混合专家架构)与6个主流开源大语言模型(涵盖14.7B-235B参数,含密集型和稀疏型架构)的跨领域评估,得出以下结论:
-
GPT-OSS模型的Inverse Scaling现象:参数更少的GPT-OSS 20B在多个基准测试中持续优于更大的GPT-OSS 120B,违背了传统的模型缩放定律(参数越多性能越好)。
-
GPT-OSS模型在当前开源大语言模型中处于中等水平,整体性能落后于最新架构
-
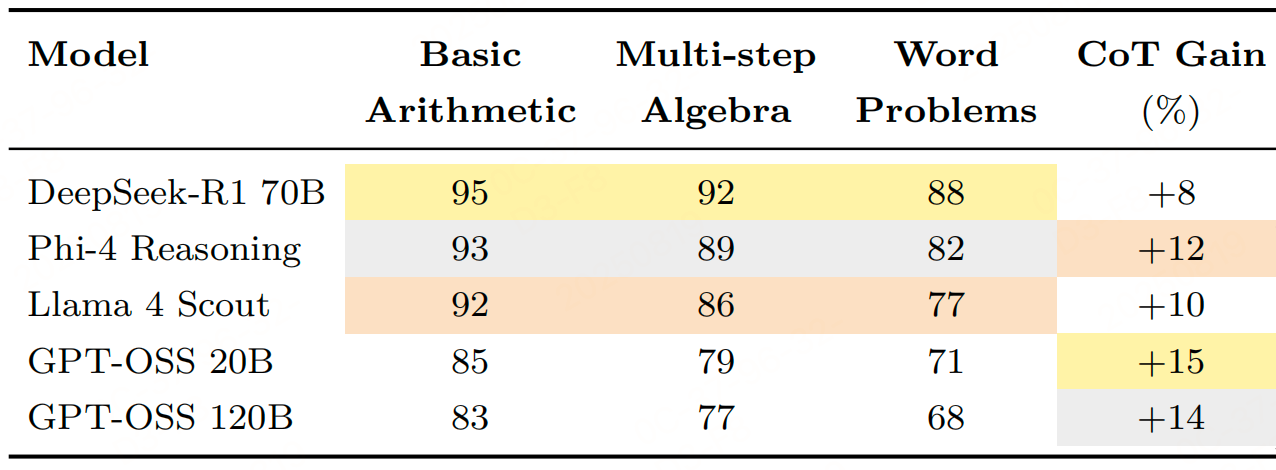
代码生成表现相对突出,20B和120B的准确率(73%、71%)接近部分更优模型,且输出更简洁(平均token数更少),效率更高。多语言能力(如C-Eval中文任务)表现极差,远低于Qwen 3 235B(89%)等针对性优化模型;专业领域(医学、法律)也较弱。 通过“思维链提示”可提升15%性能,但在数值精度(如单位转换)上仍易出错。
-
GPT-OSS模型输出更简洁(2000-3000字符),在长度适宜性、可读性和清晰度上表现更优,避免了其他模型(如Qwen 3 235B)因暴露内部推理导致的冗长(超13万字符)问题,更符合实际应用需求。
-
对模型设计的启发:混合专家(MoE)架构的缩放并非必然带来性能提升,需优化路由机制和训练策略;参数规模并非唯一决定因素,架构设计、训练数据和任务适配对性能影响更大;开源模型需在“能力-效率”间平衡,小参数模型(如20B)在成本敏感场景中更具竞争力。
评估
八个评估模型的多维度性能比较。 GPT-OSS 模型(高亮显示)表现出中等级别的性能,在代码生成方面具有显著优势,但在多语言任务中存在不足。
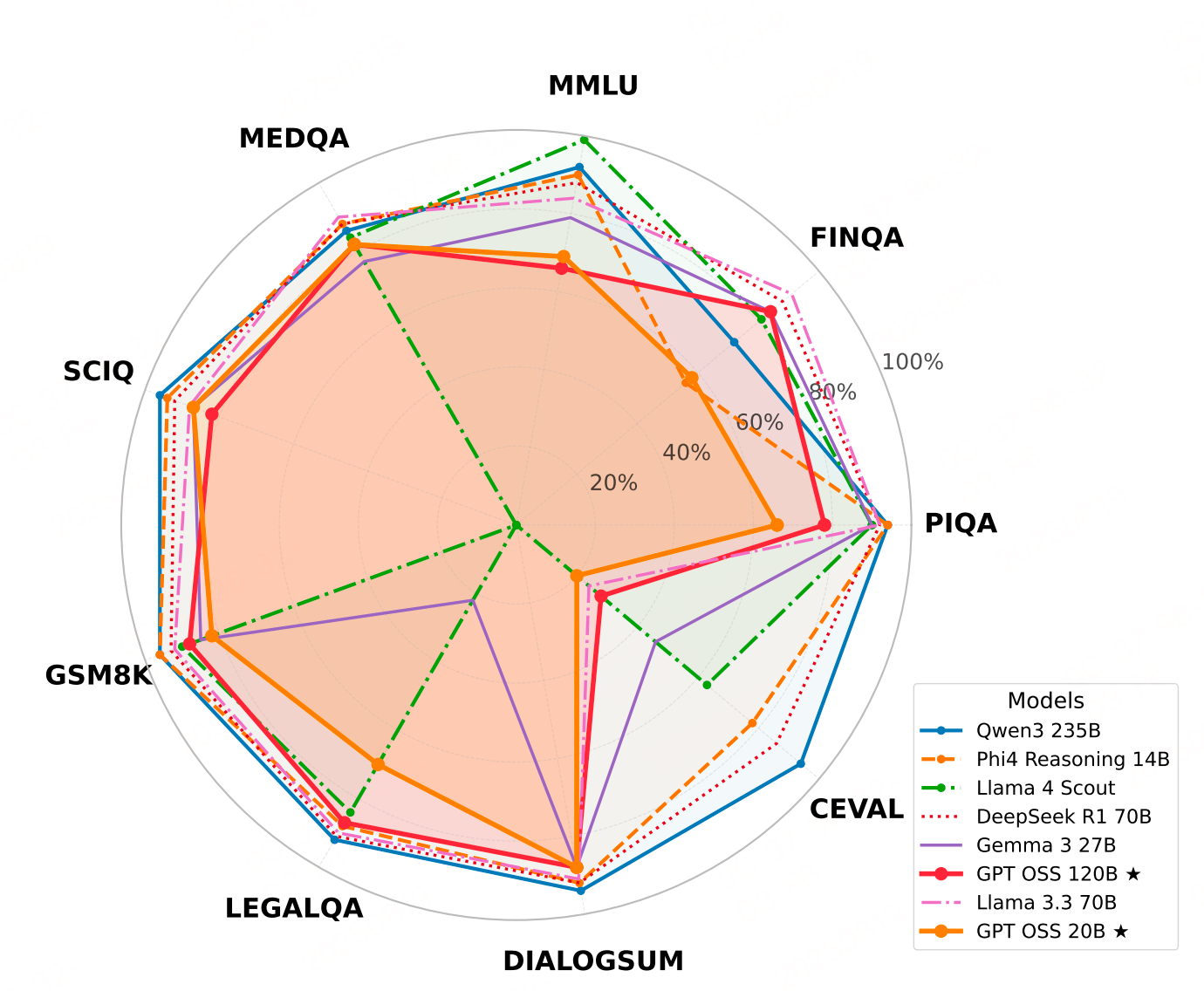
1、参与评估的开源大模型
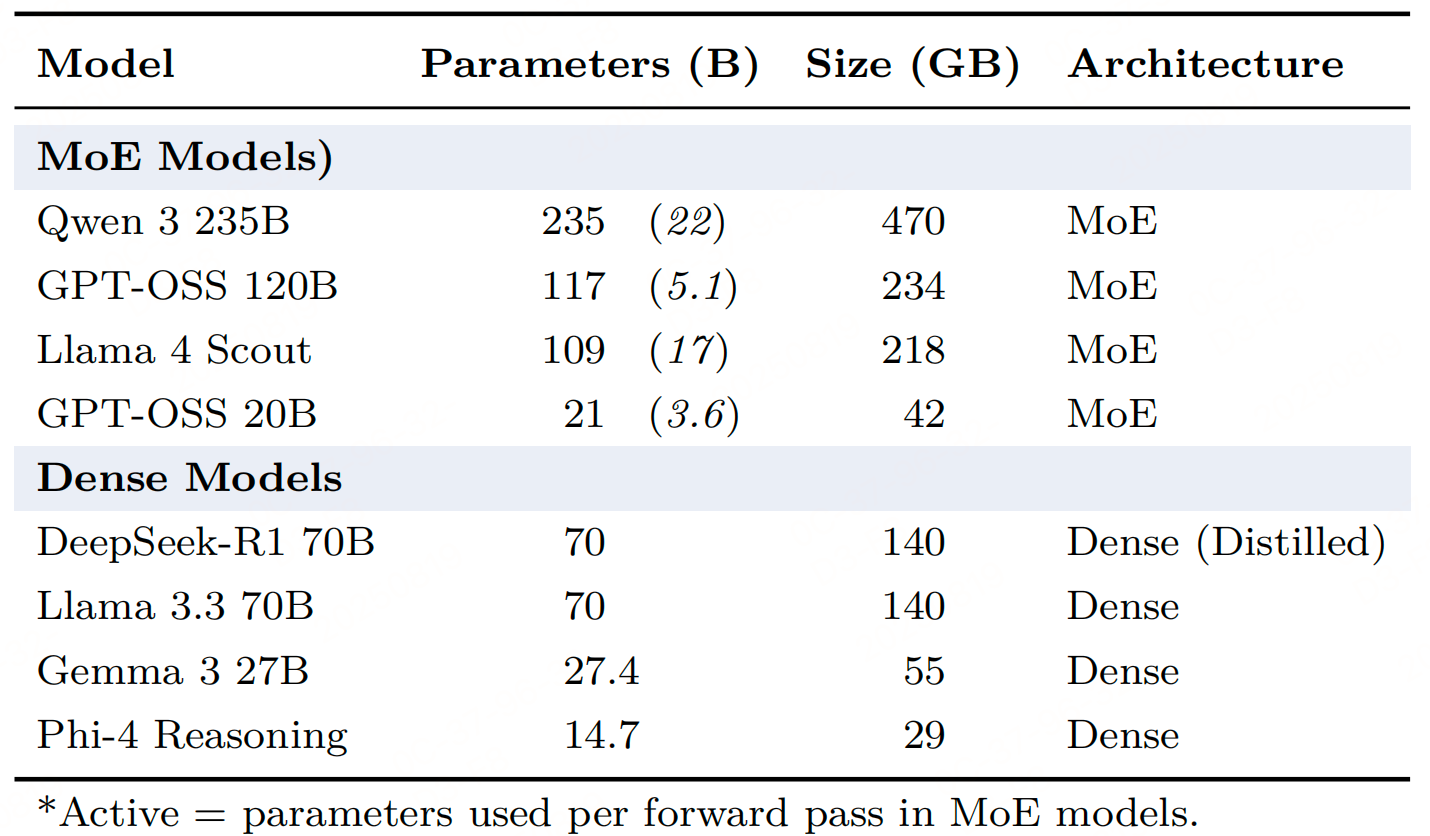
2、 所有评估基准的综合性能总结
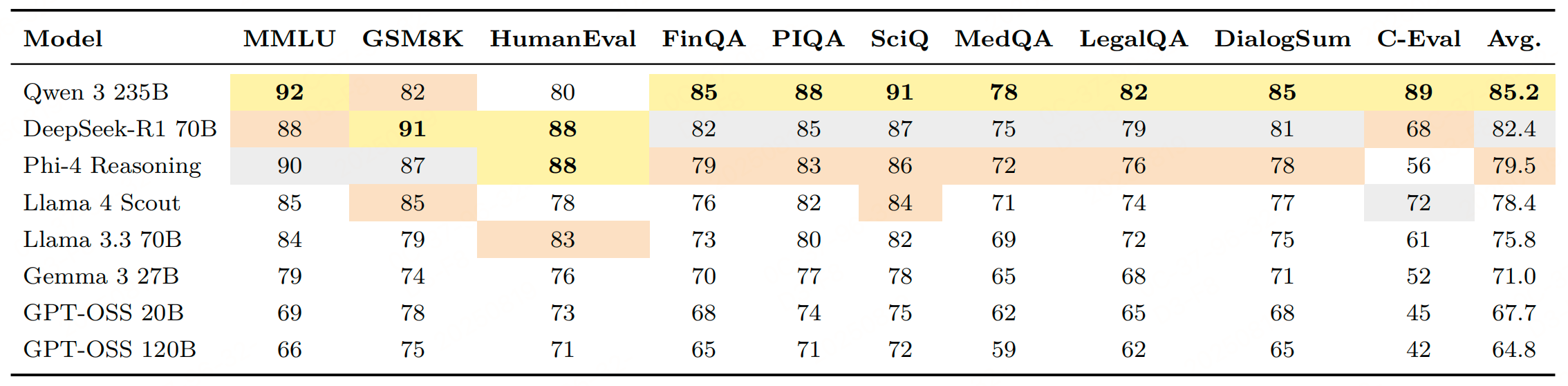
3、使用通用提示词在各基准类别中的性能排名
![误差条表示基于 Efron 和 Tibshirani [69] 的 Bootstrap 方
法计算的 95% 置信区间。Llama-4-Scout 得分较低,原因是触发的安全特性阻止了模型对通用提示词作出响应。](https://i-blog.csdnimg.cn/img_convert/d7338e296df2e080256685ddbafdf26b.png)
4、数学推理表现
5、性能分布-评估类别
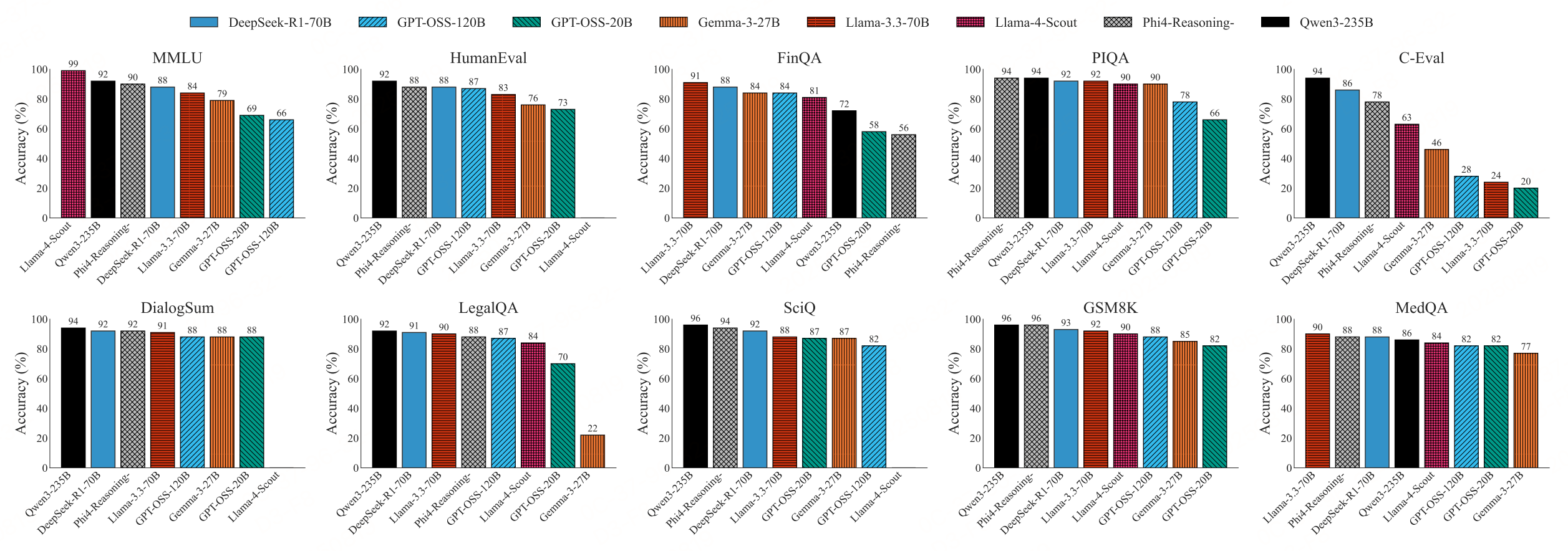
6、逻辑推理任务
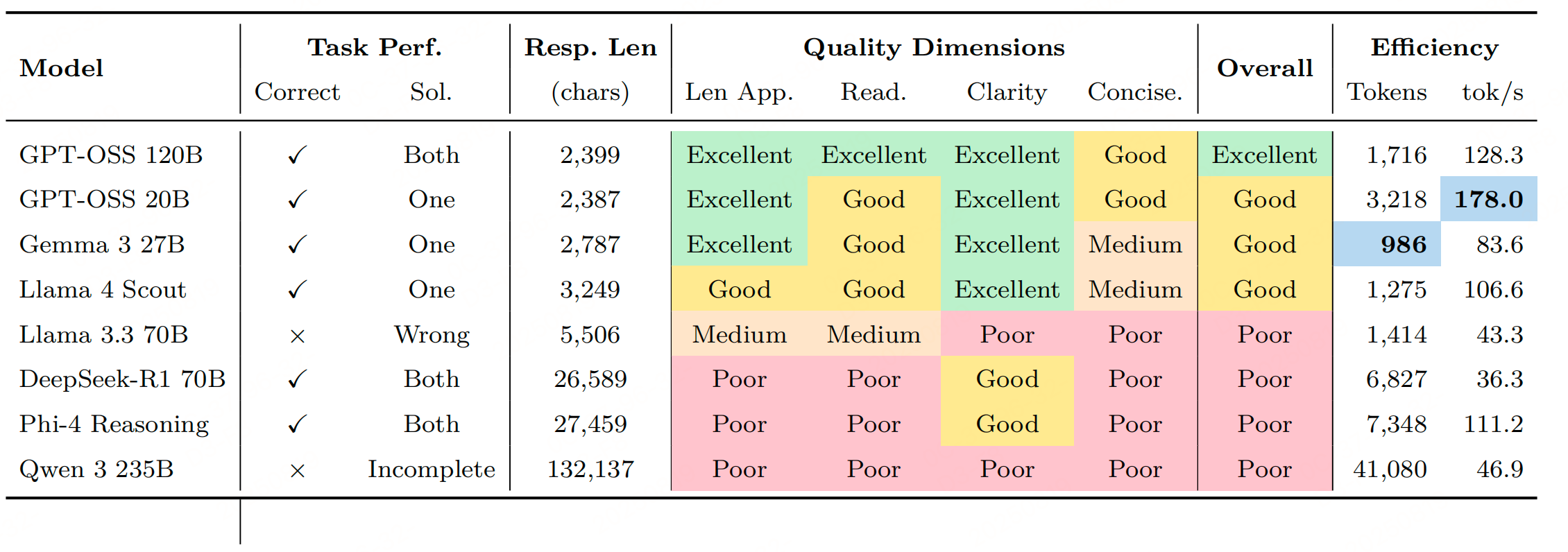
7、所有模型在聚合数据集上的 Token 计数分布
分析揭示了不同的响应长度模式,与推理优化架构相比,GPT-OSS 模型展现出显著简洁的输出
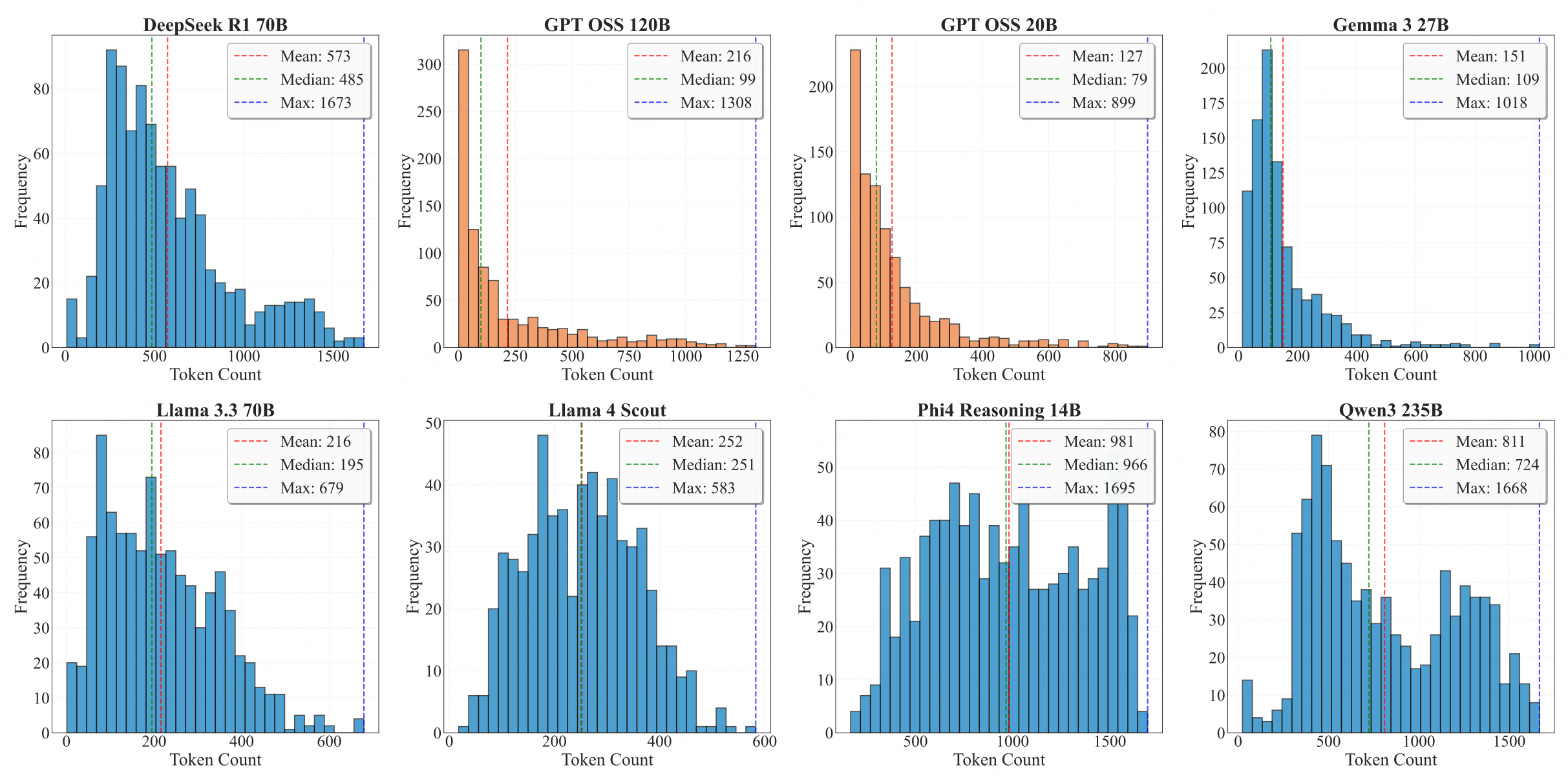
参考文献:Is GPT-OSS Good? A Comprehensive Evaluation of OpenAI’s Latest Open Source Modelshttps://arxiv.org/pdf/2508.12461v1