Building Systems with the ChatGPT API 使用 ChatGPT API 搭建系统(第二章学习笔记及总结)
吴恩达老师案例使用ChatGPT API,这里我使用百度千帆API代替,百度千帆API获取方式:千帆大模型兼容openai接口,怎么详细操作并调用千帆大模型api?-CSDN博客
章节导航:
👉第二章:Language Models, the Chat Format and Tokens(语言模型,提问范式与 Token)
目录
2. Language Models, the Chat Format and Tokens(语言模型,提问范式与 Token)
2.1 语言模型
什么是LLM?
基础 LLM
指令微调(Instruction Tuned)LLM
如何将基础语言模型转变为指令微调语言模型呢?
2.2 Tokens
2.3 提问范式
2. Language Models, the Chat Format and Tokens(语言模型,提问范式与 Token)
2.1 语言模型
什么是LLM?
大语言模型(英文:Large Language Model,缩写LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM是拥有数十亿到干亿参数、具有强大的语言理解和生成能力的模型。
基础 LLM
随着 LLM 的发展,其大致可以分为两种类型,后续称为基础 LLM 和指令微调(Instruction Tuned)LLM。基础LLM是基于文本训练数据,训练出预测下一个单词能力的模型。其通常通过在互联网和其他来源的大量数据上训练,来确定紧接着出现的最可能的词。
例如,如果你以“从前,有一只独角兽”作为 Prompt ,基础 LLM 可能会继续预测“她与独角兽朋友共同生活在一片神奇森林中”。但是,如果你以“法国的首都是什么”为 Prompt ,则基础 LLM 可能会根据互联网上的文章,将回答预测为“法国最大的城市是什么?法国的人口是多少?”,因为互联网上的文章很可能是有关法国国家的问答题目列表。
指令微调(Instruction Tuned)LLM
与基础语言模型不同,指令微调 LLM 通过专门的训练,可以更好地理解并遵循指令。举个例子,当询问“法国的首都是什么?”时,这类模型很可能直接回答“法国的首都是巴黎”。指令微调 LLM 的训练通常基于预训练语言模型,先在大规模文本数据上进行预训练,掌握语言的基本规律。在此基础上进行进一步的训练与微调(finetune),输入是指令,输出是对这些指令的正确回复。有时还会采用RLHF(reinforcement learning from human feedback,人类反馈强化学习)技术,根据人类对模型输出的反馈进一步增强模型遵循指令的能力。通过这种受控的训练过程。指令微调 LLM 可以生成对指令高度敏感、更安全可靠的输出,较少无关和损害性内容。因此。许多实际应用已经转向使用这类大语言模型。
吴恩达老师的文章文章也是基于指令微调(Instruction Tuned)LLM进行实践。
如何将基础语言模型转变为指令微调语言模型呢?
这也就是训练一个指令微调语言模型(例如ChatGPT)的过程。 首先,在大规模文本数据集上进行无监督预训练,获得基础语言模型。 这一步需要使用数千亿词甚至更多的数据,在大型超级计算系统上可能需要数月时间。 之后,使用包含指令及对应回复示例的小数据集对基础模型进行有监督 fine-tune,这让模型逐步学会遵循指令生成输出,可以通过雇佣承包商构造适合的训练示例。 接下来,为了提高语言模型输出的质量,常见的方法是让人类对许多不同输出进行评级,例如是否有用、是否真实、是否无害等。 然后,您可以进一步调整语言模型,增加生成高评级输出的概率。这通常使用基于人类反馈的强化学习(RLHF)技术来实现。 相较于训练基础语言模型可能需要数月的时间,从基础语言模型到指令微调语言模型的转变过程可能只需要数天时间,使用较小规模的数据集和计算资源。
2.2 Tokens
到目前为止对 LLM 的描述中,我们将其描述为一次预测一个单词,但实际上还有一个更重要的技术细节。即 LLM 实际上并不是重复预测下一个单词,而是重复预测下一个 token 。对于一个句子,语言模型会先使用分词器将其拆分为一个个 token ,而不是原始的单词。对于生僻词,可能会拆分为多个 token 。这样可以大幅降低字典规模,提高模型训练和推断的效率。例如,对于 "Learning new things is fun!" 这句话,每个单词都被转换为一个 token ,而对于较少使用的单词,如 "Prompting as powerful developer tool",单词 "prompting" 会被拆分为三个 token,即"prom"、"pt"和"ing"

因此,语言模型以 token 而非原词为单位进行建模,这一关键细节对分词器的选择及处理会产生重大影响。开发者需要注意分词方式对语言理解的影响,以发挥语言模型最大潜力。
❗❗❗ 对于英文输入,一个 token 一般对应 4 个字符或者四分之三个单词;对于中文输入,一个 token 一般对应一个或半个词。不同模型有不同的 token 限制,需要注意的是,这里的 token 限制是输入的 Prompt 和输出的 completion 的 token 数之和,因此输入的 Prompt 越长,能输出的 completion 的上限就越低。 ChatGPT3.5-turbo 的 token 上限是 4096。
参考LLM工作流程:LLM(大语言模型)的工作原理 图文讲解-CSDN博客
2.3 提问范式
语言模型提供了专门的“提问格式”,可以更好地发挥其理解和回答问题的能力。
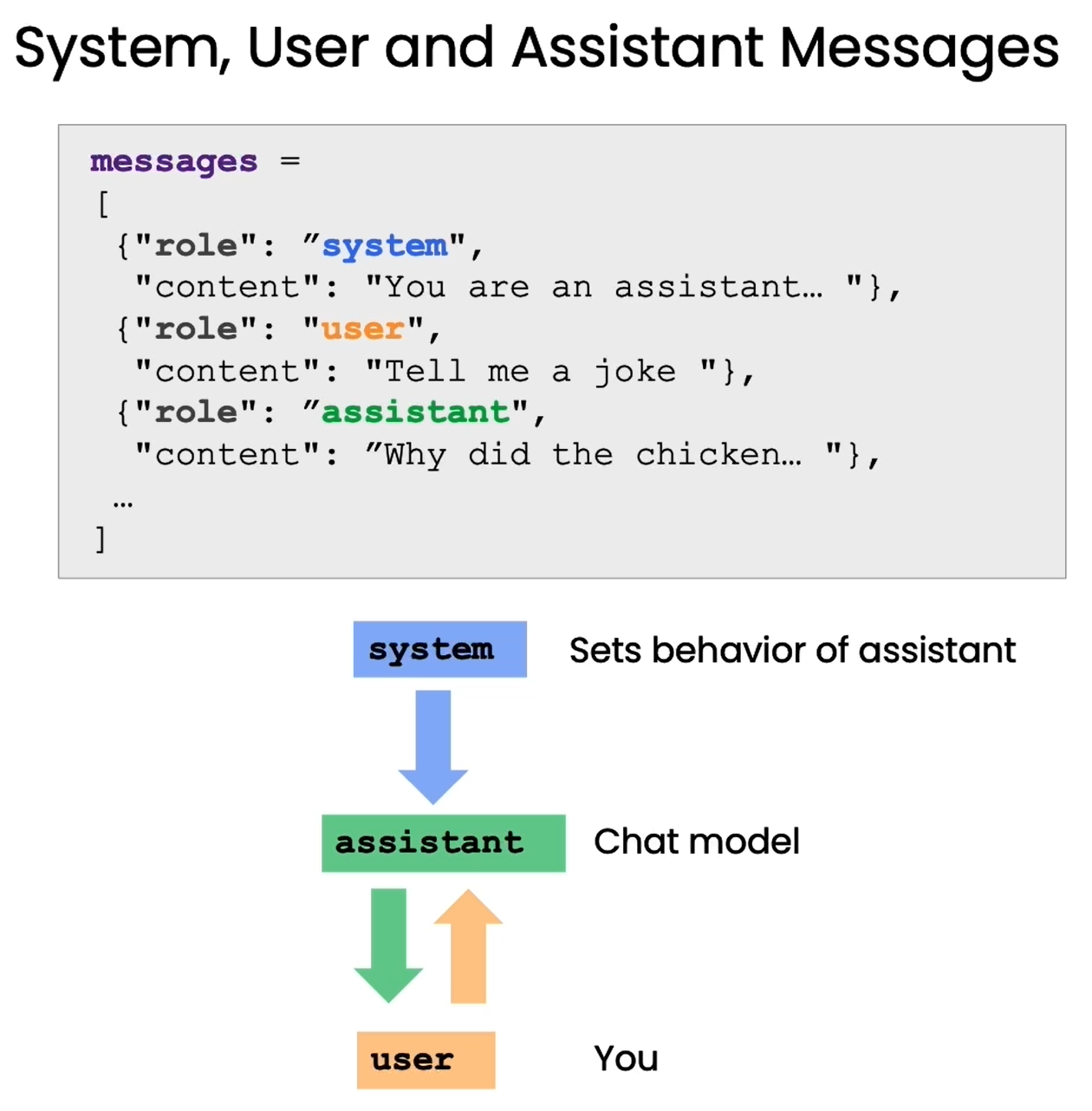
System 信息用于指定模型的规则,例如设定、回答准则等,而 assistant 信息就是让模型完成的具体指令,user信息则是模拟用户的问题。
通过这种提问格式,我们可以明确地角色扮演,让语言模型理解自己就是助手这个角色,需要回答问题。这可以减少无效输出,帮助其生成针对性强的回复。