初识CNN04——经典网络认识
系列文章目录
初识CNN01——认识CNN
初识CNN02——认识CNN2
初识CNN03——预训练与迁移学习
文章目录
- 系列文章目录
- 前言
- 一、LeNets5——现代CNN的奠基之作
- 1.1 模型整体结构
- 1.2 网络细节
- 1.3 总结
- 二、AlexNet——掀起深度学习的浪潮
- 2.1 整体结构
- 2.2 创新点
- 三、VGGNet——深度和小卷积核
- 2.1 VGG版本
- 2.2 核心思想
- 2.3 存在问题
- 总结
前言
本文对于各大经典网络结构仅作简要分享,详细内容请看论文原文。
一、LeNets5——现代CNN的奠基之作
LeNet-5是由Yann LeCun团队于1998年提出的经典卷积神经网络(CNN),专为手写数字识别设计,是第一个成功应用于手写数字识别问题并产生实际商业(邮政行业)价值的卷积神经网络。它在MNIST数据集上实现了99.2%的准确率,并推动了深度学习在计算机视觉领域的发展。
论文:《Gradient-based learning appl ied to document re cognition》

1.1 模型整体结构
输入图像为32×32的灰度图。

一共七层,3个卷积层,2个池化层,2个全连接层,所有激活函数采用Sigmoid。其中
- 三个卷积层:
- C1包括6个5×5卷积核
- C3包括60个5×5卷积核(通道)
- C5包括120×16个5×5卷积核
- 两个池化层S2和S4:
- 都是2×2的平均池化,并添加了非线性映射
- 第一个全连接层:84个神经元
- 第二个全连接层: 10个神经元
1.2 网络细节
- C1层-卷积层
普通卷积层,卷积核大小为5×5,卷积核种类(输出通道)为6,可训练参数为(5×5+1) × 6(每个卷积核 5 ×5=25个unit参数和一个bias参数,一共6 个卷积核)。

代码如下:
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=(5,5), stride=1, padding=0)
- S2层-池化层(下采样层)
2×2平均池化,步长2,带可训练参数(权重w和偏置b),经Sigmoid激活。输出6张14×14特征图。参数量为(1w + 1b)×6 = 12

代码如下:
nn.AvgPool2d(kernel_size=2,stride=2)
- C3层-卷积层
输入为S2中所有6个或者几个特征图组合,卷积核大小为5×5,卷积核种类:16个卷积核。


特征图连接关系
采用了部分连接的思想。由上图可知,C3的前6个特征图与S2层相连的3个特征图相连接,后面6个特征图与S2层相连的4个特征图相连接,后面3个特征图与S2层部分不相连的4个特征图相连接,最后一个与S2层的所有特征图相连。
采用非密集连接的方式,打破对称性,同时减少计算量,共60组卷积核。
代码如下:
class MyConv2d(nn.Module):def __init__(self, in_channels=1, out_channels=6):super(MyConv2d, self).__init__()self.in_channels = in_channelsself.out_channels = out_channelsself.conv = nn.ModuleList([nn.Conv2d(in_channels=self.in_channels, out_channels=1, kernel_size=5) for i in range(out_channels)])def forward(self, input):output_data = torch.empty(input.shape[0], 0, input.shape[2]-4, input.shape[3]-4)for i in range(input.shape[1]):if self.out_channels == 3:c_index = [j%input.shape[1] for j in range(i, i+self.in_channels+1)]c_index.pop(2)else:c_index = [j%input.shape[1] for j in range(i, i+self.in_channels)]conv = self.conv[i]channels = input[:, c_index, :, :]output = conv(channels)torch.cat([output_data, output], dim=1)return output_data
- S4层-池化层(下采样层)

- 输入:10×10
- 采样区域:2×2
- 采样方式:输入相加,乘以一个可训练参数,再 加上一个可训练偏置,使用sigmoid激活
- 输出特征图大小:5×5(10/2)
nn.AvgPool2d(kernel_size=2,stride=2)
- C5层-卷积层

- 输入:S4层的全部16个单元特征map
- 卷积核大小:5×5
- 卷积核种类:120
- 输出特征图大小:1×1(5-5+1)
- 可训练参数/连接:120 ×(16×5×5+1)=48120
代码如下:
nn.Sequential(nn.Linear(in_features=16 * 5 * 5, out_features=120),nn.ReLU(),)
- F6层-全连接层

- 输入:c5 120维向量
- 计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出
- 可训练参数:84×(120+1)=10164
计算机中 字符的编码是ASCII编码,这些图是用7×12大小的位图表示, -1表示白色,1表示黑色,84可以用于对每一个像素点的值进行估计。故F6全连接层的输出是84个节点
代码如下:

nn.Sequential(nn.Linear(in_features=120, out_features=84),nn.ReLU(),)
- Output层-全连接层
共有10个节点,分别代表数字0到9
yi=∑j(xj−wij)2y_i=\sum_j(x_j-w_{ij})^2 yi=j∑(xj−wij)2
径向基函数(RBF)的网络连接方式,输入向量与参数向量的欧式距离。 x是激活后的输出,y是RBF的输出(误差值,最小的即为分类结果),wij是参数(人为设定的,取值-1或者1),i从0~9,j从0~83
代码如下:
nn.Sequential(nn.Linear(in_features=84, out_features=10),nn.Softmax(dim=1))
1.3 总结
LeNet-5以精简的架构(约60k参数)证明了CNN处理图像任务的可行性,其“卷积-池化-全连接”范式成为深度学习的基础模板。尽管因激活函数、池化方式等设计被现代网络超越,但其核心思想仍深刻影响AlexNet、ResNet等后续模型。学习LeNet-5不仅有助于理解CNN的演进,更为设计高效轻量网络提供灵感。
二、AlexNet——掀起深度学习的浪潮
AlexNet网络参加了ILSVRC2012年大赛,以高出第二名10%的性能优势取得了冠军,由传统的70%多的准确率提升到80%多。AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的,也是在那年之后,更多的更深的神经网络被提出,他掀起了一波深度学习的浪潮,一个里程碑意义的网络。
论文地址

不同版本的AlexNet参赛的成绩表:

1CNN :训练一个AlexNet。
5CNNs :训练五个AlexNet取平均值。
1CNN*:在最后一个池化层后,额外添加第六个卷积层,并使用ImageNet 2011(秋) 数据集预训练。
7CNNs*:两个预训练微调,与5CNNs取平均值。
2.1 整体结构
一共8层, 5个卷积层,3个全连接层(池化和Normal不作为层看待)

2.2 创新点
- 多GPU并行计算
在AlexNet中使用了CUDA加速深度卷积网络的训练,同时使用了两块GTX 580 GPU进行训练,单个GTX 580只有3GB显存,这限制了可训练的网络的最大规模。因此作者将AlexNet分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。

除了将模型的神经元进行了并行,还使得通信被限制在了某些网络层。第三层卷积要使用第二层所有的特征图,但是第四层却只需要同一块GPU中的第三层的特征图。与只使用一个GPU,将top-1和top-5 错误率减少1.7%和1.2%
- 使用ReLU
全称为:Rectified Linear Unit,是一种人工神经网络中常用的激活函数,通常意义下,其指代数学中的斜坡函数,公式为:
f(x)=max(0,x)f(x)=max(0,x) f(x)=max(0,x)
对应的函数图像如下所示:

- 使用LRN局部响应归一化
LRN 首先是在 AlexNet 中首先,被定义,它的目的在于卷积(即 Relu 激活函数出来之后的)值进行局部的归一化。
在神经生物学中,有一个概念叫做侧抑制(lateral inhibitio),指的是被激活的神经元会抑制它周围的神经元,而归一化(normalization)的目的就是“抑制”,两者不谋而合,这就是局部归一化的动机,它就是借鉴“侧抑制”的思想来实现局部抑制,当我们使用Relu激活函数的时候,这种局部抑制显得很有效果。
LRN的主要思想是在神经元输出的局部范围内进行归一化操作,使得激活值较大的神经元对后续神经元的影响降低,从而减少梯度消失和梯度爆炸的问题。具体来说,对于每个神经元,LRN会将其输出按照局部范围进行加权平均,然后将加权平均值除以一个尺度因子(通常为2),最后将结果取平方根并减去均值,得到归一化后的输出。
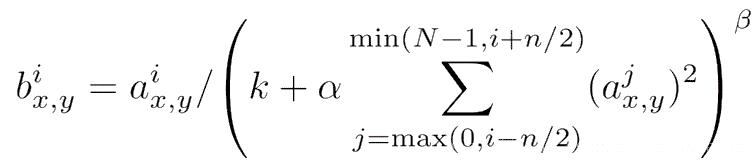
作用于ReLU层之后,抑制反馈较小的神经元,放大反馈较大的 神经元,增强模型泛化能力。但后续提出了更加有说服能力的批量归一化(Batch Normalization)的概念,而现在归一化几乎都用batchNorm的方法实现归一化。
- 全连接加入Dropout
极其有效地减轻了过拟合,是模型成功的关键因素之一。 - 数据增强
将原始图片进行水平翻转、垂直翻转、对角线翻转、旋转角度等数据增强操作,得到多张图,分别进行推理,再融合得到最终输出结果。

- 重叠池化
相邻池化区域的窗口有重叠,能捕获更多信息,减少信息丢失,可提高模型泛化能力。
三、VGGNet——深度和小卷积核
继AlexNet之后又一个里程碑式的卷积神经网络架构,由牛津大学视觉几何组(Visual Geometry Group)在2014年提出。它在ImageNet 2014挑战赛的分类任务中取得了优异的成绩(获得亚军,仅次于GoogLeNet),其核心思想对后续CNN设计产生了极其深远的影响。

VGG的亮点在于它通过堆叠多个卷积层,以小的卷积核和池化层的方式来增加网络深度,从而实现高精度的图像识别。这种方法可以有效地捕获图像中的高级特征,并通过不断拟合训练数据来提高识别准确率。
2.1 VGG版本
根据深度不同,有VGG11,VGG13,VGG16,VGG19。在日常使用过程中一般使用16层的那个,即下图中的D。
# configs
cfgs = {"A": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],"B": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],"D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],"E": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512, "M"],
}

下图展示了他们的表现效果:

2.2 核心思想
- 深度至关重要: VGG的核心假设是增加网络的深度(层数)可以显著提升模型的表征能力。它系统地探索了网络深度对性能的影响。
- 小卷积核的统一性: 全部使用非常小的3x3卷积核,摒弃了AlexNet中使用的11x11和5x5等大卷积核。这是VGG最具标志性的设计选择。
- 架构简洁与一致性: 网络结构设计得非常简洁、规则、一致。主要由重复堆叠的3x3卷积层和2x2最大池化层构成,最后接几个全连接层。这种模块化设计易于理解和实现。
- 空间分辨率递减,通道数递增: 随着网络加深,特征图的空间尺寸(宽高)通过池化层逐步减半,而特征图的通道数则逐步翻倍(或接近翻倍)。这是一种非常经典且有效的特征提取流程设计。
2.3 存在问题
尽管VGG在许多方面都表现优秀,但它也有一些缺陷:
- 该网络架构非常大,并且需要大量的计算资源来训练。这意味着,如果你想在较小的设备上使用VGG,比如移动设备或个人电脑,会发现它非常慢,并且可能无法获得足够的性能。
- 由于VGG网络架构非常深,它可能会导致梯度消失或爆炸的问题。这是由于在非常深的神经网络中,梯度在传播过程中可能会变得非常小或非常大,从而导致模型无法正常训练。
因此,VGG网络架构虽然在许多方面都非常优秀,但是要注意这些缺点可能导致的问题。
总结
本文简要介绍了三种经典神经网络——LeNet5、AlexNet、VGGNet,以及其各自在CNN的发展中所做出的贡献。