决策树(1)
一、树模型与决策树基础
决策树概念:从根节点开始一步步走到叶子节点得出决策,所有数据最终都会落到叶子节点,既可用于分类,也可用于回归。
树的组成
根节点:第一个选择点。
非叶子节点与分支:中间决策过程。
叶子节点:最终的决策结果。
二、决策树的训练与测试
训练阶段:从给定的训练集构造树,核心是从根节点开始选择特征并进行特征切分。
测试阶段:根据构造好的树模型从上到下走一遍即可完成分类或回归任务。
难点:如何构造出一棵树,涉及特征选择与切分等问题。
三、特征切分相关衡量标准
核心问题:如何选择根节点及后续节点的特征,如何进行切分。目标是通过衡量标准找到能更好切分数据(分类效果更好)的特征作为节点。
熵
定义:表示随机变量不确定性的度量,公式为H(X)=- ∑ pi * logpi, i=1,2, ... , n。
特点:不确定性越大,熵值越大;
信息增益:表示特征X使得类Y的不确定性减少的程度,分类后希望同类数据在一起,即提高分类的专一性。
四、决策树构造实例
数据与目标:基于14天打球情况的数据,包含4种环境变化特征,目标是构造决策树。
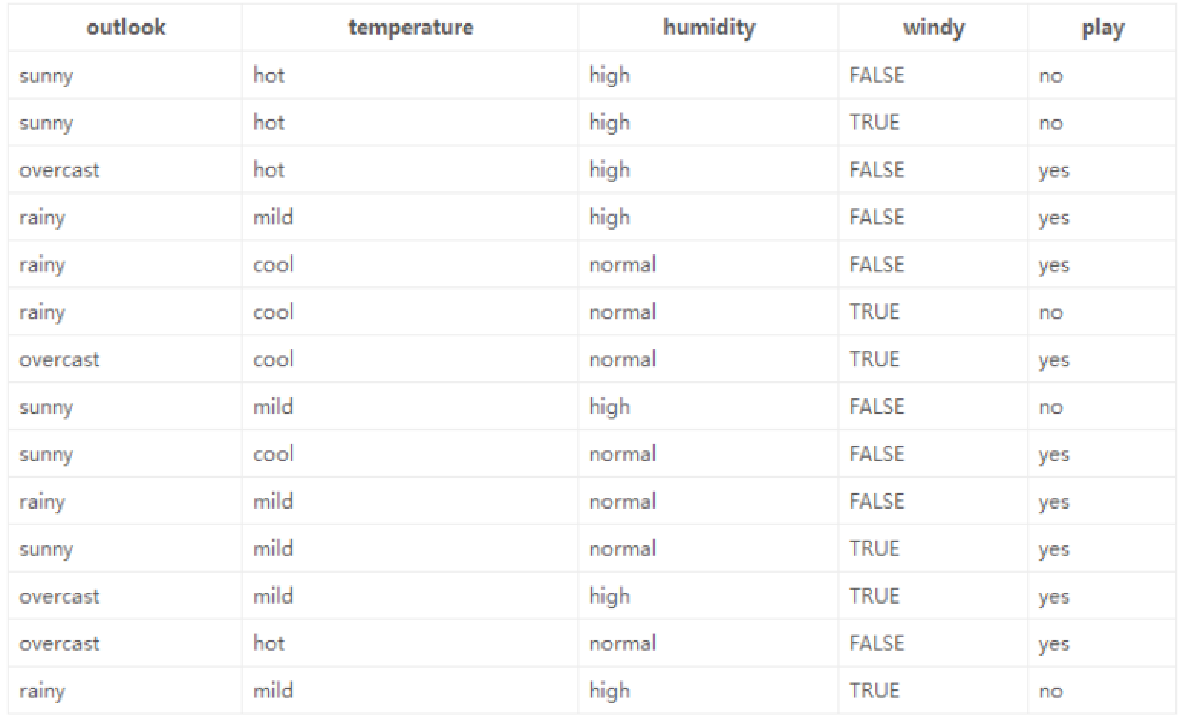
计算过程
原始数据中9天打球,5天不打球,先计算此时的熵。
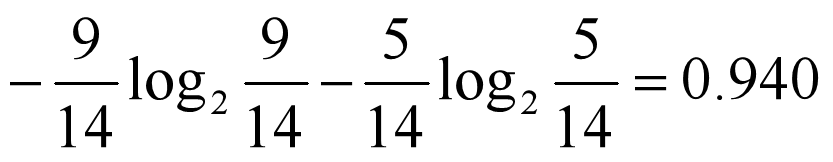
对4个特征逐一分析,以outlook特征为例,计算其不同取值时的熵值,再结合各取值的概率计算该特征下的总熵值,进而得出信息增益。


选择信息增益最大的特征作为根节点,再在剩余特征中按同样方式选择后续节点。
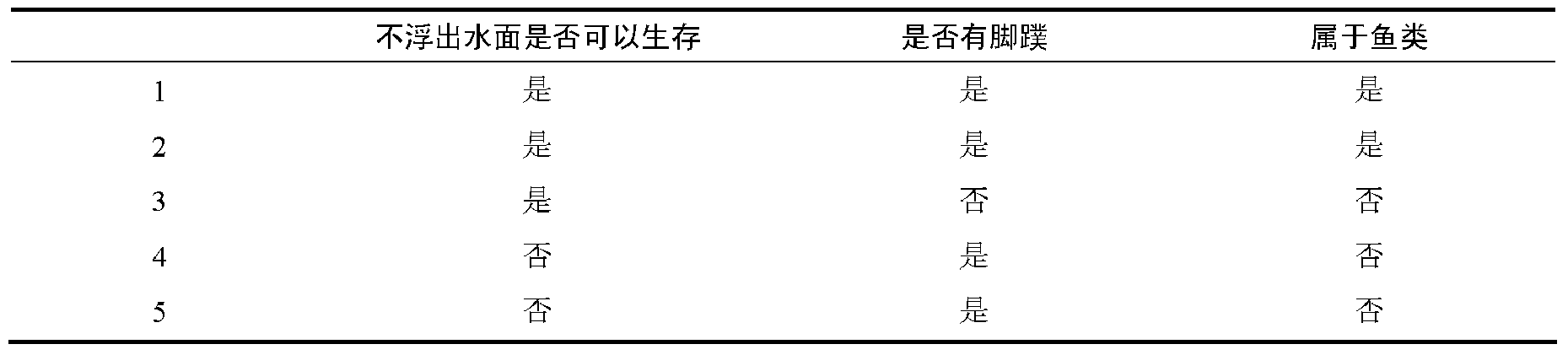
五、课堂练习