MySQL面试题:MyISAM vs InnoDB?聚簇索引是什么?主键为何要趋势递增?
在 MySQL 面试中,“MyISAM 和 InnoDB 有什么区别?” 几乎是必问问题。而背后真正考察的是你对 存储引擎、索引结构、性能优化 的理解深度。今天我们就来彻底讲清楚这个问题,并延伸到 聚簇索引、主键设计、UUID vs 雪花ID、Hash 索引限制 等高频考点!
一、MyISAM vs InnoDB:本质区别在哪?
| 特性 | MyISAM | InnoDB |
|---|---|---|
| 事务支持 | ❌ 不支持 | ✅ 支持(ACID) |
| 外键支持 | ❌ 不支持 | ✅ 支持 |
| 锁粒度 | 表级锁 | 行级锁(提升并发) |
| 崩溃恢复 | 差 | 强(通过 redo log) |
| MVCC | ❌ 不支持 | ✅ 支持(多版本并发控制) |
| 默认引擎 | ❌ 旧版默认 | ✅ MySQL 5.5+ 默认 |
📌 结论:InnoDB 是现代应用的首选引擎,尤其适用于高并发、需要事务保障的场景。
二、底层文件结构差异:数据和索引如何存储?
2.1 MyISAM:非聚簇索引(Non-Clustered Index)
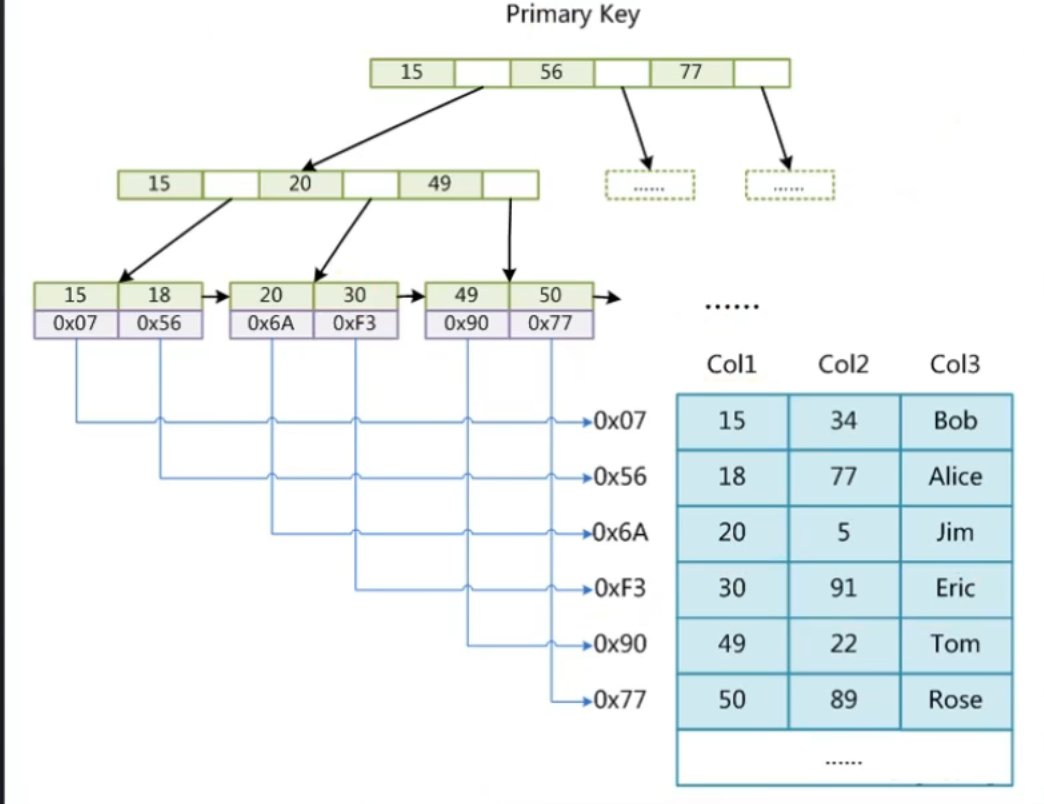
MyISAM 使用两个关键文件:
.MYD(MYData):存储数据记录.MYI(MYIndex):存储索引结构(B+树)
🔍 查询过程示例:
SELECT * FROM t WHERE col1 = 40;如果 col1 是索引字段:
- 先在
.MYI文件中查找 B+ 树索引; - 找到叶子节点后,获取指向
.MYD文件的物理地址指针; - 再去
.MYD中根据指针读取完整数据记录。
⚠️ 这个“根据索引找指针,再查数据”的过程,就是所谓的 回表查询
2.2 InnoDB:聚簇索引(Clustered Index)
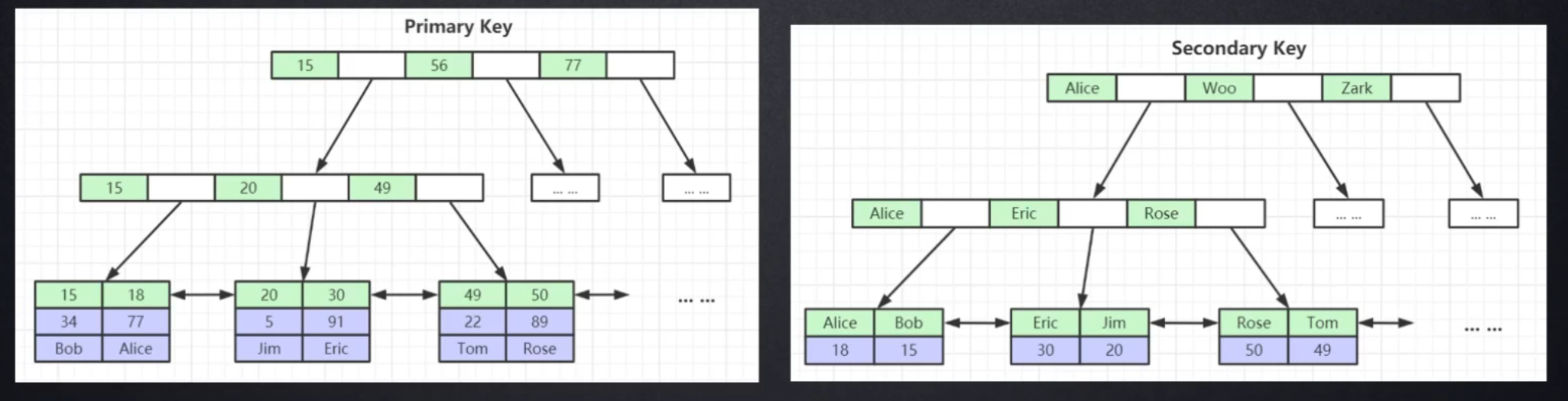
InnoDB 将数据和索引统一存储在 .ibd 文件中,其主键索引的叶子节点直接包含完整的数据行。
✅ 优势:
- 聚簇索引 = 数据 + 主键索引一体化
- 查询主键时,一次 B+ 树查找即可拿到完整数据,无需回表
📌 注意: “聚簇” 和 “聚集” 是同一个概念,只是翻译不同(Clustered Index),无需纠结。
三、聚簇索引 vs 非聚簇索引:核心区别是什么?
| 对比项 | 聚簇索引(InnoDB) | 非聚簇索引(MyISAM) |
|---|---|---|
| 叶子节点内容 | 完整数据行 | 指向数据行的指针 |
| 查询主键 | ✅ 无需回表 | ❌ 需要回表 |
| 查询非主键索引 | ❌ 需回表(通过主键再查) | ❌ 需回表(通过指针查) |
| 数据物理排序 | 按主键顺序存储 | 与索引无关 |
💡 关键结论:
- 聚簇索引减少了回表次数,提升主键查询性能。
- 但二级索引(非主键索引)仍需回表,因为叶子节点只存主键值。
四、为什么推荐使用“趋势递增”的主键?📈
InnoDB 的聚簇索引是基于主键构建的 B+ 树。如果主键是趋势递增的(如自增 ID、雪花 ID),会带来巨大性能优势:
✅ 好处一:减少页分裂和数据移动
- 新记录总是插入到 B+ 树的末尾页;
- 几乎不会触发中间页的分裂,写入效率高;
- 磁盘 IO 更连续,缓存命中率更高。
反例:随机主键(如 UUID)
- 每次插入都可能落在 B+ 树任意位置;
- 频繁触发页分裂、数据右移、索引重组;
- 性能急剧下降,尤其是大数据量时。
扩展1:没有主键怎么办?
InnoDB 会自动创建一个隐藏的 row_id(6字节,单调递增)作为聚簇索引。
⚠️ 但我们无法使用它,也无法控制其行为。所以,务必显式定义主键
五、分布式场景下的主键设计:自增 ID 不够用了!
在分库分表场景下,传统自增 ID 会遇到问题:
❌ 问题:自增 ID 分配不均
比如:
- DB1 分配 1~1000w条记录
- DB2 分配 1000w ~ 2000w → 容易造成数据倾斜、扩容困难
只有在DB1记录达到预定上限时才插入到DB2中
✅ 解法:使用趋势递增的分布式 ID —— 雪花算法(Snowflake)
雪花 ID 的优势:
- 趋势递增:时间戳前置 → 插入性能好;
- 全局唯一:机器位 + 序列位保证不重复;
- 自带时间信息:可反向解析出生成时间;
- 适合分库分表:ID 分散均匀,可按机器位或时间位路由。
场景举例:按年分库的订单系统
假设公司订单表按年分库:
order_db_2023order_db_2024order_db_2025
现在有一个需求:
💬 “查询 2024 年的前 100 条订单,点击详情页面,然后根据这些订单 ID 定位它们所在的数据库。”
如果使用的是 自增 ID 或 UUID,我们无法从 ID 本身知道它属于哪一年,必须依赖额外字段(如 create_time)去查,甚至要跨库扫描。
但如果我们使用的是 雪花算法 ID,就可以:
- 先从
order_db_2024中查出 100 条订单的 ID; - 对每个 ID 反向解析出生成时间戳;
- 提取年份 → 确定该 ID 属于哪个库(比如
order_db_2024);
六、为什么不推荐用 UUID 做主键?
虽然 UUID 全局唯一,但作为主键有严重缺陷:
| 问题 | 说明 |
|---|---|
| 写入性能差 | 随机值导致频繁页分裂、B+ 树重构 |
| 空间占用大 | 36字符字符串 vs 8字节 bigint |
| ⏱️ 比较开销高 | 字符串比较比整数慢得多 |
| 📉 缓存不友好 | 数据物理存储不连续,缓存命中率低 |
✅ 建议:如需唯一标识,可用 UUID 作为业务字段,主键仍用趋势递增 ID。
七、为什么不推荐 Hash 索引?
虽然 Hash 索引查询速度极快(O(1)),但 MySQL 默认不使用它,原因如下:
✅ Hash 索引优势:
- 精确匹配极快(
=、IN查询) - 底层是 数组 + 链表/红黑树(类似 HashMap)
❌ 重大限制:
| 限制 | 说明 |
|---|---|
| 不支持范围查询 | >、<、BETWEEN 无法使用 |
| 不支持排序 | ORDER BY 不能利用 Hash 索引 |
| 不支持模糊匹配 | LIKE 'abc%' 无效 |
| 哈希冲突 | 大量冲突时性能退化为 O(n) |
📌 结论:
Hash 索引只适合等值查询极多、无范围查询的特殊场景(如内存表 MEMORY),不适用于通用业务表。
面试回答模板
InnoDB 使用聚簇索引,数据存储在主键 B+ 树的叶子节点,查询主键无需回表;
而 MyISAM 是非聚簇索引,索引和数据分离,必须回表查询。因此 InnoDB 更适合高并发、事务场景。同时,我们推荐使用趋势递增的主键(如雪花 ID),
避免 UUID 导致的页分裂和性能下降。在分库分表时,自增 ID 不适用,雪花算法能保证全局唯一且写入高效。索引结构决定查询性能,主键设计影响系统扩展。