RK3568 NPU RKNN(六):RKNPU2 SDK
文章目录
- 1、前言
- 2、目标
- 3、RKNPU2 编译说明
- 4、RKNPU2 C API
- 5、通用API程序示例
- 5.1、完整测试程序
- 5.2、相关API
- 6、零拷贝API程序示例
- 6.1、完整测试程序
- 6.2、相关API
- 7、总结
1、前言
本文仅记录本人学习过程,不具备教学指导意义。
2、目标
上节我们提到的RKNN-Toolkit2-Lite2是一个轻量化的可以直接运行在板端的一个推理包工具,其提供的是python接口。而RKNPU2 SDK是提供的一套跨平台的编程接口(C/C++), 能够帮助用户部署RKNN模型。
3、RKNPU2 编译说明
开发者编译应用时要包含接口函数所在的头文件,并且根据使用的硬件平台和系统类型,链接相应 RKNPU 运行时库。
RKNN API库文件是librknnrt.so(对于RK356X/RK3588),头文件有rknn_api.h和rknn_matmul_api.h。 在linux系统使用该库,需要将库文件放到系统库搜索路径下,一般是放到/usr/lib下,头文件放到/usr/include。
4、RKNPU2 C API
RKNPU2 C API分为通用API和零拷贝API。区别如下:
通用API:
- 每次推理时,需要把输入数据从 外部模块内存 → NPU 内存。
- 输出也要从 NPU 内存 → 外部内存。
- 所以会有额外的数据拷贝。
零拷贝API:
- 允许用户提前分配好一块物理连续内存。
- NPU 可以直接使用这块内存作为输入或输出。
- 省去了数据搬运(拷贝),效率更高。
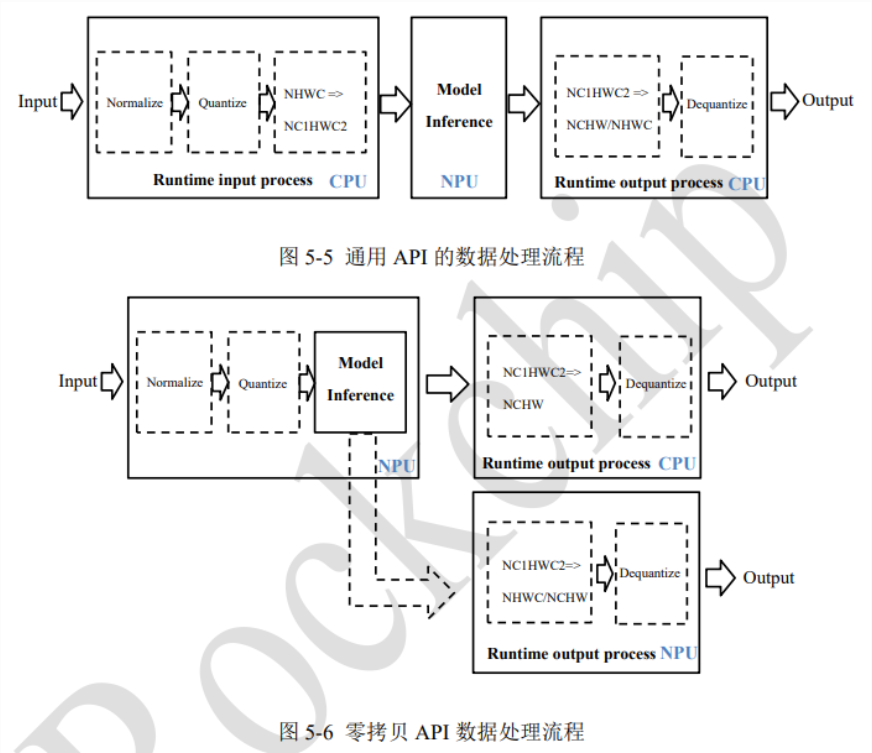
5、通用API程序示例
5.1、完整测试程序
这里依旧使用野火提供的配套例程:lubancat_ai_manual_code/dev_env/rknpu2/rknn_yolov5_demo,如下是例程中的main.cc:
// Copyright (c) 2021 by Rockchip Electronics Co., Ltd. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License./*-------------------------------------------Includes
-------------------------------------------*/
#include <dlfcn.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/time.h>#define _BASETSD_H#include "RgaUtils.h"
#include "im2d.h"
#include "opencv2/core/core.hpp"
#include "opencv2/imgcodecs.hpp"
#include "opencv2/imgproc.hpp"
#include "postprocess.h"
#include "rga.h"
#include "rknn_api.h"#define PERF_WITH_POST 1
/*-------------------------------------------Functions
-------------------------------------------*/static void dump_tensor_attr(rknn_tensor_attr* attr)
{std::string shape_str = attr->n_dims < 1 ? "" : std::to_string(attr->dims[0]);for (int i = 1; i < attr->n_dims; ++i) {shape_str += ", " + std::to_string(attr->dims[i]);}printf(" index=%d, name=%s, n_dims=%d, dims=[%s], n_elems=%d, size=%d, w_stride = %d, size_with_stride=%d, fmt=%s, ""type=%s, qnt_type=%s, ""zp=%d, scale=%f\n",attr->index, attr->name, attr->n_dims, shape_str.c_str(), attr->n_elems, attr->size, attr->w_stride,attr->size_with_stride, get_format_string(attr->fmt), get_type_string(attr->type),get_qnt_type_string(attr->qnt_type), attr->zp, attr->scale);
}double __get_us(struct timeval t) { return (t.tv_sec * 1000000 + t.tv_usec); }static unsigned char* load_data(FILE* fp, size_t ofst, size_t sz)
{unsigned char* data;int ret;data = NULL;if (NULL == fp) {return NULL;}ret = fseek(fp, ofst, SEEK_SET);if (ret != 0) {printf("blob seek failure.\n");return NULL;}data = (unsigned char*)malloc(sz);if (data == NULL) {printf("buffer malloc failure.\n");return NULL;}ret = fread(data, 1, sz, fp);return data;
}static unsigned char* load_model(const char* filename, int* model_size)
{FILE* fp;unsigned char* data;fp = fopen(filename, "rb");if (NULL == fp) {printf("Open file %s failed.\n", filename);return NULL;}fseek(fp, 0, SEEK_END);int size = ftell(fp);data = load_data(fp, 0, size);fclose(fp);*model_size = size;return data;
}static int saveFloat(const char* file_name, float* output, int element_size)
{FILE* fp;fp = fopen(file_name, "w");for (int i = 0; i < element_size; i++) {fprintf(fp, "%.6f\n", output[i]);}fclose(fp);return 0;
}/*-------------------------------------------Main Functions
-------------------------------------------*/
int main(int argc, char** argv)
{int status = 0;char* model_name = NULL;rknn_context ctx;size_t actual_size = 0;int img_width = 0;int img_height = 0;int img_channel = 0;const float nms_threshold = NMS_THRESH;const float box_conf_threshold = BOX_THRESH;struct timeval start_time, stop_time;int ret;// init rga contextrga_buffer_t src;rga_buffer_t dst;im_rect src_rect;im_rect dst_rect;memset(&src_rect, 0, sizeof(src_rect));memset(&dst_rect, 0, sizeof(dst_rect));memset(&src, 0, sizeof(src));memset(&dst, 0, sizeof(dst));if (argc != 3) {printf("Usage: %s <rknn model> <jpg> \n", argv[0]);return -1;}printf("post process config: box_conf_threshold = %.2f, nms_threshold = %.2f\n", box_conf_threshold, nms_threshold);model_name = (char*)argv[1];char* image_name = argv[2];printf("Read %s ...\n", image_name);cv::Mat orig_img = cv::imread(image_name, 1);if (!orig_img.data) {printf("cv::imread %s fail!\n", image_name);return -1;}cv::Mat img;cv::cvtColor(orig_img, img, cv::COLOR_BGR2RGB);img_width = img.cols;img_height = img.rows;printf("img width = %d, img height = %d\n", img_width, img_height);/* Create the neural network */printf("Loading mode...\n");int model_data_size = 0;unsigned char* model_data = load_model(model_name, &model_data_size);ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL);if (ret < 0) {printf("rknn_init error ret=%d\n", ret);return -1;}rknn_sdk_version version;ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version, sizeof(rknn_sdk_version));if (ret < 0) {printf("rknn_init error ret=%d\n", ret);return -1;}printf("sdk version: %s driver version: %s\n", version.api_version, version.drv_version);rknn_input_output_num io_num;ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));if (ret < 0) {printf("rknn_init error ret=%d\n", ret);return -1;}printf("model input num: %d, output num: %d\n", io_num.n_input, io_num.n_output);rknn_tensor_attr input_attrs[io_num.n_input];memset(input_attrs, 0, sizeof(input_attrs));for (int i = 0; i < io_num.n_input; i++) {input_attrs[i].index = i;ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr));if (ret < 0) {printf("rknn_init error ret=%d\n", ret);return -1;}dump_tensor_attr(&(input_attrs[i]));}rknn_tensor_attr output_attrs[io_num.n_output];memset(output_attrs, 0, sizeof(output_attrs));for (int i = 0; i < io_num.n_output; i++) {output_attrs[i].index = i;ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));dump_tensor_attr(&(output_attrs[i]));}int channel = 3;int width = 0;int height = 0;if (input_attrs[0].fmt == RKNN_TENSOR_NCHW) {printf("model is NCHW input fmt\n");channel = input_attrs[0].dims[1];height = input_attrs[0].dims[2];width = input_attrs[0].dims[3];} else {printf("model is NHWC input fmt\n");height = input_attrs[0].dims[1];width = input_attrs[0].dims[2];channel = input_attrs[0].dims[3];}printf("model input height=%d, width=%d, channel=%d\n", height, width, channel);rknn_input inputs[1];memset(inputs, 0, sizeof(inputs));inputs[0].index = 0;inputs[0].type = RKNN_TENSOR_UINT8;inputs[0].size = width * height * channel;inputs[0].fmt = RKNN_TENSOR_NHWC;inputs[0].pass_through = 0;// You may not need resize when src resulotion equals to dst resulotionvoid* resize_buf = nullptr;if (img_width != width || img_height != height) {printf("resize with RGA!\n");resize_buf = malloc(height * width * channel);memset(resize_buf, 0x00, height * width * channel);src = wrapbuffer_virtualaddr((void*)img.data, img_width, img_height, RK_FORMAT_RGB_888);dst = wrapbuffer_virtualaddr((void*)resize_buf, width, height, RK_FORMAT_RGB_888);ret = imcheck(src, dst, src_rect, dst_rect);if (IM_STATUS_NOERROR != ret) {printf("%d, check error! %s", __LINE__, imStrError((IM_STATUS)ret));return -1;}IM_STATUS STATUS = imresize(src, dst);// for debugcv::Mat resize_img(cv::Size(width, height), CV_8UC3, resize_buf);cv::imwrite("resize_input.jpg", resize_img);inputs[0].buf = resize_buf;} else {inputs[0].buf = (void*)img.data;}gettimeofday(&start_time, NULL);rknn_inputs_set(ctx, io_num.n_input, inputs);rknn_output outputs[io_num.n_output];memset(outputs, 0, sizeof(outputs));for (int i = 0; i < io_num.n_output; i++) {outputs[i].want_float = 0;}ret = rknn_run(ctx, NULL);ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);gettimeofday(&stop_time, NULL);printf("once run use %f ms\n", (__get_us(stop_time) - __get_us(start_time)) / 1000);// post processfloat scale_w = (float)width / img_width;float scale_h = (float)height / img_height;detect_result_group_t detect_result_group;std::vector<float> out_scales;std::vector<int32_t> out_zps;for (int i = 0; i < io_num.n_output; ++i) {out_scales.push_back(output_attrs[i].scale);out_zps.push_back(output_attrs[i].zp);}post_process((int8_t*)outputs[0].buf, (int8_t*)outputs[1].buf, (int8_t*)outputs[2].buf, height, width,box_conf_threshold, nms_threshold, scale_w, scale_h, out_zps, out_scales, &detect_result_group);// Draw Objectschar text[256];for (int i = 0; i < detect_result_group.count; i++) {detect_result_t* det_result = &(detect_result_group.results[i]);sprintf(text, "%s %.1f%%", det_result->name, det_result->prop * 100);printf("%s @ (%d %d %d %d) %f\n", det_result->name, det_result->box.left, det_result->box.top,det_result->box.right, det_result->box.bottom, det_result->prop);int x1 = det_result->box.left;int y1 = det_result->box.top;int x2 = det_result->box.right;int y2 = det_result->box.bottom;rectangle(orig_img, cv::Point(x1, y1), cv::Point(x2, y2), cv::Scalar(255, 0, 0, 255), 3);putText(orig_img, text, cv::Point(x1, y1 + 12), cv::FONT_HERSHEY_SIMPLEX, 0.6, cv::Scalar(0, 0, 255), 2);}imwrite("./out.jpg", orig_img);ret = rknn_outputs_release(ctx, io_num.n_output, outputs);// loop testint test_count = 10;gettimeofday(&start_time, NULL);for (int i = 0; i < test_count; ++i) {rknn_inputs_set(ctx, io_num.n_input, inputs);ret = rknn_run(ctx, NULL);ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
#if PERF_WITH_POSTpost_process((int8_t*)outputs[0].buf, (int8_t*)outputs[1].buf, (int8_t*)outputs[2].buf, height, width,box_conf_threshold, nms_threshold, scale_w, scale_h, out_zps, out_scales, &detect_result_group);
#endifret = rknn_outputs_release(ctx, io_num.n_output, outputs);}gettimeofday(&stop_time, NULL);printf("loop count = %d , average run %f ms\n", test_count,(__get_us(stop_time) - __get_us(start_time)) / 1000.0 / test_count);deinitPostProcess();// releaseret = rknn_destroy(ctx);if (model_data) {free(model_data);}if (resize_buf) {free(resize_buf);}return 0;
}5.2、相关API
# 1. 模型准备
rknn_init # 初始化RKNN上下文,加载模型# 2. 模型信息查询
rknn_query(SDK_VERSION) # 查询SDK/驱动版本
rknn_query(IN_OUT_NUM) # 查询输入输出个数
rknn_query(INPUT_ATTR) # 查询输入tensor属性
rknn_query(OUTPUT_ATTR) # 查询输出tensor属性# 3. 输入数据设置
rknn_inputs_set # 设置输入数据(拷贝到NPU内存)# 4. 推理执行
rknn_run # 执行一次推理# 5. 输出获取与释放
rknn_outputs_get # 获取推理结果(从NPU拷贝到CPU)
# --> 用户做后处理(如分类结果解析 / NMS / 画框等)
rknn_outputs_release # 释放输出结果内存# 6. (可选)重复推理
rknn_inputs_set
rknn_run
rknn_outputs_get
rknn_outputs_release# 7. 资源释放
rknn_destroy # 销毁RKNN上下文,释放资源
6、零拷贝API程序示例
6.1、完整测试程序
这里依旧使用野火提供的配套例程:lubancat_ai_manual_code/dev_env/rknpu2/rknn_api_demo_Linux,如下是例程中的rknn_create_mem_demo.cpp:
// Copyright (c) 2021 by Rockchip Electronics Co., Ltd. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License./*-------------------------------------------Includes
-------------------------------------------*/
#include "rk_mpi_mmz.h"
#include "rknn_api.h"#include <float.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/time.h>#define STB_IMAGE_IMPLEMENTATION
#include "stb/stb_image.h"
#define STB_IMAGE_RESIZE_IMPLEMENTATION
#include <stb/stb_image_resize.h>/*-------------------------------------------Functions
-------------------------------------------*/
static inline int64_t getCurrentTimeUs()
{struct timeval tv;gettimeofday(&tv, NULL);return tv.tv_sec * 1000000 + tv.tv_usec;
}static int rknn_GetTopN(float* pfProb, float* pfMaxProb, uint32_t* pMaxClass, uint32_t outputCount, uint32_t topNum)
{uint32_t i, j;uint32_t top_count = outputCount > topNum ? topNum : outputCount;for (i = 0; i < topNum; ++i) {pfMaxProb[i] = -FLT_MAX;pMaxClass[i] = -1;}for (j = 0; j < top_count; j++) {for (i = 0; i < outputCount; i++) {if ((i == *(pMaxClass + 0)) || (i == *(pMaxClass + 1)) || (i == *(pMaxClass + 2)) || (i == *(pMaxClass + 3)) ||(i == *(pMaxClass + 4))) {continue;}if (pfProb[i] > *(pfMaxProb + j)) {*(pfMaxProb + j) = pfProb[i];*(pMaxClass + j) = i;}}}return 1;
}static void dump_tensor_attr(rknn_tensor_attr* attr)
{printf(" index=%d, name=%s, n_dims=%d, dims=[%d, %d, %d, %d], n_elems=%d, size=%d, fmt=%s, type=%s, qnt_type=%s, ""zp=%d, scale=%f\n",attr->index, attr->name, attr->n_dims, attr->dims[0], attr->dims[1], attr->dims[2], attr->dims[3],attr->n_elems, attr->size, get_format_string(attr->fmt), get_type_string(attr->type),get_qnt_type_string(attr->qnt_type), attr->zp, attr->scale);
}static unsigned char* load_image(const char* image_path, rknn_tensor_attr* input_attr)
{int req_height = 0;int req_width = 0;int req_channel = 0;switch (input_attr->fmt) {case RKNN_TENSOR_NHWC:req_height = input_attr->dims[1];req_width = input_attr->dims[2];req_channel = input_attr->dims[3];break;case RKNN_TENSOR_NCHW:req_height = input_attr->dims[2];req_width = input_attr->dims[3];req_channel = input_attr->dims[1];break;default:printf("meet unsupported layout\n");return NULL;}int height = 0;int width = 0;int channel = 0;unsigned char* image_data = stbi_load(image_path, &width, &height, &channel, req_channel);if (image_data == NULL) {printf("load image failed!\n");return NULL;}if (width != req_width || height != req_height) {unsigned char* image_resized = (unsigned char*)STBI_MALLOC(req_width * req_height * req_channel);if (!image_resized) {printf("malloc image failed!\n");STBI_FREE(image_data);return NULL;}if (stbir_resize_uint8(image_data, width, height, 0, image_resized, req_width, req_height, 0, channel) != 1) {printf("resize image failed!\n");STBI_FREE(image_data);return NULL;}STBI_FREE(image_data);image_data = image_resized;}return image_data;
}/*-------------------------------------------Main Functions
-------------------------------------------*/
int main(int argc, char* argv[])
{if (argc < 3) {printf("Usage:%s model_path input_path [loop_count]\n", argv[0]);return -1;}char* model_path = argv[1];char* input_path = argv[2];int loop_count = 1;if (argc > 3) {loop_count = atoi(argv[3]);}rknn_context ctx = 0;// Load RKNN Modelint ret = rknn_init(&ctx, model_path, 0, 0, NULL);if (ret < 0) {printf("rknn_init fail! ret=%d\n", ret);return -1;}// Get sdk and driver versionrknn_sdk_version sdk_ver;ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &sdk_ver, sizeof(sdk_ver));if (ret != RKNN_SUCC) {printf("rknn_query fail! ret=%d\n", ret);return -1;}printf("rknn_api/rknnrt version: %s, driver version: %s\n", sdk_ver.api_version, sdk_ver.drv_version);// Get Model Input Output Inforknn_input_output_num io_num;ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));if (ret != RKNN_SUCC) {printf("rknn_query fail! ret=%d\n", ret);return -1;}printf("model input num: %d, output num: %d\n", io_num.n_input, io_num.n_output);printf("input tensors:\n");rknn_tensor_attr input_attrs[io_num.n_input];memset(input_attrs, 0, io_num.n_input * sizeof(rknn_tensor_attr));for (uint32_t i = 0; i < io_num.n_input; i++) {input_attrs[i].index = i;// query inforet = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr));if (ret < 0) {printf("rknn_init error! ret=%d\n", ret);return -1;}dump_tensor_attr(&input_attrs[i]);}printf("output tensors:\n");rknn_tensor_attr output_attrs[io_num.n_output];memset(output_attrs, 0, io_num.n_output * sizeof(rknn_tensor_attr));for (uint32_t i = 0; i < io_num.n_output; i++) {output_attrs[i].index = i;// query inforet = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));if (ret != RKNN_SUCC) {printf("rknn_query fail! ret=%d\n", ret);return -1;}dump_tensor_attr(&output_attrs[i]);}// Get custom stringrknn_custom_string custom_string;ret = rknn_query(ctx, RKNN_QUERY_CUSTOM_STRING, &custom_string, sizeof(custom_string));if (ret != RKNN_SUCC) {printf("rknn_query fail! ret=%d\n", ret);return -1;}printf("custom string: %s\n", custom_string.string);unsigned char* input_data = NULL;rknn_tensor_type input_type = RKNN_TENSOR_UINT8;rknn_tensor_format input_layout = RKNN_TENSOR_NHWC;// Load imageinput_data = load_image(input_path, &input_attrs[0]);if (!input_data) {return -1;}int mb_flags = RK_MMZ_ALLOC_TYPE_CMA | RK_MMZ_ALLOC_UNCACHEABLE;// Allocate input memory in outsideMB_BLK input_mb;int input_size = input_attrs[0].size_with_stride;ret = RK_MPI_MMZ_Alloc(&input_mb, input_size, mb_flags);if (ret < 0) {printf("RK_MPI_MMZ_Alloc failed, ret: %d\n", ret);return ret;}void* input_virt = RK_MPI_MMZ_Handle2VirAddr(input_mb);if (input_virt == NULL) {printf("RK_MPI_MMZ_Handle2VirAddr failed!\n");return -1;}uint64_t input_phys = RK_MPI_MMZ_Handle2PhysAddr(input_mb);if (input_phys == 0) {printf("RK_MPI_MMZ_Handle2PhysAddr failed!\n");return -1;}printf("input mb info: virt = %p, phys = %#lx, size: %d\n", input_virt, input_phys, input_size);// Allocate outputs memory in outsideMB_BLK output_mbs[io_num.n_output];void* output_virts[io_num.n_output];uint64_t output_physs[io_num.n_output];for (uint32_t i = 0; i < io_num.n_output; ++i) {// default output type is depend on model, this require float32 to compute top5output_attrs[i].type = RKNN_TENSOR_FLOAT32;int output_size = output_attrs[i].n_elems * sizeof(float);output_attrs[i].size = output_size;ret = RK_MPI_MMZ_Alloc(&output_mbs[i], output_size, mb_flags);if (ret < 0) {printf("RK_MPI_MMZ_Alloc failed, ret: %d\n", ret);return ret;}output_virts[i] = RK_MPI_MMZ_Handle2VirAddr(output_mbs[i]);if (output_virts[i] == NULL) {printf("RK_MPI_MMZ_Handle2VirAddr failed!\n");return -1;}output_physs[i] = RK_MPI_MMZ_Handle2PhysAddr(output_mbs[i]);if (output_physs[i] == 0) {printf("RK_MPI_MMZ_Handle2PhysAddr failed!\n");return -1;}printf("output%d mb info: virt = %p, phys = %#lx, size = %d\n", i, output_virts[i], output_physs[i], output_size);}// Create input tensor memoryrknn_tensor_mem* input_mems[1];// default input type is int8 (normalize and quantize need compute in outside)// if set uint8, will fuse normalize and quantize to npuinput_attrs[0].type = input_type;// default fmt is NHWC, npu only support NHWC in zero copy modeinput_attrs[0].fmt = input_layout;input_mems[0] = rknn_create_mem_from_phys(ctx, input_phys, input_virt, input_attrs[0].size_with_stride);// Copy input data to input tensor memoryint width = input_attrs[0].dims[2];int stride = input_attrs[0].w_stride;if (width == stride) {memcpy(input_mems[0]->virt_addr, input_data, width * input_attrs[0].dims[1] * input_attrs[0].dims[3]);} else {int height = input_attrs[0].dims[1];int channel = input_attrs[0].dims[3];// copy from src to dst with strideuint8_t* src_ptr = input_data;uint8_t* dst_ptr = (uint8_t*)input_mems[0]->virt_addr;// width-channel elementsint src_wc_elems = width * channel;int dst_wc_elems = stride * channel;for (int h = 0; h < height; ++h) {memcpy(dst_ptr, src_ptr, src_wc_elems);src_ptr += src_wc_elems;dst_ptr += dst_wc_elems;}}// Create output tensor memoryrknn_tensor_mem* output_mems[io_num.n_output];for (uint32_t i = 0; i < io_num.n_output; ++i) {output_mems[i] = rknn_create_mem_from_phys(ctx, output_physs[i], output_virts[i], output_attrs[i].size);}// Set input tensor memoryret = rknn_set_io_mem(ctx, input_mems[0], &input_attrs[0]);if (ret < 0) {printf("rknn_set_io_mem fail! ret=%d\n", ret);return -1;}// Set output tensor memoryfor (uint32_t i = 0; i < io_num.n_output; ++i) {// set output memory and attributeret = rknn_set_io_mem(ctx, output_mems[i], &output_attrs[i]);if (ret < 0) {printf("rknn_set_io_mem fail! ret=%d\n", ret);return -1;}}// Runprintf("Begin perf ...\n");for (int i = 0; i < loop_count; ++i) {int64_t start_us = getCurrentTimeUs();ret = rknn_run(ctx, NULL);int64_t elapse_us = getCurrentTimeUs() - start_us;if (ret < 0) {printf("rknn run error %d\n", ret);return -1;}printf("%4d: Elapse Time = %.2fms, FPS = %.2f\n", i, elapse_us / 1000.f, 1000.f * 1000.f / elapse_us);}// Get top 5uint32_t topNum = 5;for (uint32_t i = 0; i < io_num.n_output; i++) {uint32_t MaxClass[topNum];float fMaxProb[topNum];float* buffer = (float*)output_mems[i]->virt_addr;uint32_t sz = output_attrs[i].n_elems;int top_count = sz > topNum ? topNum : sz;rknn_GetTopN(buffer, fMaxProb, MaxClass, sz, topNum);printf("---- Top%d ----\n", top_count);for (int j = 0; j < top_count; j++) {printf("%8.6f - %d\n", fMaxProb[j], MaxClass[j]);}}// free mb blk memoryRK_MPI_MMZ_Free(input_mb);for (uint32_t i = 0; i < io_num.n_output; ++i) {RK_MPI_MMZ_Free(output_mbs[i]);}// Destroy rknn memoryrknn_destroy_mem(ctx, input_mems[0]);for (uint32_t i = 0; i < io_num.n_output; ++i) {rknn_destroy_mem(ctx, output_mems[i]);}// destroyrknn_destroy(ctx);free(input_data);return 0;
}6.2、相关API
# 1. 模型准备
rknn_init # 初始化RKNN上下文,加载模型文件# 2. 模型信息查询
rknn_query(SDK_VERSION) # 查询SDK/驱动版本
rknn_query(IN_OUT_NUM) # 查询模型输入输出个数
rknn_query(INPUT_ATTR) # 查询输入tensor属性
rknn_query(OUTPUT_ATTR) # 查询输出tensor属性
rknn_query(CUSTOM_STRING) # 查询模型自定义字符串(可选)# 3. 外部分配物理内存(Zero-copy模式)
RK_MPI_MMZ_Alloc # 为输入/输出张量分配连续物理内存
RK_MPI_MMZ_Handle2VirAddr # 获取虚拟地址
RK_MPI_MMZ_Handle2PhysAddr # 获取物理地址# 4. 创建RKNPU张量内存对象
rknn_create_mem_from_phys # 将物理内存映射为NPU可用张量# 5. 设置输入输出张量内存
rknn_set_io_mem # 绑定输入/输出张量的内存和属性# 6. 输入数据准备
memcpy(input_mem->virt_addr, preprocessed_image, input_size) # 拷贝预处理图像到输入内存# 7. 推理执行
rknn_run # 执行模型推理# 8. 输出结果解析
# 直接从输出张量内存读取,无需额外拷贝
# 可执行Top-N、NMS、分类/检测结果处理等
process_output(output_mem->virt_addr)# 9. (可选)重复推理
rknn_run
process_output(output_mem->virt_addr)# 10. 资源释放
rknn_destroy_mem # 销毁输入/输出张量对象
RK_MPI_MMZ_Free # 释放外部分配的物理内存
rknn_destroy # 销毁RKNN上下文
7、总结
参考文章:
https://doc.embedfire.com/linux/rk356x/Ai/zh/latest/lubancat_ai/env/rknpu.html#linux