Week 1
1.1 Neural networks
Model
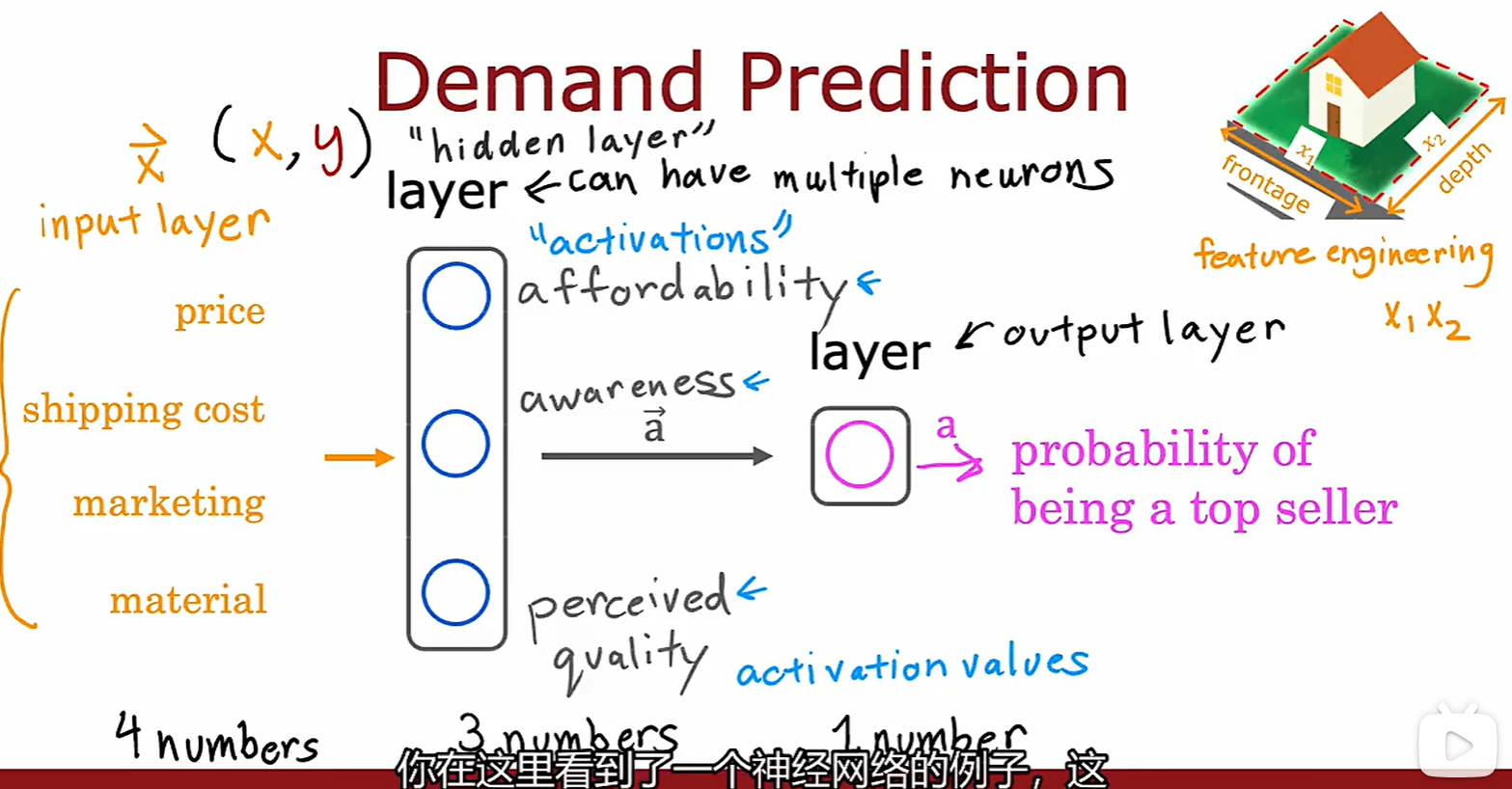
- 几个概念:输入、隐藏、输出层,激活值,特征向量 x;
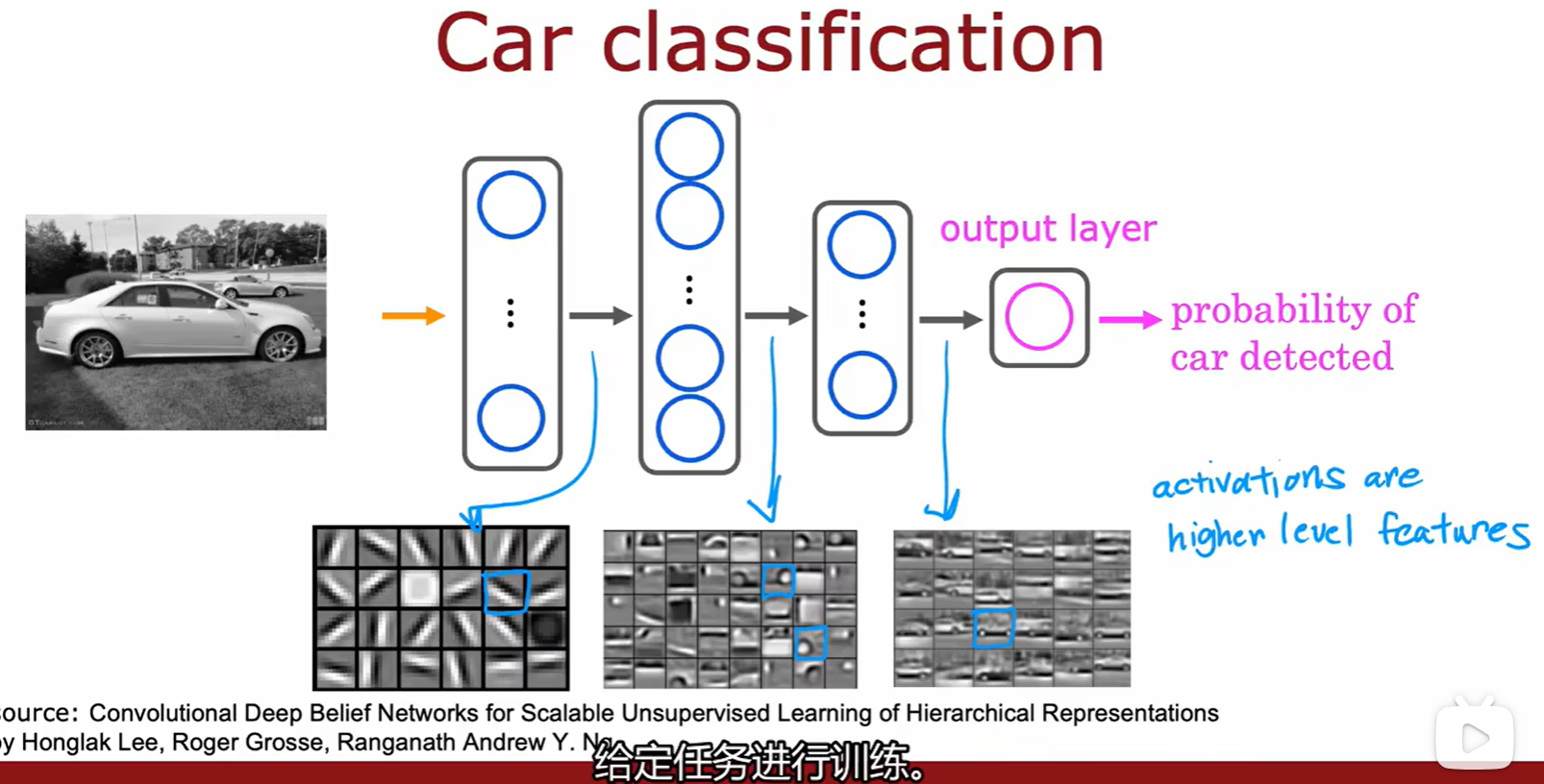
- 神经网络在图像识别中的作用:从细节组合到特征,再从特征组合成完整的图像;
Layers
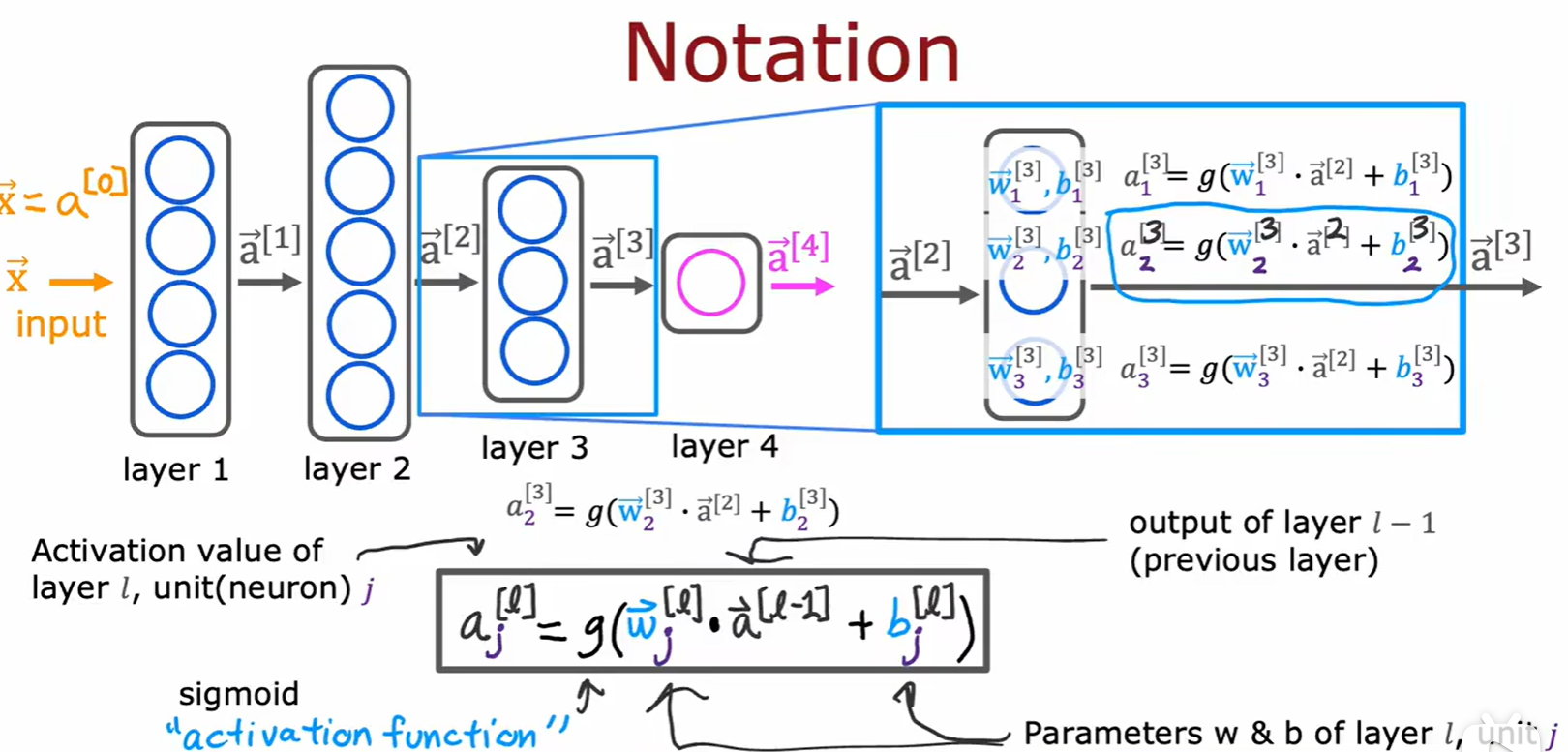
- 方括号内的值 i 表示这是与第 i 层有关的数据,上一层的输出就是下一层的输入;
Tensor

1.2 Forward Propagation


Week 2
2.1 Activation function
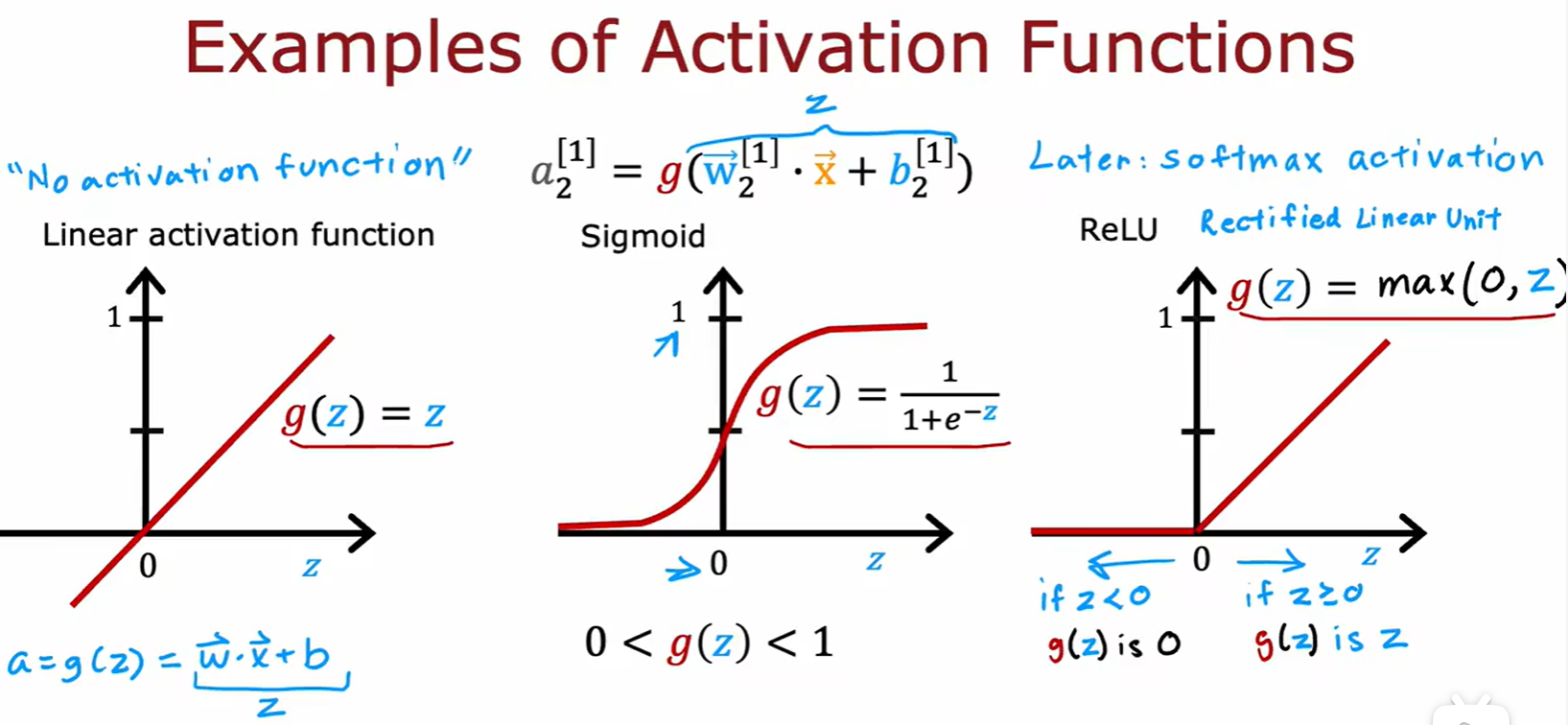
ReLU
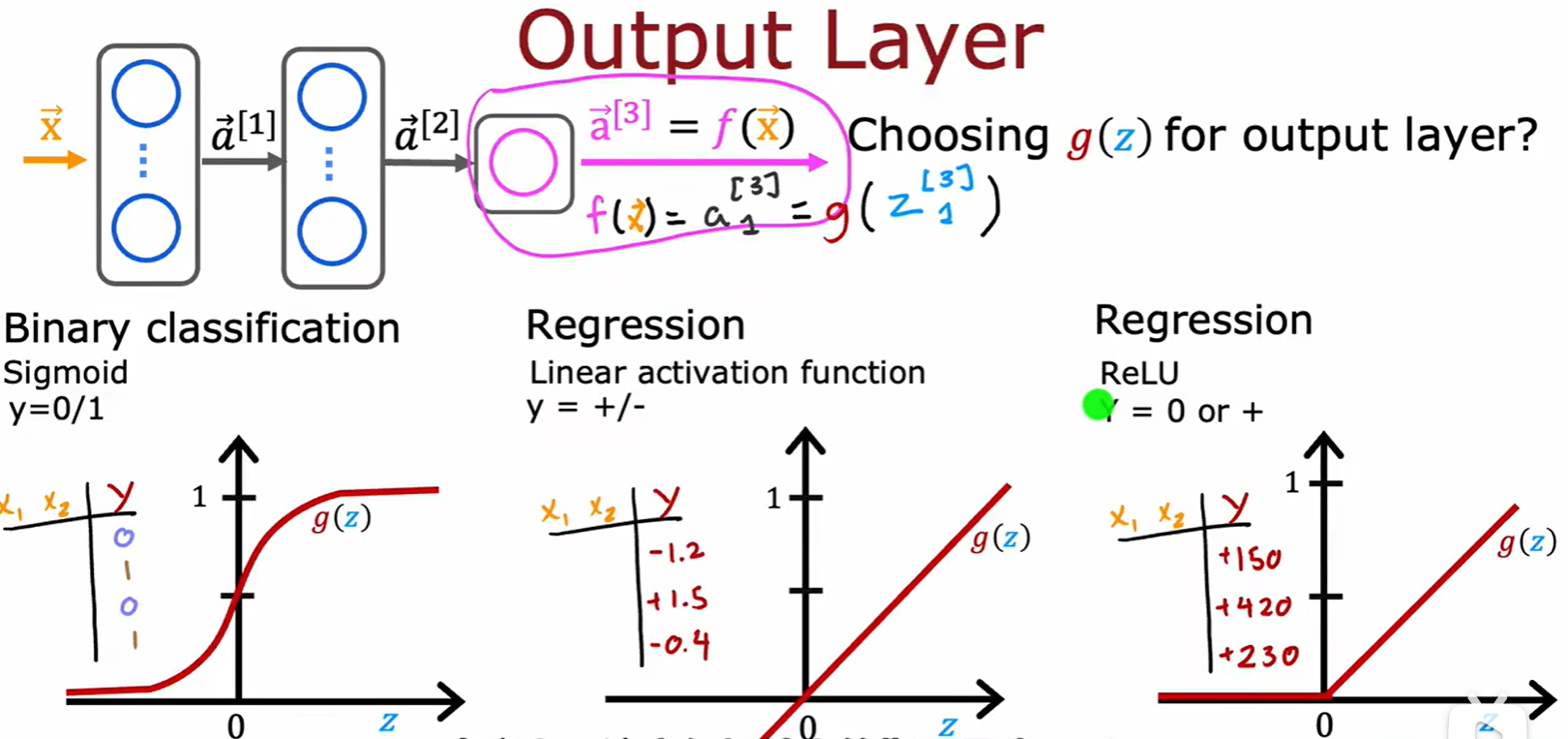
How to choose
- 输出层:二分类用 sigmoid,结果有正有负用线性,只有正用 ReLU;
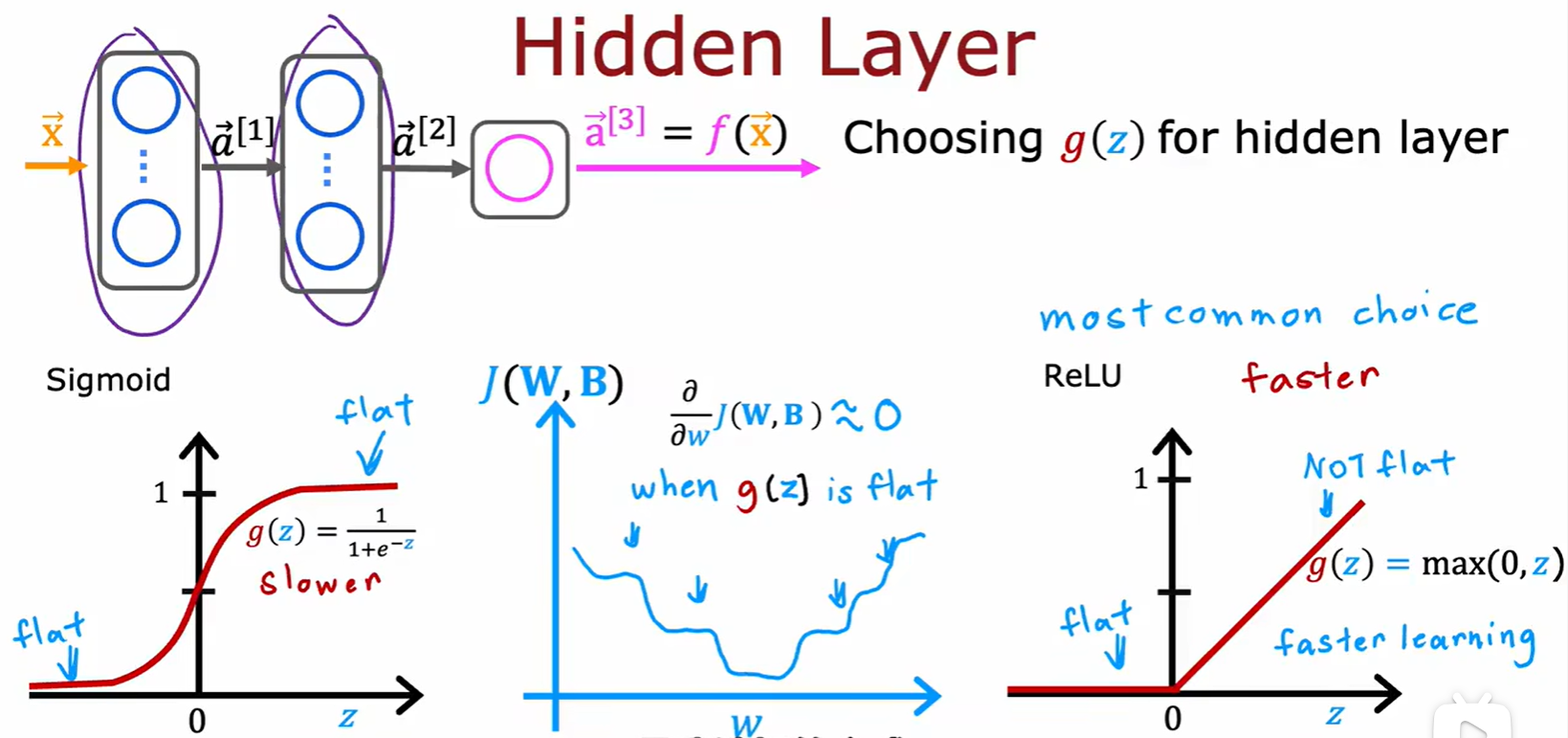
- 隐藏层:只推荐用 ReLU,相比与 sigmoid 计算速度更快(一是计算公式简单,二是函数只有一边是平的,这两个原因导致的速度更快)
Why we need
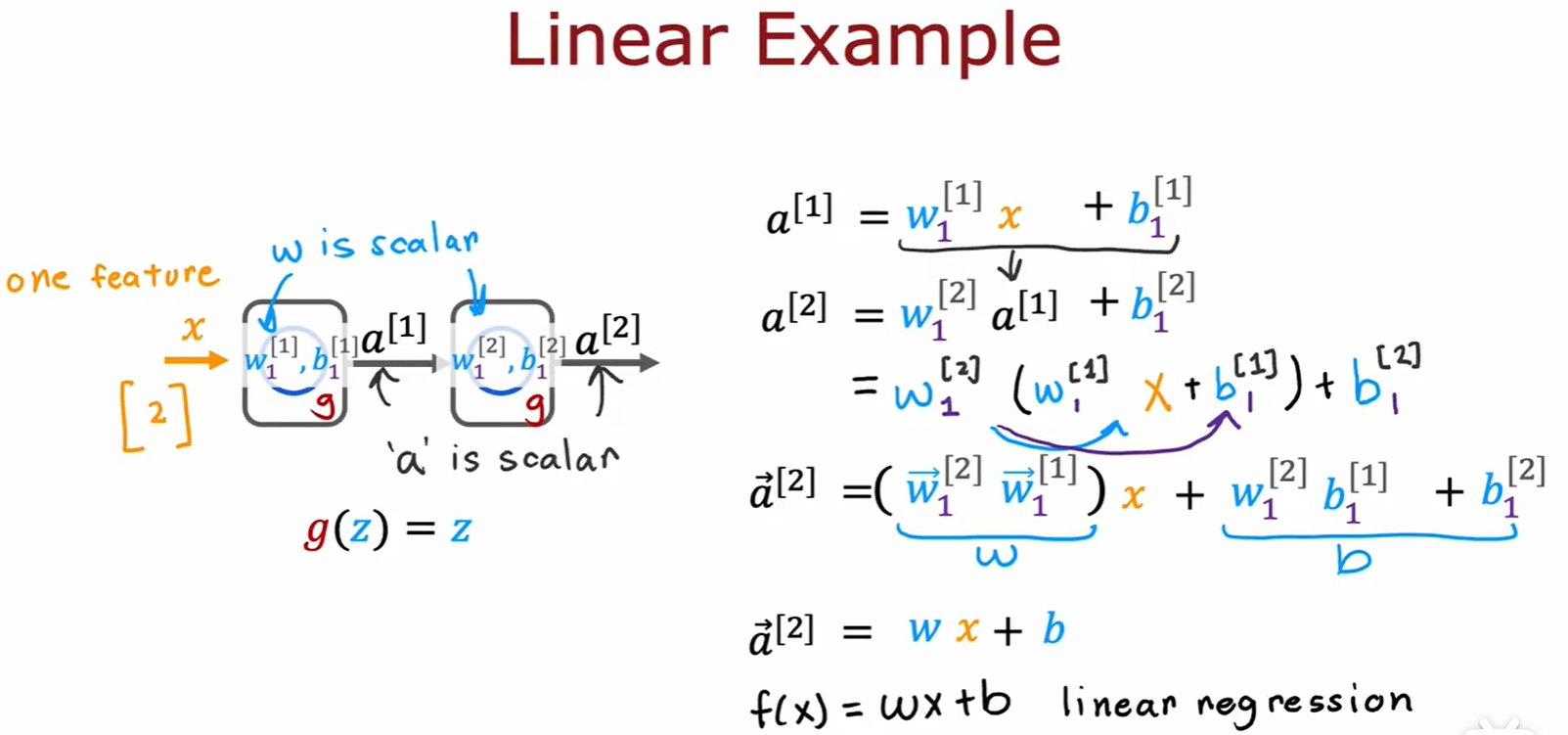
- 如果每一层都使用线性回归,最后也就相当于计算了一层线性回归而已,所以隐藏层推荐用 ReLU;
2.2 Multi-class Clssification
Softmax Regression

Cross Entropy Loss
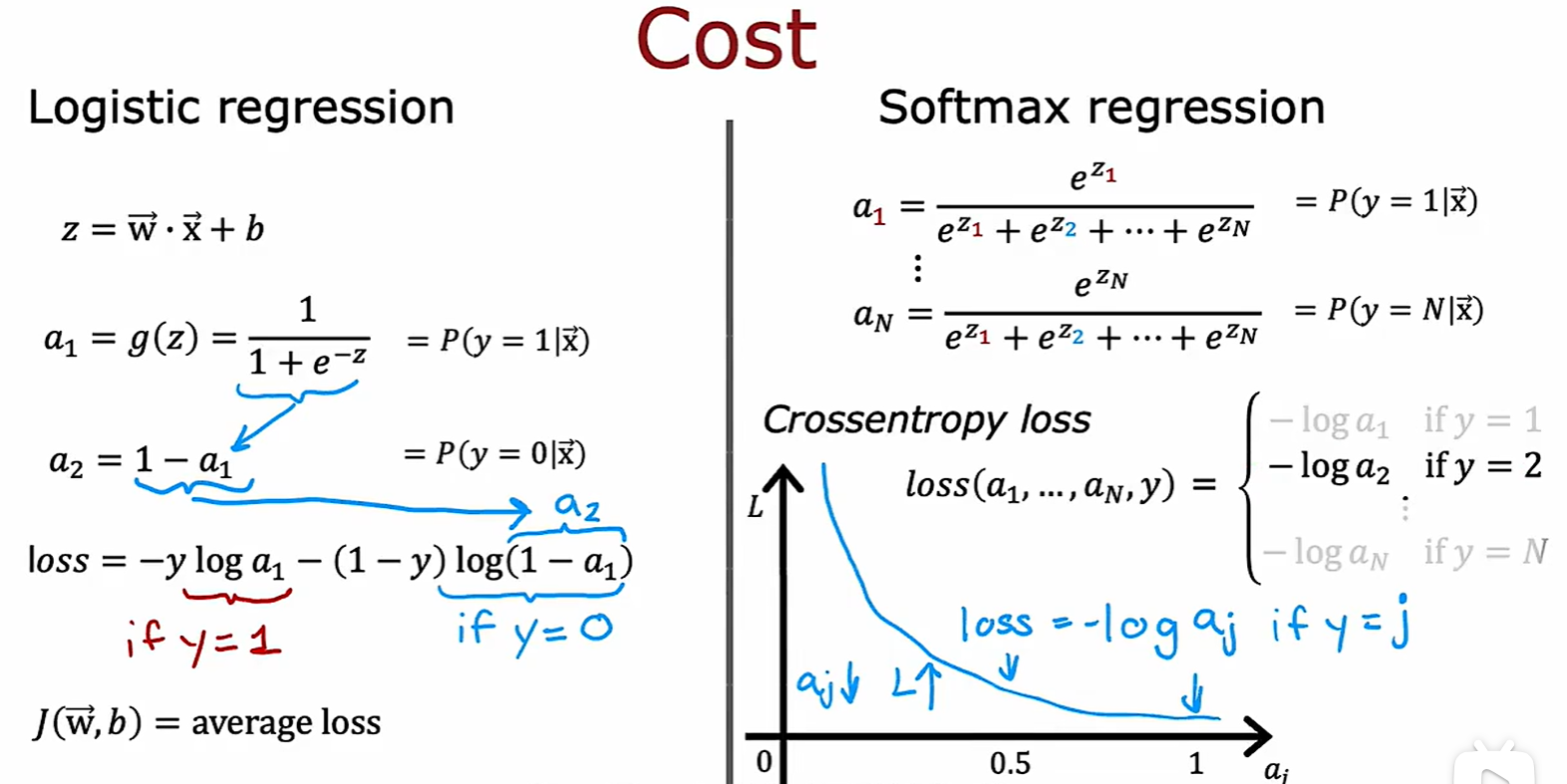
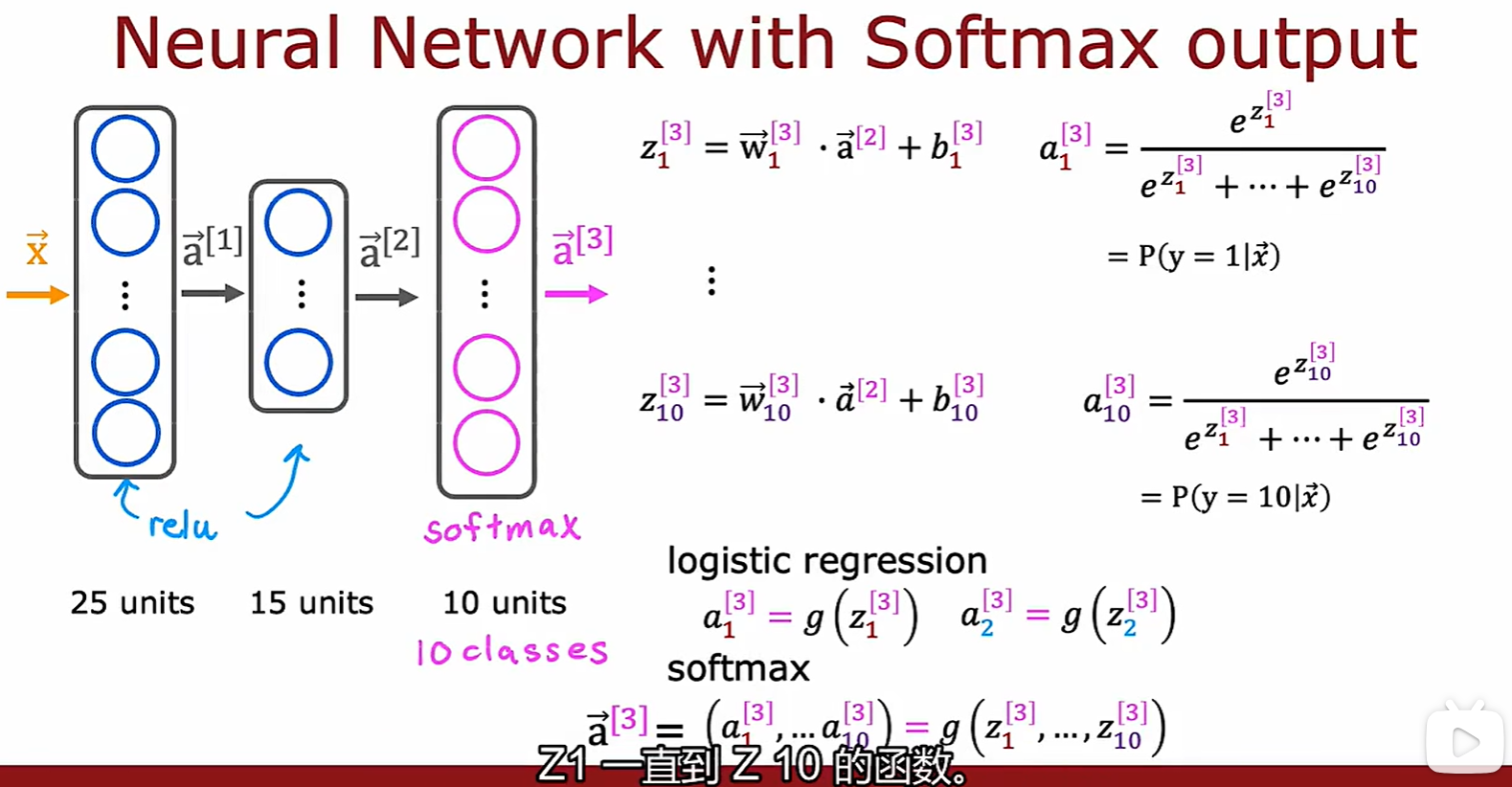
Softmax output
- 在其它激活函数中,ai 是 zi 的函数,而在这个激活函数中,ai 是 [z1 - zn] 的函数;
2.3 Multi-label Clssification
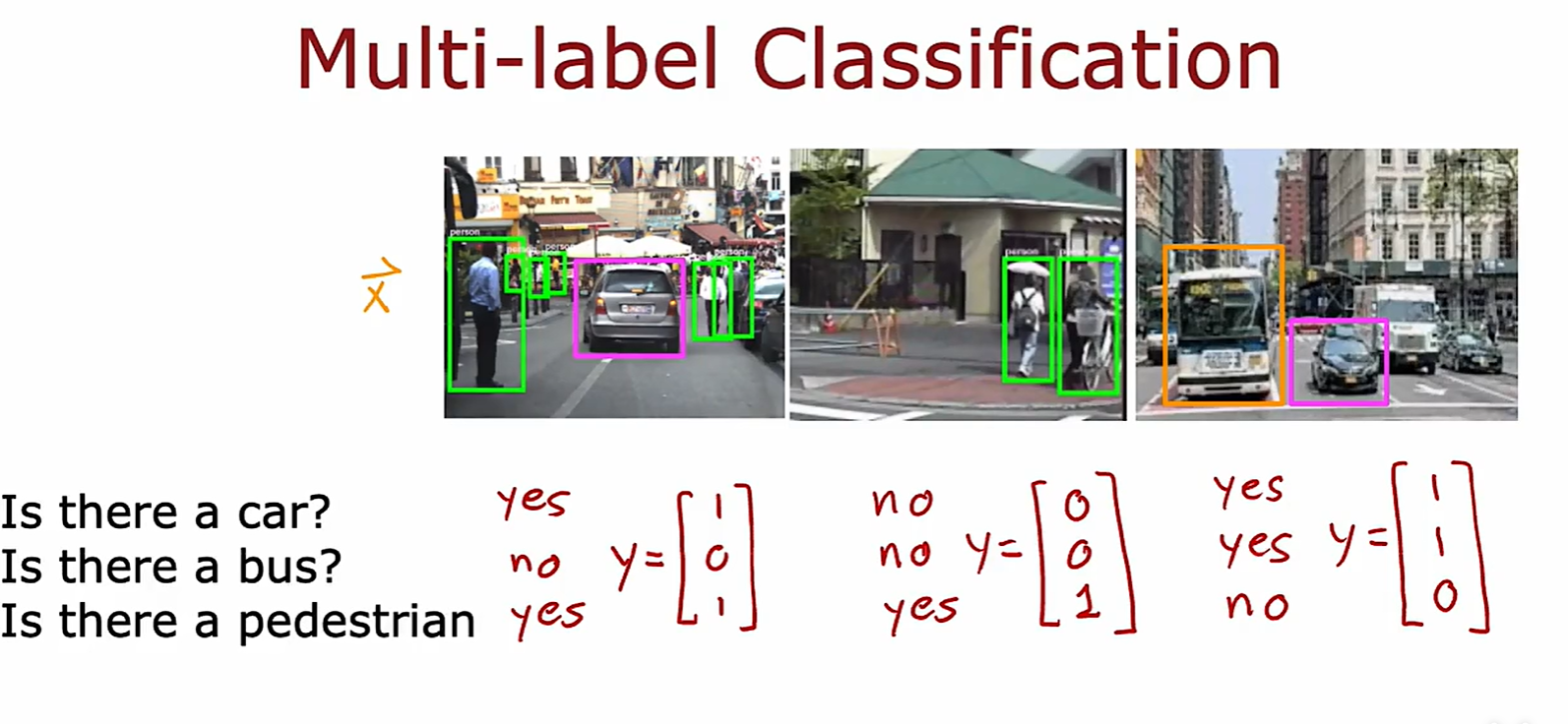
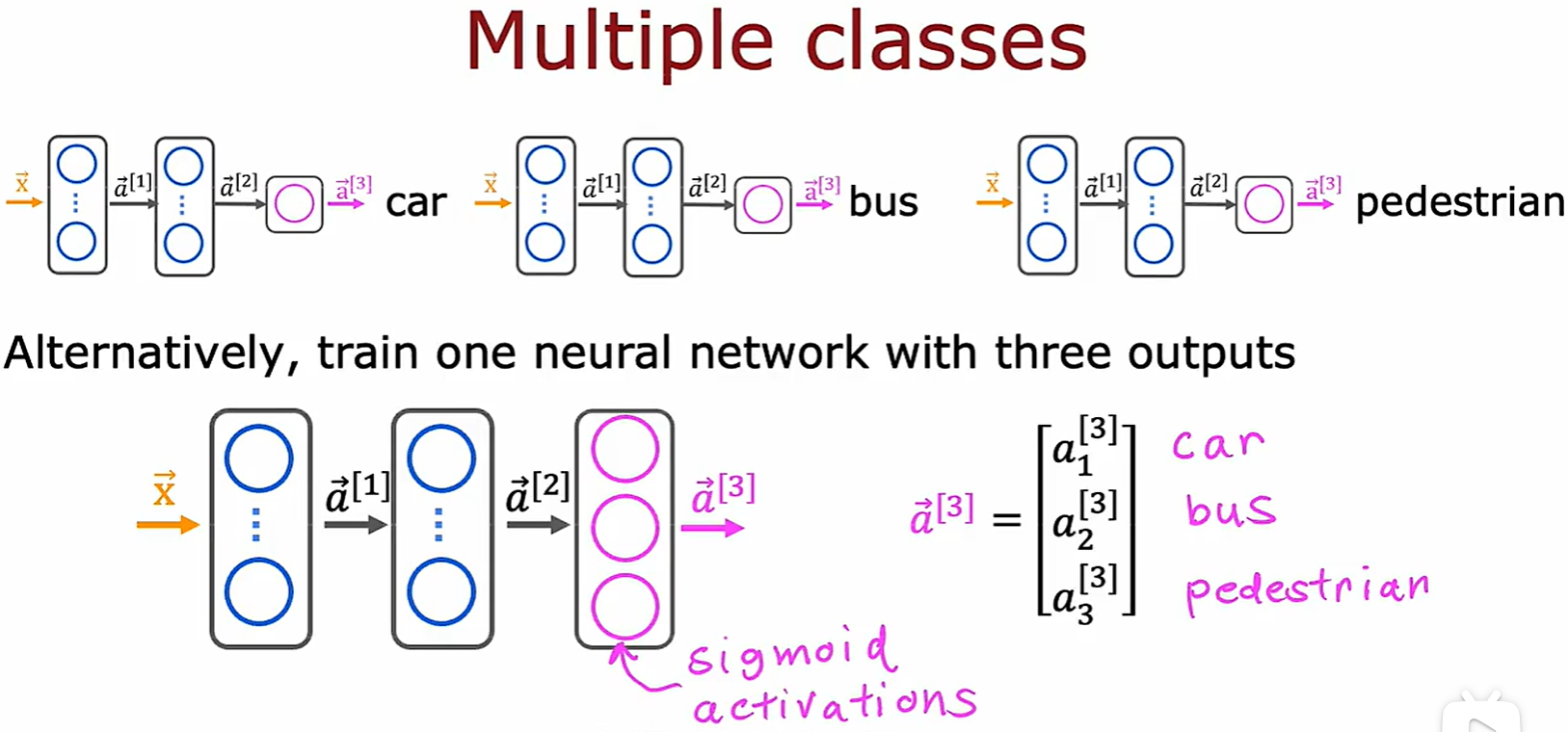
Difference
- 多标签得到的结果是不同类别的独立概率,而多分类是同类别的相关概率;
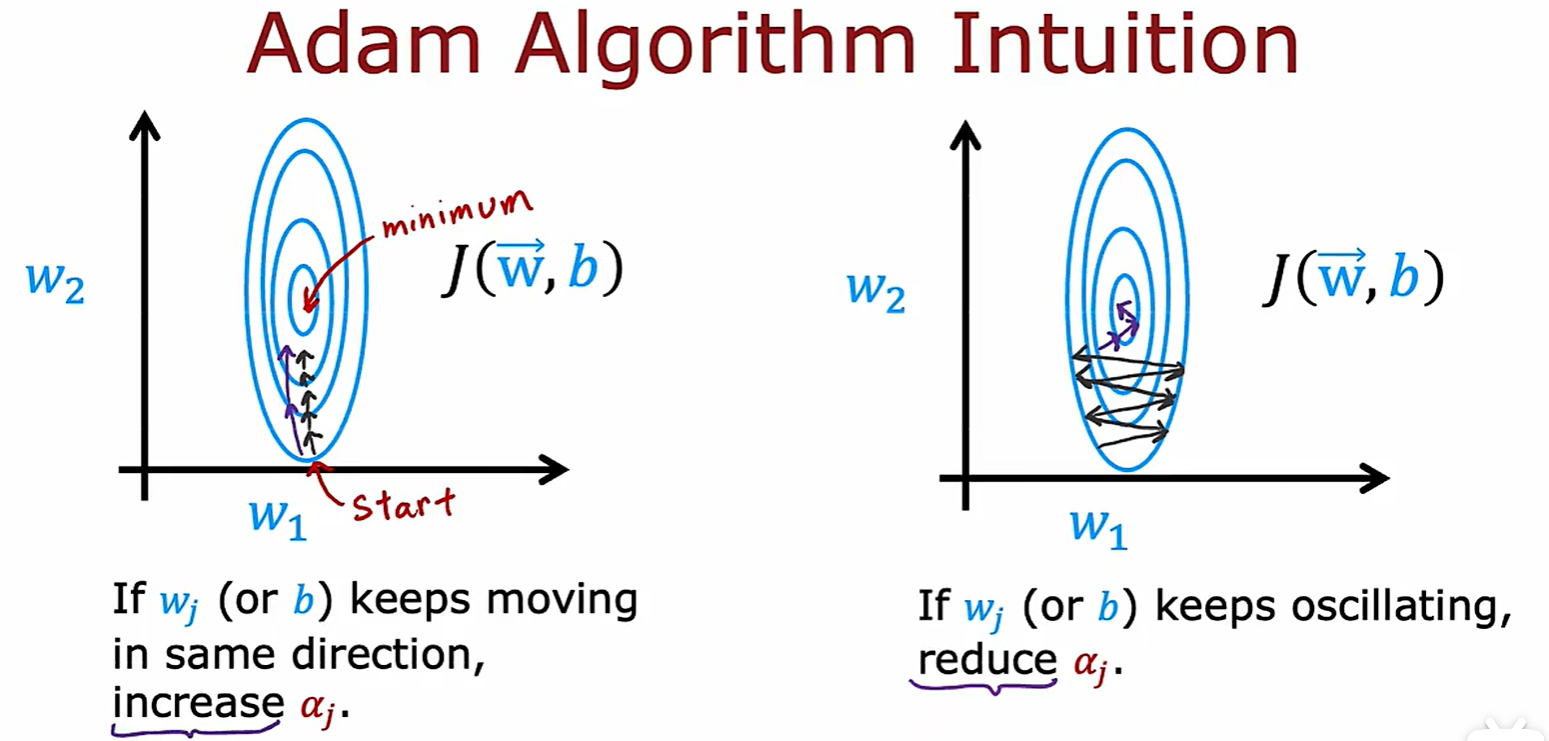
2.4 Adam algorithm
Advantage
- 和梯度下降算法不一样,Adam 算法可以根据下降方向的变化,动态地调整学习率的大小;

2.5 Convenlutional Neural Network
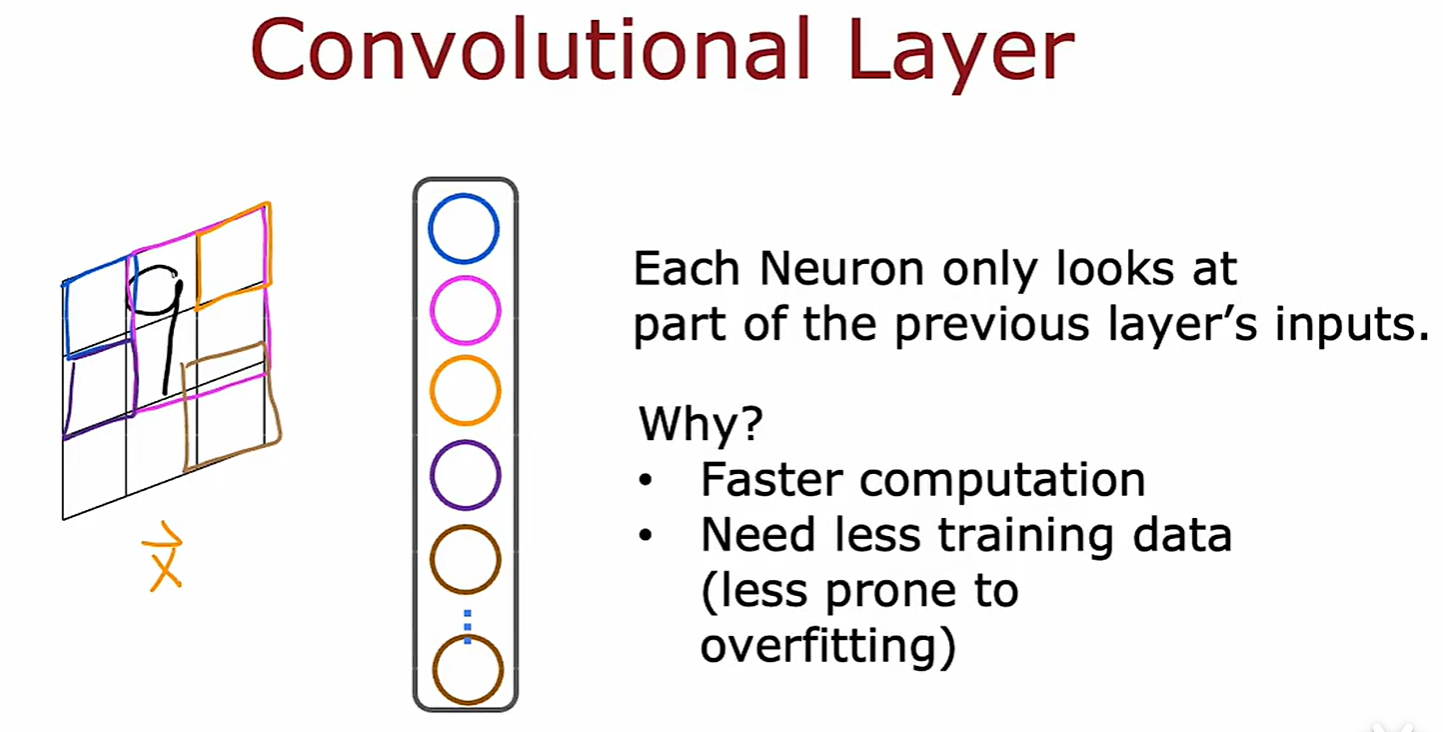
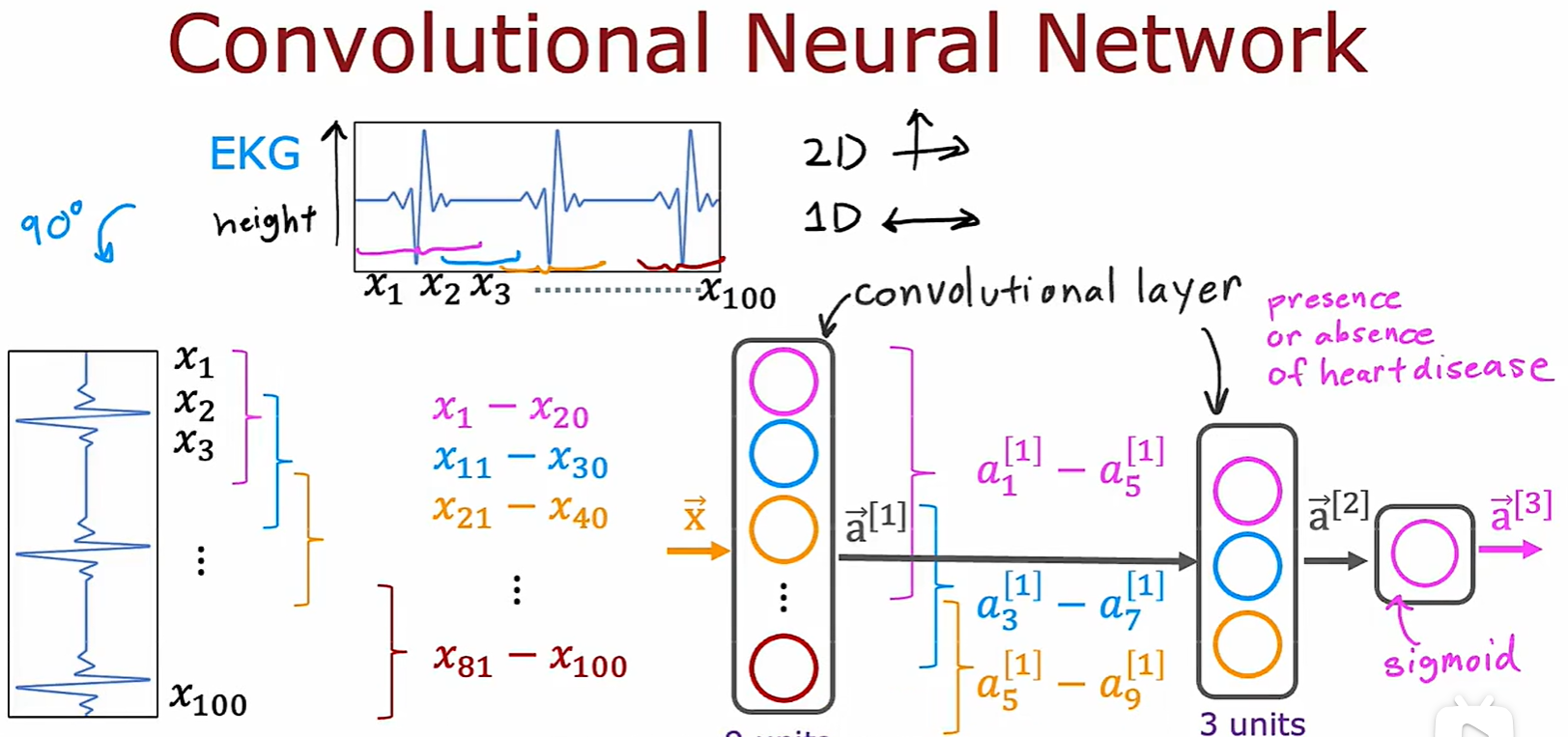
Convenlutional Layer
- 卷积层:一层中的某个神经元只选择 x 的一部分作为输入;
Week 3
3.1 Choosing Model
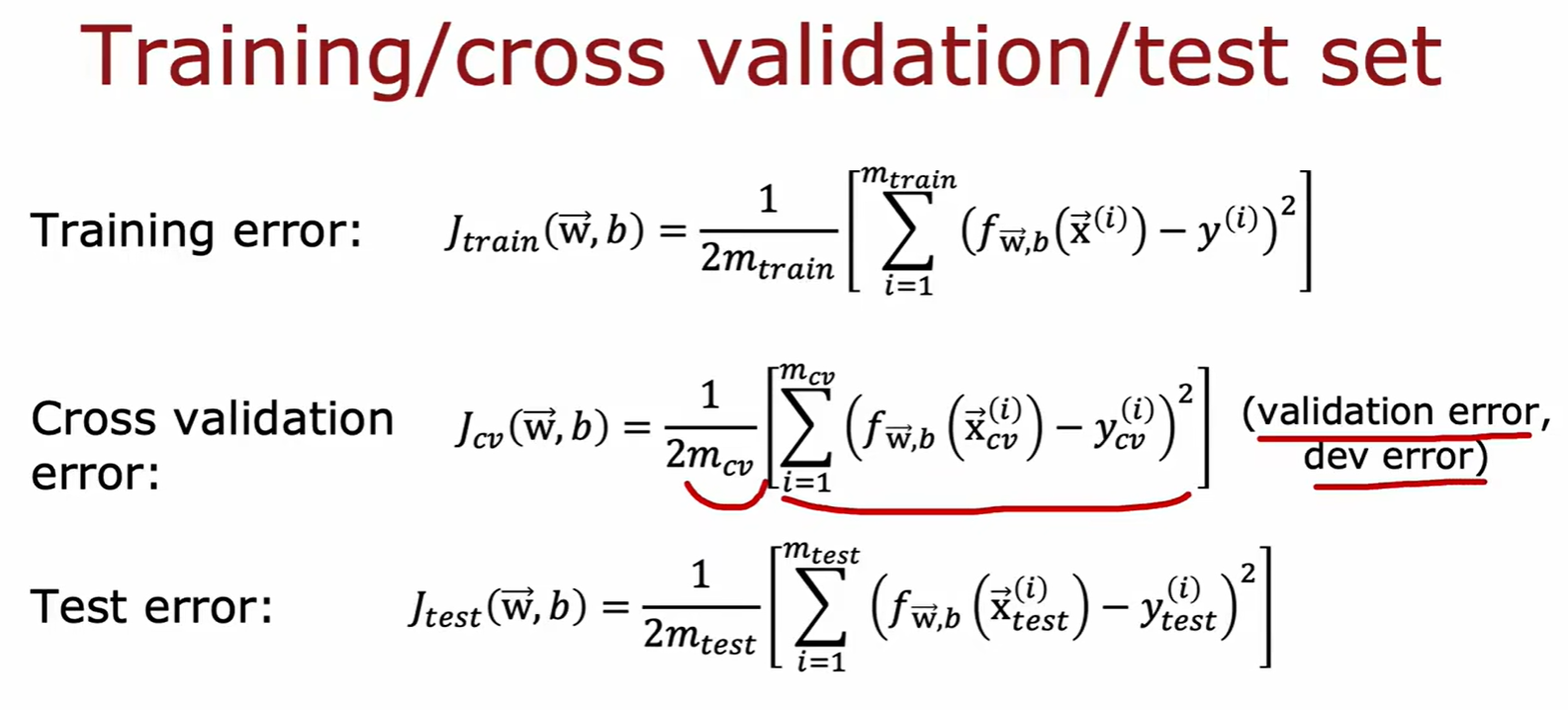
- 本质:选择几个模型进行训练,然后用交叉验证集对几个模型进行损失值评估,以此选出最好的模型,再通过测试集新数据评估该模型泛化误差;
Test set
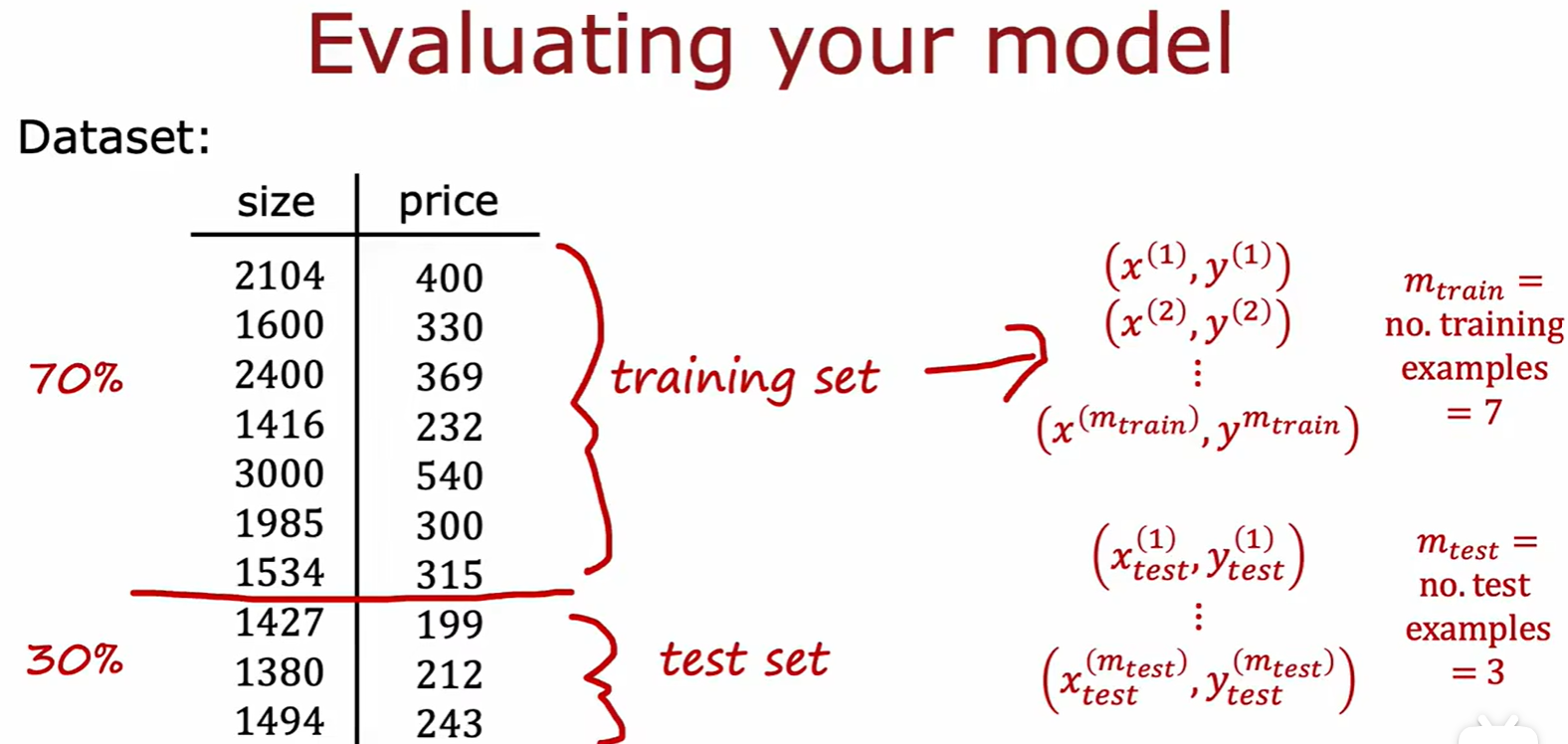
- 计算测试集的损失(损失计算不包含正则化这一项),来评估训练结果:


Cross validation set
- 交叉验证集(验证集,开发集):计算该集合损失,选择最合适的模型;

3.2 Diagnosing model
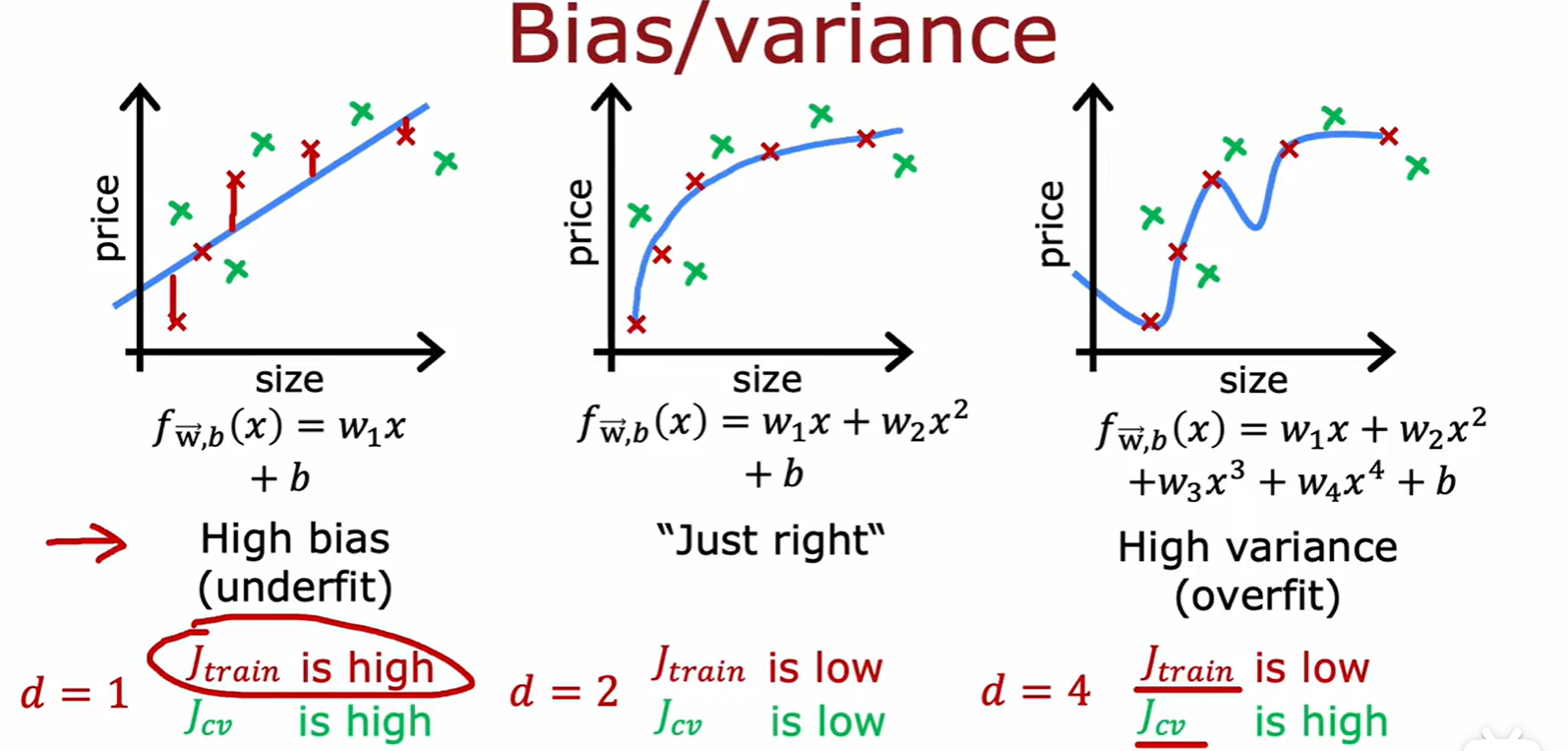
Bias / variance
- 高偏差:模型在训练数据上表现不好;
- 高方差:模型在训练数据上表现很好,但在新数据(交叉验证集)上表现较差;
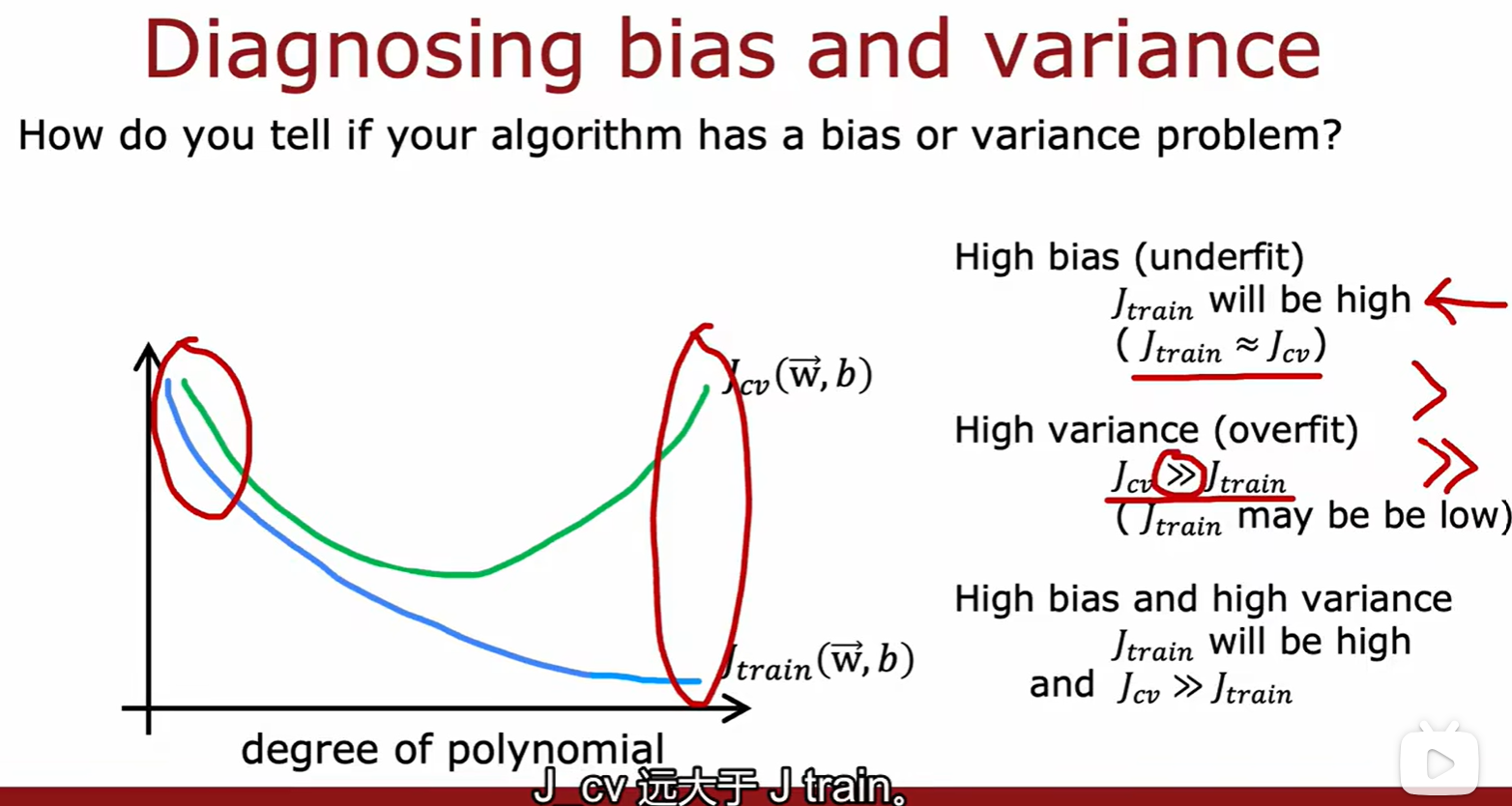
- 训练集损失,交叉验证集损失在不同维度的模型下的大小变化:
Lambda
- 如何选择
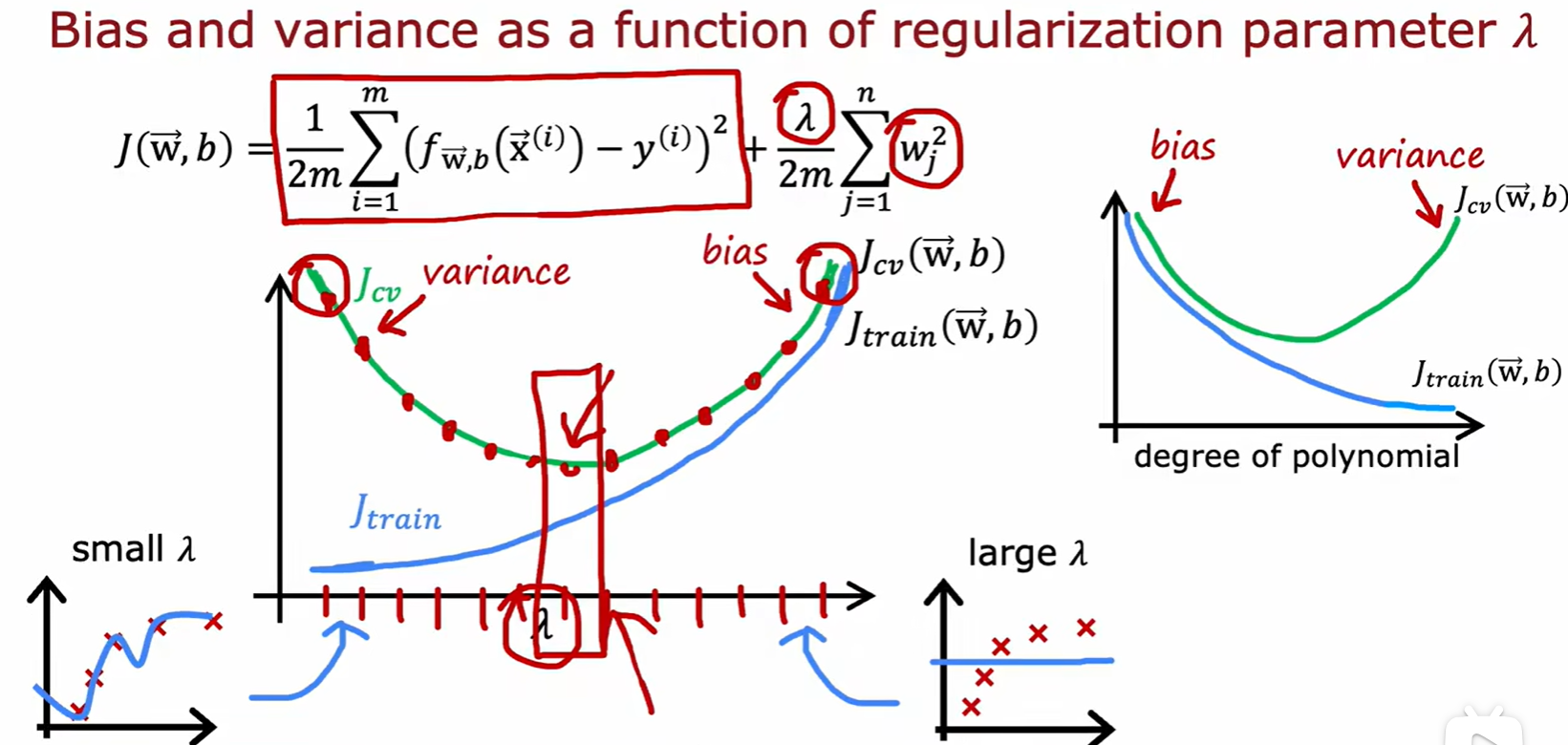
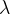 :
:

- 训练集损失,交叉验证集损失在不同 的模型下的大小变化:
Performance Evaluation
- 评估模型性能首先得知道基准水平,比如声音识别中人类可以达到的准确率:


3.3 Learning curves
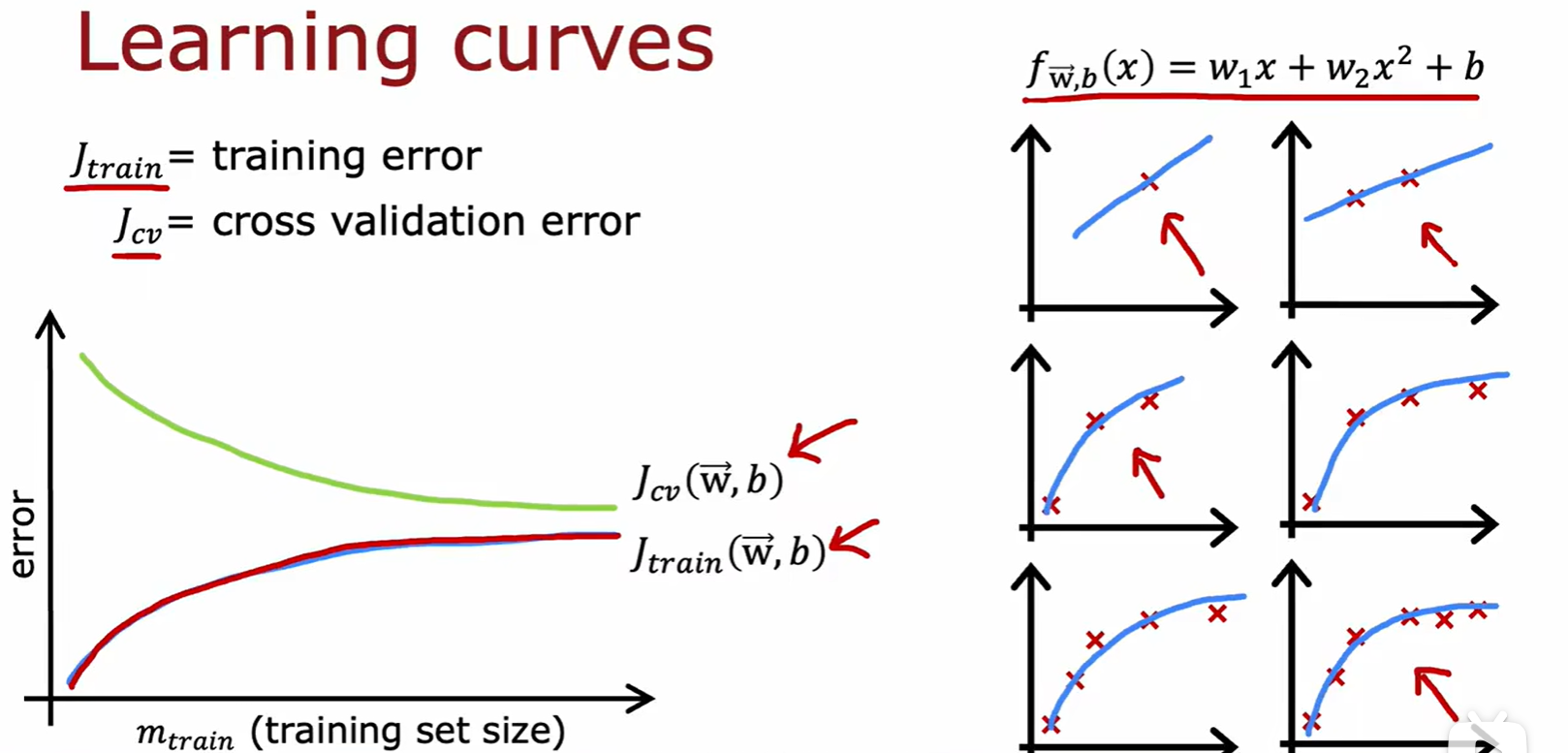
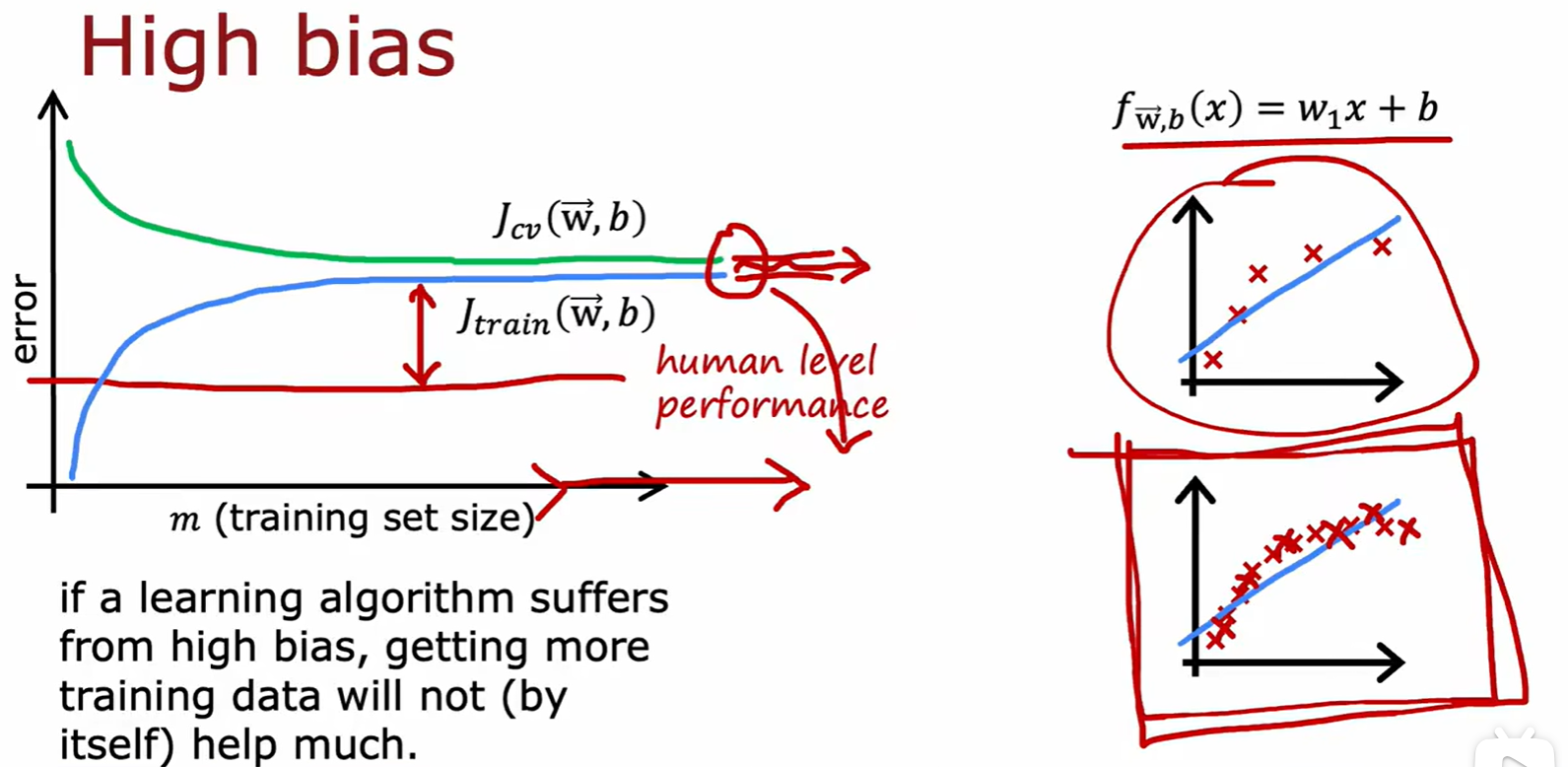
High bias
- 在只有调整训练集大小的操作中,如果存在高偏差,那么增加训练集作用很小;
High variance
- 在只有调整训练集大小的操作中,如果存在高方差,那么增加训练集作用比较大;

Summary

Bias/variance in Neural networks
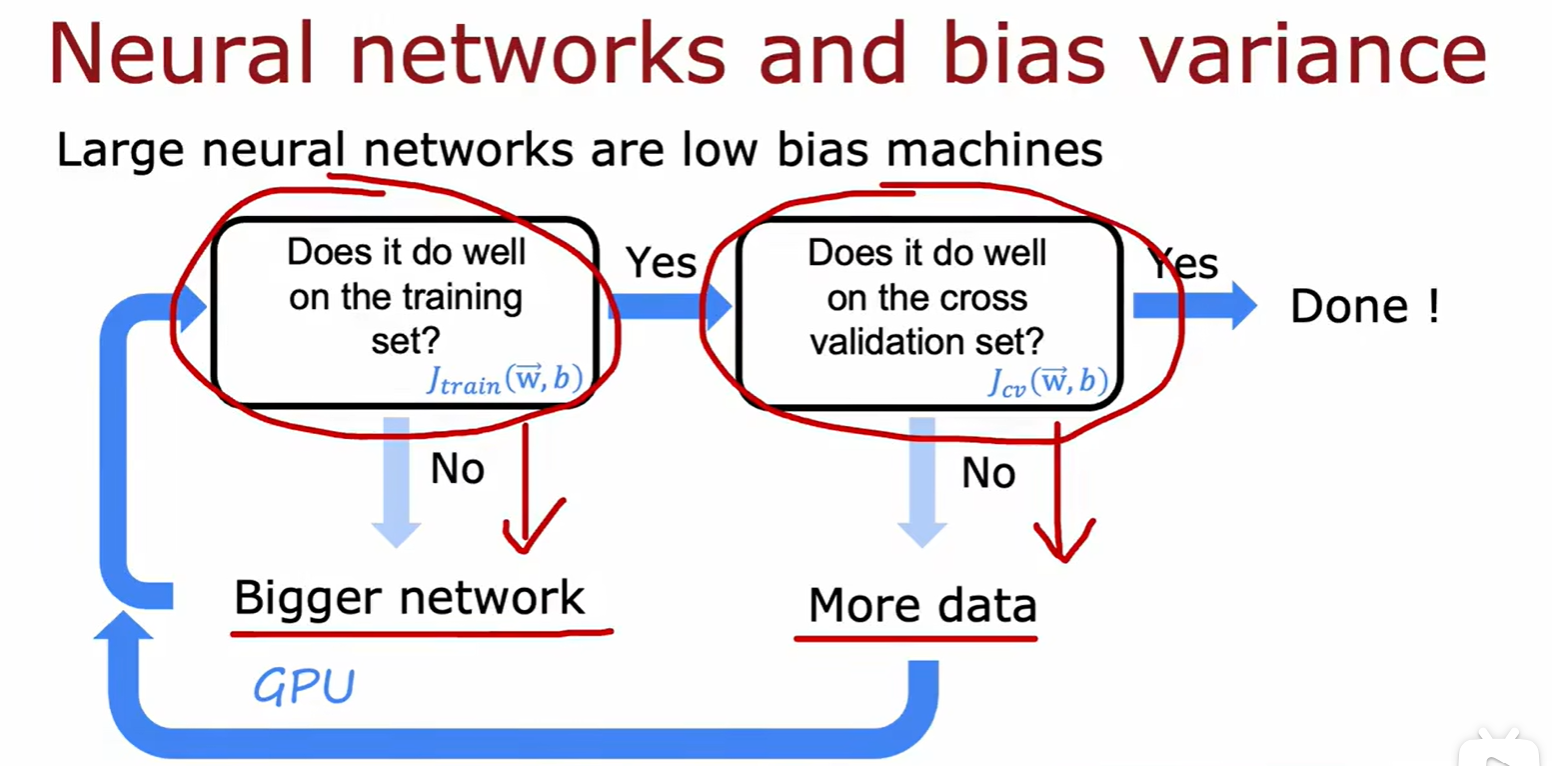
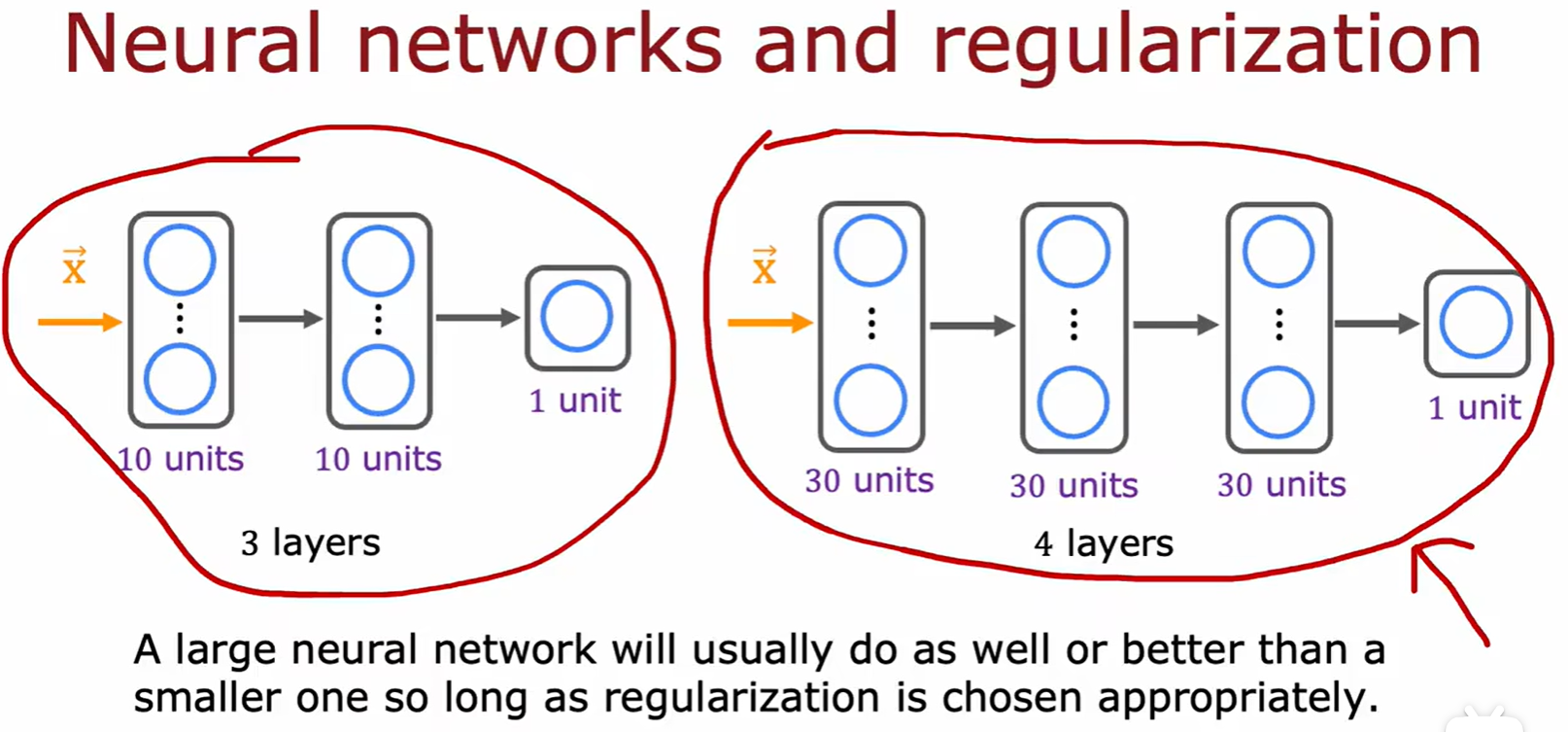
- 在神经网络中,只要选择了合适的正则化,那么增加神经网络层数通常都能减小偏差;
3.4 Getting Data
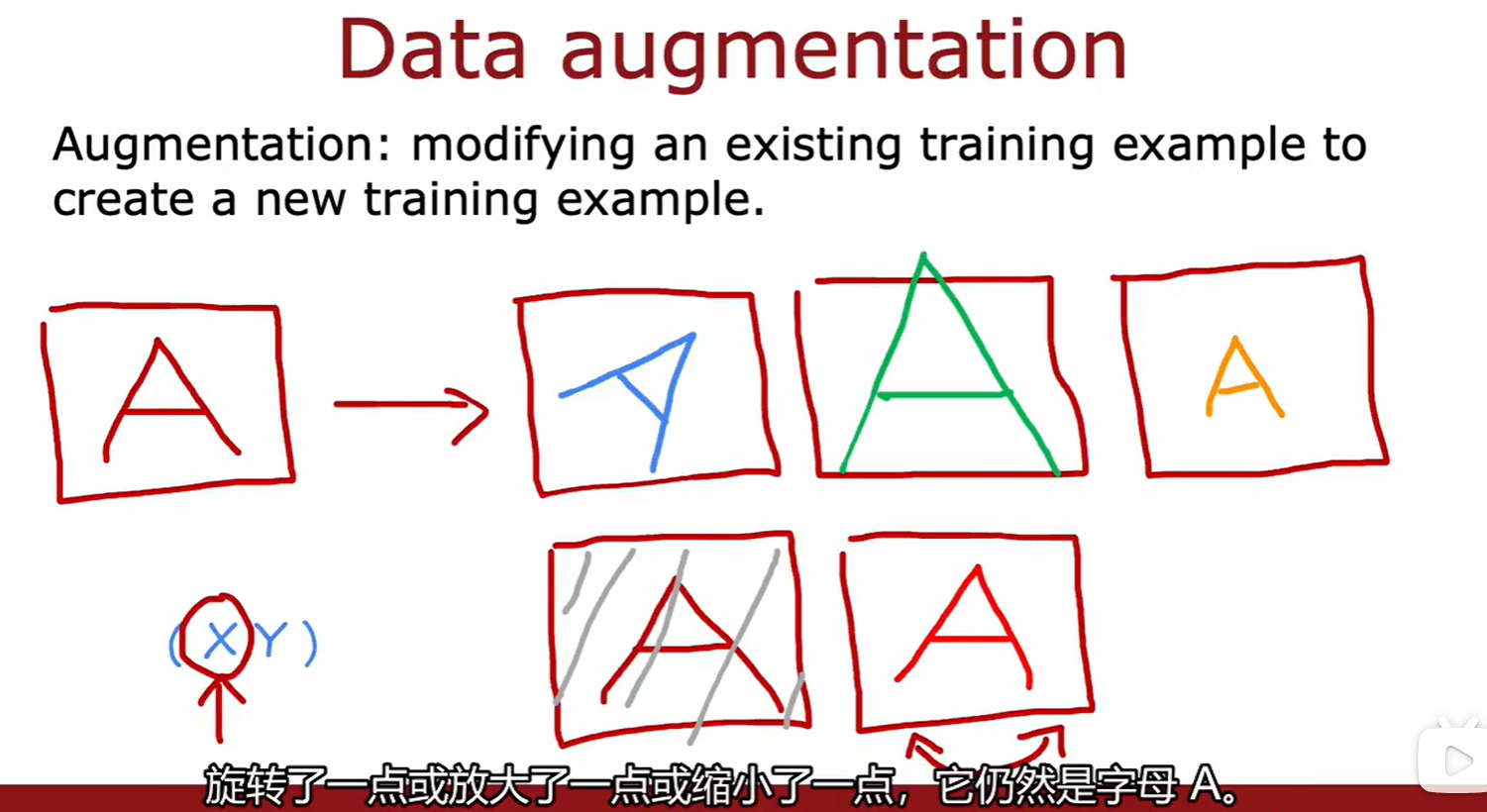
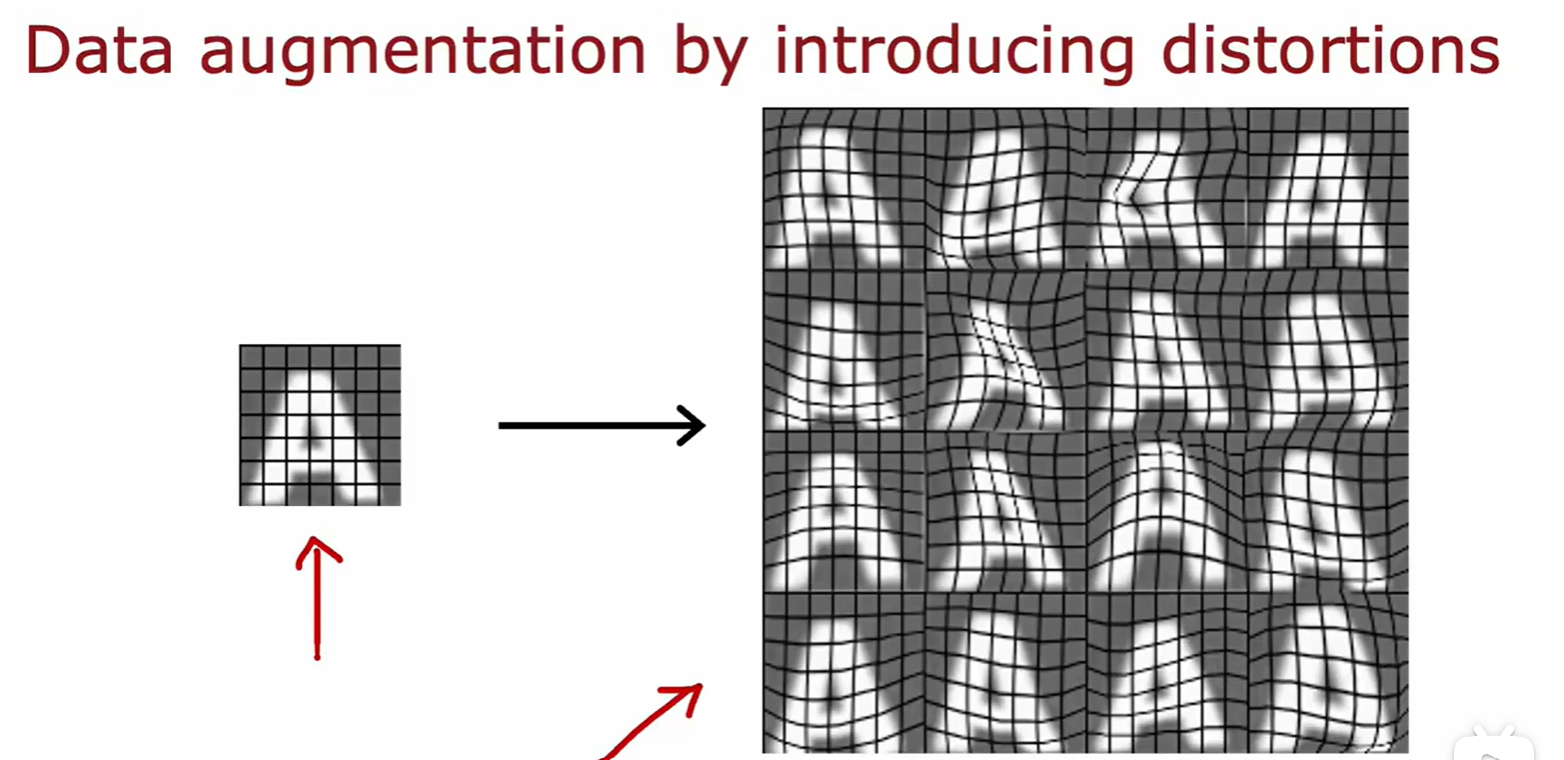
Data augmentation


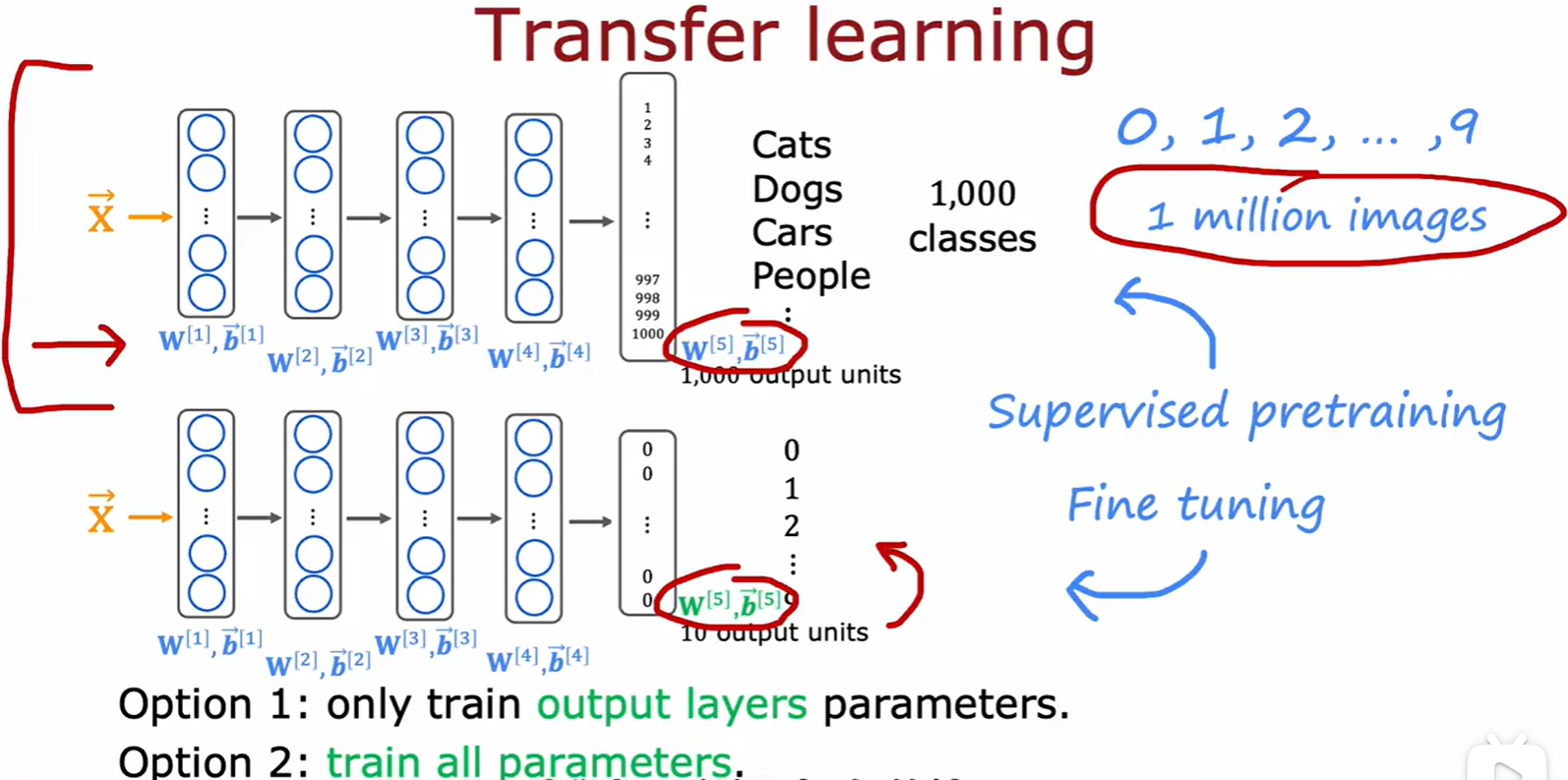
Transfer learning
- 迁移学习:应用场景是你的手写识别数据集不够,而其他猫狗数据集足够的情况下,用别人已经做好的模型更换输出层做预训练;
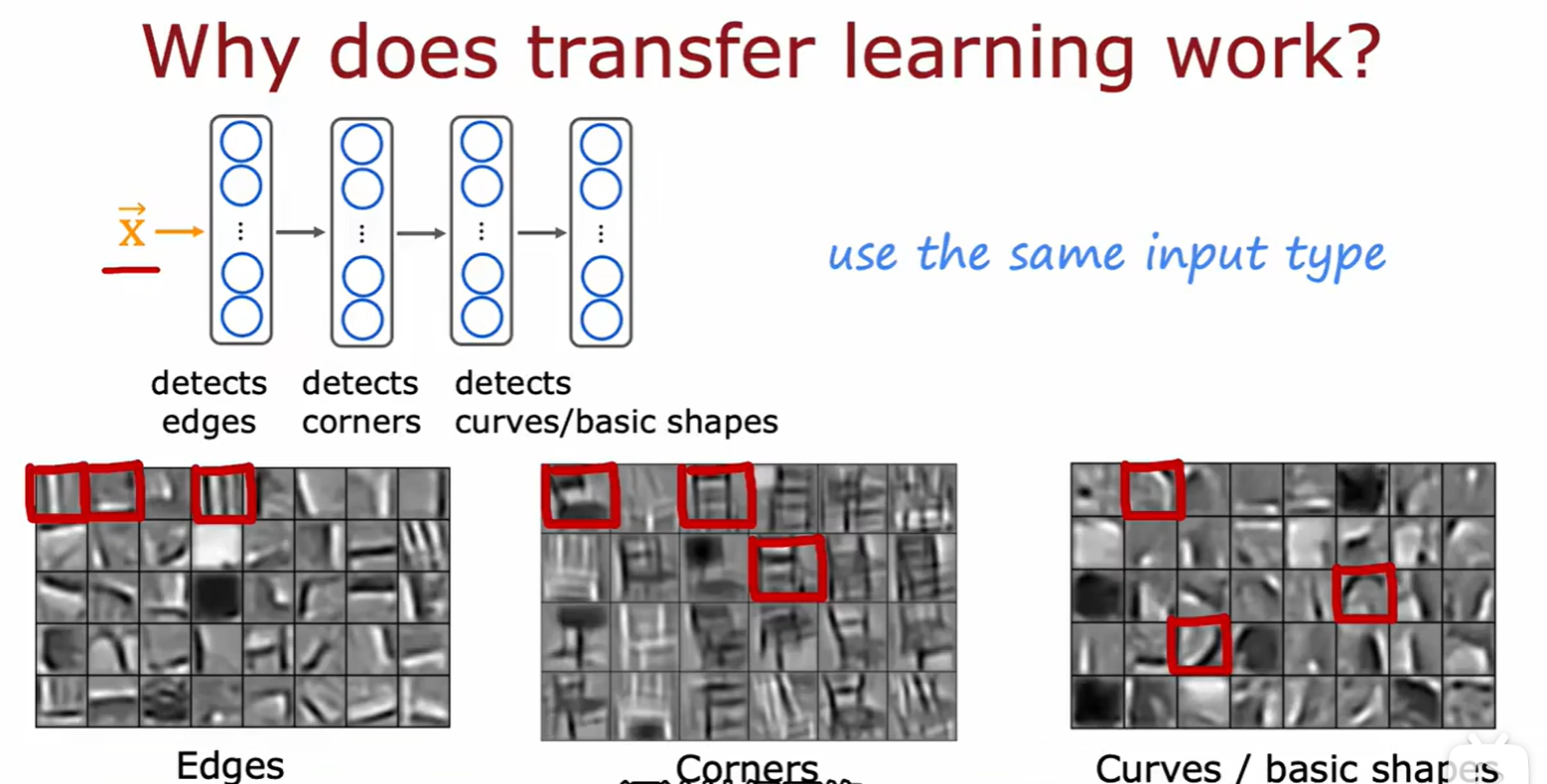
- 迁移学习需要预训练模型的输入和我们所需的相同,如文本、音频等;
- 底层原理就是神经网络的隐藏层是由边缘到角落慢慢地构建框架的,可以套用;
3.5 Skewed Datasets
- 倾斜数据集:这里的意思是这种病是一种罕见病,在人群中只有0.5%的发病率,所以我的模型预测没病的概率是100%,这样的话我的模型准确率还有99.5%;
- 由于 99.5% 准确率的模型只会判断为无病,所以准确率低一点的模型反而可以检测出一些有病的情况;

Precision / recall
- 精确率与召回率:两者都较高的模型拟合的更好;
- 精确率:预测为 1,且确实为 1 的概率;
- 召回率:事实为 1,且预测为 1 的概率;

Trading off precision and recall
- 权衡精确率和召回率:当希望预测的更准确,则设置阈值变大,此时精确率上升、召回率下降,反之同理;

F1 score

Week 4
4.1 Decision Trees
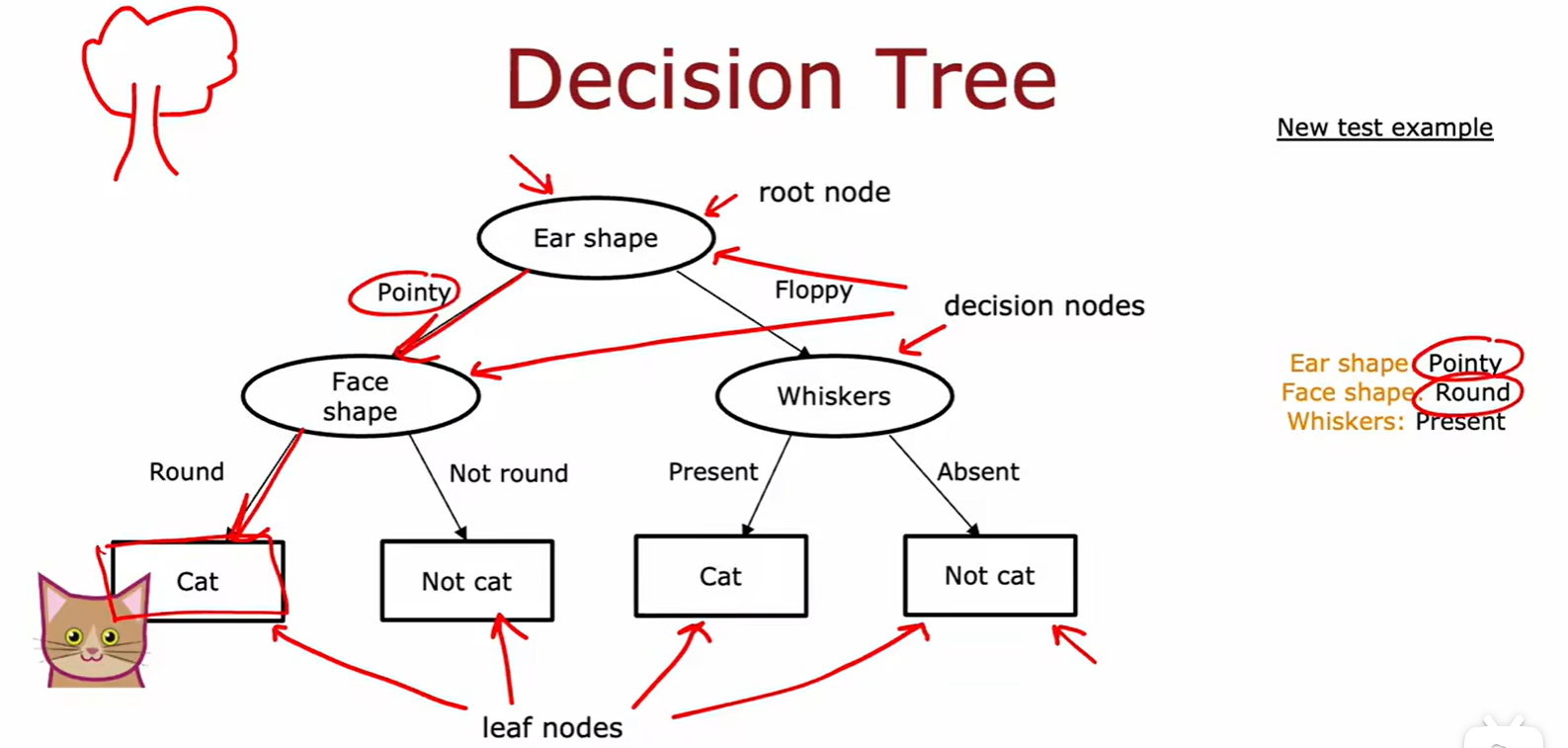
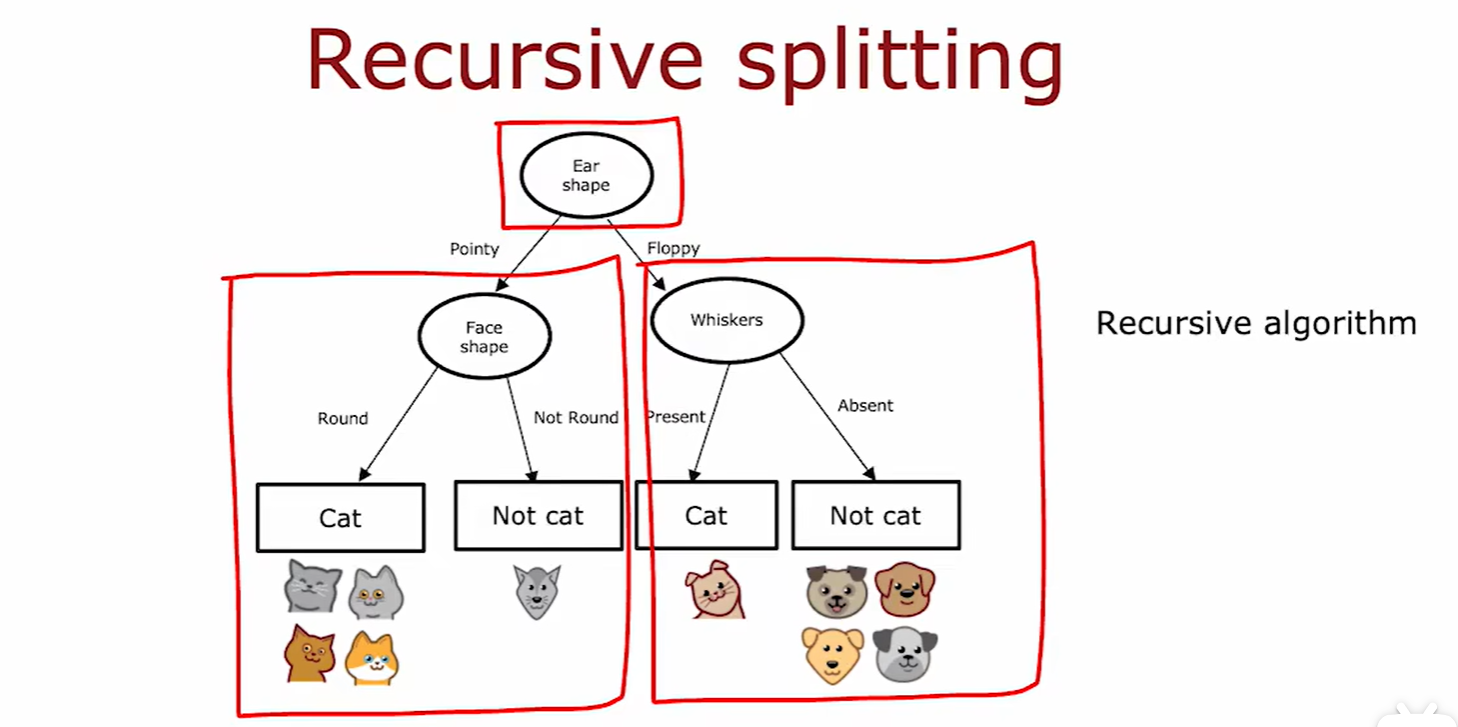
Learning Process


Purity
- 纯度:利用熵函数进行计算,在比例为 0.5 时纯度最低,也就是熵最小;

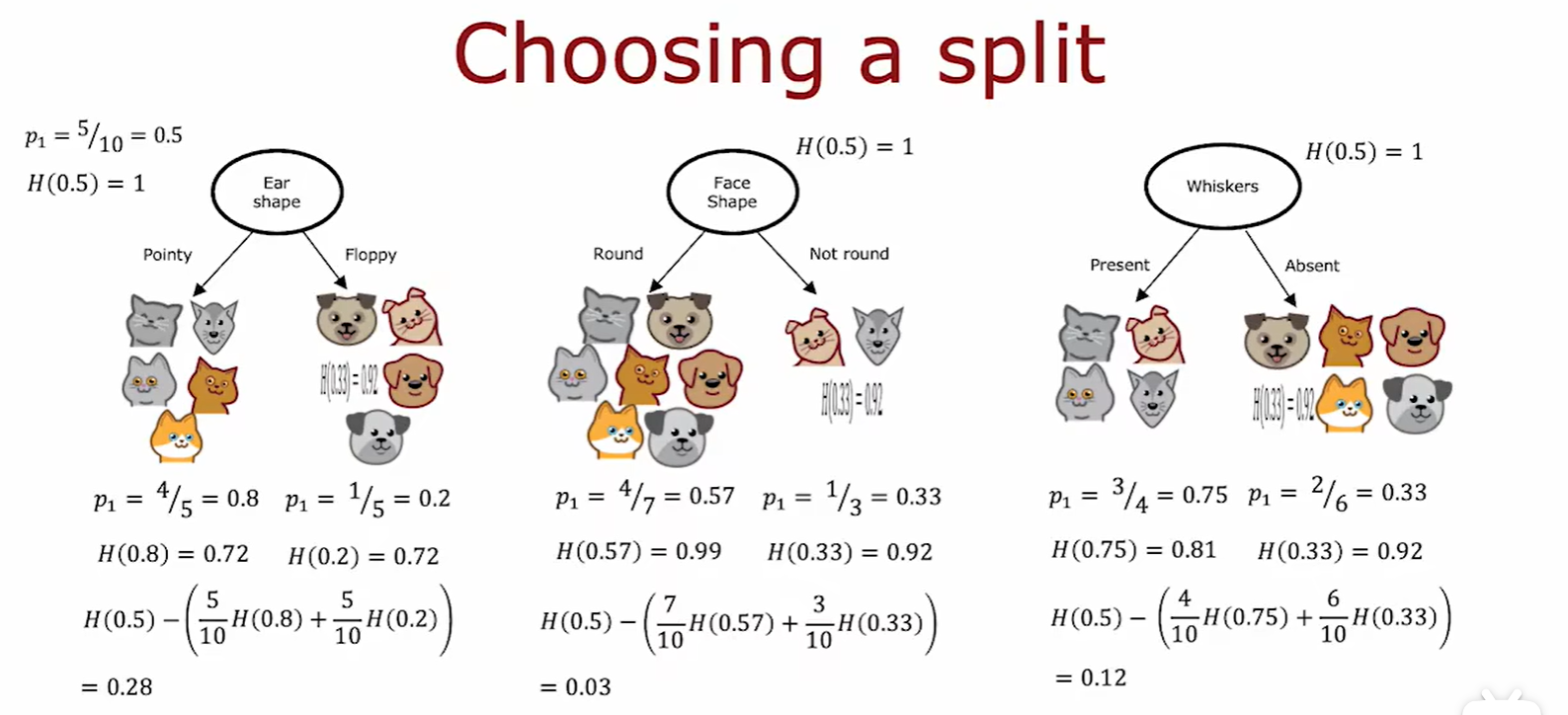
Choosing a split
- 熵的减少称为信息增益(information gain),选取信息增益最大的分裂方式;
- 这里处理两边熵值的方法为加权平均数,因为熵更大的数地位更高:
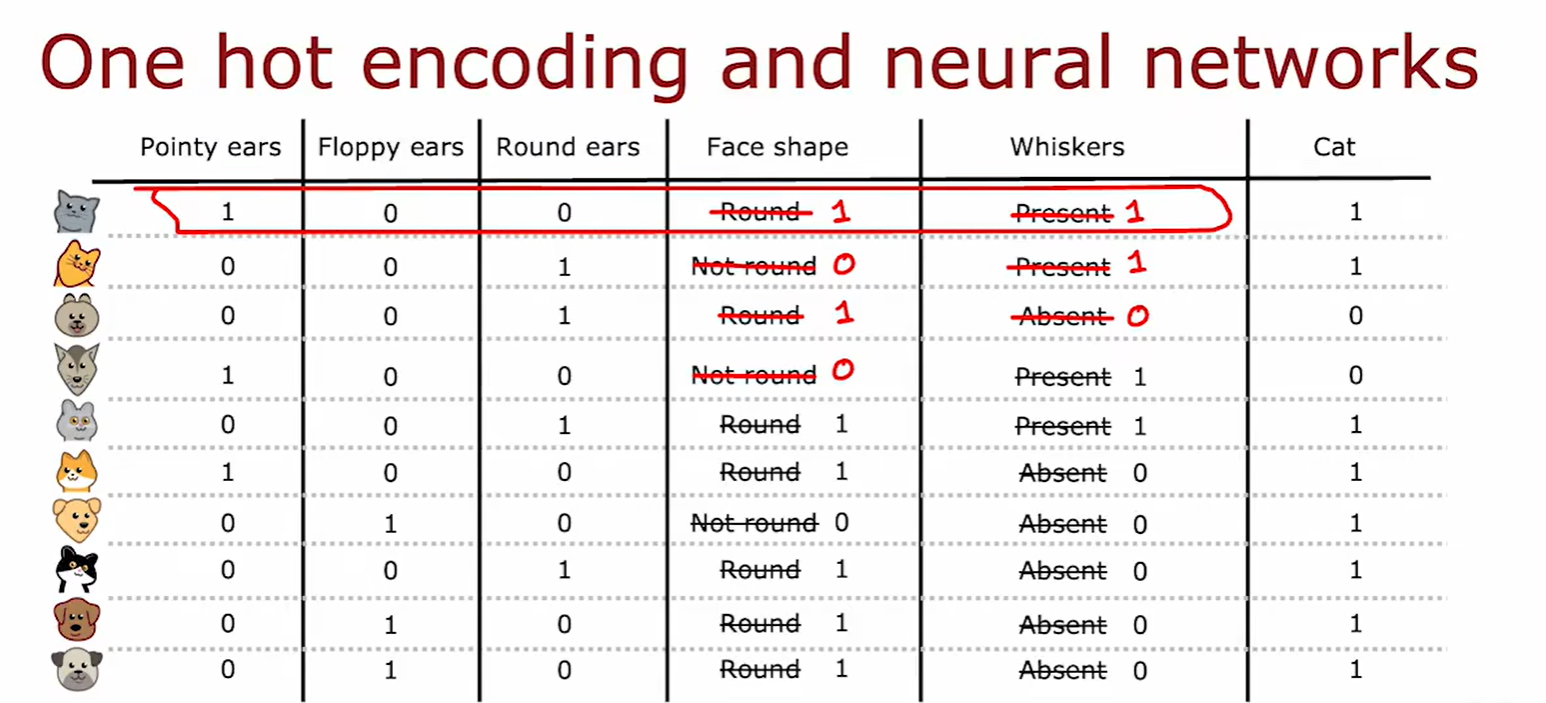
One-hot encoding
- 独热编码:当某个特征具有两个以上特征值时(设为3),将其转化为3个单独特征进行分裂,分别用 0,1 对是否含有该特征进行赋值;
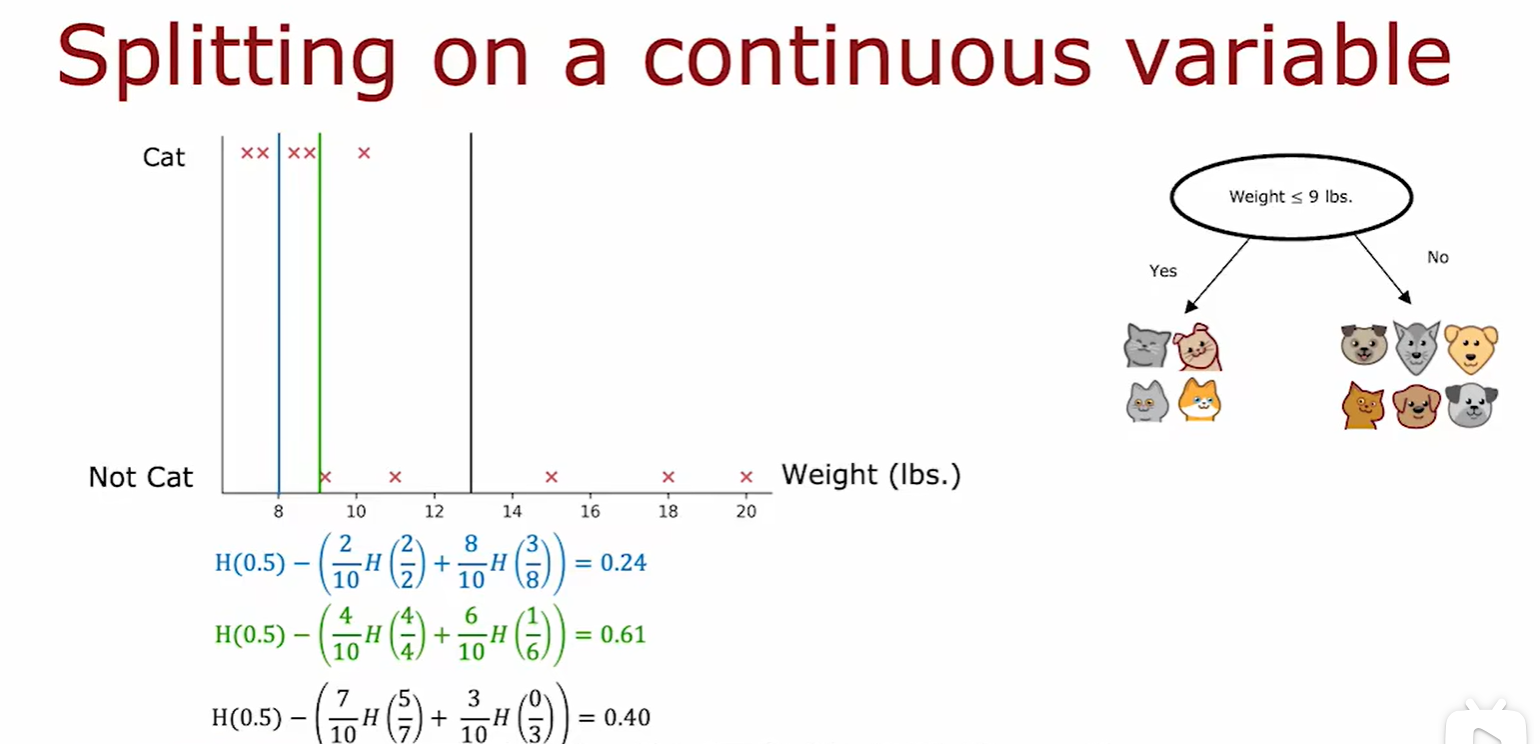
Continuous variable
- 如果某个特征是可以去连续值的,则分类根本是计算权重,选取不同值的权重计算信息增益,选择信息增益最大处的权重作为分类标准;
4.2 Regression Trees
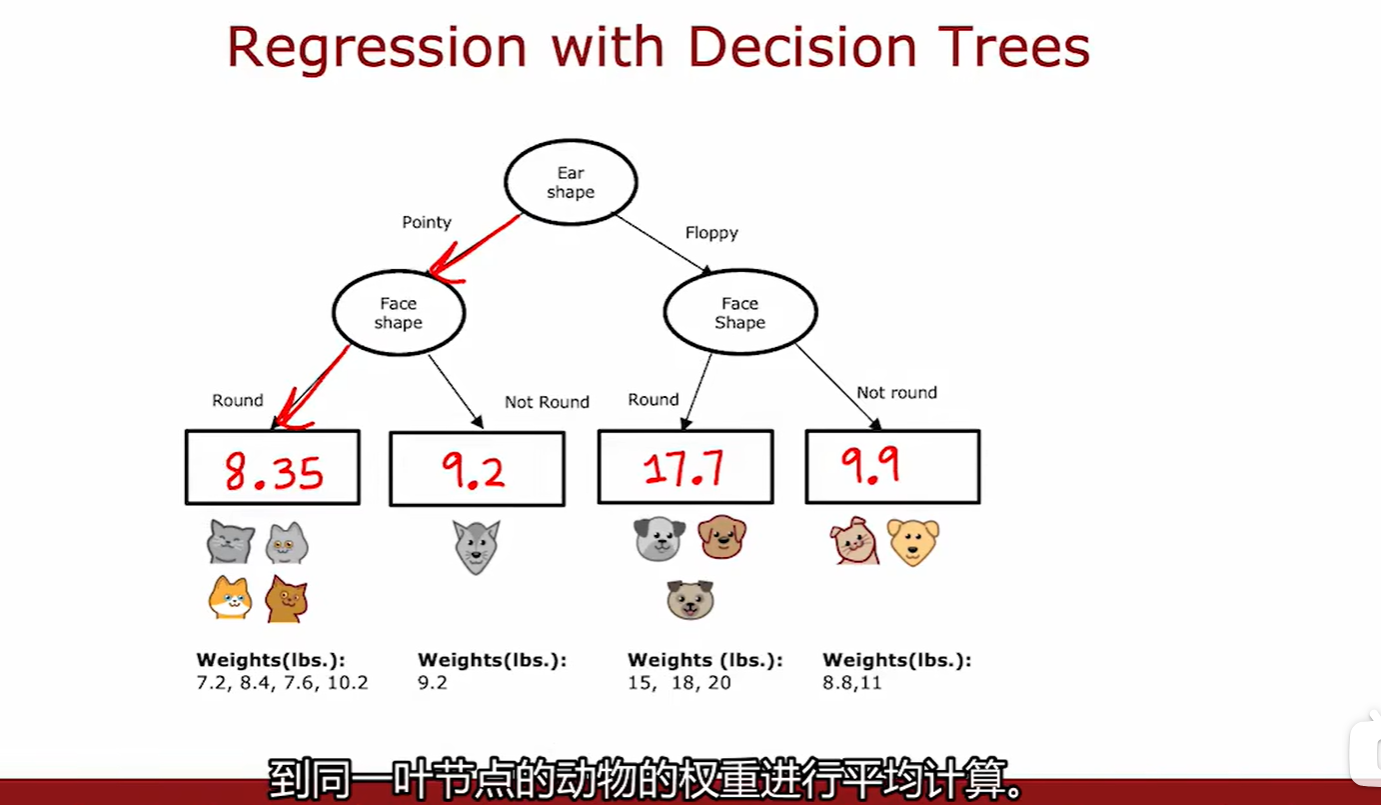
Regression with Decision Trees
Choosing a split
- 这里采用的是计算方差的加权平均数,再计算信息增益,选取增益最大的方式分裂:

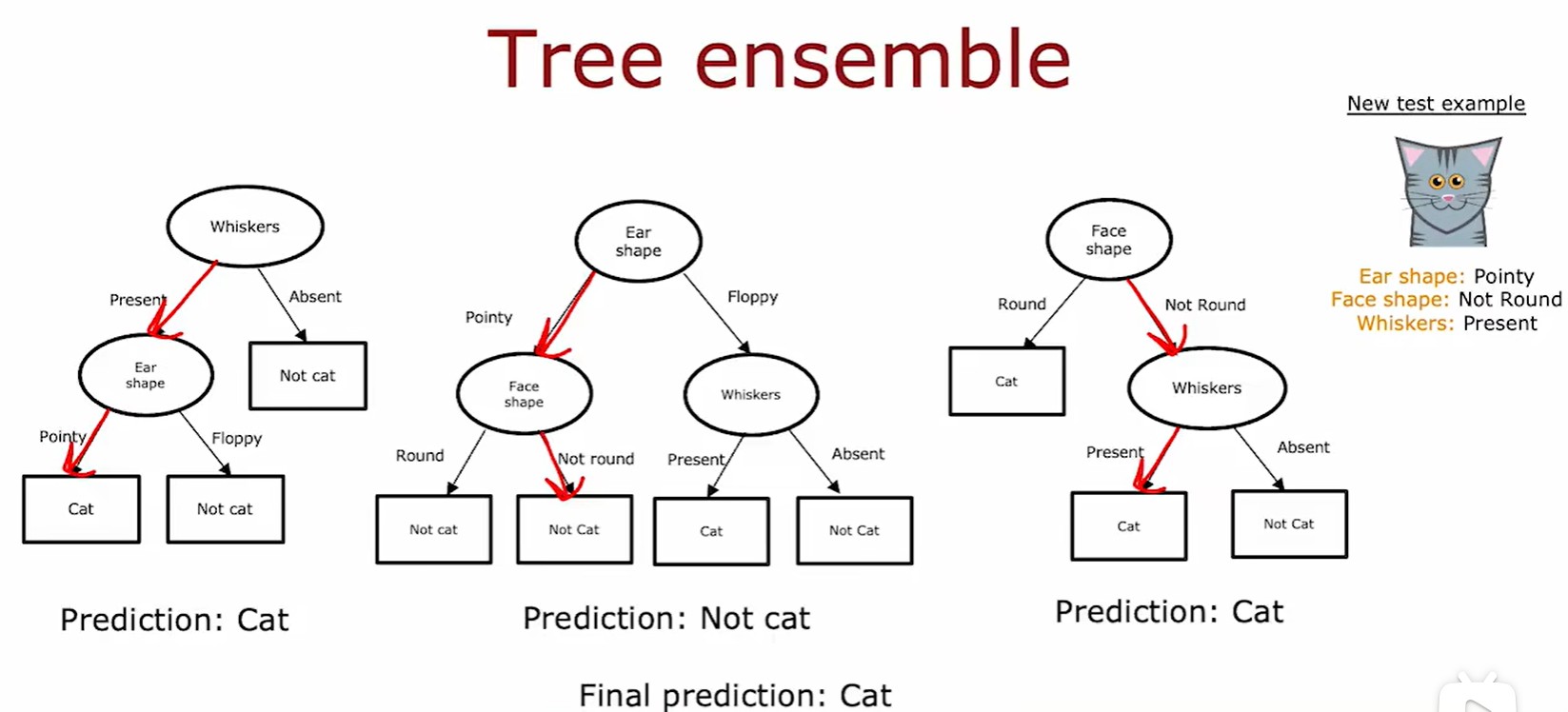
4.3 Tree ensemble
- 使用多个决策树,通过所有决策树最后的投票结果,预测该动物类别:
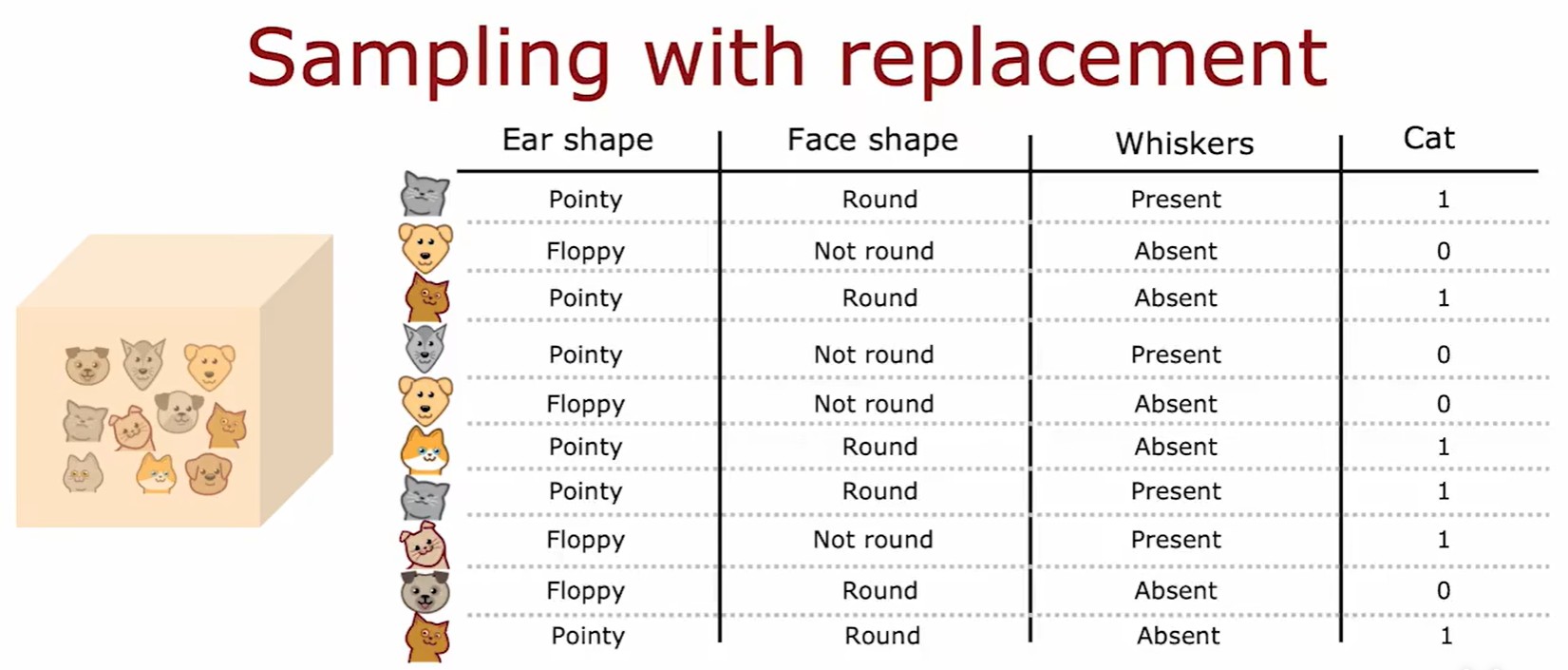
Sampling with replacement
4.4 Random forest algorithm
Bagged decision tree
- 袋装决策树:利用有放回取样方法,搭建大约100个决策树(通常取64/128,太大会过拟合)
- 由于这种方法还是会有在根节点处分类相似的情况出现,因此提出了随机森林算法;
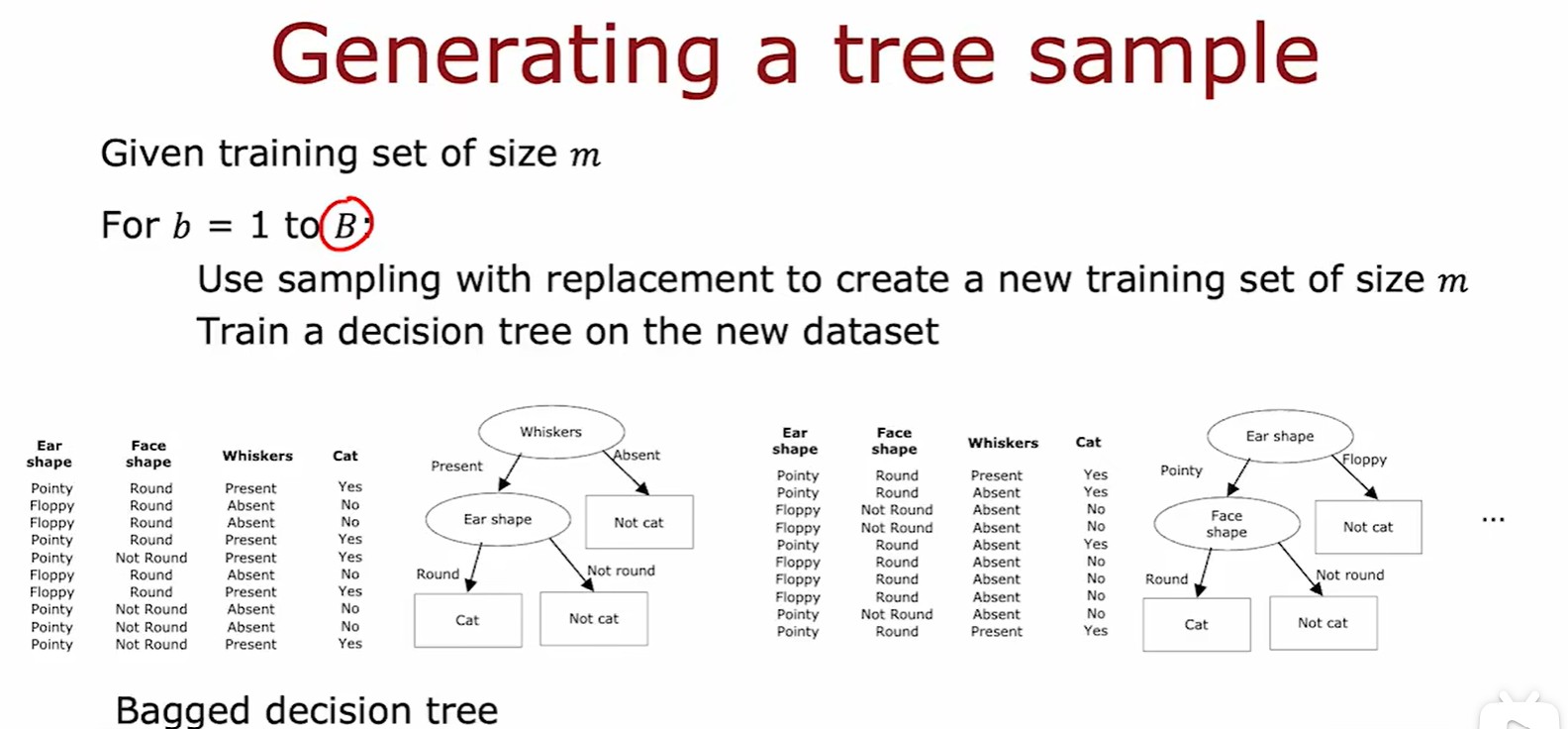
Random forest
- 随机森林算法:在某个结点处,若有 n 个特征可以使用,则随机挑选 k 个特征作为子集,再让结点从中挑选(最常见的是 k =
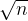 );
);

4.5 XGBoost
Boosted Trees
- 提升树:通过组合多个决策树,逐步修正错误;
- 核心:每次建立新的数据集都会有更高的概率选择那些之前采样的表现不佳的样本;

eXtreme Gradient Boosting
- XGBoost (极端梯度提升),它通过逐步构建一系列的决策树,每棵树都在之前树的残差(误差)上进行训练,从而逐步改进预测结果。每棵树的作用是纠正前一棵树的错误,最后通过加权求和得到最终的预测结果。
- 优势:1.内置了正则化功能防止过拟合;2.不是通过替换进行采样,而是为不同的训练样本分配不同的权重;

4.6 Decision Trees and Neural Networks
- 如何选择决策树还是神经网络:决策树多用于结构化数据且速度快,而神经网络适用各种结构但是速度较慢;
