Flink Stream API - 源码开发需求描述
概述
本文介绍如何基于Flink源码进行二次开发,实现一个动态规则引擎系统。通过自定义算子和算子协调器,实现数据流的动态规则计算和协调管理。以此更好理解前面介绍的源码相关文章
项目需求
核心功能
实现一个动态规则引擎,具备以下特性:
- 数据源产生两类数据:数据本身 和 运算表达式
- 按照运算表达式对数据进行运算并输出结果
- 运算表达式可以动态更新
- 支持多并行度的运算任务
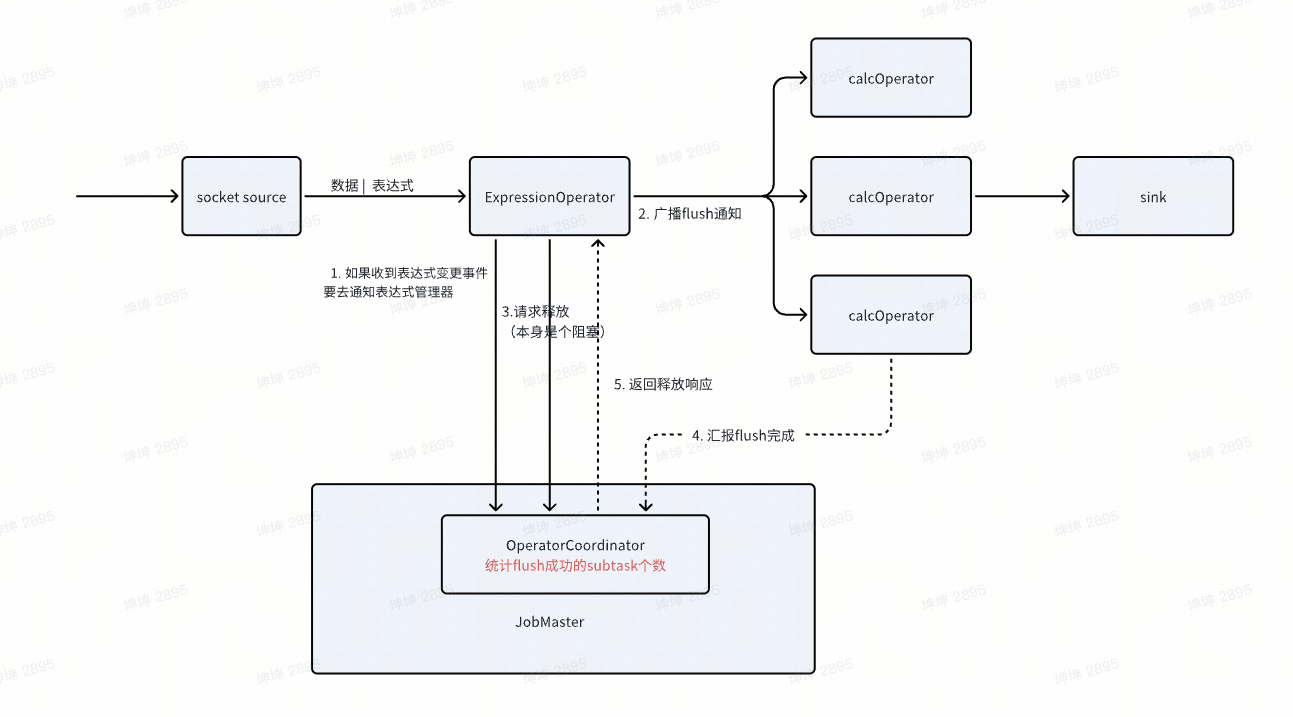
架构设计
具体例子说明
场景:实时温度监控系统
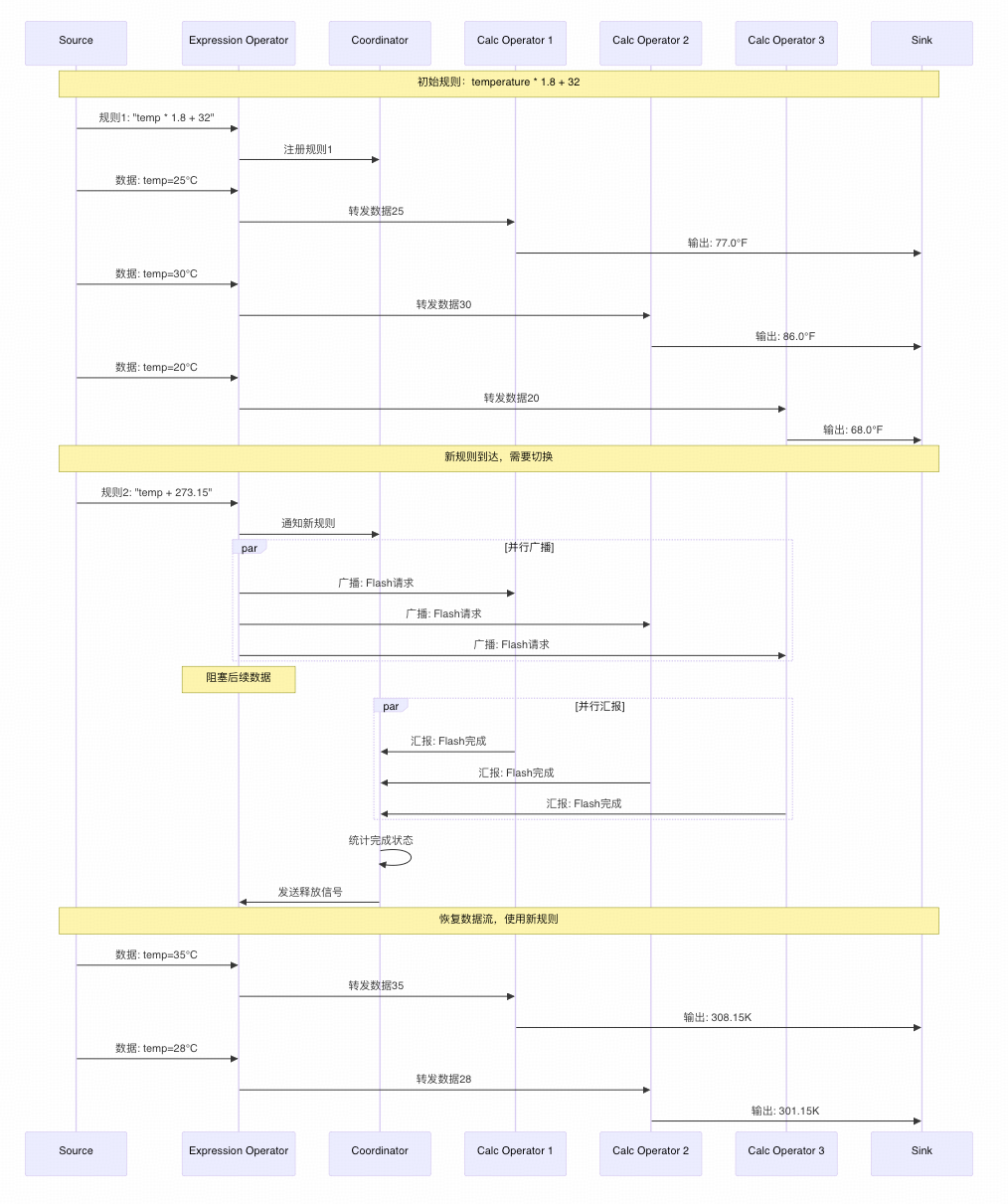
假设我们有一个实时温度监控系统,需要对传感器数据进行动态计算:
数据源输入示例:
时间线:
T1: {"type": "rule", "expression": "temperature * 1.8 + 32"} // 摄氏度转华氏度
T2: {"type": "data", "sensorId": "001", "temperature": 25.0}
T3: {"type": "data", "sensorId": "002", "temperature": 30.0}
T4: {"type": "data", "sensorId": "003", "temperature": 20.0}
T5: {"type": "rule", "expression": "temperature + 273.15"} // 摄氏度转开尔文
T6: {"type": "data", "sensorId": "004", "temperature": 35.0}
T7: {"type": "data", "sensorId": "005", "temperature": 28.0}
期望的处理结果:
T2数据: 25.0 * 1.8 + 32 = 77.0°F (使用第一个规则)
T3数据: 30.0 * 1.8 + 32 = 86.0°F (使用第一个规则)
T4数据: 20.0 * 1.8 + 32 = 68.0°F (使用第一个规则)
--- 规则切换点 ---
T6数据: 35.0 + 273.15 = 308.15K (使用第二个规则)
T7数据: 28.0 + 273.15 = 301.15K (使用第二个规则)
关键挑战:
- 数据一致性:T4的数据必须用第一个规则计算完成后,T6的数据才能开始用第二个规则计算
- 并行处理:如果有多个Calc Operator并行处理,需要确保它们都完成了旧规则的计算
- 无数据丢失:规则切换过程中不能丢失任何数据
处理流程详解:
当T5时刻新规则到达时:
1. Expression Operator收到新规则↓
2. 通知Coordinator更新规则: "temperature + 273.15"↓
3. 向所有Calc Operator广播: "请完成当前批次计算"↓
4. 阻塞数据流: T6、T7数据暂时不向下游发送↓
5. 等待所有Calc Operator汇报: "我已完成T4及之前的数据计算"↓
6. Coordinator确认所有Task完成后,通知Expression Operator: "可以继续"↓
7. 恢复数据流: T6、T7数据开始使用新规则处理
多并行度场景:
假设有3个Calc Operator并行处理:Calc-1: 正在处理T2数据 (25.0°C)
Calc-2: 正在处理T3数据 (30.0°C)
Calc-3: 正在处理T4数据 (20.0°C)当T5新规则到达时:
- 所有Calc都必须完成当前计算并汇报
- 只有收到3个完成汇报后,才能开始处理T6、T7数据
为什么需要Operator Coordinator?
问题:Flink的Task之间只能传递数据,无法传递控制信号
解决:通过Job Master中的Coordinator实现:
- Expression Operator → Coordinator: "新规则来了"
- Coordinator → 所有Calc Operator: "完成当前批次"
- 所有Calc Operator → Coordinator: "我完成了"
- Coordinator → Expression Operator: "可以继续了"
时序图示例: