SpatialLLM,SpatialReasoner,SpatialLM论文解读
SpatialVLM->SpatialRGPT->SpatialReasoner,SpatialMLLM,SpatialLM,SpatialLLM
SpatialLM聚焦室内场景理解,输入为点云信息。SpatialReasoner和SpatialLLM都可以理解为针对3D空间下存在2D图像捷径的问题,在数据上都引入了更多反常规的图像信息,避免产生捷径问题,训练上采用两种不同的方式处理,一个是通过准确的3D数据+RL微调使得LLM理解空间信息,当然他也可以获得更多的物体间,物体本身的空间信息。一个是只通过RGB信息的问答对(CoT包裹),通过完整的三步走多模态模型训练,来实现物体间空间关系。
目录
一、SpatialLM
1、概述
2、方法
3、训练过程
4、实验
二、SpatialReasoner
1、概述
2、方法
3、训练过程
4、实验
三、SpatialLLM
1、概述
2、方法
3、训练过程
4、实验
一、SpatialLM
1、概述
动机:传统3D室内场景理解方法依赖任务特定的网络设计,难以泛化。现有LLMs缺乏3D点云数据的能力,这由于高质量的3D数据集规模小,且点云的不规则结构使得点云特征对齐LLMs空间比较困难。
SpatialLM中主要提出了利用结构化文本解决室内结构化场景表示,同时构建大规模合成数据集用于训练。
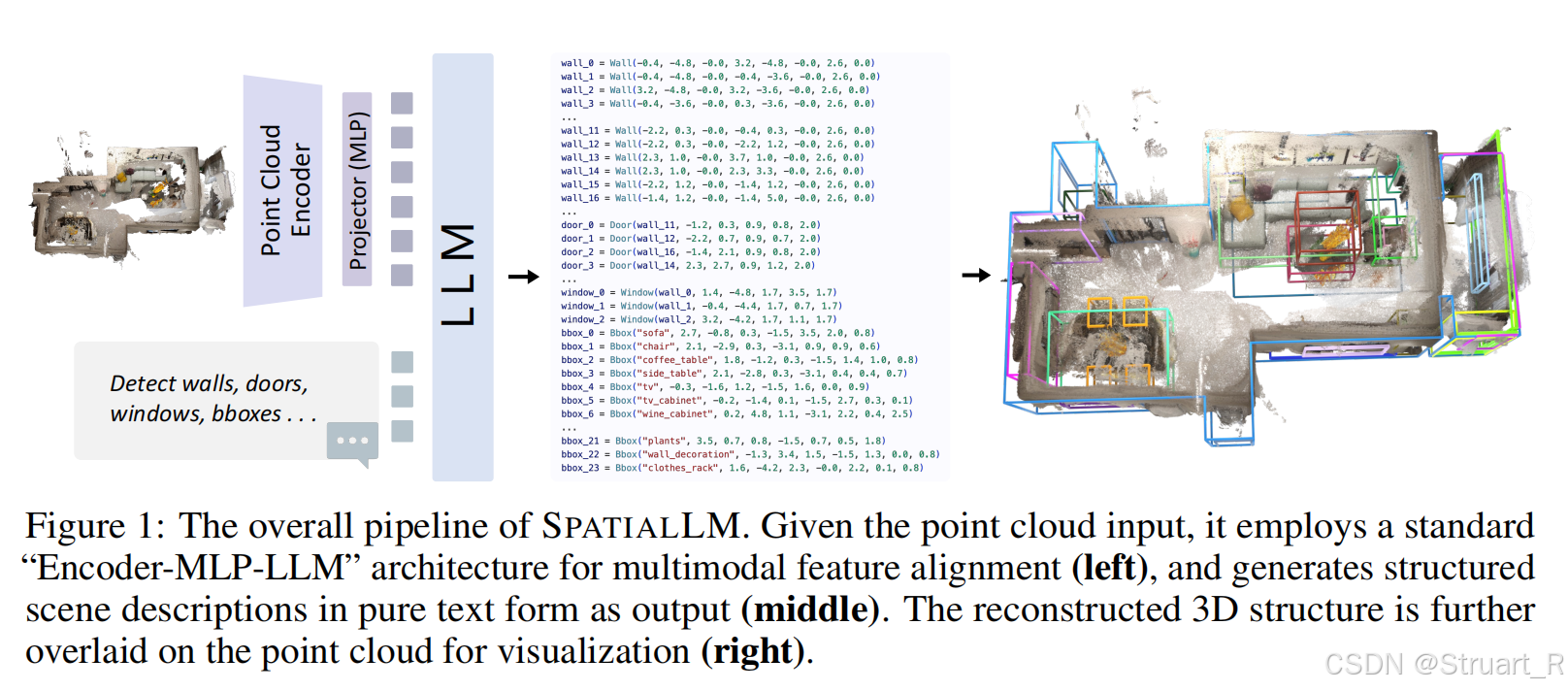
2、方法
SpatialLM数据集
由于以往的数据集要么是RGB-D扫描后手动标注的三维信息,要么合成数据集的质量上有些差,比如只有物品标注,对墙体,布局没有标注。
SpatialLM数据集则使用室内设计行业在线平台的作品,包含12328个室内场景(5w个房间)。
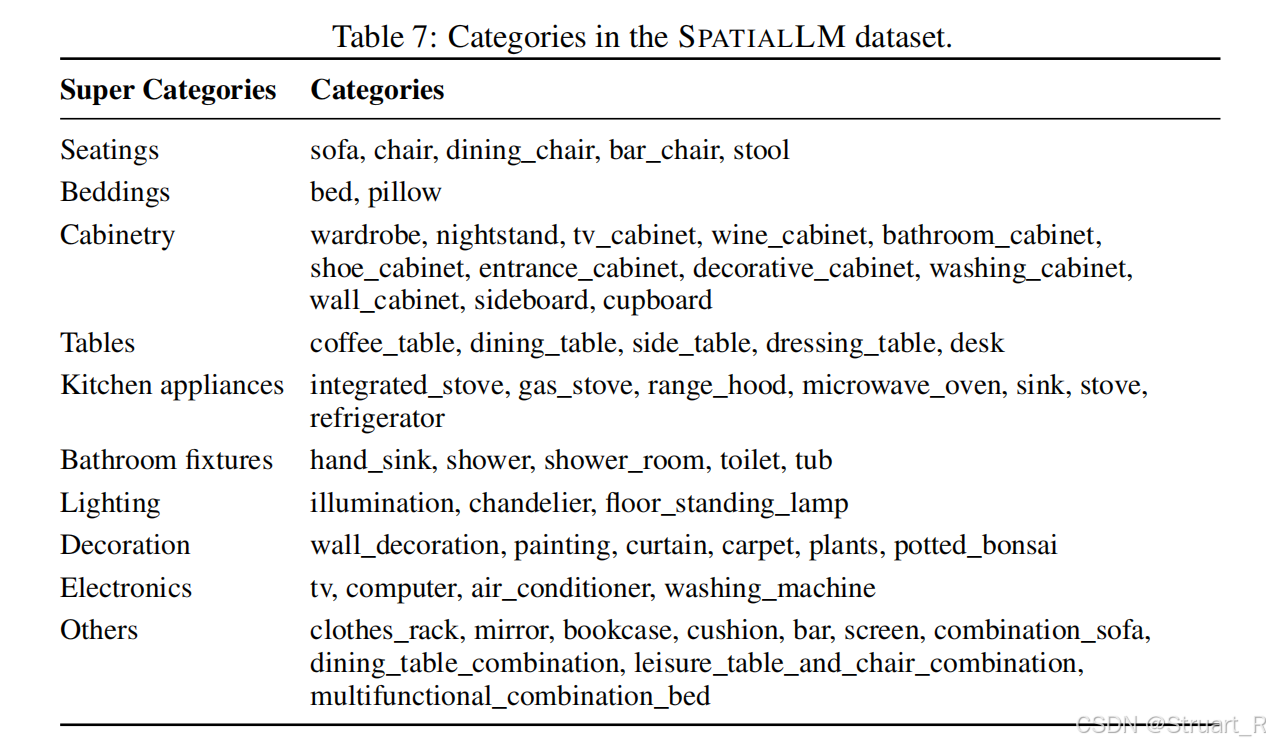
标注上,精确标注了墙、门、窗户的结构元素:

对于每一个3D物体,覆盖了59个常见类别(分为9个超类),并剔除边长小于15cm的小物体,保留41w个物体实例。图片渲染过程利用工业级渲染引擎生成照片级RGBD图像,每隔0.5m渲染一张图片。
模型架构
采用Encoder-MLP-LLM的架构,输入房间场景点云信息(XYZ坐标+RGB颜色),经过编码器Sonata(Point Transformer V3的变体),得到K个特征嵌入
,之后通过2层MLP对齐点云特征与文本嵌入空间。LLM模型采用Qwen2.5-0.5B,输出结构化的python脚本,用于描述布局和物体包围框。
在编码器选择中,作者尝试了SceneLLM中体素网格的方式(体素网格+DINOv2)但是下采样会丢失过多细节信息。3DCNN的方法(稀疏卷积3DCNN+DINOV2)效果虽然有提升,但是不如纯点云编码器Sonata。
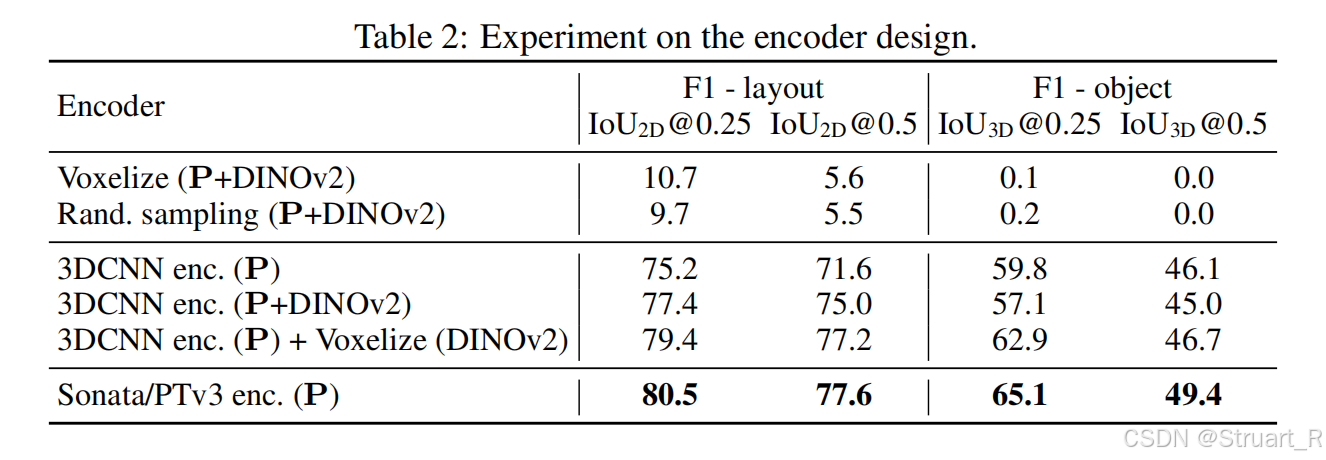
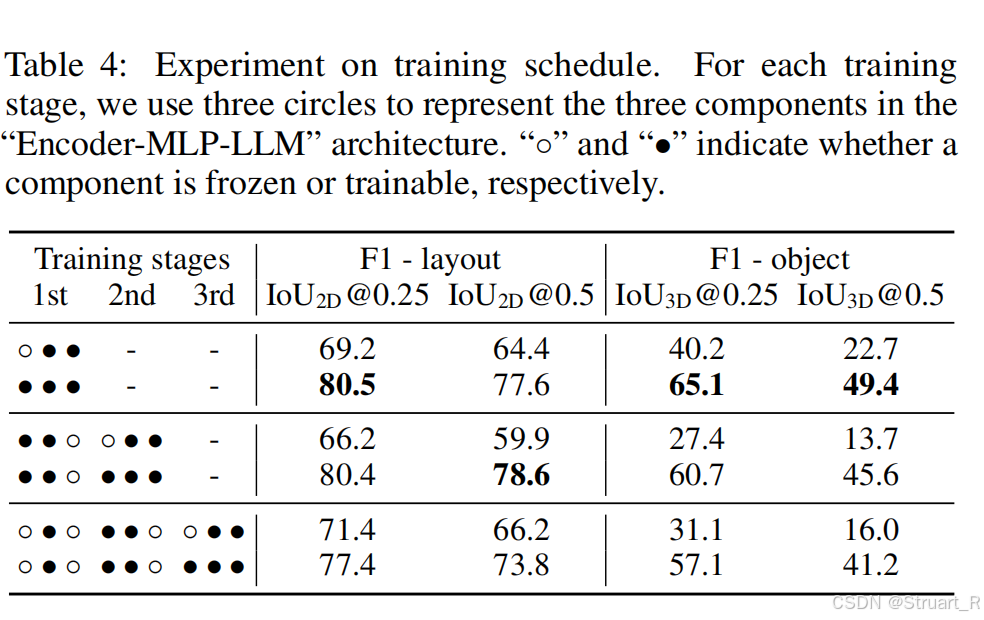
3、训练过程
训练过程中通过测试得到全模型微调对于布局和物体的准确定位更优,这同时也反映了多阶段微调会降低精度。但是也可以理解,一般多阶段微调适用于多任务的情况。
4、实验
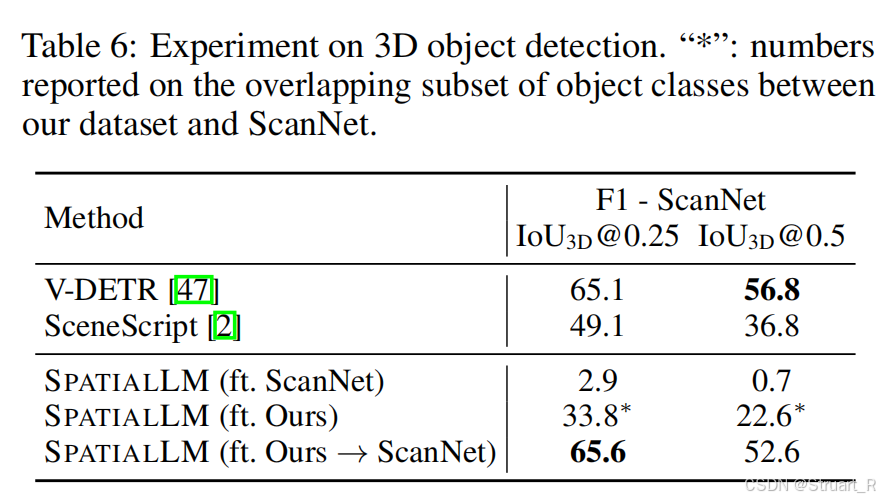
主要利用SpatialLM模型执行三个任务,布局估计(预测墙,门,窗),3D物体检测(检测带语义类别的物体包围框),零样本视频检测(处理单目视频重建的点云)
在推理阶段,针对与不同的任务先依赖SpatialLM数据集预训练过的模型,再通过相关下游任务的测试集进行二次微调。
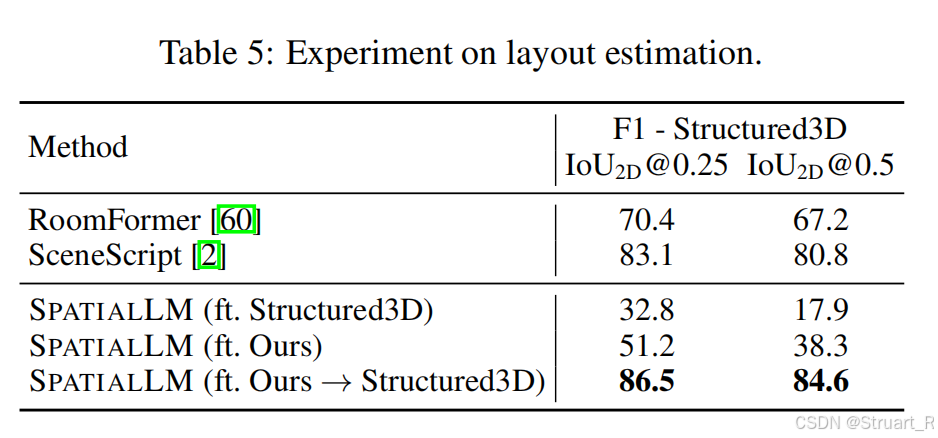
布局估计任务,则依赖Structed3D数据集,能看到二次微调后效果大大改进,但初始的预训练模型效果平平。RoomFormer独立检测物体导致门窗检测不到(其实也是数据集没有标注),SceneScript易遗漏小结构元素。
物体检测对常见物体检测更加完整。

零样本视频检测,输入107个虚拟场景视频,MASt3R-SLAM重建点云(含噪声、遮挡),零样本预测布局和物体的任务。

二、SpatialReasoner
1、概述
这个论文是对比SpatialRGPT论文的,当前多模态大模型在3D空间推理任务中存在显著不足,比如以前的空间关系只能描述物体在右前方,不能计算出精确的数值。另外对于新型的空间推理问题(比如多物体相对位置)表现不佳,在推理过程中缺乏可解释性。
SpatialReasoner则显式建立三维表征并应用于感知-计算-推理三阶段推理过程,通过3D LVLM实现3D thinking 和3D computation。另外在数据集上扩展以往的数据3D标注信息,在感知信息,空间问答,链式推理上显式给出3D计算过程,通过数据训练LVLM的3D显式推理能力。在训练过程中同样引入GRPO算法,提升推理泛化性。
下图对比以往多种大模型在空间推理问题上的性能,其中在给出图片(人物与水瓶的关系)和问题的情况下,Qwen2.5,ChatGPT o3,只能根据图像本身进行分析,并不懂从人物视角怎么看这个空间关系。Gemini2.0 虽然有3D空间的思考,但是缺乏显式的3D信息,他的答案也有所影响。SpatialReasoner则有明显的物体坐标信息,可以通过显式坐标信息,灵活的切换到不同的物体视角下来计算空间关系。

2、方法
3D Pseudo-annontations
对于显式三维表征的数据集构建,不依赖点云输入,而是采用单张RGB图像的3D伪标注生成,当然这也不一定准确,但是他容易获得。
数据来源:OpenImages数据集,是一个大规模真实世界图像数据集
标注信息:标注物体类别,3D位置,3D姿态。
标注过程:这个标注过程竟然在SpatialLM和SpatialLLM上进行改进的,但是添加了数据过滤和人工验证。这里也相当于给出了这两个模型的标注方法。首先利用视觉基础模型SAM2,分割图像中的物体实例;调用深度估计模型Depthanything V2,预测像素级深度图;结合物体掩码与深度图,通过相机内参反投影计算物体中心3D坐标;最后利用物体姿态估计模型 ImageNet3D预测物体朝向向量;所有3D坐标定义在校准相机空间,其Z轴对齐世界高度,XY平面平行于地平面。
标注过程相对关系计算:计算物体间相对向量(坐标作差),向量夹角判断方位(夹角<90°则为右侧)。
数据过滤:过滤掉遮挡严重、物体密集的图像,排除难分割或姿态估计的类别(如透明物体),丢弃空间关系模糊的样本(如两物体轴线重合)。
人工验证:随机抽取1.2K样本,人工验证3D标注正确性,并且在训练过程中专用于RL训练。
基于这个3D伪标注原理,构建了三类训练数据。
- Basic3D-QA:基础 3D 属性问答(例:“瓶子的高度是多少?” 回答:直接数值(如“1.2 米”))
- SR-QA:空间关系判断(例:“桌子在椅子的左侧吗?” 回答:二分类结果(“是”/“否”)+ 显式向量计算)
- SR-CoT:复杂空间推理(例:“从人的视角看,瓶子在左侧还是右侧?” 分步生成显式 3D 计算链)

SpatialReasoner
SpatialReasoner空间推理系统包括两个重要设计,显式3D表征作为接口支持多阶段的推理过程,通过多阶段训练空间推理能力。
首先对于以往的3D LLM(SpatialRGPT,SpatialLLM)或者LLM(Gemini2.0)来说都在空间推理能力上缺乏显式的三维表征信息,只是依赖自然语言来描述三维空间,这一点可以看上面Gemin2.0对话的例子,基本上都是在谁的角度下偏左,偏右这种方式描述,但是复杂空间下常常并不准确。
所以这里通过数据驱动,将LVLMs与显式三维表征结合,LVLM内部融合了3D感知,3D计算,3D推理,最终计算结果生成最终答案,通过CoT实现。
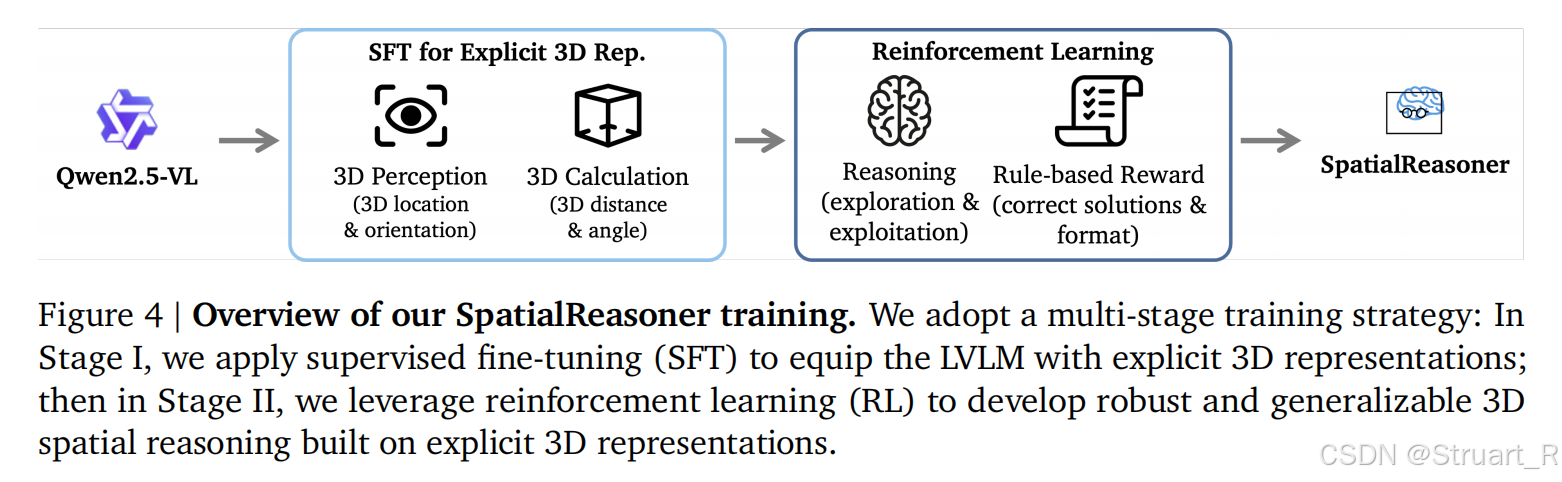
3、训练过程
首先利用监督模型SFT训练准确的显式向量,之后利用RL来优化结果正确性和完整的计算步骤。
RL奖励,一方面包括利用MMBench指标的奖励结果正确性,完全正确才输出1。另一方面就是格式奖励,也就是强制过程步骤。
4、实验
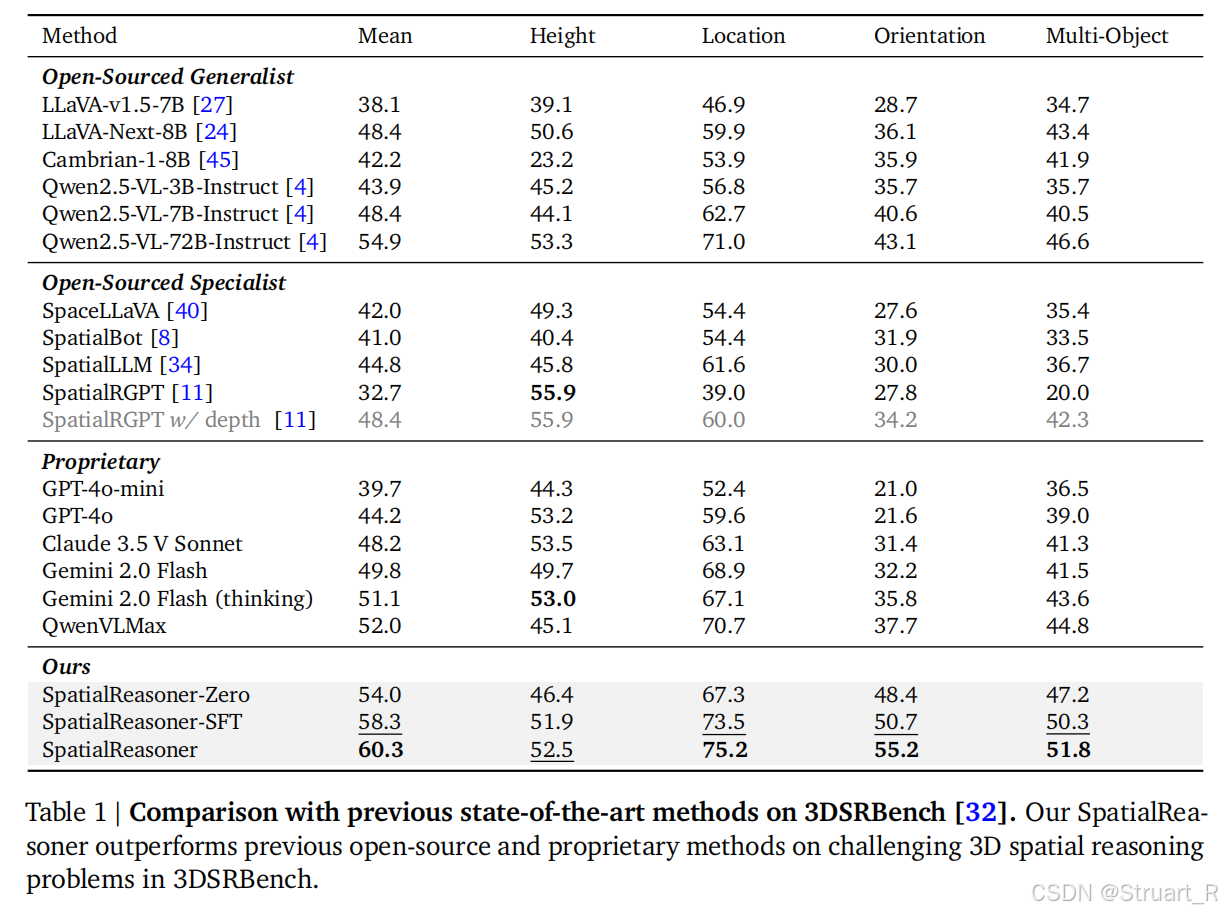
3DSRBench
基于3D空间推理能力设计的评测集,涵盖高度、位置、方向、多物体关系等 5 类空间问题, 对于答案围绕伪标签生成几何关系,目的是避免2D视觉特征与3D答案的捷径关联,让他有强制3D空间关联,但是这Bench也与数据集强关联。
反捷径设计,故意构造2D与3D空间矛盾的样本。比如下图右侧,红色的人距离狗狗更近(但是2D图像上蓝色的人距离狗狗更近),这种方法阻碍模型依赖2D距离来猜答案。

3DSRBench下的测试,多样本下准确率提升很显著。
CV-Bench-3D验证基础3D感知,GQA验证推理泛化性。在SpatialReasoner的训练过程中,CV-Bench-3D的distance任务猛猛下降,说明原来的这个bench就是存在问题的,依赖2D捷径。
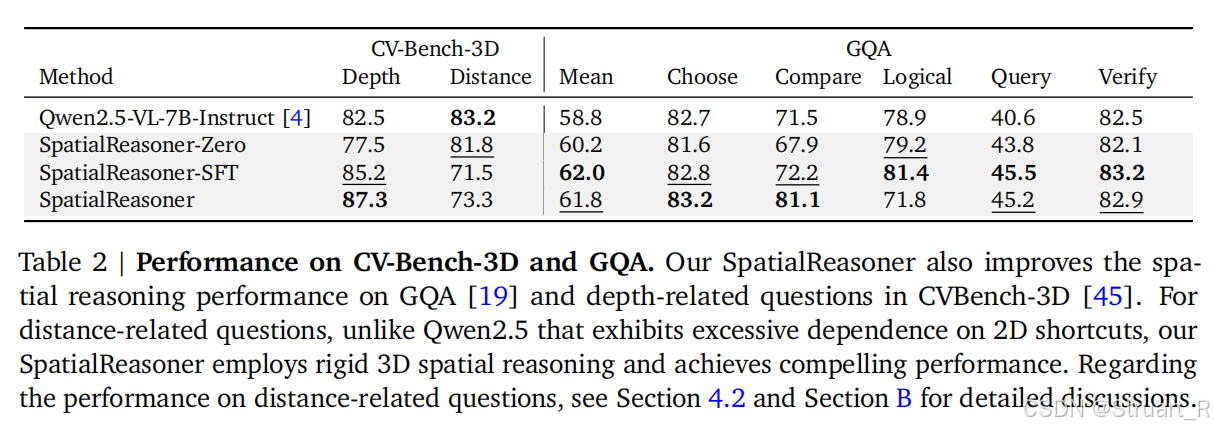
3D表征的接口确实在训练过程中提升了很多,显式CoT推理强化,另外在奖励函数中删除了以往的KL散度正则化会损害性能,这倒是很反常规。我的理解是,以往的Qwen2.5没有考虑过3D的问题,反而KL的引入会对这种显式的3D计算变得模糊,KL的引入会鼓励贴近以往的SFT分布,这样最后精确地空间推理和保守的结构化约束产生了冲突。
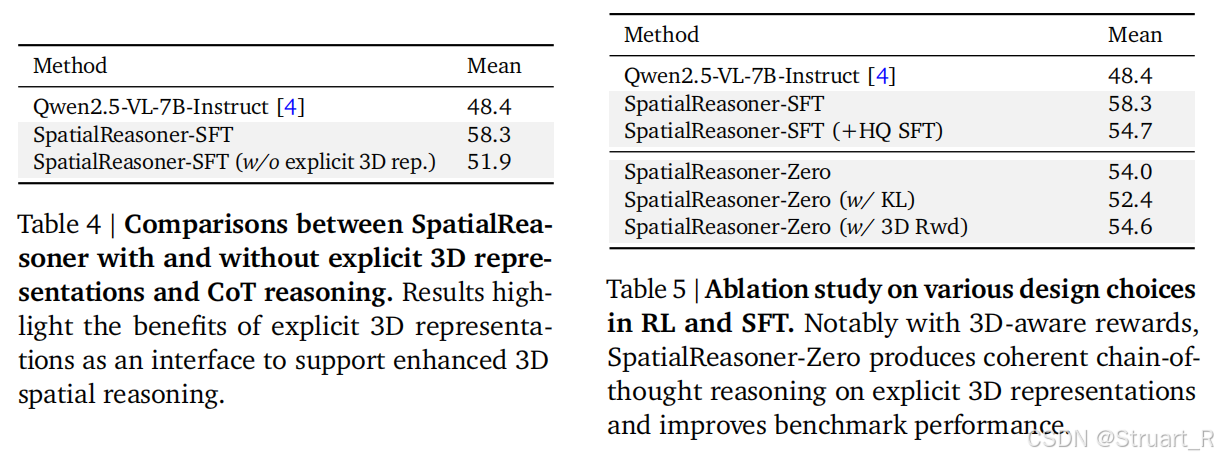
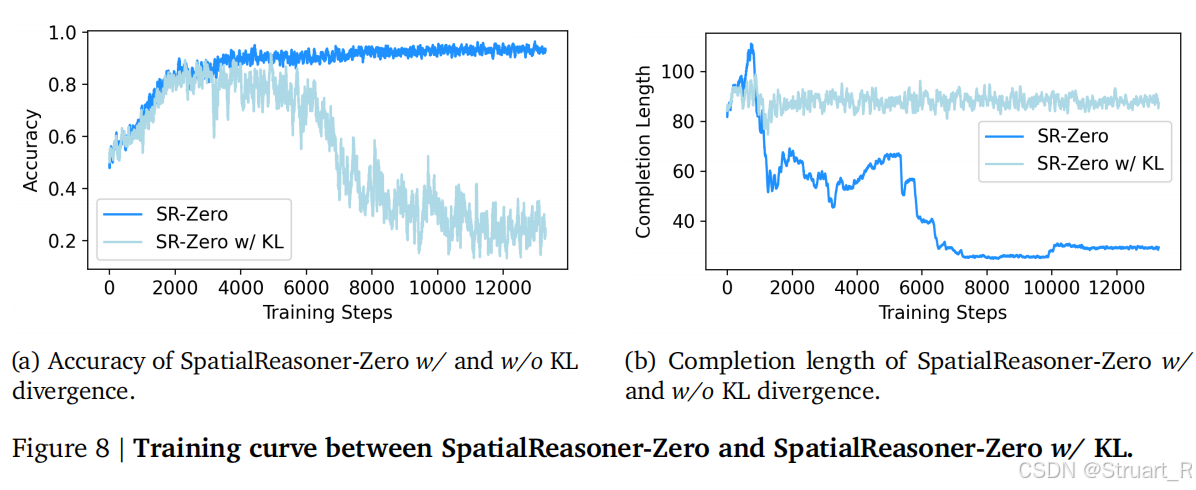
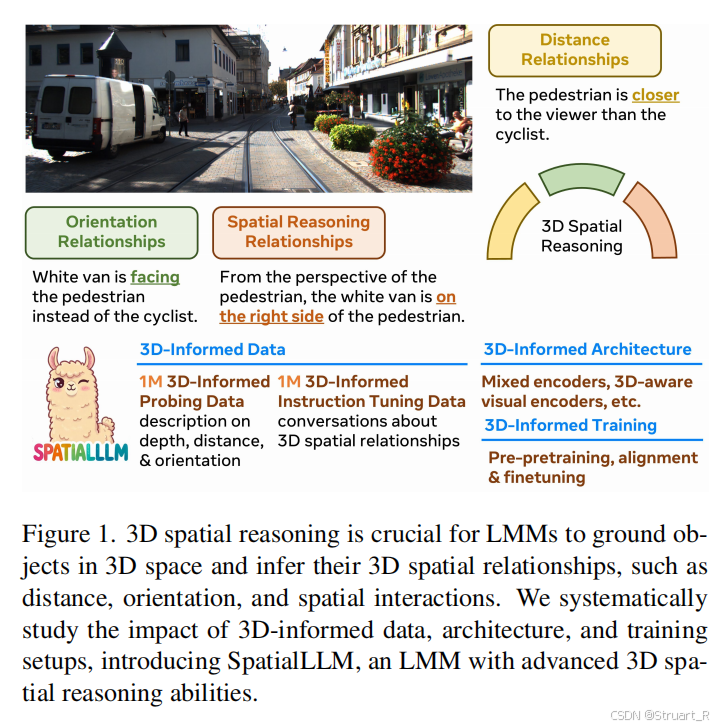
三、SpatialLLM
1、概述
这个模型与SpatialReasoner相似,同样是针对以往的大模型不理解物体间3D空间关系。同样理解到缺乏精确的数据信息(3D位置,朝向标注),同样的设计发现以往模型过度依赖2D图像特征,忽视了3D几何信息内在表示。
但是呢,他用了以往Visual Encoder+connector+LLM的传统架构来解决这个问题。然后同样构建了相关空间关系的数据集3D-Informed Data(3DI),以及相关的评测基准SpatialVQA(对比的是GQA缺乏3D朝向问题的空白)。
2、方法
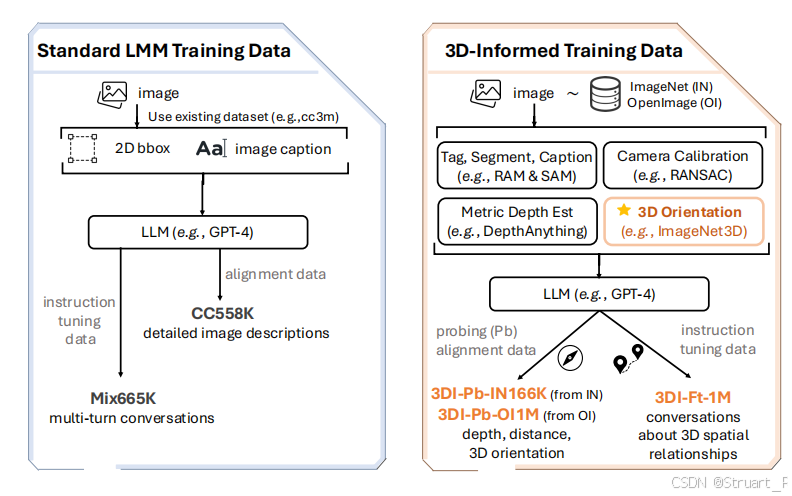
数据集
数据集分为3DI-Pb和3DI-Ft,前者用于简单的空间关系问答(单一物体级位置,深度,朝向),后者用于复杂空间关系问答(物体间)
3DI-Pb包含3DI-Pb-O1M和3DI-Pb-IN166K两个数据,前者依赖OpenImages进行伪标注(伪标注与SpatialReasoner相同),ImageNet3D则复用ImageNet3D人工验证的位姿,直接利用原数据进行转换。
3DI-Ft来自The open images dataset v4数据集,然后预定义12类问题模板,这个问题与SpatialReasoner的很像。

对于数据集验证上,对于深度估计,仅保留DepthAnything置信度 > 0.8的预测。朝向估计,位姿估计器分类置信度 > 0.9,对对称物体(例:球体)屏蔽朝向问题。
并且利用人工验证,抽取10%验证逻辑性,以及排除遮挡物体和位姿误差<5°的物体。
并且对于朝向问题,保证同向和异向的样本均衡。(所以这个论文主要搞物体朝向的)
数据相比于标准的LMM数据来说,引入了多源异构数据,并且引入更多的工具来获得准确的空间信息,最后利用LLM来生成带有CoT推理的QA。
SpatialLLM架构
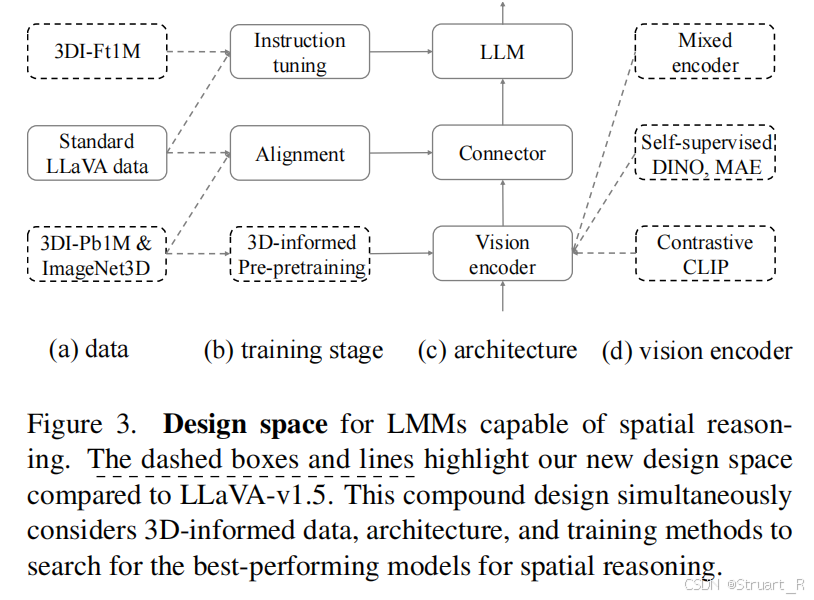
Visual Encoder+MLP+LLM架构。
Visual Encoder:采用混合架构,CLIP-ViT+DINOV2-ViT,其中CLIP-ViT用于语义对齐,DINO用于捕获几何特征,通过双路特征拼接作为混合编码
MLP:同样的两层MLP,建立跨模态对齐。
LLM:将以往的Vicuna-7B替换为Llama-7B
但是这个模型没有用强化学习
3、训练过程
三阶段训练经典。
(1)先用3DI-Pb数据,LoRA 微调编码器最后一层,冻结其他参数(避免破坏基础表征)。
(2)多模态特征对齐:训练connector冻结其他模块,CC558K图文对,混合3DI-Pb数据,强制视觉-文本空间几何对齐。对比 SpatialVLM 仅用深度数据。
(3)指令微调:全参数微调(包括解冻编码器),标准指令数据Mix665K,3D对话数据3DI-Ft-1M,引入物体间朝向关系样本。
4、实验
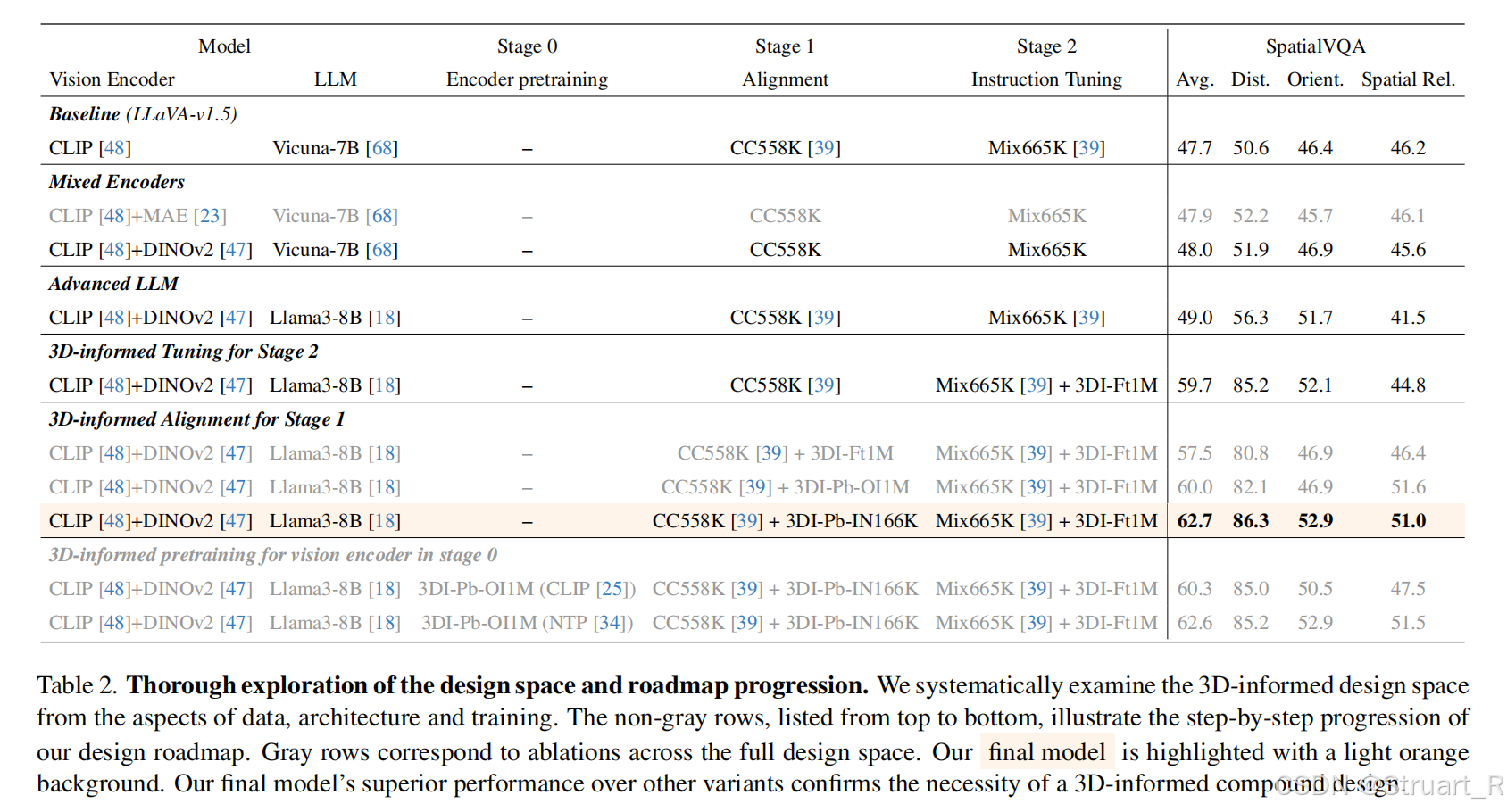
这个模型完全对比的LLaVA-1.5,当找不到信息可以找LLaVA。
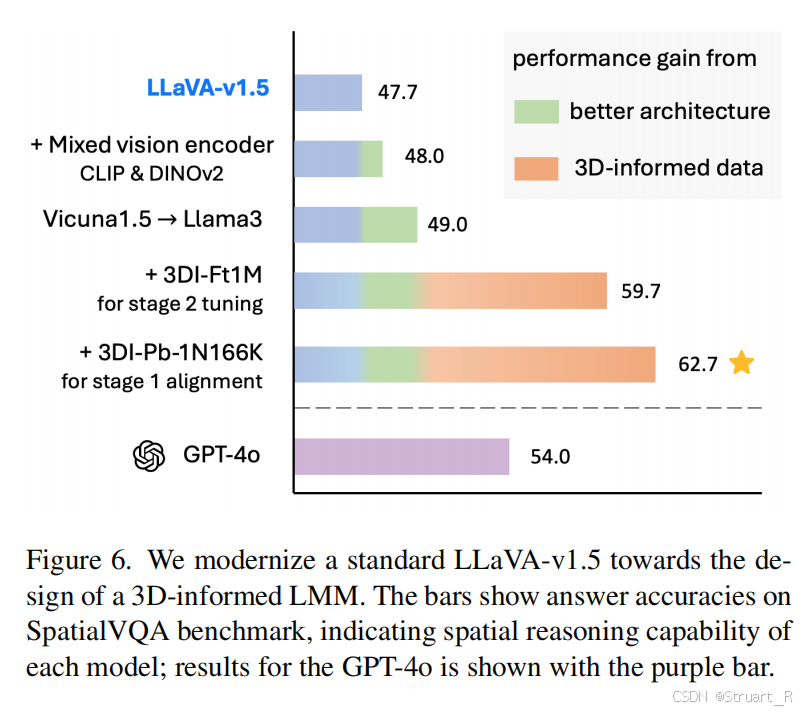
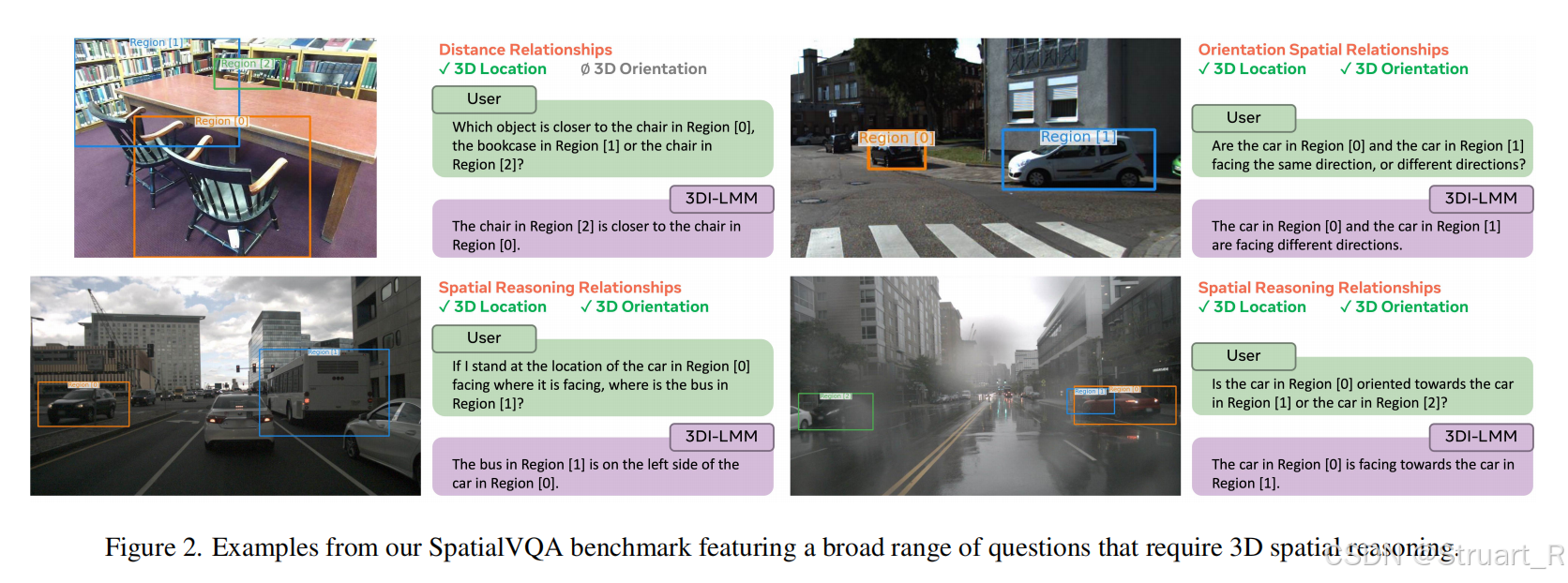
SpatialVQA benchmark
相较于传统GQA基准聚焦于图像平面关系,无法评估3D空间理解。SpatialVQA首次引入朝向关系评估(相较于SpatialVLM,ScanQA是通过扫描的深度图,这个不能算)。
数据来源:Omni3D,12000+真实场景图像,包括室内(办公室、家庭),户外(街道、自然)
标注基础:原有的精确3D边界框,转换为answer数据,并人工验证位姿。其中这里也包括了组合空间关系(“从人的视角看,椅子在左侧还是右侧?”)
评估指标:acc(严格匹配答案),细粒度信息(包括距离,朝向,组合,场景信息)
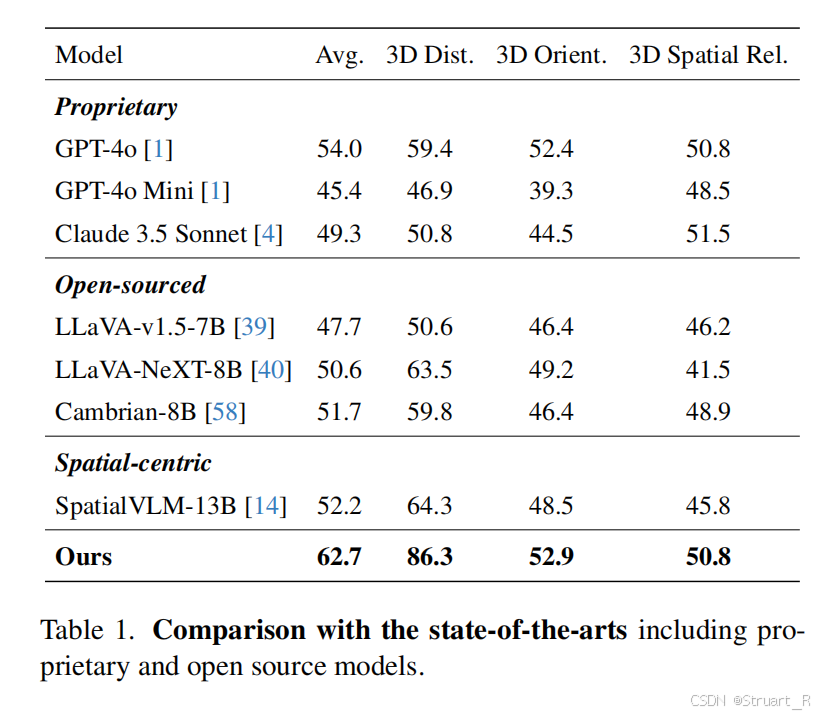
相较于当前开源,闭源模型来说,在三维距离,三维方向,三维空间关系的所有推理上均取得SOTA。但是没有对比近期的SpatialRGPT,SpatialLLM这一些LVLMs。
参考论文:[2506.07491] SpatialLM: Training Large Language Models for Structured Indoor Modeling
[2504.20024] SpatialReasoner: Towards Explicit and Generalizable 3D Spatial Reasoning
[2505.00788] SpatialLLM: A Compound 3D-Informed Design towards Spatially-Intelligent Large Multimodal Models