LLM入门学习
LLM,Large Language Model,大语言模型
国外模型
GPT 系列:由 OpenAI 开发,当前常用版本是 GPT-3.5-turbo 和 GPT-4,采用 Transformer 架构,是带有 API 的通用 LLM,被许多企业使用,如 Microsoft、Duolingo 等
Gemini:谷歌的多模态基础模型,能同时理解和处理文本、图像、视频等多种类型的数据输入,目标是实现跨模态的理解和生成能力
PaLM:谷歌的大模型,聚焦单一自然语言处理,与 Gemini 根据不同的使用场景和需求来部署和整合
Llama 2:Meta 和 Instagram 的开源 LLM,可从 Github 下载源代码,免费用于研究和商业用途,许多 LLM 以 Llama 2 为基础进行开发
Falcon 180B:一个大规模的语言模型,具有 1800 亿参数,专为高性能自然语言处理任务设计,在各种 AI 基准测试中表现良好
Claude 2:是 GPT 最重要的竞争对手之一,面向诉求安全的企业客户,仅作为 API 提供,可根据数据进行进一步训练和微调,由美国科技公司 Anthropic 开发的大语言模型
国内模型
百度文心大模型:包含 NLP、CV 和跨模态大模型。文心 ERNIE 系列模型在自然语言处理领域具有强大的小样本学习能力和基本推理能力;文心 VIMER-CAE 在图像分割方面能力突出;文心 ERNIE-ViLG 2.0 能生成语义相关、质量更高的图片。
腾讯混元大模型:腾讯全链路自研的通用大语言模型,具备强大的中文创作能力、复杂语境下的逻辑推理能力以及可靠的任务执行能力。支持多种视频生成能力,还在文 / 图生 3D 方面有布局。
阿里云通义千问:拥有千亿参数,可用于智能问答、知识检索、文案创作等场景,具备多轮对话、文案创作、逻辑推理、多模态理解、多语言支持等核心能力。
科大讯飞星火大模型:支持对话、写作、编程等功能,提供语音交互方式,具备文本生成、语言理解、知识问答、逻辑推理、数学能力、代码能力和多模态能力等核心能力。
字节跳动豆包大模型:是字节跳动开发的大规模预训练语言模型,可能集成了自然语言处理、计算机视觉和语音识别等多种 AI 技术,在多模态学习和应用、自然语言理解和生成、个性化内容推荐等方面有优势。
智谱华章智谱清言:专注于语言理解和生成,能够提供高质量的文本内容,在文本生成和语言理解方面表现出色。
华为云盘古大模型:在多模态数据处理方面表现出色,能够处理图像、文本等多种数据类型,适合智能监控、内容审核等场景。
百川智能百小应:以其快速响应和高准确性在智能客服领域受到好评,适合需要快速准确响应的客服场景。
月之暗面 Kimi:是一款对话式 AI 产品,支持 200 万字的无损上下文输入,能够处理复杂的对话和文档处理,在短时间内进步显著。
360 安全大模型:专注于网络安全领域,提供安全防护和威胁检测等功能,在网络安全领域具有专业的防护和检测能力。
紫东太初:由中科院自动化研究所开发,是跨模态通用 AI 模型。
商汤日日新:商汤科技推出的模型,在自然语言处理和内容生成方面有一定能力。
跨模态含义
Modality
məʊˈdæləti
moʊˈdæləti
形式,形态;程序;物理疗法
Modal
ˈməʊdl
ˈmoʊdl
模式的;情态的;形式的
跨模态(Cross-Modal)
不同类型的信息(如文本、图像、音频、视频、语音、传感器数据等)之间的交互、融合、转换或理解过程
核心是打破单一信息模态的局限,让模型或系统能够处理、关联多种不同形式的信息,从而更全面地理解世界或完成复杂任务。
什么是 “模态”?
模态(Modality) 指信息的存在或表现形式,常见的模态包括:
文本模态:文字、句子、文档、代码等;
视觉模态:图像、视频帧、图表、表情包等;
听觉模态:语音、音乐、环境声音、音频信号等;
其他模态:传感器数据(如温度、湿度)、触觉信号、手势动作等。
每种模态有其独特的特征,例如文本依赖语义和语法,图像依赖像素和视觉特征,音频依赖波形和频谱特征。
跨模态技术的核心
解决不同模态信息的关联与转换
具体目标包括:
理解关联:找到不同模态间的语义对应关系(例如 “文本描述” 与 “图像内容” 的匹配);
融合互补:结合多种模态的信息,提升任务效果(例如用 “图像 + 文本” 共同分析内容);
跨模态转换:将一种模态的信息转换为另一种模态(例如 “文本生成图像”“语音转文字”)。
常见跨模态应用场景
跨模态技术已广泛应用于日常生活和科技领域:
(1)跨模态理解与检索
图文检索:输入一段文字描述(一只在雪地里奔跑的金毛犬),系统从图库中找到匹配的图像;或输入一张图像,返回相关的文本标签 / 描述。
视频内容分析:结合视频画面(视觉模态)和音频(听觉模态),识别场景(如 “演唱会” 画面中的人群 + 音频中的音乐匹配)。
(2)跨模态转换与生成
文本生成图像:输入文本描述(如赛博朋克风格的未来城市夜景),模型生成对应的图像(如 Midjourney、DALL・E 的核心功能)
语音转文字(ASR)与文字转语音(TTS):将听觉模态的语音转换为文本模态,或反之(如微信语音转文字、有声书生成)
图像生成文本:输入一张图像,模型自动生成描述文字(如一个小女孩在公园放风筝,背景有蓝天白云)
(3)多模态融合任务
智能助手:结合语音(用户说话)、文本(屏幕显示)、图像(摄像头识别场景),理解用户需求(如帮我查这道菜的做法,需识别用户指向的菜品图像 + 语音指令)
自动驾驶:融合摄像头(视觉)、雷达(距离数据)、激光雷达(三维环境)、地图文本信息,实现环境感知和决策
视频字幕生成:结合视频画面(识别内容)和音频(提取语音转文字),生成精准的字幕(需匹配画面人物说话时机)
跨模态技术的挑战
跨模态任务的难点在于不同模态的异质性:
特征差异大:文本是离散符号,图像是连续像素,两者的底层特征无法直接比较
语义鸿沟:同一种语义可能在不同模态中表现形式差异极大(例如开心的文本描述与笑脸的图像特征)
数据对齐难:高质量的跨模态标注数据(如精准配对的图文、音视频)获取成本高
跨模态与大模型的关系
近年来,以 GPT-4、Gemini 为代表的多模态大模型成为跨模态技术的核心载体。它们通过统一的模型架构(如 Transformer)处理多种模态输入。
例如:
GPT-4 可同时接收文本和图像输入,回答图像中的物体是什么或根据图文混合指令生成内容;
Gemini 支持文本、图像、音频、视频的融合理解,实现更自然的人机交互。
这些模型通过海量跨模态数据训练,学习到不同模态间的深层关联,从而打破单一模态的局限
总结
跨模态,本质是连接不同信息形式的桥梁,它让机器能像人类一样,综合文字、图像、声音等多种信息理解世界
是实现更智能、更自然的人机交互的核心技术之一
从图文生成到自动驾驶,跨模态技术正深刻改变着 AI 的应用边界
Anthropic
anthropic
ænˈθrɒpɪk
ænˈθrɑːpɪk
Anthropic是一家位于美国加州旧金山的人工智能股份有限公司,成立于2021年。 该公司由达里奥·阿莫迪和丹妮拉·阿莫迪兄妹创立,现任首席执行官达里奥·阿莫迪。 是一家人工智能安全和研究公司,致力于构建可靠、可解释和可操纵的AI系统。 Anthropic公司开发了聊天机器人Claude,提出的“宪法AI原则”。
Palm
palm 有手掌的含义,pɑːm,这里是公司,叫奔迈
Pilot
/ ˈpaɪlət /
/ ˈpaɪlət /
飞行员;领航员;(船只的)领航员;(电视)试播节目;航海手册;<非正式>职业骑师;<古>向导;(火车头前端的)排障器
Palm公司,原名Palm, Inc.,是一家美国公司,曾是知名的掌上电脑和智能手机制造商。它以其早期的Palm Pilot系列产品和Palm OS操作系统而闻名。后来,Palm公司经历了多次重组和收购,最终于2010年被惠普收购。
Falcon
falcon
/ ˈfɔːlkən /
/ ˈfælkən /
隼(sun),猎鹰
Falcon 180B is a super-powerful language model with 180 billion parameters, trained on 3.5 trillion tokens. It’s currently at the top of the Hugging Face Leaderboard for pre-trained Open Large Language Models and is available for both research and commercial use…
This model performs exceptionally well in various tasks like reasoning, coding, proficiency, and knowledge tests, even beating competitors like Meta’s LLaMA 2.
Among closed source models, it ranks just behind OpenAI’s GPT 4, and performs on par with Google’s PaLM 2 Large, which powers Bard, despite being half the size of the model.
猎鹰180B是一个超级强大的语言模型,有1800亿参数,训练了3.5万亿个符号。它目前在预训练开放LLM的拥抱脸排行榜上名列前茅,可用于研究和商业用途。
该模型在推理、编码、熟练程度和知识测试等各种任务中表现异常出色,甚至击败了Meta的LLaMA 2等竞争对手。
在闭源模型中,它的排名仅次于OpenAI的GPT 4,性能与谷歌的PaLM 2 Large相当,后者为Bard提供动力,尽管尺寸只有模型的一半。
Hugging Face Leaderboard
Hugging Face 的 Leaderboard 是评估自然语言处理(NLP)模型性能的重要平台。不同任务的指标反映了模型在各自领域的表现
Hugging Face Leaderboard 有多个不同类型的榜单,不同榜单的指标查看位置有所不同,以下是一些常见的情况:
Open LLM Leaderboard:
该榜单基于 AI2 推理挑战、HellaSwag、MMLU、TruthfulQA 等基准测试来评估模型性能。在页面上可以看到不同模型在这些基准测试任务上的得分及排名等指标信息,点击具体模型,还能查看其在各项任务上的详细表现。
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard#/
MTEB Leaderboard:
排行榜页面展示了各种模型在翻译、摘要、问答等多个任务上的表现,包括不同模型的名称、各项任务的得分以及综合排名等指标。
https://huggingface.co/spaces/mteb/leaderboard
OpenCompass LLM Leaderboard:
可以通过查看不同的能力维度选项来分别查看综合榜单与专项榜单,同时区分了中文数据集与英文数据集。点击模型的名称可跳转进入模型详情页,查看单个模型的各项具体数据,通过选定不同能力维度,可快速查看模型在各个细分能力的数据集上的性能表现。
https://huggingface.co/spaces/opencompass/opencompass-llm-leaderboard
Open LLM Leaderboard 中涉及的指标
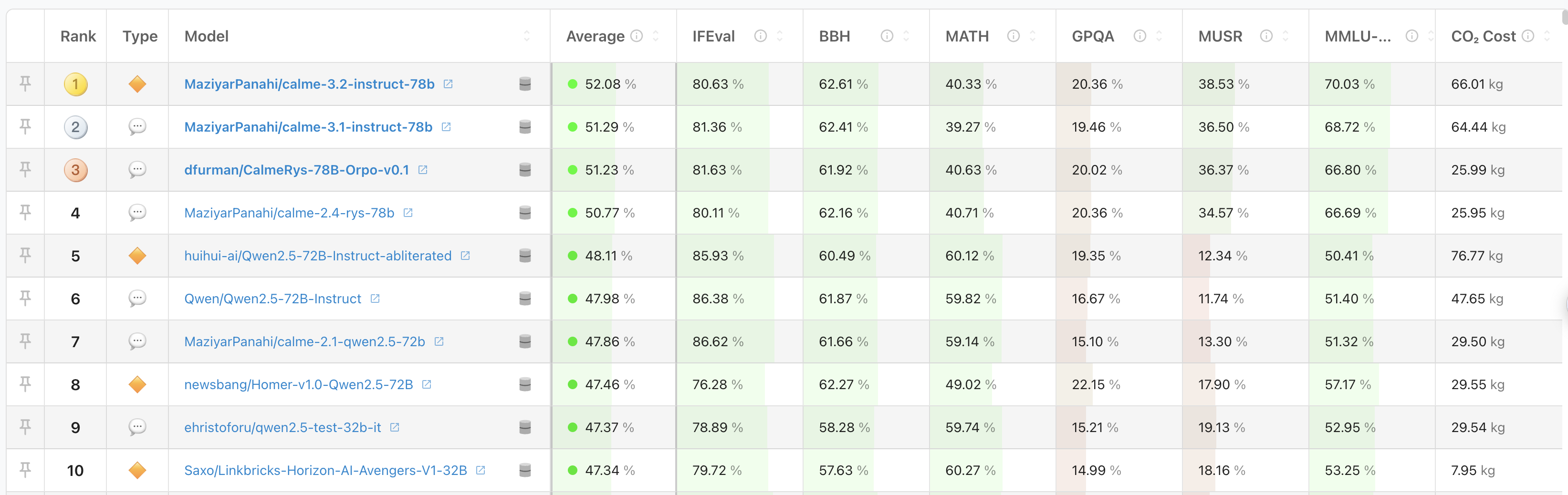
IFEval
(following / ˈfɒləʊɪŋ /)
Instruction-Following Evaluation (IFEval) 指令遵循评估
Purpose:
Tests model’s ability to follow explicit formatting instructions 测试模型遵循明确格式指令的能力
Instruction following 指令遵循
Formatting 格式规范
Generation 内容生成
Scoring: Accuracy: Was the format asked for strictly respected (严格遵循)
评分标准:准确性:生成内容是否严格符合要求的格式
BBH
Big Bench Hard (BBH):
Collection of challenging for LLM tasks across domains
这是一系列针对大型语言模型(LLM)的跨领域挑战性任务集合
Language understanding 语言理解
Mathematical reasoning 数学推理
Common sense and world knowledge 常识与世界知识
Scoring: Accuracy: Was the correct choice selected among the options.
评分标准:准确性:是否从选项中选出了正确答案。
MATH
Mathematics Aptitude Test of Heuristics (MATH), level 5:
启发式数学能力测试(MATH),5 级:
Content:
High school level competitions mathematical problems 高中水平竞赛类数学题
Complex algebra 复杂代数题
Geometry problems 几何题
Advanced calculus 高等微积分题
Scoring: Exact match: Was the solution generated correct and in the expected format
评分标准:精确匹配:生成的解答是否正确且符合预期格式。
GPQA
Graduate-Level Google-Proof Q&A (GPQA):
研究生级谷歌验证问答(GPQA)
Focus: PhD-level knowledge multiple choice questions in science 聚焦“博士级科学领域多项选择题”
Chemistry 化学
Biology 生物学
Physics 物理学
Scoring: Accuracy: Was the correct choice selected among the options.
评分标准:准确性:是否从选项中选出了正确答案。
MUSR
(Reasoning / ˈriːzənɪŋ / 推理,推论;推断力)
多步骤软性推理(MuSR)
Multistep Soft Reasoning (MuSR):
Scope: Reasoning and understanding on/of long texts 针对长文本的推理与理解能力
Language understanding 语言理解
Reasoning capabilities 推理能力
Long context reasoning 长上下文推理
Scoring: Accuracy: Was the correct choice selected among the options.
评分标准:准确性:是否从选项中选出了正确答案。
MMLU-Pro
Massive Multitask Language Understanding - Professional (MMLU-Pro): 大规模多任务语言理解 - 专业版
(ethics / ˈeθɪks / 伦理)
Coverage: Expertly reviewed multichoice questions across domains
经专家评审的跨领域多项选择题
Medicine and healthcare 医学与 healthcare
Law and ethics 法律与伦理
Engineering 工程学
Mathematics 数学
Scoring: Accuracy: Was the correct choice selected among the options.
评分标准:准确性:是否从选项中选出了正确答案。
Carbon Dioxide Emissions:
(inference / ˈɪnfərəns / 推断,推理;推断结果,结论,model inference 模型推理)
(methodology / ˌmeθəˈdɒlədʒi / 方法论,一套方法)
CO₂ emissions of the model evaluation 模型评估阶段的二氧化碳排放量
Only focuses on model inference for our specific setup 仅针对我们特定设置中的模型推理过程
Considers data center location and energy mix
Allows equivalent comparision of models on our use case
考虑数据中心位置和能源结构
支持在我们的使用场景中对不同模型进行等效对比
Why it matters: Environmental impact of AI model training
Large models can have significant carbon footprints
为何重要?
AI 模型训练对环境的影响
大型模型可能产生显著的碳足迹
Helps make informed choices about model selection
帮助在模型选择时做出更明智的决策
Learn more: For detailed information about our CO₂ calculation methodology
如需关于我们二氧化碳计算方法的详细信息
Average
Average score across all benchmarks:
Calculation:
Weighted average of normalized scores from all benchmarks
Each benchmark is normalized to a 0-100 scale
All normalised benchmarks are then averaged together
所有基准测试标准化分数的加权平均值