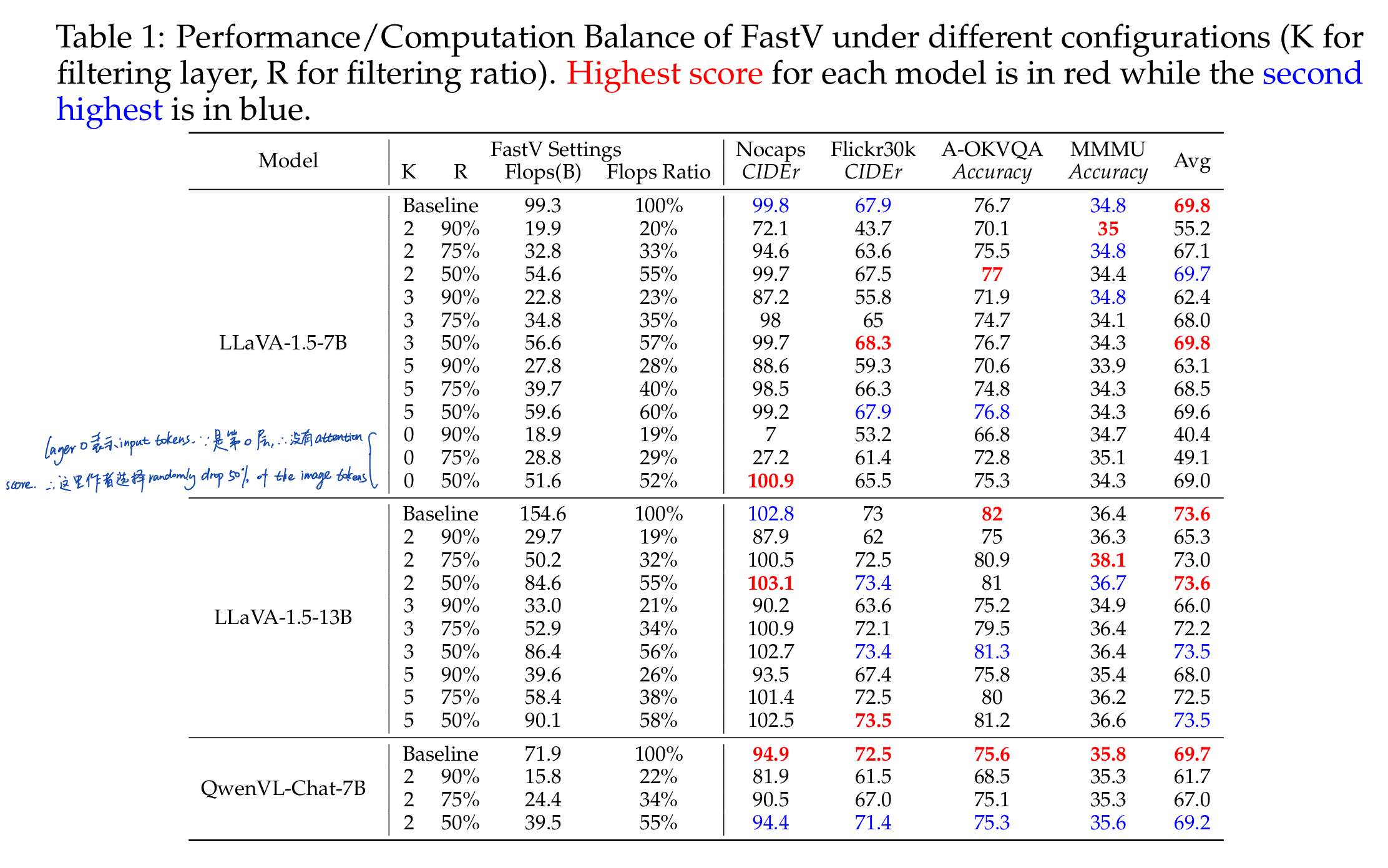
FastV: An Image is Worth 1/2 Tokens After Layer 2
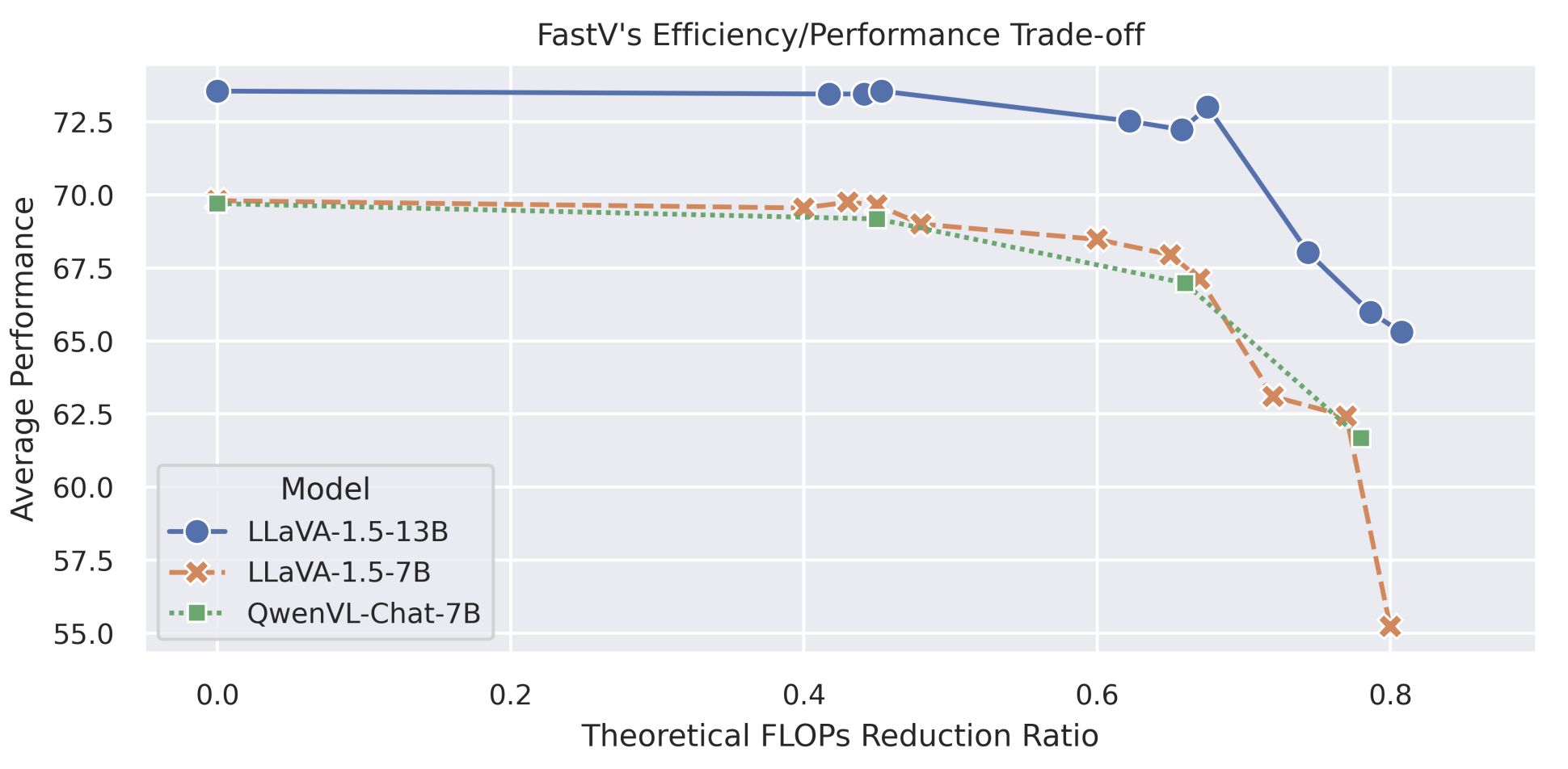
论文的发现:Half of the tokens of large vision language models are kind of redundant, so we can compress the flops of 13 billion parameter model to achieve a lower budget that of a 7 billion parameter model while still maintaining superior performance.
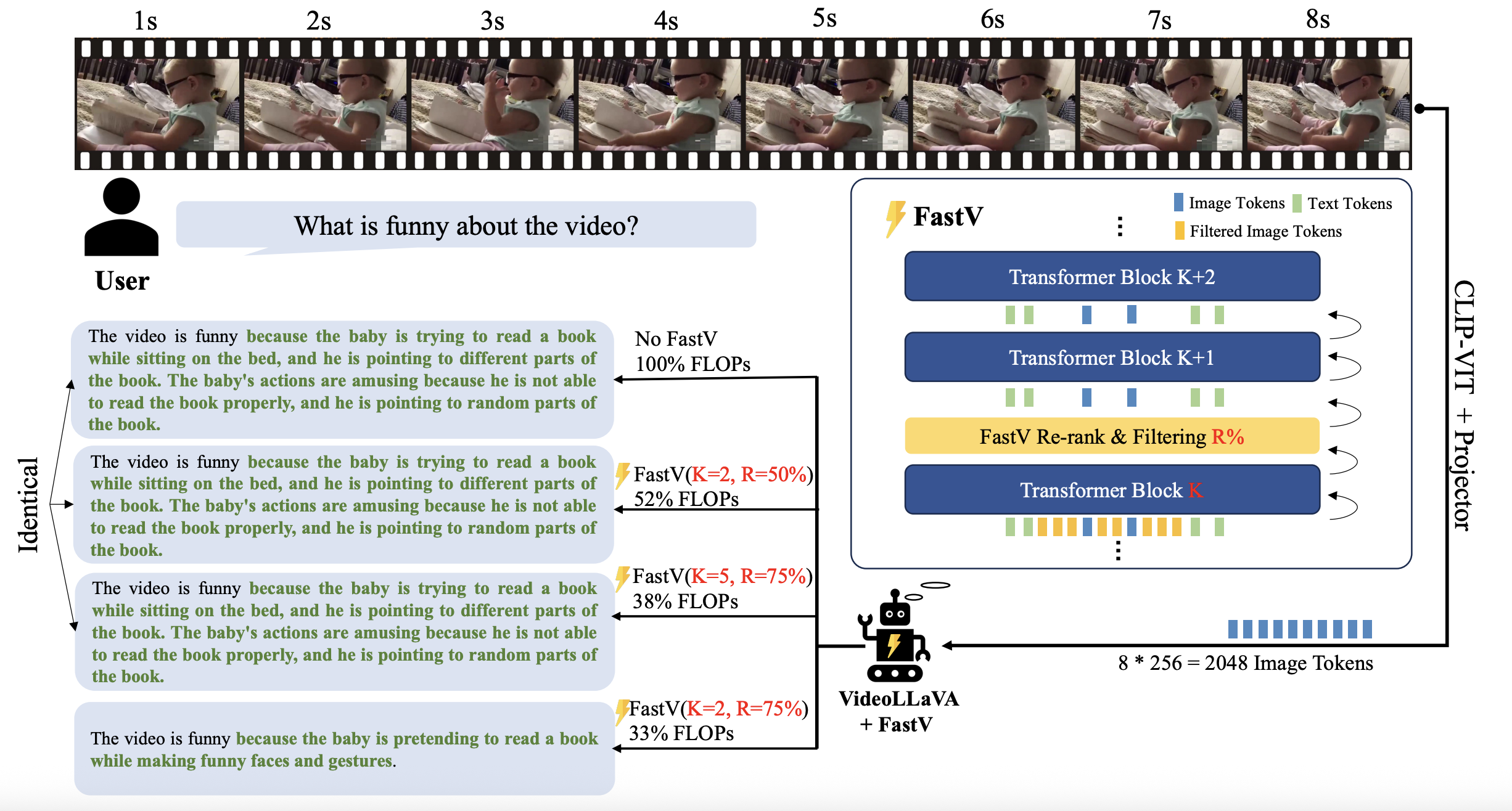
如下图所示,我们需要在第K层后添加一个filter层,将不重要的tokens去掉,然后再接着下一层。
How should we filter them out?
We do it based on those attention scores α\alphaα. We compute them for each tokens so we have some score that says how much each of these tokens are attending to the previous tokens. And if they do not attend a lot meaning that they are not very important so I can select like 50% of them and filter them out.
如下图所面所示的结果,我们可以看到如果选择在第2层filter out 50%的image tokens,我们就减少了52%的flops,而模型的输出完全一致;如果选择在第5层filter out 75%的image tokens,我们就减少到38%的flops,模型的输出还是一样;如果选择在第2层filter out 75%的image tokens,模型的输出就会受到影响了
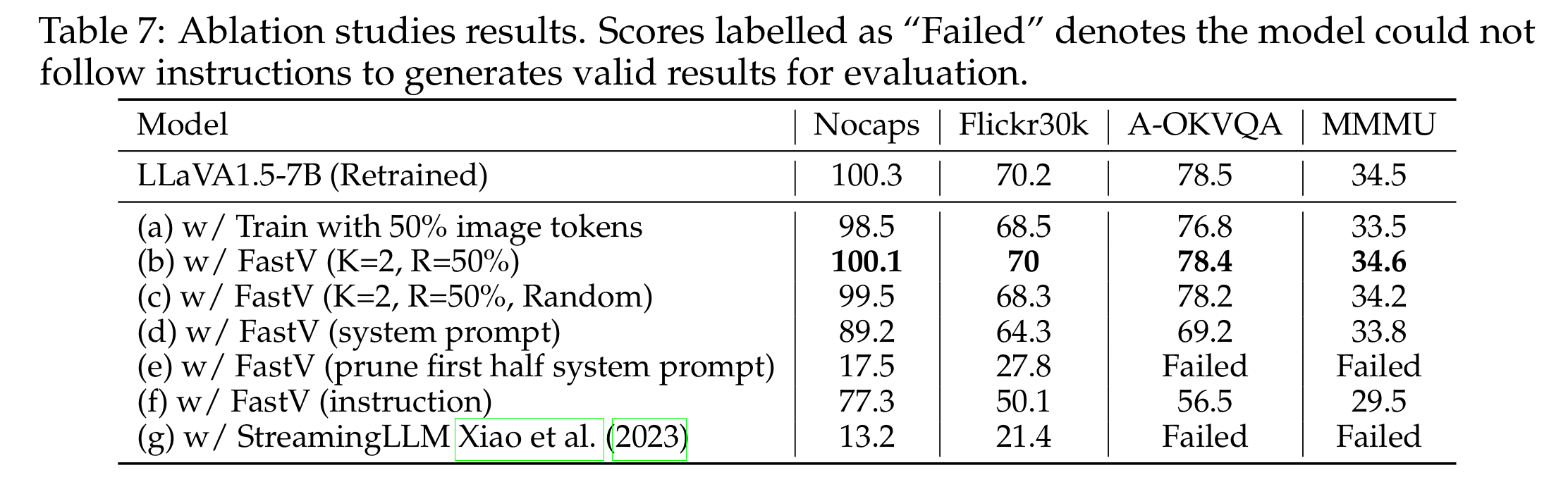
更详细的数据对比如下表所示