【Python】-- 机器学习项目 - 基于KNN算法的鸢尾花分类
文章目录
文章目录
- 01 什么是KNN算法
- 02 KNN算法如何执行
- 03 KNN算法核心思想
- 04 基于KNN算法的鸢尾花分类
- 05 基于KNN算法的鸢尾花分类原理代码解释
- 06 基于KNN算法的鸢尾花分类源码
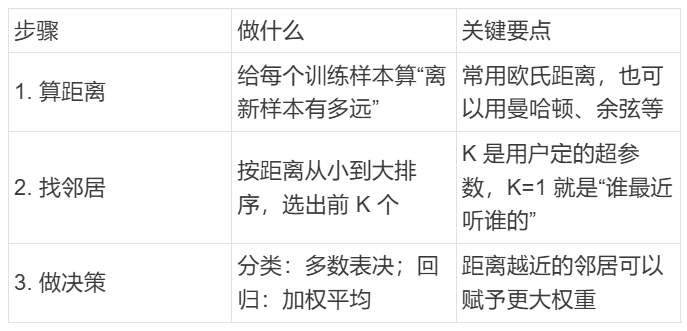
01 什么是KNN算法
计算测试样本与训练集中各个样本之间的距离,选择与测试样本距离最近的K个,然后统计这K个样本中出现标记最多的那个,将这个标记作为测试样本的标记。
02 KNN算法如何执行
03 KNN算法核心思想
平滑假设:空间相近的样本具有相似的输出。如果这一假设不成立(比如数据位于高维稀疏空间),KNN 就失灵。
04 基于KNN算法的鸢尾花分类
"""KNN算法也叫做K近邻算法,它的主要思想是:计算测试样本与训练集中各个样本之间的距离,选择与测试样本距离最近的K个,然后统计这K个样本中出现标记最多的那个,将这个标记作为测试样本的标记
"""from sklearn.datasets import load_iris
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
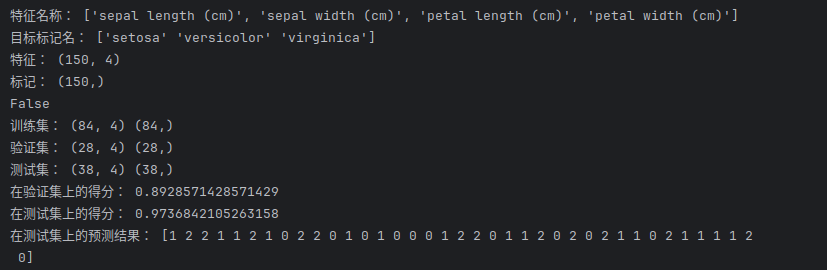
from sklearn.neighbors import KNeighborsClassifierdef knn():# 加载数据集iris = load_iris()feature = iris.datatarget = iris.targetprint("特征名称:", iris.feature_names)print("目标标记名:", iris.target_names)print("特征:", feature.shape)print("标记:", target.shape)# 特征预处理# 判断有没有缺失值print(pd.isnull(feature).any())# 标准化std = StandardScaler()feature = std.fit_transform(feature)# 划分数据集x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.25)x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.25)print("训练集:", x_train.shape, y_train.shape)print("验证集:", x_val.shape, y_val.shape)print("测试集:", x_test.shape, y_test.shape)# 建立KNN模型kn = KNeighborsClassifier(n_neighbors=5)# 训练kn.fit(x_train, y_train)# 验证score_val = kn.score(x_val, y_val)print("在验证集上的得分:", score_val)# 测试score_test = kn.score(x_test, y_test)print("在测试集上的得分:", score_test)predict = kn.predict(x_test)print("在测试集上的预测结果:", predict)if __name__ == "__main__":knn()05 基于KNN算法的鸢尾花分类原理代码解释
1.load_iris()取 150×4 的花特征和花类别。
2.检查缺失值(无),
StandardScaler 把 4 个特征拉成 0 均值 1 方差。
3.两次
train_test_split:
• 第一次 75/25 → 训练集 + 临时集
• 第二次 75/25 → 训练集再拆 → 得到 验证集
最终比例 ≈ 56% 训练 / 19% 验证 / 25% 测试。
4.KNeighborsClassifier(n_neighbors=5)建模型。
5.fit不迭代,只是把训练数据存起来。
6.score_val看验证集准确率,用来挑 K(本例固定 5)。
7.score_test给出最终未见过的测试集准确率。
06 基于KNN算法的鸢尾花分类源码
提供了Python的实现代码,使得用户可以根据自己的需求进行调整和应用。
Python代码下载地址