自然语言处理NLP---预训练模型与 BERT
一、预训练模型
1.1简单认识
预训练模型(Pretrained Model):在大规模数据上提前训练好模型,让模型先学习这些大数据的通用信息,掌握一般的特征或知识。然后再迁移到具体的任务中,无需重新从0开始训练。
注意:这些数据集是没有标签的,进行的是无监督学习。预训练模型总结来的两个重要思想就是预训练和微调。
预训练模型的杰出代表:ChatGPT、BERT
1.2核心技术机制
(1)自监督学习(SSF--self supervised learning):使用数据本身构造标签;
(2)微调(FT --- fine tuning):方式众多比如继续训练、参数微调;
(3)多模态建模:同时处理文本、图像、语言等多模态信息。
1.3案例
利用别人封装好的大模型进行一个文本分类操作,当前选择的模型是基于BERT模型的
步骤:
(1)导入模型,可以自己在官网下载,也可以编写程序,在程序中自动下载;
(2)利用模型进行推理。(最好在集成终端中进行)
# from transformers import BertForSequenceClassification
# from transformers import BertTokenizer
# import torch
# import os# current_path=os.path.realpath(os.path.dirname(__file__))
# cache_path =os.path.join(current_path,'cache')# tokenizer=BertTokenizer.from_pretrained(
# 'IDEA-CCNL/Erlangshen-Roberta-110M-Sentiment',
# cache_dir=cache_path
# )
# model=BertForSequenceClassification.from_pretrained(
# 'IDEA-CCNL/Erlangshen-Roberta-110M-Sentiment',
# cache_dir=cache_path
# )# text='今天天气真好'# inputs = tokenizer(
# text,
# return_tensors = 'pt'
# )
# print('输入token_id',inputs['input_ids'])# with torch.no_grad():
# outputs=model(**inputs)
# print('输出logits',outputs.logits)# # 转为类别
# predicted_class_id = torch.argmax(outputs.logits, dim=-1).item()
# print("预测类别ID:", predicted_class_id)
# print("预测类别标签:", model.config.id2label[predicted_class_id])# # model.config.id2label
# # 是 Hugging Face Transformers 模型中的一个字典,它把 模型输出的类别索引(整数) 映射为 可读的标签(字符串)。from transformers import BertForSequenceClassification
from transformers import BertTokenizer #把文字转成模型能理解的 token_id(整数序列)。
import torch
import os#路径处理,最好都用这种方法
current_path=os.path.realpath(os.path.dirname(__file__)) #当前文件的相对路径
cache_path =os.path.join(current_path,'cache') #路径拼接#加载分词器,指定缓存路径
tokenizer=BertTokenizer.from_pretrained('IDEA-CCNL/Erlangshen-Roberta-110M-Sentiment',cache_dir=cache_path)#加载分类模型,直接用于预测
model=BertForSequenceClassification.from_pretrained('IDEA-CCNL/Erlangshen-Roberta-110M-Sentiment',cache_dir=cache_path)text='今天天气真好'inputs = tokenizer(text,return_tensors = 'pt')
print('编码id:',inputs['input_ids'])
decoder_text = tokenizer.decode(inputs['input_ids'][0])
print('解码文字:',decoder_text)#推理
with torch.no_grad():outputs = model(**inputs)print('原始输出:',outputs.logits)#转换类别
pre_cls_id = torch.argmax(outputs.logits,dim=-1).item()#将原本的positive、negative变为中文版的解释
id2label = model. config.id2label
pre_label = id2label[pre_cls_id]dict1 = {'Positive':'这是好评','Neutral': '这是中立评论','Negative':'这是差评'
}
print('预测类别id:',pre_cls_id)
print('预测类别标签:',dict1[pre_label])
结果:
编码id: tensor([[ 101, 791, 1921, 1921, 3698, 4696, 1962, 102]])
解码文字: [CLS] 今 天 天 气 真 好 [SEP]
原始输出: tensor([[-0.5385, 0.4860]])
预测类别id: 1
预测类别标签: 这是好评
二、BERT
BERT(bidirectional encoder representations from transformers)
2.1核心思想
就是预训练模型的范式:BERT还包括一个双向。
(1)海量无标签数据进行无监督学习的预训练;
(2)对模型进行具体项目的微调。
cls本身并不代表具体的单词,它只是一个特殊标记,但是它为什么可以做分类判断:注意力机制,提取了整个语句的语义。
2.2优势
强上下文理解能力:双向建模使得其理解力更强。
预训练迁移能力强:可以微调于各种NLP下游任务。
统一架构:一个模型可以处理分类、问答、文本蕴含等多种任务。
2.3模型结构
BERT完全基于transformer encoder,没有decoder。
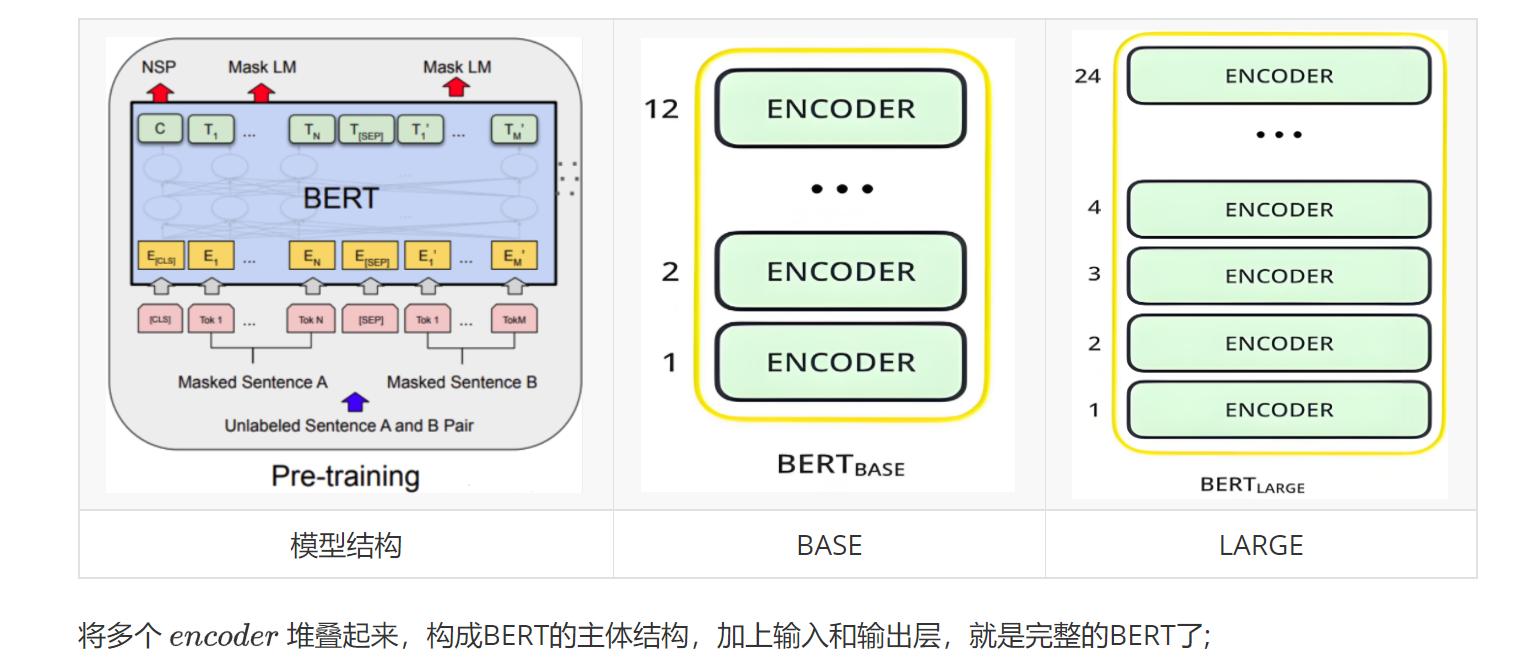
| 版本 | 层数 | 隐藏维度 | 注意力头数 | 参数量 |
BERT base BERT large | 12 24 | 768 1024 | 12 16 | 110M 340M |
M:百万
b:十亿
CLS:作为句子的开头,通过注意力机制,允许CLS与其他的token进行交互,具有整合序列全局信息的作用。
SEP:每一句话的结尾,作为模型区分句子的标志。
2.4预训练任务
预训练任务有MLM和NSP两个任务,且两个任务同时训练。
2.4.1MLM
MLM(Masked Language Model):将原句子的一小部分词(15%)进行掩码填充,不让模型看到这个真实的词,帮助模型理解词级别的上下文。
方法:80%被mask,10%随机词,10%保留原词。
2.4.2NSP
NSP(next sentences prediction):帮助模型理解句子之间的关系。模型输入两个句子50%是实际的连续句子,50%是另一篇文章的随机句子。
2.5下游任务
BERT在做预训练之后,可以被用于多种NLP(自然语言处理)下游任务。
(1)句子级任务:情感分析、新闻分类、意图识别、虚假新闻识别;
(2)句对级任务:自然语言推理、问题匹配、问答系统;
(3)标注级任务:命名体识别、关键词抽取;
2.6使用方式
(1)预训练后微调FN整个模型;
(2)冻结BERT参数,再添加符合自己需求的上层新网络。
2.7 BERT问答系统
如果已经保存了模型,就只填模型路径,如果没有保存模型,可以直接下,将模型放到固定位置。
from transformers import AutoModelForQuestionAnswering,AutoTokenizer,pipeline
import oscurrent_path=os.path.realpath(os.path.dirname(__file__))
model_path=os.path.join(current_path,'01.review\QA_model')
if __name__ == '__main__':model = AutoModelForQuestionAnswering.from_pretrained(#'uer/roberta-base-chinese-extractive-qa',model_path)tokenizer = AutoTokenizer.from_pretrained(#'uer/roberta-base-chinese-extractive-qa',model_path)QA = pipeline('question-answering', model=model, tokenizer=tokenizer)QA_input = {'question': "谁是笨蛋",'context': "1不太聪明,2也不太聪明,3最不聪明。"}QA(QA_input)print(QA(QA_input))
三、小结
学习了预训练范式以及基于BERT框架的情感分类、问答系统的两个小实验,认识了BERT的结构和参数组成,初步了解了一点有关大模型的基础知识。