利用标准IO实现寻找文件中字符出现最多次数
一、可以实现的方法
双向循环链表、数组的方法。
前者比较繁琐,需要构建链表,实际操作起来较繁琐,但查找元素方便(有想法可去试试);
后者相比较为简单,能够实现题目要求;
二、数组方法实现
1、思路:
定义一个数组,让数组的序号与字符的ASCII与之对应(例如a[ch]→ch→65→'A')。再接收字符,将接收到的字符让与之对应的数组内的值+1。将文件内容接收完毕之后,选数组内元素值的最大值,就是出现过多少次,对应的序号就是就是哪个字符。
2、代码实现:
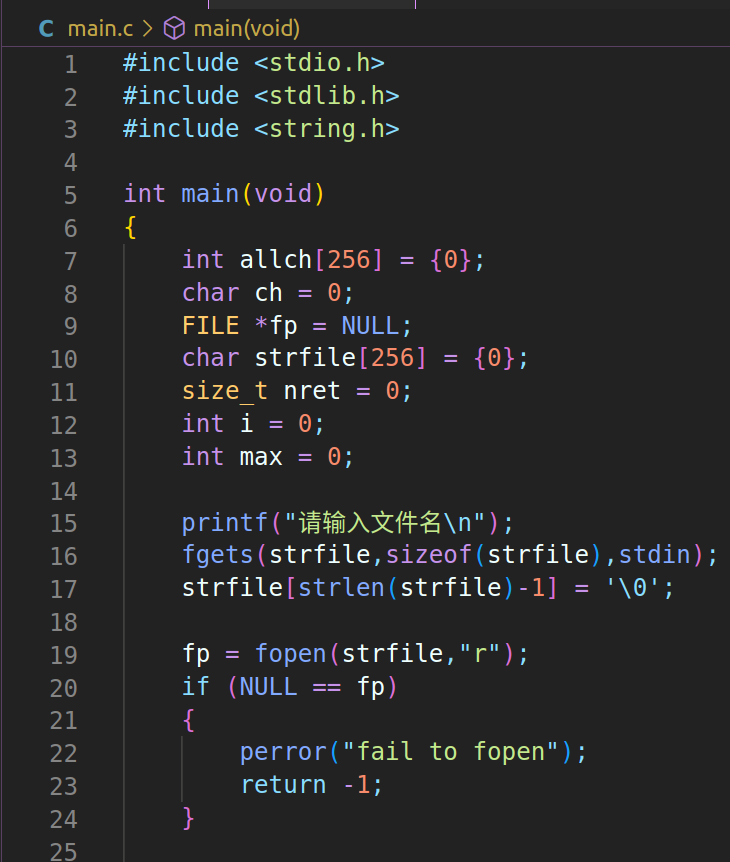
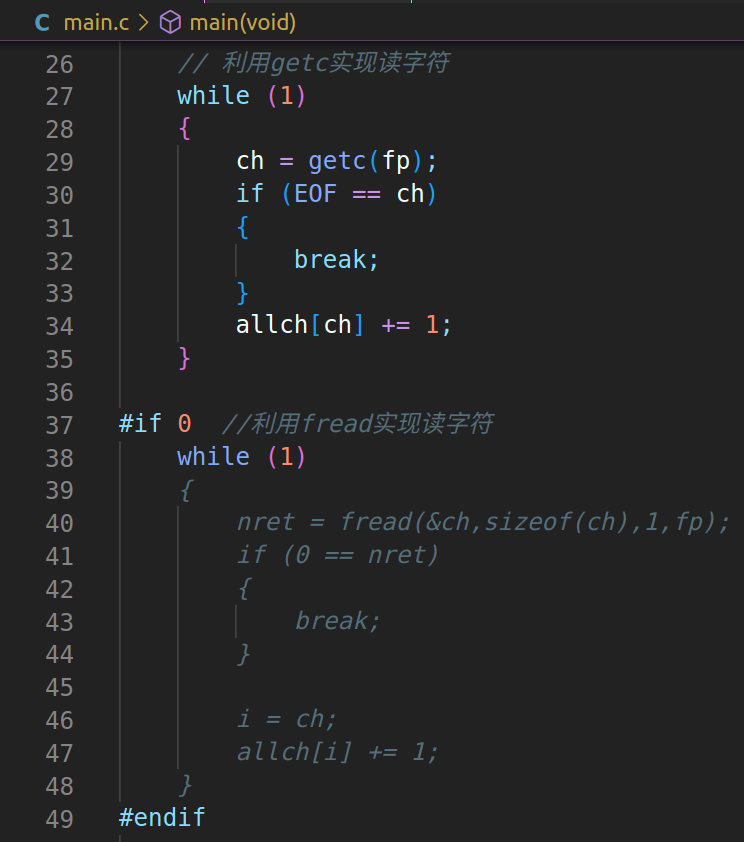
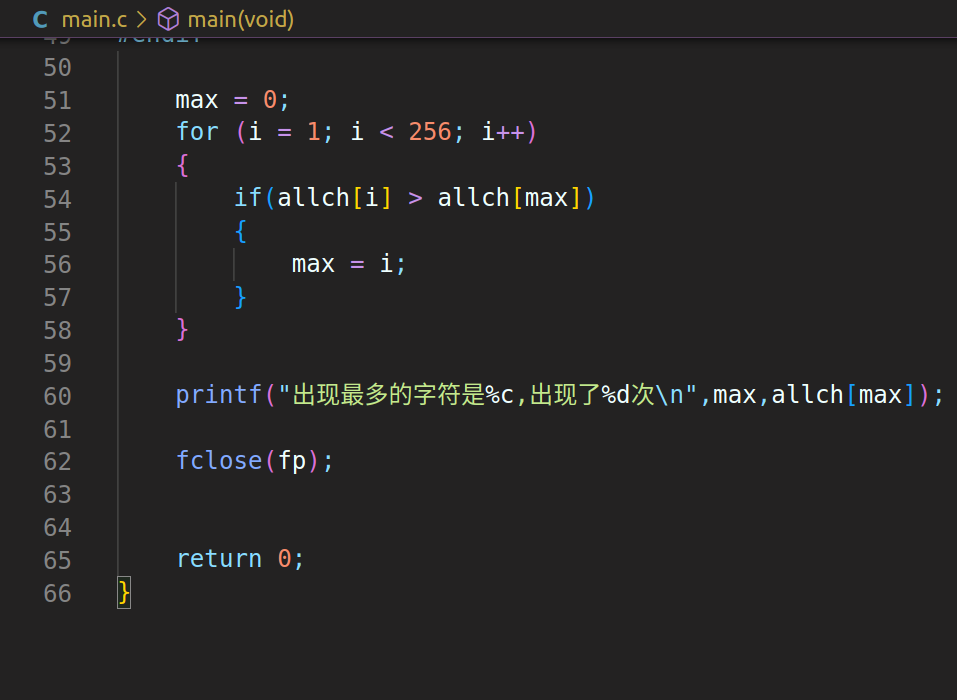

3、注意点:
1)fguts从终端(stdin)接收内容时会多接收一个'\n',导致字符串末尾(\n\0),为了使字符串能够正常接收,我们需要将字符串倒数第二位的'\n'赋值为'\0'.
2)数组利用元素下标比大小时,比较前假设第一位元素为最大或者最小,后续在循环内比较的对象是假设的这一位和 ‘i’ 对应的元素下标,满足if条件时则更新下标。最终我们既能得到最大或者最小的值,也能获得元素下标。而元素下标的数字对应的ASCII,用%c打印就可获得对应的字符。
3)fread函数接口,成功的返回值是读取到的对象个数,类型是size_t ,虽然这个类型是int型,我们也成size_t的意义是不再是简单的数字而是赋予这个数字是一个大小→读取到的对象的个数