问津集 #5:Crystal: A Unified Cache Storage System for Analytical Databases
文章目录
- 引言
- 传统缓存方案的局限性
- Crystal架构
- Region设计
- Cache Optimizition
- 总结
引言
语义缓存,文件缓存,查询结果缓存,中间过程缓存;AP计算中的缓存是一个非常大的话题,基于不同的需求,查询特征,有很多设计的余地在里面,这篇文章基于对于对象存储支持谓词下推能力的观察,设计了一套对应的缓存系统,以跨多个查询缓存和重用计算结果。
传统缓存方案的局限性
现有的缓存解决方案,如Alluxio、Databricks Delta Cache,Snowflake缓存层,腾讯云GooseFS,Velox AsyncCache普遍采用黑盒式的文件或块级缓存,使用LRU等标准替换策略。这种方案存在四个显著问题:
- 重复造轮子问题:每个DBMS都需要实现自己的缓存层,导致大量重复工作。
- 缓存利用率低下:即使页面中只需要一条记录,也必须缓存整个页面,造成宝贵缓存空间的浪费。以TPC-H的lineitem表为例,一个1MB的页面可能包含数千条记录,但查询可能只需要其中几条。
- 格式处理效率低:对于非列式格式的数据处理速度较慢,即使数据已缓存在计算节点上,成本依然很高。
- 谓词下推能力未充分利用:虽然云存储开始支持谓词下推(如AWS S3 Select,腾讯云COS Select),但现有缓存方案无法有效利用这一能力。
除了论文中提到的,其实基于块的缓存还存在冷读较慢的问题,因为其第一次读取需要读取整个块。
Crystal 通过下述方案解决上面的挑战:
- 很多系统正在采用plug-in “data source” 模型,这允许将表级谓词下推到数据源,这样就可以通过为系统添加一种数据源来支持Crystal了(在Velox中叫Connector机制,但是Velox目前不支持谓词下推到数据源级别,只能在FileReader级别做过滤)
- 使用Semantic Caching,实际存储经过Projection Filter + Predicates Filter后的数据,可供这种方法比起结果缓存可以让更多的查询从一个region中收益
- 使用Parquet存储缓存数据,使用Arrow Gandiva来过滤Arrow Table, Gandiva是为Arrow新开发的执行引擎,使用LLVM编译代码来过滤Arrow表(CodeGen在条件过滤上优势很大)
- 缓存的数据本身就是基于谓词过滤的,也是这篇文章的精彩之处,就算远程存储不支持也可以拉到原始数据后在本地执行过滤
Crystal架构


图一可以看到Crystal是一个外挂的缓存,和计算节点部署在一起,之前的文章提到过,这样做的缺点是:
- 计算节点需要挂盘
- 热点扩展不及时
- 为了缓存一致性上层需要保证任务分配时始终分配到固定节点
- 宕机后缓存无法复用
图二可以看到Crystal的相关组件,论文中认为Crystal是一个mini-DBMS或者cache management system (CMS),这个定位没问题,现在很多对象存储的缓存都是透明加速,Crystal的定位一个全新的data source,但是可以缓存来自远端的数据,以此做到尽可能适配更多的分析系统,这个思路是没问题的。
Crystal 维护两个本地缓存:
- 一个较小的requested region (RR)缓存
- 一个较大的 oracle region(OR)缓存
分别对应短期和长期缓存数据,这两个缓存都用Parquet存储数据,实际的一次查询步骤是这样的:
- Crystal通过Crystal API从Connector接收查询,一个查询包含remote file path + push-down predicates
- Crystal首先用Matcher对缓存(PR+OR)进行比对,查看是否可以使用一个或多个region覆盖该查询。如果缓存命中,它会从本地存储返回一组文件路径,如果缓存未命中,则有两个选择:
- 用远程路径进行回应,Connector正常访问远程逻辑,Crystal 可以选择将Connector下载并过滤后的region存储在 RR 缓存。
- Remote Downloader从远程下载数据,应用谓词,将结果存储在RR缓存中,并将本地路径返回给Connector。
- Crystal会收集查询的历史记录,并调用缓存Oracle Plugin为OR缓存计算最佳内容
这里的关键有两个:
- 如何设计Region,以做到基于predicates的查询?因为每个查询都会基于查询的文件生成一组Region,其他查询如何利用到这些Region
- Oracle Plugin 如何基于OR缓存来执行Prefetch。历史信息如何设计,如何基于历史信息决策预取哪些数据来填充OR
Region设计
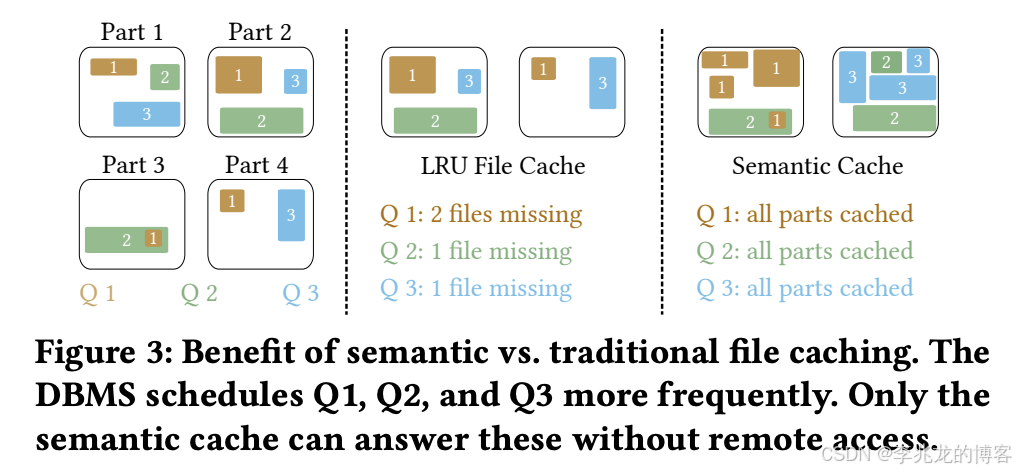
这张图指出的是语义缓存的好处,因为存储的是过滤后的数据而不是文件块,其占用的缓存总量就会小很多,同等大小的缓存就可以加速更多的缓存。
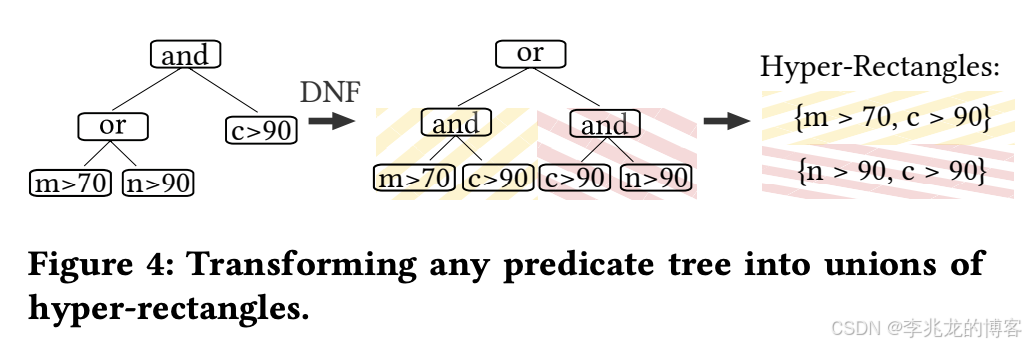
hyper-rectangles的设计是整篇论文的精髓,Crystal接收下推谓词字符串,并将其转换回内部 AST。由于对任意嵌套的逻辑表达式(“and”和“or”)进行论证较为困难,Crystal会将AST转换为 DNF,在DNF中,所有conjunctions 都被下推到表达式树中, conjunctions 和 disjunctions 不再交错。
这种转换的优势在于将复杂的逻辑表达式标准化为易于处理的 hyper-rectangles。每个conjunctions代表一个hyper-rectangles,整个region就是这些hyper-rectangles的并集。
在Crystal中,region 由 disjunction of conjunctions of predicates来标识,region还包含其远程文件和 projection
of the schema。简单来讲就是一个查询的结果就是一组region,每个region由disjunction of conjunctions of predicates 来标识,这样我们就可以很轻松的去计算Region之间以下关系了:
- 相等(Equality):两个区域包含完全相同的数据
- 超集(Superset):一个区域包含另一个区域的所有数据
- 交集(Intersection):两个区域有部分数据重叠
- 部分超集(Partial Superset):包含另一区域的某些合取项
Crystal使用 intersections and supersets of conjunctions 来判断region的关系,详细解释下上面的名词:
- 每个region包含多个hyper-rectangles
- 每个hyper-rectangles包含多个Conjunctions
- 每个Conjunctions对每个谓词列包含一个restriction
- 每个restrictions包含:range (min, max), their potential equal value, their set of non-equal values and whether isNull or isNotNull
如果两个restrictions pxp_{x}px和pyp_{y}py在同一列上,Crystal计算pxp_{x}px是否完全满足pyp_{y}py或pxp_{x}px是否与pyp_{y}py有交集。
- 为了确定超集关系,首先检查空值约束是否不矛盾。
- 测试pxp_{x}px的(最小值,最大值)区间是否是pyp_{y}py的超集
- 检查pxp_{x}px是否有限制性的非相等值来取消超集属性
- pyp_{y}py的所有额外相等值是否也包含在pxp_{x}px中。
对于两个Conjunctions cxc_{x}cx和cyc_{y}cy,如果cxc_{x}cx只包含在同一列上都比cyc_{y}cy的约束限制性更小的约束,则cx⊃cyc_{x} \supset c_{y}cx⊃cy。因此,cxc_{x}cx必须具有相等数量或更少的约束,这些约束都满足cyc_{y}cy的匹配约束。否则,cx⊅cyc_{x} \not \supset c_{y}cx⊃cy。cxc_{x}cx可以有更少的约束
在下面,我们展示确定两个region rxr_{x}rx和ryr_{y}ry之间关系的算法:
- 如果ryr_{y}ry的所有Conjunctions都在rxr_{x}rx中找到超集,则rx⊃ryr_{x} \supset r_{y}rx⊃ry成立。
- 如果rxr_{x}rx的至少一个Conjunctions与ryr_{y}ry的某个Conjunctions有交集,则rx∩ry≠0r_{x} \cap r_{y} \ne 0rx∩ry=0成立。
- 如果ryr_{y}ry的至少一个Conjunctions在rxr_{x}rx中找到超集,则∃conj⊂rx:conj⊂ry\exists conj \subset r_{x}: conj \subset r_{y}∃conj⊂rx:conj⊂ry(部分超集)成立。
- rx=ry:rx⊃ry∧ry⊃rxr_{x}=r_{y}: r_{x} \supset r_{y} \land r_{y} \supset r_{x}rx=ry:rx⊃ry∧ry⊃rx

查询时尽量选择Superset,如果找不到,则以conjunction为单位,以greedy的方式,在Partial Superset尽量选择能够包含尽可能多conjunction的region,逐步所有直到所有conjunction都被满足。
这就解释了第一个问题,通过AST转DNF的方式来生成hyper-rectangles,标识每个region,查询时使用用户传入的push-down predicates匹配region,以此在多个查询之间共享语义缓存。
Cache Optimizition
Requested Region(RR)缓存采用急切策略,专门处理短期查询模式:
- LRU-2策略:只有在第二次访问时才进行缓存,避免一次性查询占用缓存空间
- 快速响应:能够立即对工作负载变化做出反应
- 缓冲作用:为OR缓存收集足够统计信息提供缓冲期,如果有可以被长期使用的region,也可以被OR接管
Oracle Region(OR)缓存采用懒惰策略,基于历史查询模式进行优化:
- 背景计算:查询工作负载的长期洞察由OR缓存捕获,其可利用PR的历史记录来计算本地缓存的理想region set,以实现最佳性能,而且缓存的数据PR就不需要再重复计算
- 重叠感知算法:这是Crystal第二个核心创新
predicting cached regions 的一个关键组件是PR的历史记录。为了识别查询patterns,之前被访问的region存储在Crystal中,使用 ring-buffer 来保存最近的历史记录,每个 buffer element 代表由一组远程数据文件计算得出的request,这些文件与schema information, tuple count, and size相关联。
region的selectivity通过 result statistics 来体现。数据库本身可以提供结果统计信息,或者由Crystal进行计算。Crystal利用先前创建的sample生成 result statistics。,结合相关的schema information,Crystal预测tuple count 和 the result size。
如何基于PR的历史来判断哪些region应该存入OR呢,其实关键就是节省了多少拉取流量,之前还没看这篇论文,在我和小雷的讨论中也明确了这一点。
让我们定义一下问题,即每个region都关联一个收益值,即如果缓存的话可以节省的拉取流量,其成本自然就是缓存大小,假设缓存大小固定,我们需要求解的是如何让收益更大,这是一个典型的01背包问题
但是朴素的动态规划有两个问题:
- 背包容量(存储总量)和物品数(节省的字节数)值都非常大,想求最优解计算复杂度过高O(N*W),虽然可以通过将bytes修改为MB降低复杂度,但是还是很大
- 没有考虑region语义覆盖问题,可能两个region的收益都很大,但是其中一个是另外一个的Superset,那另外一个的收益就不是它本身的收益了
所以论文把动态规划直接改为了贪心算法,非常简单,就是用benefit/size,然后从大到小排序,贪婪的使用靠前的region直到空间不足。
对于语义覆盖是基于第一种算法的:
- 如果candidate是刚选中item的超集,其benefit要减去item的benefit,代表这部分收益已经被item包含了
- 如果candidate是刚选中item的子集,其benefit变为0,因此没有额外收益
- 如果candidate和刚选中item有交集,需要benefit做相应的减少,减少的delta部分是历史上能够被这两个region完全cover的entry项的benefit值

总结
正如论文结尾提到,Crystal背后的基本思想是跨多个查询缓存和重用计算结果,这一想法在大量研究工作中得到了探索,至少包括materialized view, semantic caching, intermediate results reusing
确实是很trick,且非常具有一定实用价值的工业研究结果,但是并不是所有场景都适配,比如时序场景下动则上千个查询条件组合很难和现有region存在交叠,或者车联网单车查询几乎是没有交叠的,而且查询时间不可控,可能需要再本地读取N个region,文件缓存可能只需要读取一次。
论文考虑到了查询下推这一点确实是非常巧妙,配合region的设计解决了这个问题,确实是很不错的一篇文章。
参考:
- 问津集 #4:The Five-Minute Rule for the Cloud: Caching in Analytics Systems