MM-Spatial和Spatial-MLLM论文解读
目录
一、MM-Spatial
1、概述
2、方法
3、架构
4、实验
二、Spatial-MLLM
1、概述
2、方法
3、训练过程
4、实验
一、MM-Spatial
1、概述
动机:现有多模态大模型在2D视觉任务上表现出色,但在3D空间理解上存在局限,主要对比SpatialRGPT任务中缺乏3D定位能力,所以提出更强的bench。另外MM-Spatial的数据集标注依赖激光扫描深度真值,而SpatialRGPT采用单目深度估计,MM-Spatial有更准确的度量信息。
2、方法
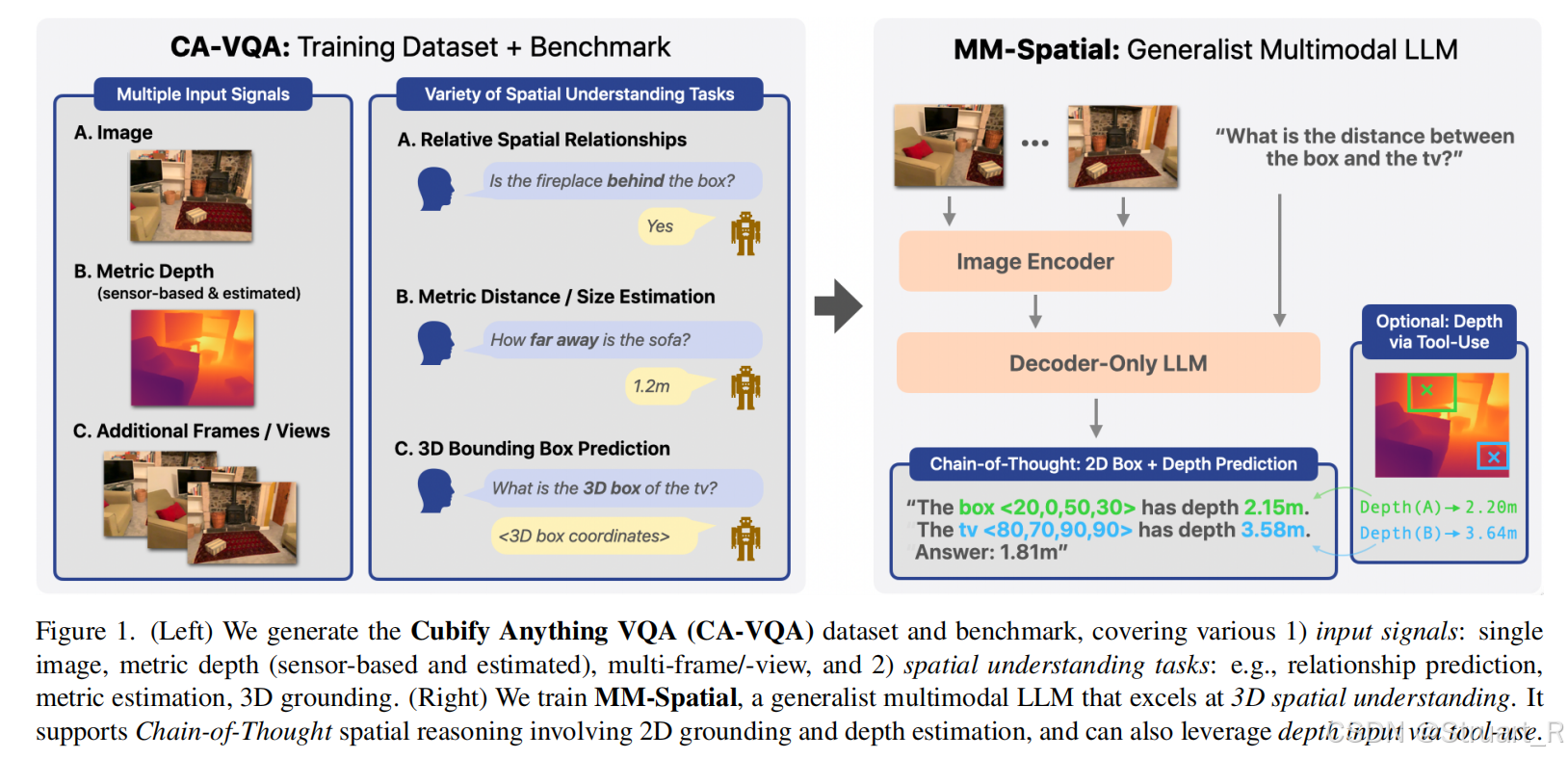
CA-VQA数据集和benchmark
数据集动机:以往的方法大多缺少3D定位任务,以及深度图信息。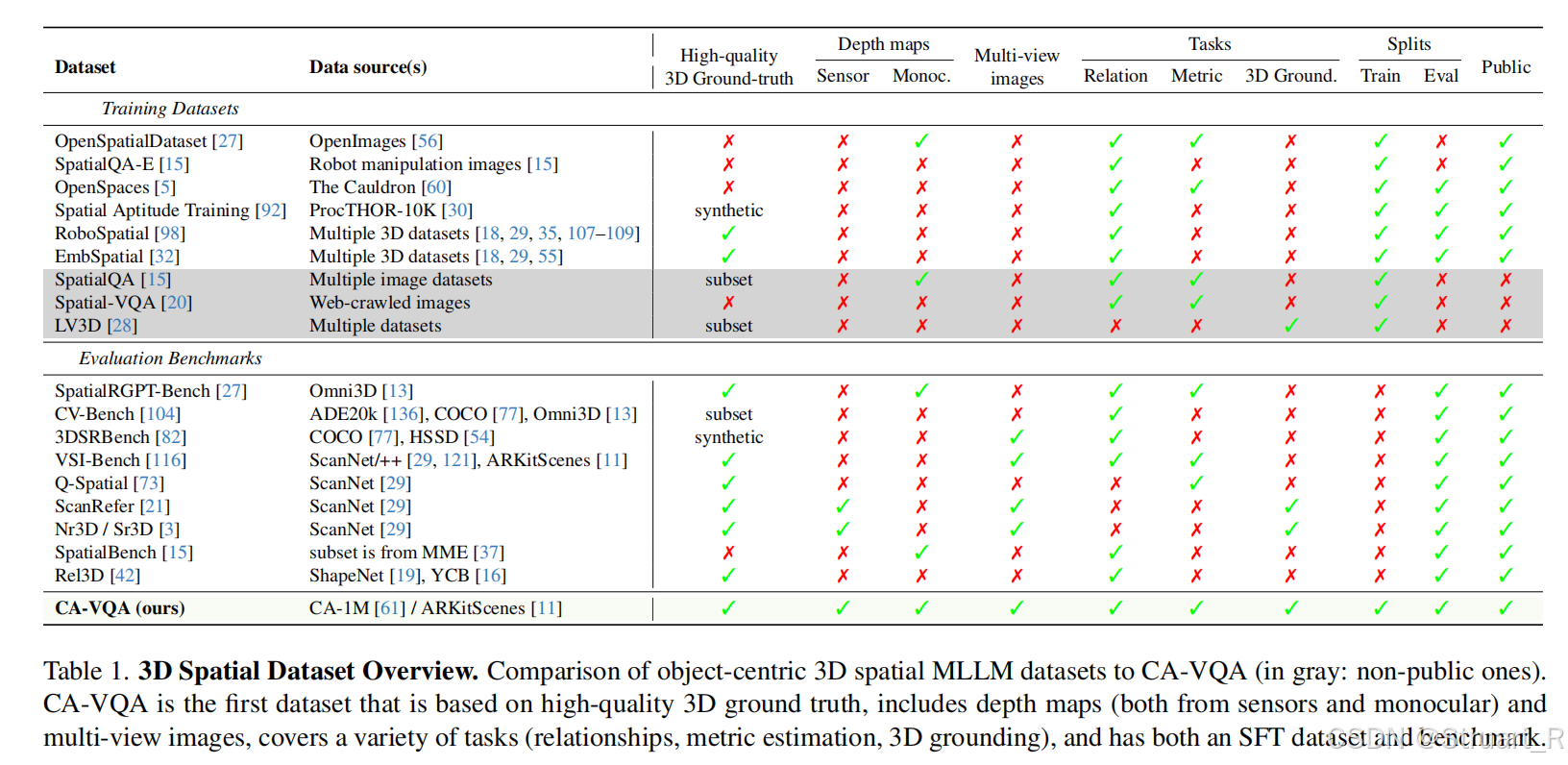
数据来源:基于CA-1M数据集(使用 ARKitScenes 的高质量激光扫描真值),包含7-DOF 3D边界框(也就是带旋转的OBB),3.3k个开放词汇标签,覆盖350k+物体实例,并且包含材质、颜色、形状等语义标签。数据集分为训练集和测试集,训练集按1FPS采样,覆盖连续视角。测试集按0.1FPS采样,减少冗余,确保场景多样性。

CA-VQA基于上述数据,采用四类输入信号,单视图RGB,多视图图像,传感器深度(FARO激光真值,ARKit雷达融合深度),单目估计深度。
包含7类空间任务,物体技术,视角相关关系,度量估计,物体距离,2D定位,3D定位,多选题。并且基于规则生成多样化问题,并将答案统一(比如尺寸单位统一到cm,距离单位统一到m,方向类问题离散化到8个方位)
盲过滤算法:减少语言先验偏差,防止模型不依赖视觉信息直接通过语言能力经验主义猜出答案,先通过7个基线模型(GPT-4o,Phi-3-Vision)等预测大难,若大于等于3个模型仅凭借文本信息就蒙对,则移除这个样本。
VQA数据如下:

3、架构
基于MM1.5架构,并利用DFN-CLIP作为图像编码器,语言模块采用Decoder-only LLM主干,连接模块通过C-Abstractor连接视觉与LLM空间。
对于单一图片,则划分为4个子图+1个概览图,提升高分辨率细节能力。
对于多视图,则支持拼接多帧图像。
对于深度信息采用类似SpatialRGPT的方式,或者通过工具直接调用上述的两个激光雷达测出来的深度值,或者完全利用CoT预测深度值。
训练过程沿用MM1.5通用多模态训练,并在此基础上新增CA-VQA空间数据加以SFT监督微调。
4、实验
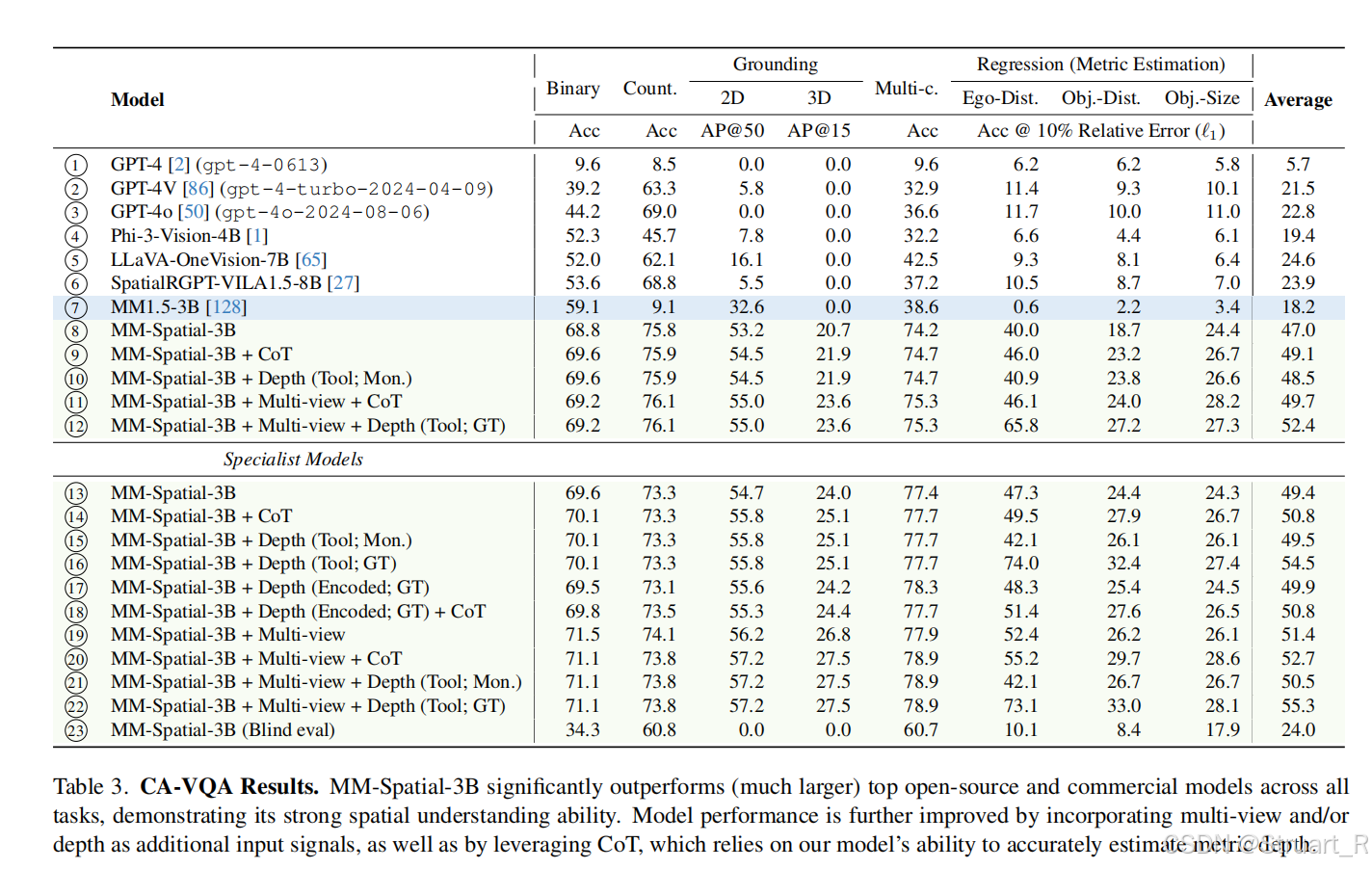
可以看到MM-Spatial本身就具有一定的度量空间的能力,但是不够严谨,经过CoT后数值更加准确。这个GT我没太搞懂,测试集直接把激光雷达的深度信息加进去了?

用CA-VQAbench对比的以往的方法。
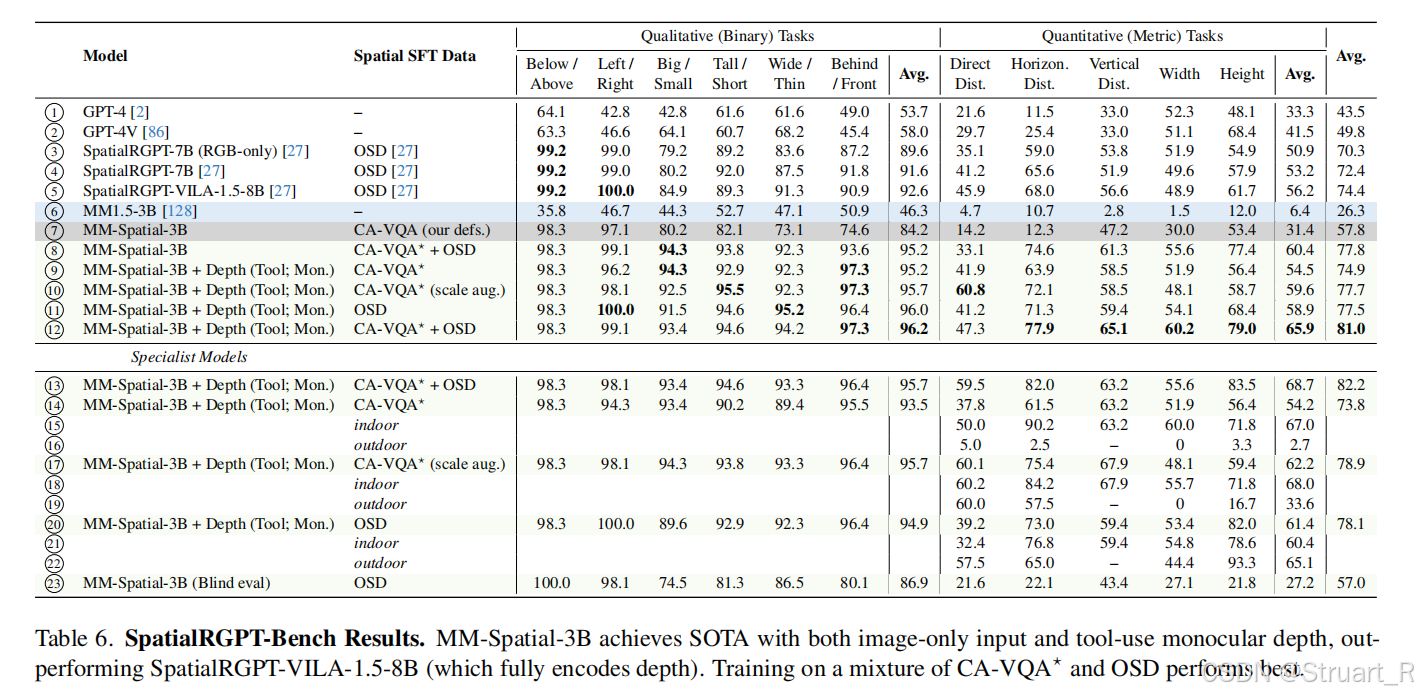
同样用SpaitalRGPT bench对比了一下:
二、Spatial-MLLM
1、概述

动机:现有视频多模态大语言模型(MLLM)在2D语义理解任务中表现出色,但在纯2D视频输入下的3D空间推理上仍然存在明显瓶颈。一方面传统3D MLLM需要依赖点云、深度图等进行输入,限制了仅有普通视频的现实场景的应用。另一方面,主流视频MLLM(如Qwen-VL)采用CLIP-based编码器,更加侧重语义信息,缺乏3D几何结构,空间感知能力较弱。
Spatial-MLLM提出了一个Spatial-MLLM-120k数据集,双编码器架构(引入VGGT作为空间编码器)提取语义信息和3D结构特征,利用SFT+RL的训练策略,强化推理能力。
2、方法
Spatial-MLLM架构
Spatial-MLLM的核心是双编码器+连接器+LLM骨干,融合语义和3D结构信息。输入视频帧序列,输出空间推理响应。
Dual Encoder
双编码器包括2D视觉编码器和空间编码器,其中2D编码器沿用Qwen2.5-VL-3B的视觉编码器,也就是基于预训练SigLIP2的ViT架构编码器。空间编码器采用VGGT初始化的编码器。
2D视觉编码器,用于提取高层语义特征,专注场景语义理解和物体识别,对于输入帧序列,每隔一帧作为2D Encoder的输入,并进行patchify,作为ViT的输入。ViT输出为
其中,
为patch大小,
为特征维度,帧处理取每隔一帧,
。
空间编码器,用于从2D视频中恢复隐式3D结构信息,这里视频帧不做切片处理所以帧数仍然是
,基于VGGT模型骨干,生成密集3D特征:
其中,相机特征(相机内外参数)
,区分首帧与其他帧的辅助tokens
,但仅
用于融合3D信息。
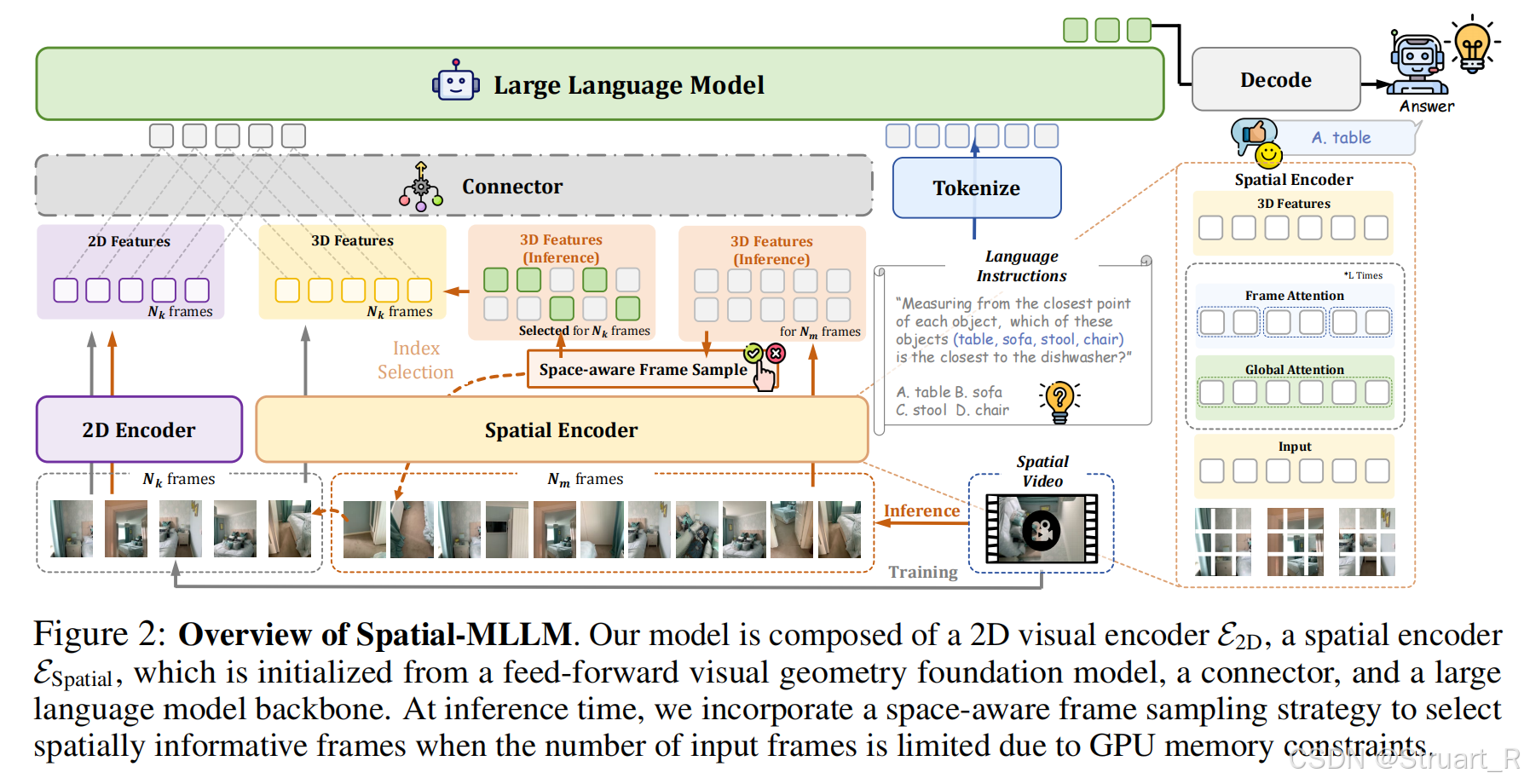
连接器,负责整合双编码器输出,首先将空间编码器的输出重组到匹配2D特征的维度,对齐时间维度和空间维度,,之后经过两个轻量级的MLP后拼接这两个特征,
,此时输出
。
为序列长度。
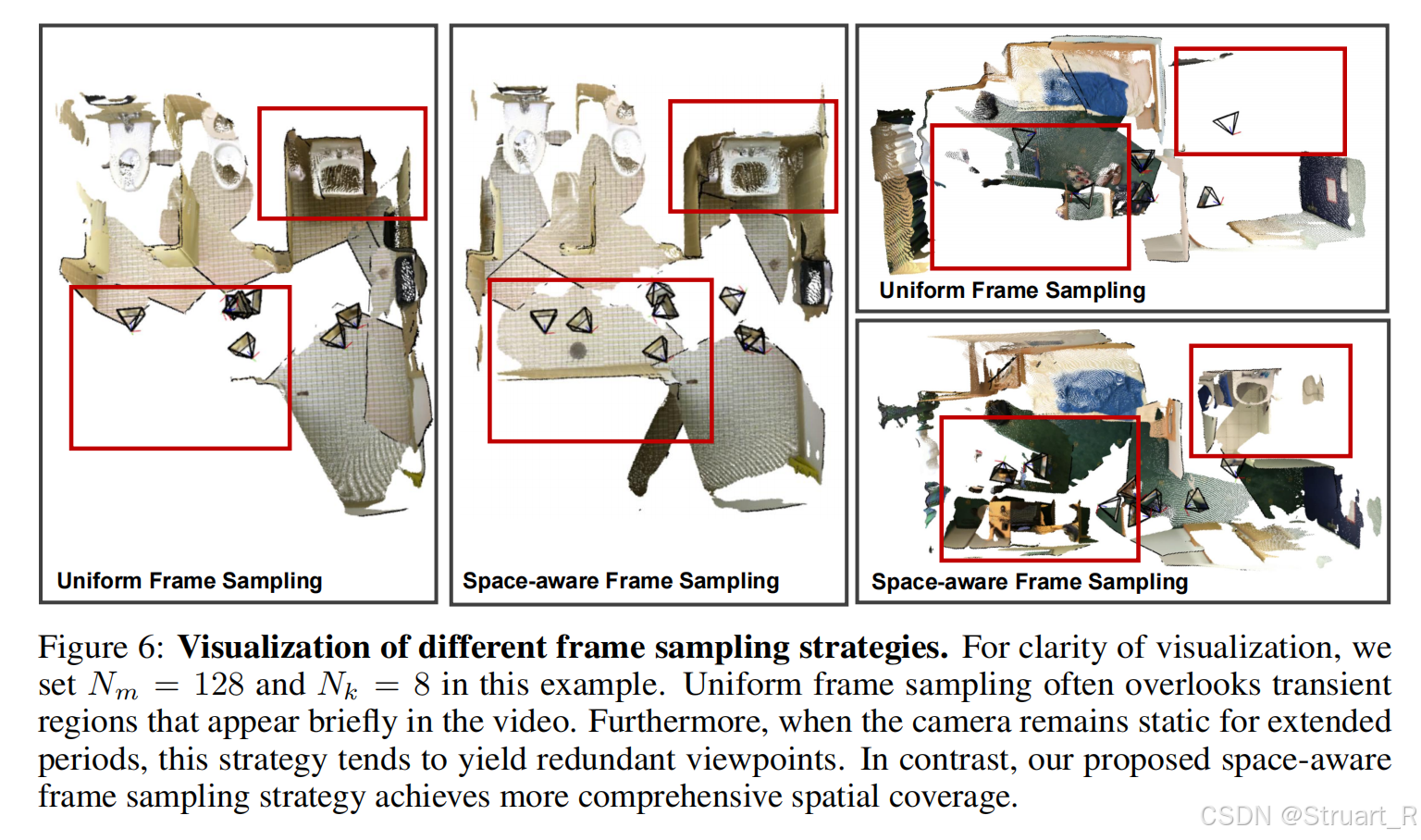
空间感知帧采样
首先因为推理过程中,如果输入一整个视频帧来进行编码是很耗费存储的,显存也会发生爆炸,同时我们也知道视频中包含大量的冗余帧,然而以往的均匀采样方式可能会忽略短暂出现的关键视角信息。
所以这里提出利用VGGT的空间编码特征,建模一个最大覆盖问题,找到最适合的帧数。目的是找到最优的,最大覆盖的帧,保证
帧下能覆盖最大的区域。
目标:定义,最优帧的集合也就是
。同样均匀采样128帧作为候选集合,
,候选集
,目的是从128帧中选出最优的16帧来最大覆盖这128帧的信息。
具体来说,
提取3D几何特征,利用VGGT的预训练空间编码器机器预训练头(深度头和相机参数头
),对每一帧候选帧,生成相机参数和深度图信息。其中
和
为空间编码器输出的中间特征。
点云重建与体素化,将深度图反投影到点云,每个像素对应一个3D点,其中代表像素坐标。
当然从深度头中,对于每个值都可以获得一个置信度,对应到点云的点上就是,之后采用有效点过滤,保留置信度大于0.1的点,组成有效点集
。
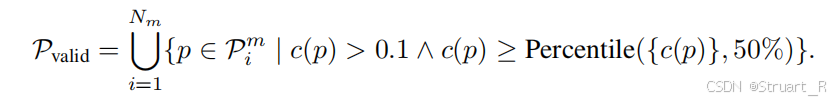
自适应体素划分,根据场景尺度动态设置体素大小,将场景包围盒的最小维度划分为20份,
。
帧覆盖计算,利用规定好的体素大小,将点云离散化为体素集合
。
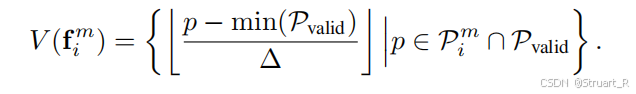
贪心最大覆盖,选择16帧,最大化总覆盖体素,输出S作为关键帧索引。
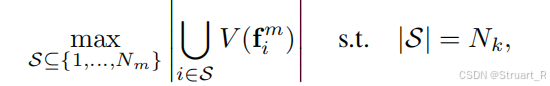
3、训练过程
数据集
全部基于ScanNet训练集的室内场景,问答数据来自ScanQA,SQA3D,以及新增70KQA对的自建数据,覆盖7类空间任务。总共QA120K样本,每个样本为四元组,为问题,答案,视频ID,任务类型。
由于ScanNet原始场景为RGB-D数据,所以转换为24FPS连续视频,并丢弃低质量帧,排除评估集场景(312个VSI-Bench测试场景)。
7类空间推理问题包括,物体计数,物体尺寸,房间尺寸,绝对距离,相对距离,相对方向,出现顺序。这个与VSI-Bench的空间问题十分相近
训练细节
训练过程分为SFT和GRPO两个阶段,均冻结空间编码器部分,监督训练SFT,采用标准交叉熵损失,训练1个epochs (7500steps),之后强化学习训练,先冷启动,用Qwen2.5-VL-72B生成CoT数据,筛选高奖励样本,之后利用GRPO训练每组采样8条推理路径,奖励函数包括数值型,多选型,文本型三种。
训练过程中限制视频640x480,16frames。训练过程不用空间帧采样啊,注意!
推理过程中采用内空间帧采样策略。
4、实验
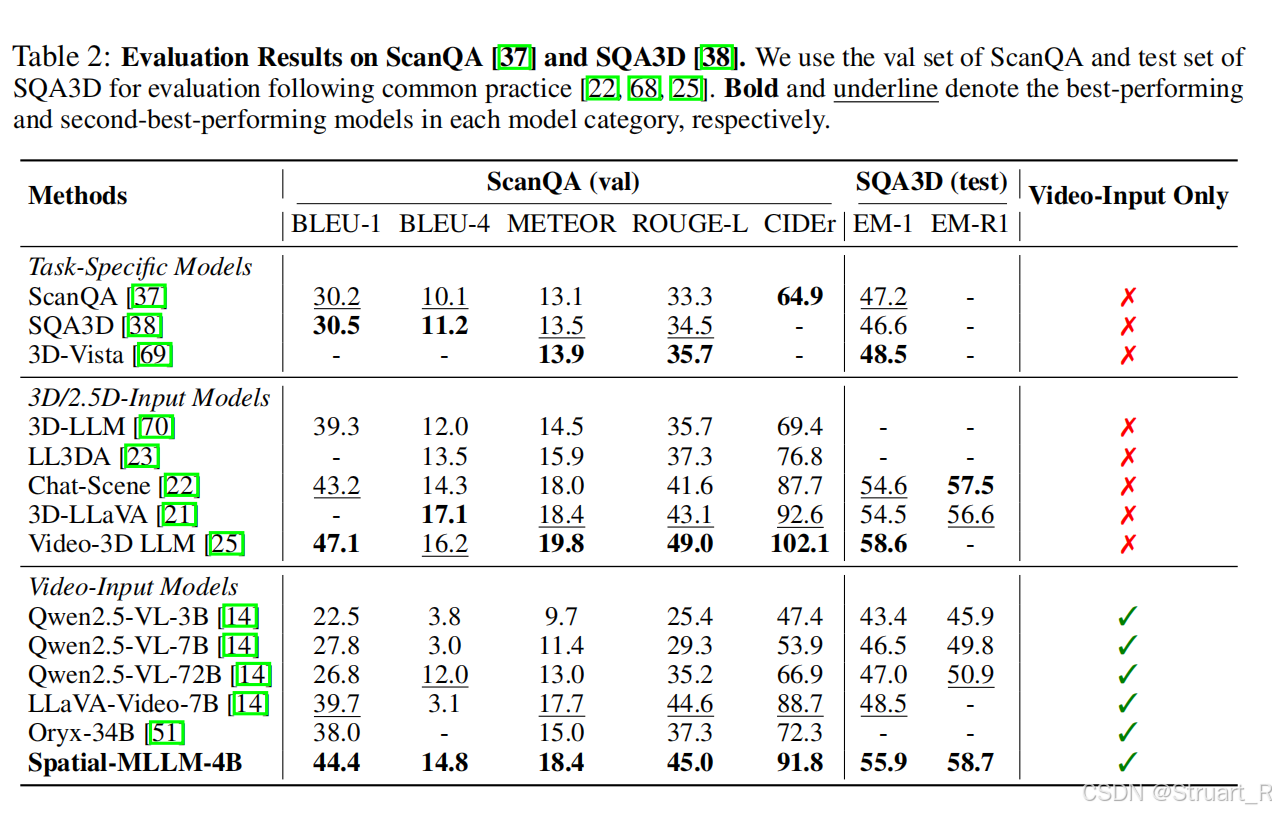
在ScanQA和SQA中对于仅视频输入的模型达到SOTA。基于ScanNet的任务,这相当于保留了原有的ScanQA和SQA数据特性。
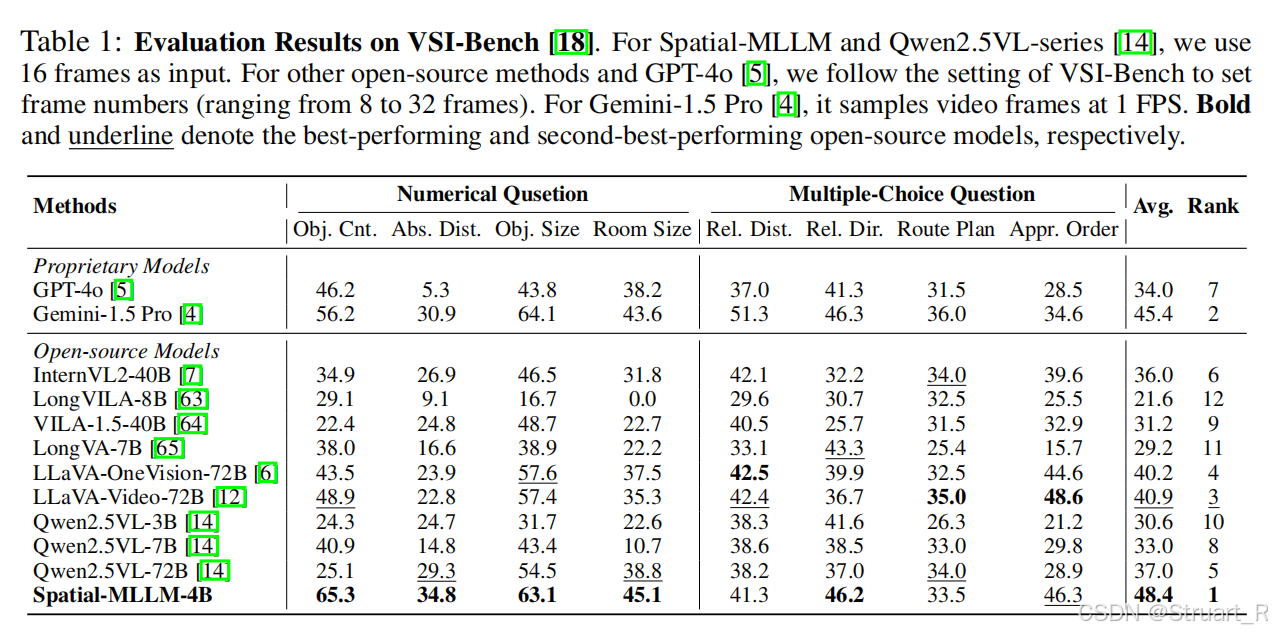
VSI-Bench上评估多模态大模型的空间理解能力上达到SOTA,这也与数据集中添加了7类任务密切相关。相当于按着这几个任务做的类似数据集。
参考论文:
[2503.13111] MM-Spatial: Exploring 3D Spatial Understanding in Multimodal LLMs
[2505.23747] Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence