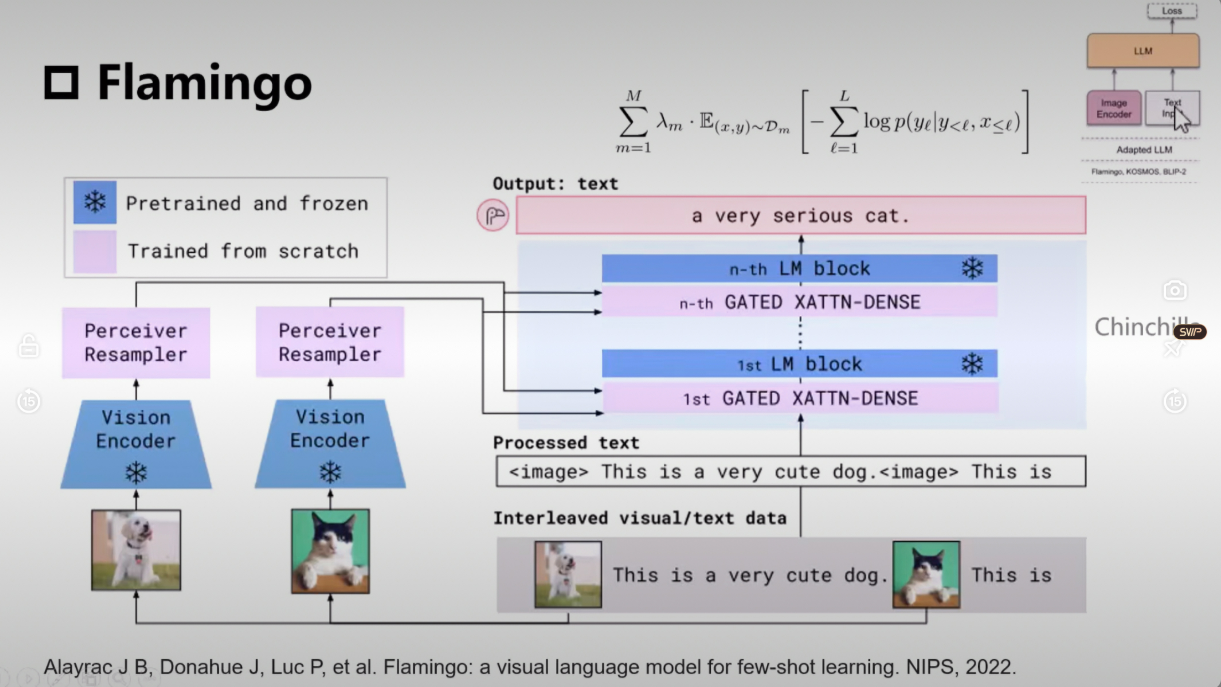
Flamingo
网络结构
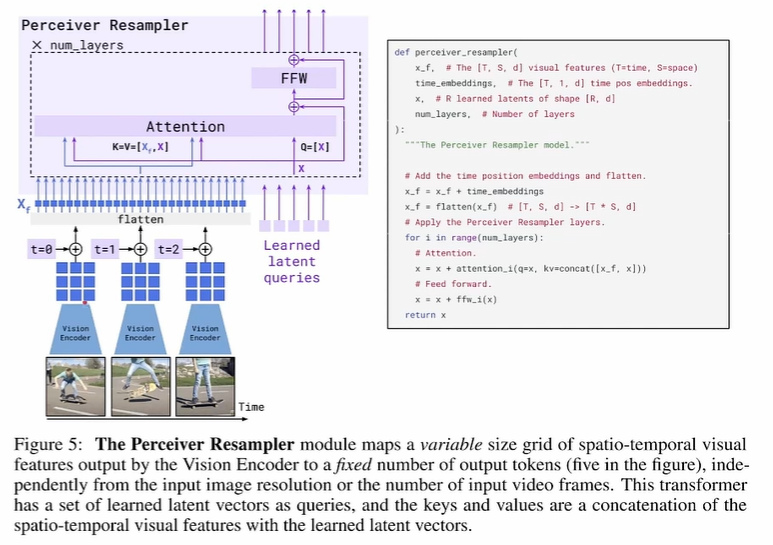
- Perceiver Resampler 感知重采样器
图像特征经过 encoder之后得到的embedding维度比较大, 如果直接和 text embedding做 cross attention, 会计算量爆炸, 所以这里通过 引入一个低维的 可学习queries, 从视觉的embedding中学习视觉信息,得到一个比较短的视觉token (可学习queries) 。 将高维视觉特征(如 196 个图像 patch)压缩为固定数量的视觉标记(如 64 个)
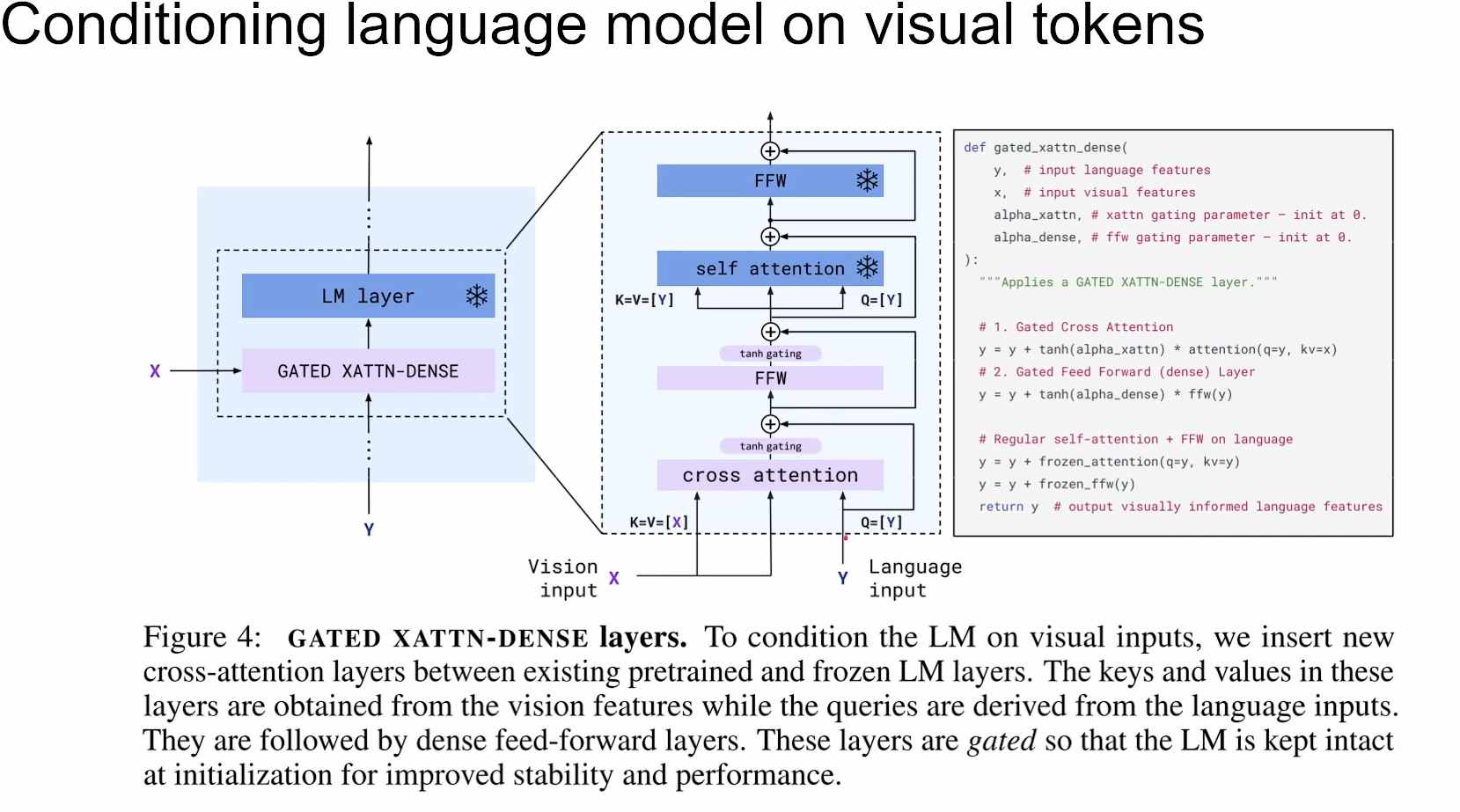
- 门控注意力
把学习到的视觉token 怎么融合到 语言模型中呢? 因为LLM是冻住不训练的,所以得像个办法讲视觉token融合语言模型中,这里采用了一个门控的 Cross Attention, 即用一个 tanh函数, 把Cross Attention的输出乘以 tanh(α), 其中α是一个可学习的参数,初始化为0, 再此基础上进行残差连接,一步步慢慢融合视觉信息。
参考:https://www.bilibili.com/video/BV1pu411G7ce/?spm_id_from=333.337.search-card.all.click&vd_source=a671b6c09bdc87f50b8d9fbbf85c6245