【大模型应用开发 3.RAG技术应用与Faiss向量数据库】
目录
一、大模型应用开发的三种模式
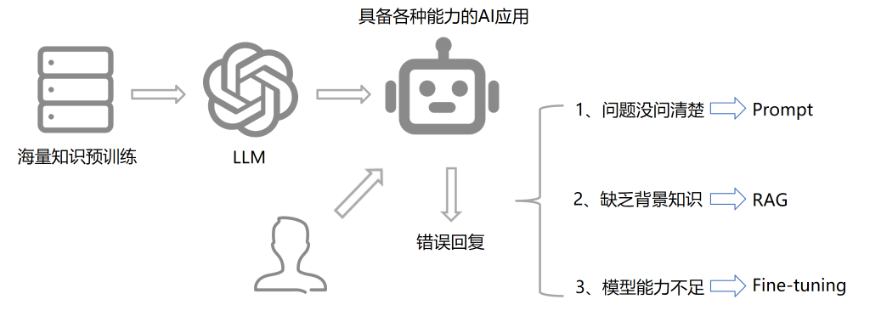
1.Prompt、RAG、Fine-tuning什么时候使用?
Ⅰ、问题没问清楚 —> Prompt
Ⅱ、缺乏背景知识 —> RAG
Ⅲ、模型能力不足 —> Fine-tuning
二、什么是RAG
1.RAG的优势是什么?
2.RAG的核心原理和流程
① Step1:数据预处理,构建索引库
② Step2:检索阶段
③ Step3:生成阶段
三、NativeRAG
四、基于LangChain框架快速搭建本地知识库检索
1.搭建流程
2.安装必要库
3.从PDF中提取文本并记录每行文本对应的页码函数
4.处理文本并创建Faiss向量存储
5.从磁盘加载向量数据库和页码信息函数
6.调用函数处理并保存
7.查询方式1
8.查询方式2
9.整体代码🚀
代码运行流程
编辑
小结:
Ⅰ、PDF文本提取与处理
Ⅱ、向量数据库构建
Ⅲ、语义搜索与问答链
Ⅳ、成本跟踪与结果展示
五、三大有效提升RAG质量方法
1.数据准备阶段
Ⅰ、常见问题
Ⅱ、如何提升数据准备阶段的质量
① 构建完整的数据准备流程【数据质量部】
1.数据评估与分类
2.数据清洗
3.敏感信息处理
4.数据标记与标注
5.数据治理框架
② 智能文档技术【复杂文档处理】
2.知识检索阶段
Ⅰ、常见问题
Ⅱ、如何提升知识检索阶段的质量
① 通过查询转换澄清用户意图
② 混合检索的重排策略
3.答案生成阶段
Ⅰ、常见问题
Ⅱ、如何提升答案生成阶段的质量
① 改进提示词模板
② 实施动态防护栏
六、RAG在不同阶段提升质量的实践
七、反思
—— 25.8.11
一、大模型应用开发的三种模式
1.Prompt、RAG、Fine-tuning什么时候使用?
Ⅰ、问题没问清楚 —> Prompt
当用户提问存在 表述模糊、信息缺失(如缺少上下文、目标边界不明) 等问题时,可通过 Prompt 工程 优化,即通过设计更精准的指令(如明确任务类型、补充约束条件)、插入示例引导(Few-Shot Prompting)、规范输出格式等策略,帮助模型理解问题核心,从而输出更贴合需求的结果。
Ⅱ、缺乏背景知识 —> RAG
若模型因 训练数据滞后(如未涵盖实时信息)、领域知识空白(如小众行业知识) 无法深入回答,可采用 检索增强生成(RAG) 方案,即先通过向量数据库等工具,从外部知识库(文档、知识库、互联网等)实时检索与问题相关的背景信息,再将这些信息嵌入 Prompt 中喂给模型,让模型基于 “外部知识 + 自身能力” 生成回答,突破固有知识边界。
Ⅲ、模型能力不足 —> Fine-tuning
当模型在 特定任务(如医疗问诊、法律合同分析)中表现薄弱(因预训练的通用能力无法适配专业场景),可通过 微调(Fine-tuning) 提升,即使用领域内的标注数据(如医疗问答对、法律文本分类数据),对模型参数进行针对性更新,强化其在该任务上的推理、分类、生成等核心能力,让模型更 “擅长” 处理细分场景的问题。
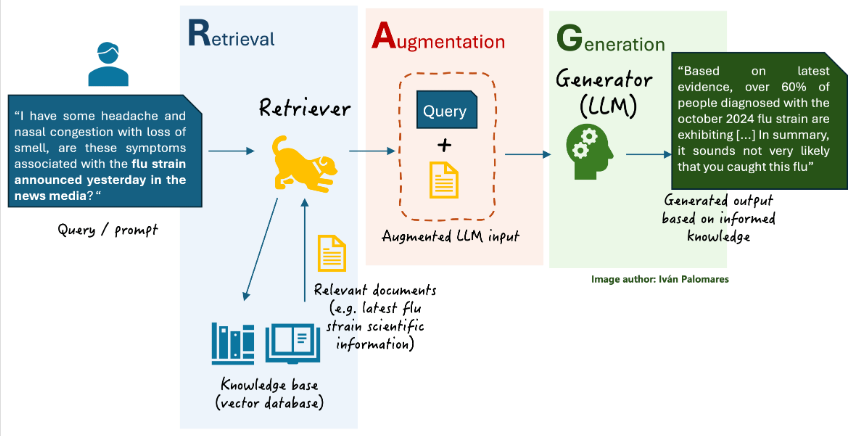
二、什么是RAG
RAG(Retrieval Augmented Generation)
检索增强生成,是一种结合信息检索(Retrieval)和文本生成(Generation)的技术
RAG技术通过实时检索相关文档或信息,并将其作为上下文输入到生成模型中,从而提高生成结果的时效性和准确性。
RAG大致流程:
① 用户编写prompt提出query —>
② 先在本地知识库中做一个检索,检索到与这个问题相关的知识片段 —>
③ 然后将检索到的知识片段和用户的query一起打包合并成一个新的Prompt,送给大模型进行回答 —>
④ 我们的大语言模型基于用户query和检索到的知识片段进行回答
1.RAG的优势是什么?
① 解决知识时效性问题:大模型的训练数据通常是静态的,无法涵盖最新信息,而RAG可以检索外部知识库实时更新信息
② 减少模型幻觉:通过引入外部知识,RAG能够减少模型生成虚假或不准确内容的可能性
③ 提升专业领域回答质量:RAG能够结合垂直领域的专业知识库,生成更具专业深度的回答
④ 生成内容的溯源【可解释性】
2.RAG的核心原理和流程
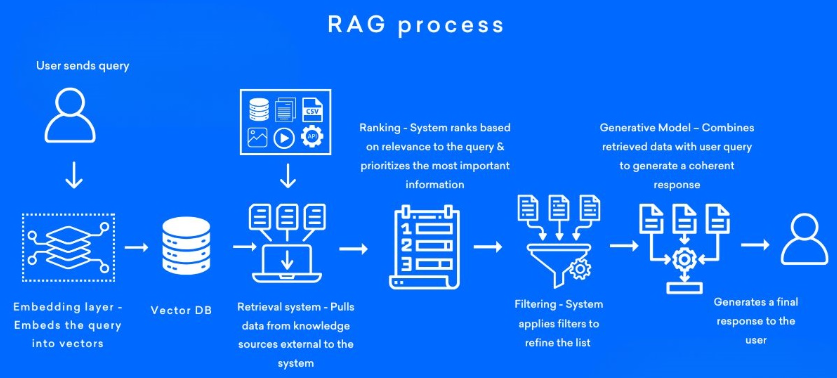
① Step1:数据预处理,构建索引库
-
知识库构建:收集并整理文档、网页、数据库等多源数据,构建外部知识库
-
文档分块:将文档切分为适当大小的片段(chunks),以便后续检索。分块策略需要在语义完整性与检索效率之间取得平衡
-
向量化处理:使用嵌入模型(如BGE、M3E、Chinese-Alpaca-2等)将文本块转换为向量,并存储在向量数据库中
② Step2:检索阶段
-
查询处理:将用户输入的问题转换为向量,并在向量数据库中进行相似度检索,找到最相关的文本片段
-
重排序:对检索结果进行相关性排序,选择最相关的片段作为生成阶段的输入
③ Step3:生成阶段
-
上下文组装:将检索到的文本片段与用户问题结合,形成增强的上下文输入
-
生成回答:大语言模型基于增强的上下文生成最终回答
RAG的本质就是结合知识片段构建一个新的Prompt
三、NativeRAG
⭐NativeRAG的实现步骤(基于文本):
Indexing 索引 => 如何更好地把知识存起来。
文档加载:将企业内部的私有化数据(语料:非结构化数据)进行清洗
数据质量部
使用智能文档技术来解析成为结构化数据
文档切片:不同需求场景,选择不同的切片策略进行切分
TextSpliter:文本切割
Chunk_size控制单个文本块的最大长度进行切割
Chunk_Overloap控制相邻文本块的重叠部分进行切割
文本向量化:选择一个合适的向量模型
BGE系列、阿里百炼:textEmbedding-v1/v2/v3
向量存储:
Chroma:数据量及访问量适中选择,使用简单,维护成本低,典型场景:原型开发、小规模 RAG、快速验证
Milvus:数据量及访问量较大选择,需要考虑企业高并发场景(K8s)分布式部署,维护成本高,典型场景:生产环境、大规模 RAG、高并发检索
Faiss-cpu/gpu:高性能向量检索算法库,典型场景:高性能检索场景(如推荐、图像检索),需搭配其他存储
Retrieval 检索 => 如何在大量的知识中,找到一小部分有用的,给到模型参考。
- 使用多路召回策略(混合检索)
- 向量检索(通过向量度量比较语义相似度)
- 关键字检索(BM25算法)
- 对召回的文档进行重排序(Rerank模型)
Generation 生成 => 如何结合用户的提问和检索到的知识,让模型生成有用的答案。
上下文利用率
一个重要结论:知识库中3-6个文档是比较合适的
LLM模型如何精确的提炼知识
四、基于LangChain框架快速搭建本地知识库检索
1.搭建流程
① 文档加载,并按一定条件切割成片段
② 将切割的文本片段灌入检索引擎
③ 封装检索接口
④ 构建调用流程:Query —> 检索 —> Prompt —> LLM —> 回复
2.安装必要库
清华园安装:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
pypdf2库:一个轻量级的 PDF 文件处理库,专注于 PDF 的读取、解析和基础操作。
- 提取 PDF 中的文本内容(支持分页提取);
- 合并、分割、旋转 PDF 页面;
- 加密 / 解密 PDF 文件,添加水印等基础编辑。
dashscope库:阿里云官方推出的大模型服务开发工具包(SDK),用于对接阿里云的通义千问等大模型。
- 调用通义千问系列模型(如 qwen-7b、qwen-plus)进行文本生成、对话交互;
- 使用阿里云的嵌入模型(如 text-embedding-v1)生成文本向量;
- 集成阿里云的其他 AI 能力(如图片生成、语音处理等)。
langchain库:一个用于构建大语言模型(LLM)应用的开发框架,提供模块化组件和链式调用能力。
- 整合 LLM(如 GPT、通义千问)、向量数据库、工具(如搜索引擎、API)等组件;
- 实现复杂逻辑(如 RAG 检索增强生成、智能代理 Agent、多步对话流程);
- 简化 LLM 应用的开发流程(如提示词管理、记忆机制、输出解析)。
langchain-openai库:langchain的官方扩展包,专门用于对接 OpenAI 的模型和服务。
- 在
langchain框架中调用 OpenAI 的 GPT 系列模型(如 gpt-3.5-turbo、gpt-4); - 使用 OpenAI 的嵌入模型(如 text-embedding-ada-002)生成向量;
- 集成 OpenAI 的其他功能(如函数调用、Moderation API 内容审核)。
langchain-community库:langchain的社区贡献版,包含大量第三方工具、模型和集成组件。
- 对接非官方或社区支持的模型(如 Anthropic Claude、谷歌 Gemini、开源模型 LLaMA);
- 集成各种向量数据库(如 Milvus、Chroma、Pinecone)、数据库(MySQL、MongoDB);
- 连接外部工具(如维基百科、GitHub、Slack、计算器等)。
faiss-cpu库:Facebook 推出的高效向量检索库(CPU 版本),用于大规模向量的相似度搜索和聚类。
- 在 RAG 等场景中,快速检索与查询向量最相似的文档向量;
- 处理百万级甚至亿级向量数据,支持多种相似度计算(如欧氏距离、余弦相似度);
- 作为向量数据库的底层检索引擎,提升检索效率。
3.从PDF中提取文本并记录每行文本对应的页码函数
pdf:不是原始的 PDF 文件路径(字符串),也不是二进制文件流,而是通过 PDF 处理库(如 PyPDF2、pdfplumber、PyMuPDF 等)打开并解析后得到的 “文件对象”。
text:字符串类型,用于累积存储从 PDF 中提取的所有文本内容(所有页面的文本拼接而成)
page_numbers:列表类型,每个元素是整数,对应 text 中每行文本的原始页码(例如:text 第 3 行对应 page_numbers[2])。
page_number:整数类型,当前遍历的 PDF 页码(从 1 开始计数),表示正在处理的是 PDF 的第几页。
page:页面对象,来自 pdf.pages 集合中的元素,代表 PDF 中的一页,通过它可调用 extract_text() 方法提取该页文本。
pdf.pages:PDF 文件对象的属性,是一个可迭代的集合,包含 PDF 中所有页面对象(每个元素对应一页)。
extracted_text:字符串类型,通过 page.extract_text() 从当前页(page)提取的文本内容;若页面无文本(如图片页),则为 None 或空字符串。
enumrate():Python 内置函数,用于遍历可迭代对象(如列表、集合、pdf.pages 等)时,同时返回元素的索引(计数) 和元素本身。在 PDF 文本提取场景中,常用于获取每页的页码(从指定数值开始计数)。
| 参数名 | 作用说明 | 是否必填 | 默认值 |
|---|---|---|---|
iterable | 待遍历的可迭代对象(如 pdf.pages、列表、元组等),需支持迭代。 | 是 | 无 |
start | 索引的起始值(计数从该值开始)。例如 start=1 时,首个元素索引为 1。 | 否 | 0 |
page.extract_text():PDF 页面对象(page)的核心方法,用于提取当前页的文本内容。不同 PDF 处理库(如 PyPDF2、pdfplumber)均实现此方法,返回值为字符串(提取的文本)或 None(若页面无文本,如图片页、空白页)。
列表.extend():Python 列表的内置方法,用于将另一个可迭代对象(如列表、元组、字符串)的所有元素添加到当前列表的末尾,实现列表的扩展。与 列表.append() 不同,它会 “打散” 可迭代对象并添加元素,而非整体添加。
| 参数名 | 作用说明 | 是否必填 | 默认值 |
|---|---|---|---|
iterable | 待添加到列表的可迭代对象(如列表、元组、字符串等),其元素会被逐个添加到当前列表。 | 是 | 无 |
str.split():Python 字符串的内置方法,用于按指定分隔符将字符串分割为列表。默认按空白字符(空格、换行符 \n、制表符 \t 等)分割,可通过参数自定义分隔符和分割次数。
| 参数名 | 作用说明 | 是否必填 | 默认值 |
|---|---|---|---|
sep | 分割符(字符串)。若为 None,则按任意空白字符(空格、\n、\t 等)分割。 | 否 | None |
maxsplit | 最大分割次数。-1 表示无限制(全部分割);n 表示只分割前 n 次,剩余内容作为最后一个元素。 | 否 | -1 |
logging.warning():Python logging 模块的方法,用于输出警告级别的日志信息。警告日志表示程序运行中出现了潜在问题(如 PDF 某页无文本),但不会中断程序执行,常用于调试和问题追踪。
| 参数名 | 作用说明 | 是否必填 | 默认值 |
|---|---|---|---|
msg | 警告信息的字符串(支持格式化,如 f"No text on page {page_number}")。 | 是 | 无 |
*args | 用于格式化 msg 的可变参数(如 msg="Page %d" % args 中的动态值)。 | 否 | 无 |
** kwargs | 其他可选参数(如 exc_info=True 强制输出异常堆栈信息,stack_info=True 输出堆栈上下文)。 | 否 | 无 |
def extract_text_with_page_numbers(pdf) -> Tuple[str, List[int]]:"""从PDF中提取文本并记录每行文本对应的页码参数:pdf: PDF文件对象返回:text: 提取的文本内容page_numbers: 每行文本对应的页码列表"""text = ""page_numbers = []for page_number, page in enumerate(pdf.pages, start=1):extracted_text = page.extract_text()if extracted_text:text += extracted_textpage_numbers.extend([page_number] * len(extracted_text.split("\n")))else:logging.warning(f"No text found on page {page_number}.")return text, page_numbers4.处理文本并创建Faiss向量存储
text:需要进行处理的原始文本内容,通常是从文档(如 PDF、TXT 等)中提取的完整文本字符串,是后续分割和向量转换的输入源。
page_numbers:与text中每行文本对应的页码列表。例如,若text的第 1 行来自文档第 3 页,第 2 行来自文档第 3 页,第 3 行来自文档第 4 页,则page_numbers可能为[3, 3, 4],用于后续记录每个文本块的原始页码位置。
save_path:向量数据库和页码信息的保存路径。若提供该参数,函数会将生成的 FAISS 向量存储和页码信息文件保存到该路径下;若为None,则不保存,仅返回内存中的向量存储对象。
text_splitter:文本分割器实例,用于将长文本text按照指定规则(如分隔符、块大小等)分割成多个短文本块(chunks),便于后续向量转换和检索。
RecursiveCharacterTextSplitter():创建一个递归字符文本分割器,用于将长文本按照多层级分隔符(如段落、句子、单词等)分割为指定大小的短文本块。分割逻辑是从优先级高的分隔符开始尝试,若无法分割到指定大小,则使用下一优先级的分隔符,以此类推,尽量保持文本的语义完整性。
| 参数名 | 类型 | 说明 |
|---|---|---|
| separators | List[str] | 分割文本的分隔符列表,按优先级从高到低排列(例如 ["\n\n", "\n", ".", " "] 表示先按空行分割,再按换行分割等) |
| chunk_size | int | 每个文本块的最大长度(单位:字符数) |
| chunk_overlap | int | 相邻文本块的重叠长度(单位:字符数),用于保留上下文连续性 |
| length_function | Callable | 计算文本长度的函数(默认使用 len 函数,即按字符数计算长度) |
chunks:text经过text_splitter.split_text(text)处理后得到的文本块列表。每个元素是一个较短的文本片段,长度由chunk_size控制,用于后续生成向量。
text_splitter.split_text():RecursiveCharacterTextSplitter 实例的方法,用于实际执行文本分割操作。根据分割器的配置(分隔符、块大小等),将输入的长文本拆分为多个短文本块,返回文本块列表。
| 参数名 | 类型 | 说明 |
|---|---|---|
| text | str | 需要分割的原始长文本 |
embeddings:文本嵌入模型实例,用于将文本块(chunks)转换为数值向量(嵌入向量),以便通过向量相似度进行检索。这里使用的是阿里百炼平台的text-embedding-v2模型。
DashScopeEmbeddings():创建阿里百炼(DashScope)平台的文本嵌入模型实例,用于将文本转换为数值向量(嵌入向量)。该模型通过调用百炼平台的 API 实现文本向量化,生成的向量可用于后续的相似度计算或检索。
| 参数名 | 类型 | 说明 |
|---|---|---|
| model | str | 嵌入模型的名称(例如 text-embedding-v2,指定使用的百炼模型) |
| dashscope_api_key | str | 阿里百炼平台的 API 密钥,用于 API 调用的身份验证(通常从环境变量获取) |
knowledgeBase:基于 FAISS 库的向量存储对象,包含chunks中所有文本块的嵌入向量,支持高效的向量相似度搜索,是后续知识库检索的核心对象。
FAISS.from_texts():FAISS(Facebook AI Similarity Search)库的静态方法,用于从文本列表创建向量存储对象。内部会通过指定的嵌入模型将每个文本转换为向量,并构建 FAISS 索引,最终返回可用于高效向量检索的 FAISS 对象。
| 参数名 | 类型 | 说明 |
|---|---|---|
| texts | List[str] | 需要转换为向量的文本块列表(如分割后的 chunks) |
| embedding | 嵌入模型实例 | 用于将文本转换为向量的嵌入模型(如 DashScopeEmbeddings 实例) |
page_info:Dict[str, int],记录每个文本块对应页码的字典。键为文本块(chunk),值为该文本块对应的页码(来自page_numbers),用于后续查询时返回结果的原始页码信息。
knowledgeBase.page_info:动态为knowledgeBase对象添加的属性,用于存储page_info字典,使向量存储对象与页码信息关联,方便后续获取文本块对应的页码。
os.makedirs():Python 标准库 os 中的函数,用于递归创建目录(即若目标目录的父目录不存在,会自动创建父目录)。常用于确保文件保存路径的目录结构存在,避免因目录不存在导致的写入错误。
| 参数名 | 类型 | 说明 |
|---|---|---|
| name | str | 要创建的目录路径(可以是多级目录,例如 ./data/faiss_db) |
| exist_ok | bool | 若为 True,则当目录已存在时不抛出异常;默认值为 False(实际使用中常设为 True 避免报错) |
knowledgeBase.save_local():FAISS 向量存储对象的方法,用于将向量数据库(包括文本块对应的向量索引、原始文本等信息)保存到本地文件系统,以便后续加载复用,避免重复计算向量。
| 参数名 | 类型 | 说明 |
|---|---|---|
| folder | str | 保存向量数据库的目录路径 |
open():Python 内置函数,用于打开文件并返回文件对象,支持对文件进行读写操作。根据不同的打开模式(如读、写、二进制模式等),可实现文件内容的读取或写入。
| 参数名 | 类型 | 说明 |
|---|---|---|
| file | str | 要打开的文件路径(例如 ./page_info.pkl) |
| mode | str | 打开文件的模式(例如 r 表示只读,w 表示写入,wb 表示二进制写入,a 表示追加等) |
| buffering | int | 缓冲策略(可选,默认值为 -1,表示使用系统默认缓冲) |
pickle.dump():Python 标准库 pickle 中的函数,用于将 Python 对象(如字典、列表等)序列化(转换为字节流)并写入文件,便于将对象持久化存储到本地,后续可通过 pickle.load() 恢复对象。
| 参数名 | 类型 | 说明 |
|---|---|---|
| obj | 任意 Python 对象 | 需要序列化的对象(例如记录页码信息的 page_info 字典) |
| file | 文件对象 | 写入序列化数据的文件对象(即 open() 函数返回的对象) |
os.path.join():Python 标准库 os.path 中的函数,用于拼接多个路径组件,生成符合当前操作系统(如 Windows、Linux)路径格式的完整路径字符串,自动处理路径分隔符(如 / 或 \)。
| 参数名 | 类型 | 说明 |
|---|---|---|
| *paths | str | 可变参数,需要拼接的路径组件(例如 save_path 和 page_info.pkl,拼接后为 save_path/page_info.pkl) |
def process_text_with_splitter(text: str, page_numbers: List[int], save_path: str = None) -> FAISS:"""处理文本并创建向量存储参数:text: 提取的文本内容page_numbers: 每行文本对应的页码列表save_path: 可选,保存向量数据库的路径返回:knowledgeBase: 基于FAISS的向量存储对象"""# 创建文本分割器,用于将长文本分割成小块text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", ".", " ", ""],chunk_size=512,chunk_overlap=128,length_function=len,)# 分割文本chunks = text_splitter.split_text(text)# logging.debug(f"Text split into {len(chunks)} chunks.")print(f"文本被分割成 {len(chunks)} 个块。")# 创建嵌入模型,OpenAI嵌入模型,配置环境变量 OPENAI_API_KEY# embeddings = OpenAIEmbeddings()# 调用阿里百炼平台文本嵌入模型,配置环境变量 DASHSCOPE_API_KEYembeddings = DashScopeEmbeddings(model="text-embedding-v2",dashscope_api_key=os.getenv("BAILIAN_API_KEY"))# 从文本块创建知识库knowledgeBase = FAISS.from_texts(chunks, embeddings)print("已从文本块创建知识库...")# 存储每个文本块对应的页码信息page_info = {chunk: page_numbers[i] for i, chunk in enumerate(chunks)}knowledgeBase.page_info = page_info# 如果提供了保存路径,则保存向量数据库和页码信息if save_path:# 确保目录存在os.makedirs(save_path, exist_ok=True)# 保存FAISS向量数据库knowledgeBase.save_local(save_path)print(f"向量数据库已保存到: {save_path}")# 保存页码信息到同一目录with open(os.path.join(save_path, "page_info.pkl"), "wb") as f:pickle.dump(page_info, f)print(f"页码信息已保存到: {os.path.join(save_path, 'page_info.pkl')}")return knowledgeBase5.从磁盘加载向量数据库和页码信息函数
load_path:向量数据库在磁盘上的保存路径(目录路径),用于指定从哪里加载之前保存的 FAISS 向量存储和页码信息文件。
embeddings:用于文本向量化的嵌入模型。若传入已实例化的模型,则加载向量数据库时复用该模型;若为None,函数会自动创建一个阿里百炼平台的DashScopeEmbeddings实例(使用text-embedding-v2模型),确保向量数据库加载时的嵌入模型与保存时一致。
DashScopeEmbeddings():创建阿里百炼(DashScope)平台的文本嵌入模型实例,用于将文本转换为数值向量(嵌入向量)。该模型通过调用百炼平台的 API 实现文本向量化,生成的向量可用于相似度计算或检索,确保与保存向量时使用的模型一致。
| 参数名 | 类型 | 说明 |
|---|---|---|
| model | str | 嵌入模型名称(例如 text-embedding-v2,指定使用的百炼模型) |
| dashscope_api_key | str | 阿里百炼平台的 API 密钥,用于 API 调用身份验证(通常从环境变量获取) |
os.getenv():Python 标准库 os 中的函数,用于获取环境变量的值。若环境变量不存在,可返回指定的默认值(若未指定则返回 None)。常用于安全获取 API 密钥等敏感信息,避免硬编码。
| 参数名 | 类型 | 说明 |
|---|---|---|
| key | str | 环境变量的名称(例如 BAILIAN_API_KEY) |
| default | 任意类型(可选) | 当环境变量不存在时返回的默认值(默认值为 None) |
knowledgeBase:从load_path路径加载的向量存储对象,包含之前保存的文本块向量索引、原始文本等信息,可直接用于后续的向量相似度检索。
Faiss.load_local():FAISS 库的方法,用于从本地磁盘加载之前保存的 FAISS 向量数据库。需要与保存时使用的嵌入模型匹配,以确保向量格式一致,支持后续检索操作。
| 参数名 | 类型 | 说明 |
|---|---|---|
| folder_path | str | 向量数据库的保存目录路径(即 load_path) |
| embeddings | 嵌入模型实例 | 与保存时一致的嵌入模型(如 DashScopeEmbeddings 实例) |
| allow_dangerous_deserialization | bool(可选) | 是否允许反序列化(加载时需显式设为 True,因 FAISS 序列化可能包含代码,默认值为 False) |
page_info_path:页码信息文件的完整路径,由load_path与页码信息文件名(page_info.pkl)拼接而成(通过os.path.join()实现),用于定位并加载记录文本块对应页码的文件。
os.path.join():Python 标准库 os.path 中的函数,用于拼接多个路径组件,生成符合当前操作系统格式的完整路径字符串,自动处理路径分隔符(如 / 或 \)。
| 参数名 | 类型 | 说明 |
|---|---|---|
| *paths | str | 可变参数,需拼接的路径组件(如 load_path 和 page_info.pkl) |
os.path.exists():Python 标准库 os.path 中的函数,用于检查指定路径(文件或目录)是否存在,返回布尔值(True 表示存在,False 表示不存在)。常用于加载文件前验证文件是否存在,避免报错。
| 参数名 | 类型 | 说明 |
|---|---|---|
| path | str | 需要检查的路径字符串 |
open():Python 内置函数,用于打开文件并返回文件对象,支持对文件进行读写操作。加载页码信息时使用二进制读取模式("rb"),以配合 pickle.load() 反序列化对象。
| 参数名 | 类型 | 说明 |
|---|---|---|
| file | str | 要打开的文件路径(例如 page_info_path) |
| mode | str | 打开模式("rb" 表示二进制只读,用于读取序列化的 pkl 文件) |
| buffering | int | 缓冲策略(可选,默认值为 -1,表示使用系统默认缓冲) |
page_info:从page_info_path文件中加载的字典,键为文本块(chunk),值为该文本块对应的原始页码,与process_text_with_splitter函数中保存的page_info结构一致。
pickle.load():Python 标准库 pickle 中的函数,用于从打开的文件对象中反序列化数据,恢复之前通过 pickle.dump() 保存的 Python 对象(如 page_info 字典)。
| 参数名 | 类型 | 说明 |
|---|---|---|
| file | 文件对象 | 已打开的二进制读取模式文件对象(即 open() 返回的 f) |
knowledgeBase.page_info:动态为加载后的knowledgeBase对象添加的属性,用于存储加载的page_info字典,使向量存储对象与页码信息关联,方便后续查询时获取结果对应的原始页码。
def load_knowledge_base(load_path: str, embeddings=None) -> FAISS:"""从磁盘加载向量数据库和页码信息参数:load_path: 向量数据库的保存路径embeddings: 可选,嵌入模型。如果为None,将创建一个新的DashScopeEmbeddings实例返回:knowledgeBase: 加载的FAISS向量数据库对象"""# 如果没有提供嵌入模型,则创建一个新的if embeddings is None:embeddings = DashScopeEmbeddings(model="text-embedding-v2",dashscope_api_key=os.getenv("BAILIAN_API_KEY"))# 加载FAISS向量数据库,添加allow_dangerous_deserialization=True参数以允许反序列化knowledgeBase = FAISS.load_local(load_path, embeddings, allow_dangerous_deserialization=True)print(f"向量数据库已从 {load_path} 加载。")# 加载页码信息page_info_path = os.path.join(load_path, "page_info.pkl")if os.path.exists(page_info_path):with open(page_info_path, "rb") as f:page_info = pickle.load(f)knowledgeBase.page_info = page_infoprint("页码信息已加载。")else:print("警告: 未找到页码信息文件。")return knowledgeBase6.调用函数处理并保存
pdf_reader:通过 PdfReader() 初始化的 PDF 读取器对象,用于存储和访问目标 PDF 文件的内容信息(如页面数据、文本内容、元数据等)。通过该对象可以进一步从 PDF 中提取文本、获取页面数量等操作。
PdfReader():用于读取和解析 PDF 文件的类(通常来自 PyPDF2 库),其核心作用是加载指定的 PDF 文件并创建一个可操作的实例对象。通过该对象可以获取 PDF 的页面内容、文本信息、元数据(如标题、作者)等,是后续提取 PDF 文本、处理 PDF 内容的基础。
| 参数名 | 类型 | 说明 |
|---|---|---|
| stream | str / bytes / file | 必需参数。表示 PDF 文件的来源,可以是: - 字符串(PDF 文件的本地路径,如绝对路径或相对路径); - 字节流(二进制数据); - 类文件对象(已打开的文件流)。 |
| strict | bool | 可选参数,默认值为 True。控制是否以严格模式解析 PDF。若为 True,解析时遇到错误会抛出异常;若为 False,则会尝试忽略部分错误继续解析。 |
| password | str | 可选参数。若 PDF 文件被加密,需传入解密密码以正常读取内容。 |
extract_text_with_page_numbers():接收 PDF 文件对象,提取其中的文本内容并记录每行文本对应的页码,最终返回提取的文本和页码列表。
text:字符串类型,用于累积存储从 PDF 中提取的所有文本内容(所有页面的文本拼接而成)
page_numbers:列表类型,每个元素是整数,对应 text 中每行文本的原始页码(例如:text 第 3 行对应 page_numbers[2])。
process_text_with_splitter():接收文本内容、对应页码列表和可选保存路径,将文本分割为块后通过阿里百炼嵌入模型创建 FAISS 向量存储,关联各文本块的页码信息,若指定保存路径则保存向量数据库和页码信息,最终返回 FAISS 向量存储对象。
# 读取PDF文件
pdf_reader = PdfReader(r'F:\AI_BigModel\L1课件\第2章_RAG技术与应用/浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf')
# 提取文本和页码信息
text, page_numbers = extract_text_with_page_numbers(pdf_reader)
print(text)print(f"提取的文本长度: {len(text)} 个字符。")# 处理文本并创建知识库,同时保存到磁盘
save_dir = "./vector_db"
knowledgeBase = process_text_with_splitter(text, page_numbers, save_path=save_dir)# 处理文本并创建知识库
knowledgeBase = process_text_with_splitter(text, page_numbers)
print(knowledgeBase)7.查询方式1
query:用户提出的查询问题(如 “客户经理每年评聘申报时间是怎样的?”),是后续相似度搜索和问答生成的核心输入。
docs:通过知识库相似度搜索(knowledgeBase.similarity_search(query))返回的与query相关的文档块列表,包含从知识库中匹配到的文本片段。
knowledgeBase.similarity_search():FAISS 知识库对象的方法,用于根据用户查询(query)在知识库中搜索语义最相似的文档块,返回匹配的相关文档列表,作为回答的依据。
| 参数名 | 类型 | 说明 |
|---|---|---|
| query | str | 用户的查询问题(如 query 变量) |
| k | int(可选) | 要返回的最相似文档数量(默认值通常为 5,可根据需求调整) |
| filter | dict(可选) | 过滤条件(用于筛选特定文档,默认无过滤) |
chatLLM:初始化的对话大模型实例(这里使用阿里百炼兼容的deepseek-v3模型),用于基于相关文档生成对query的回答。
ChatOpenAI():LangChain 中用于初始化 OpenAI 兼容聊天模型的类,支持配置 API 密钥、基础 URL 和模型名称,用于生成自然语言回答(这里适配阿里百炼平台的模型)。
| 参数名 | 类型 | 说明 |
|---|---|---|
| api_key | str(可选) | API 调用的密钥(代码中从环境变量 BAILIAN_API_KEY 获取) |
| base_url | str(可选) | API 请求的基础 URL(代码中设为阿里百炼兼容地址 https://dashscope.aliyuncs.com/compatible-mode/v1) |
| model | str | 要使用的模型名称(代码中为 deepseek-v3) |
os.getenv():Python 标准库 os 中的函数,用于获取环境变量的值。若环境变量不存在,可返回指定的默认值,避免硬编码敏感信息(如 API 密钥)。
| 参数名 | 类型 | 说明 |
|---|---|---|
| key | str | 环境变量的名称(代码中为 BAILIAN_API_KEY) |
| default | 任意类型(可选) | 当环境变量不存在时返回的默认值(默认返回 None) |
chain:通过load_qa_chain加载的问答处理链,将chatLLM与指定的处理类型(chain_type="stuff")结合,用于整合相关文档和问题并生成回答。
load_qa_chain():LangChain 中的函数,用于加载问答处理链,将聊天模型(chatLLM)与指定的处理类型(chain_type)结合,实现基于相关文档回答用户问题的逻辑。
| 参数名 | 类型 | 说明 |
|---|---|---|
| llm | 聊天模型实例 | 用于生成回答的大模型实例(如 chatLLM) |
| chain_type | str | 问答链的处理类型(代码中为 "stuff",表示将所有相关文档合并后输入模型) |
| verbose | bool(可选) | 是否打印详细日志(默认 False) |
input_data:问答链的输入数据字典,包含 “相关文档列表”(input_documents: docs)和 “用户问题”(question: query),作为chain.invoke的输入参数。
get_openai_callback():LangChain 中的上下文管理器函数,用于跟踪 OpenAI 兼容 API(如阿里百炼)的调用成本,包括令牌(token)使用量、请求次数、费用等信息,便于成本监控。该函数通过上下文管理器(with 语句)使用,无需传入参数
response:问答链执行(chain.invoke)后返回的结果对象,其中response["output_text"]存储生成的最终回答文本。
chain.invoke():LangChain 中 Chain 对象的方法,用于执行问答链的核心逻辑,接收输入数据并生成输出结果。将用户问题与相关文档结合,通过大模型生成回答。
| 参数名 | 类型 | 说明 |
|---|---|---|
| input | dict | 问答链的输入数据字典,需包含 input_documents(相关文档)和 question(用户问题) |
| config | dict(可选) | 执行配置参数(如超时时间、回调函数等,默认可省略) |
unique_pages:用于存储查询结果来源的唯一页码集合,通过去重避免重复显示同一页码,确保来源页码的唯一性。
set():Python 内置函数,用于创建一个空集合或从可迭代对象(如列表、字符串)创建集合。集合中的元素具有唯一性(自动去重),且无序。
| 参数名 | 类型 | 说明 |
|---|---|---|
| iterable | 可迭代对象(可选) | 用于初始化集合的可迭代对象(如代码中未传入参数,创建空集合 unique_pages = set()) |
text_content:从搜索到的文档块(doc)中提取的具体文本内容(通过doc.page_content获取),用于在knowledgeBase.page_info中查找该文本块对应的原始页码。
getattr():Python 内置函数,用于动态获取对象的属性值。若属性不存在,可返回指定的默认值,避免直接访问不存在的属性时抛出异常。
| 参数名 | 类型 | 说明 |
|---|---|---|
| object | 任意对象 | 需要获取属性的对象(例如代码中的 doc) |
| name | str | 要获取的属性名称(例如代码中的 "page_content") |
| default | 任意类型(可选) | 当属性不存在时返回的默认值(若未指定,属性不存在则抛出 AttributeError) |
knowledgeBase.page_info.get():字典的内置方法,用于从 knowledgeBase.page_info 字典中根据键获取对应的值。若键不存在,可返回指定的默认值,避免直接访问不存在的键时抛出异常。
| 参数名 | 类型 | 说明 |
|---|---|---|
| key | 任意可哈希类型 | 要查找的键(例如代码中的 text_content.strip() 处理后的文本块) |
| default | 任意类型(可选) | 当键不存在时返回的默认值(代码中设为 "未知") |
str.strip():字符串的内置方法,用于去除字符串首尾的指定字符(默认去除空白字符,如空格、换行符 \n、制表符 \t 等),返回处理后的新字符串。
| 参数名 | 类型 | 说明 |
|---|---|---|
| chars | str(可选) | 要去除的字符集,若未指定,则默认去除所有空白字符(' \t\n\r\f\v') |
集合.add():集合(set)的内置方法,用于向集合中添加元素。若元素已存在于集合中,则不重复添加(保持集合元素的唯一性)。
| 参数名 | 类型 | 说明 |
|---|---|---|
| element | 任意可哈希类型 | 要添加到集合中的元素 |
# 设置查询问题
# query = "客户经理被投诉了,投诉一次扣多少分"
query = "客户经理每年评聘申报时间是怎样的?"
if query:# 执行相似度搜索,找到与查询相关的文档docs = knowledgeBase.similarity_search(query)# 初始化对话大模型chatLLM = ChatOpenAI(# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",api_key=os.getenv("BAILIAN_API_KEY"),base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",model="deepseek-v3")# 加载问答链chain = load_qa_chain(chatLLM, chain_type="stuff")# 准备输入数据input_data = {"input_documents": docs, "question": query}# 使用回调函数跟踪API调用成本with get_openai_callback() as cost:# 执行问答链response = chain.invoke(input=input_data)print(f"查询已处理。成本: {cost}")print(response["output_text"])print("来源:")# 记录唯一的页码unique_pages = set()# 显示每个文档块的来源页码for doc in docs:text_content = getattr(doc, "page_content", "")source_page = knowledgeBase.page_info.get(text_content.strip(), "未知")if source_page not in unique_pages:unique_pages.add(source_page)print(f"文本块页码: {source_page}")8.查询方式2
query:用户提出的查询问题,例如 "客户经理每年评聘申报时间是怎样的?"。是整个查询流程的输入核心,驱动后续的相似度搜索、文档整合和回答生成。
embeddings:文本嵌入模型实例。使用阿里百炼平台的 text-embedding-v2 模型,通过环境变量 BAILIAN_API_KEY 获取 API 密钥,用于将文本转换为向量。与加载向量数据库时的嵌入模型保持一致,确保向量格式兼容。
DashScopeEmbeddings():创建阿里百炼(DashScope)平台的文本嵌入模型实例,用于将文本转换为数值向量(嵌入向量)。该模型通过调用百炼平台的 API 实现文本向量化,生成的向量可用于相似度计算或检索,确保与保存向量时使用的模型一致。
| 参数名 | 类型 | 说明 |
|---|---|---|
| model | str | 嵌入模型名称(例如 text-embedding-v2,指定使用的百炼模型) |
| dashscope_api_key | str | 阿里百炼平台的 API 密钥,用于 API 调用身份验证(通常从环境变量获取) |
loaded_knowledgeBase:从磁盘路径 ./vector_db 加载的向量数据库对象。通过 load_knowledge_base 函数加载,包含之前保存的文本块向量索引和页码信息,用于执行相似度搜索(similarity_search(query))获取与查询相关的文档块。
load_knowledge_base():从指定路径加载已保存的向量数据库(如 FAISS 向量存储),用于恢复之前创建的知识库,需传入与保存时一致的嵌入模型以确保向量匹配。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
save_path | str | 是 | 向量数据库保存的本地路径(如"./vector_db")。 |
embeddings | 嵌入模型对象(如DashScopeEmbeddings) | 是 | 与保存向量时使用的嵌入模型一致,用于解析向量数据。 |
DASHSCOPE_API_KEY:从环境变量 BAILIAN_API_KEY 获取的阿里百炼平台 API 密钥,用于大模型的身份验证。
os.getenv():Python 标准库 os 中的函数,用于获取环境变量的值。若环境变量不存在,可返回指定的默认值,避免硬编码敏感信息(如 API 密钥)。
| 参数名 | 类型 | 说明 |
|---|---|---|
| key | str | 环境变量的名称(代码中为 BAILIAN_API_KEY) |
| default | 任意类型(可选) | 当环境变量不存在时返回的默认值(默认返回 None) |
llm:初始化的对话大模型实例。使用阿里百炼平台的 deepseek-v3 模型,通过 dashscope_api_key 进行身份验证,用于基于相关文档(docs)和用户问题(query)生成自然语言回答。
Tongyi():初始化阿里通义千问(Tongyi)系列大语言模型的实例,用于调用通义千问或兼容的大语言模型能力(如生成回答)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
model_name | str | 是 | 模型名称(如"deepseek-v3"、"qwen-plus"等),指定要调用的具体模型。 |
dashscope_api_key | str | 是 | 阿里 DashScope 平台的 API 密钥,用于身份验证和 API 调用权限。 |
temperature | float | 否 | 生成文本的随机性参数(0~1,值越高随机性越强,默认通常为 0.7)。 |
max_tokens | int | 否 | 生成文本的最大 token 数限制。 |
chain:通过 load_qa_chain(llm, chain_type="stuff") 加载的问答处理链。将对话大模型(llm)与指定的处理类型(chain_type="stuff",表示将所有相关文档合并后输入模型)结合,用于整合相关文档和用户问题,生成最终回答。
load_qa_chain():LangChain 中的函数,用于加载问答处理链,将聊天模型(chatLLM)与指定的处理类型(chain_type)结合,实现基于相关文档回答用户问题的逻辑。
| 参数名 | 类型 | 说明 |
|---|---|---|
| llm | 聊天模型实例 | 用于生成回答的大模型实例(如 chatLLM) |
| chain_type | str | 问答链的处理类型(代码中为 "stuff",表示将所有相关文档合并后输入模型) |
| verbose | bool(可选) | 是否打印详细日志(默认 False) |
input_data:问答链的输入数据字典。包含两个关键键值对:"input_documents": docs(与查询相关的文档块列表)和 "question": query(用户的查询问题),作为 chain.invoke() 方法的输入参数,供问答链整合信息生成回答。
get_openai_callback():LangChain 中的上下文管理器函数,用于跟踪 OpenAI 兼容 API(如阿里百炼)的调用成本,包括令牌(token)使用量、请求次数、费用等信息,便于成本监控。该函数通过上下文管理器(with 语句)使用,无需传入参数
response:问答链(chain)执行后返回的结果对象。其中 response["output_text"] 存储大模型基于相关文档生成的最终回答文本,是整个查询流程的核心输出结果。
chain.invoke():LangChain 中 Chain 对象的方法,用于执行问答链的核心逻辑,接收输入数据并生成输出结果。将用户问题与相关文档结合,通过大模型生成回答。
| 参数名 | 类型 | 说明 |
|---|---|---|
| input | dict | 问答链的输入数据字典,需包含 input_documents(相关文档)和 question(用户问题) |
| config | dict(可选) | 执行配置参数(如超时时间、回调函数等,默认可省略) |
unique_pages:用于存储查询结果来源的唯一页码集合。通过集合的唯一性特性,避免重复记录或显示同一页码,确保最终输出的来源页码不重复,清晰展示回答依据的文档页码。
set():Python 内置函数,用于创建一个空集合或从可迭代对象(如列表、字符串)创建集合。集合中的元素具有唯一性(自动去重),且无序。
| 参数名 | 类型 | 说明 |
|---|---|---|
| iterable | 可迭代对象(可选) | 用于初始化集合的可迭代对象(如代码中未传入参数,创建空集合 unique_pages = set()) |
text_content:从搜索到的文档块(doc)中提取的具体文本内容。通过 getattr(doc, "page_content", "") 动态获取文档块的 page_content 属性(文档块的原始文本),若该属性不存在则返回空字符串,用于后续查找该文本块对应的原始页码。
getattr():Python 内置函数,用于动态获取对象的属性值。若属性不存在,可返回指定的默认值,避免直接访问不存在的属性时抛出异常。
| 参数名 | 类型 | 说明 |
|---|---|---|
| object | 任意对象 | 需要获取属性的对象(例如代码中的 doc) |
| name | str | 要获取的属性名称(例如代码中的 "page_content") |
| default | 任意类型(可选) | 当属性不存在时返回的默认值(若未指定,属性不存在则抛出 AttributeError) |
knowledgeBase.page_info.get():从知识库对象(knowledgeBase)的 page_info 属性(通常是一个字典)中,根据指定的键(文本内容)获取对应的值(页码)。若键不存在,返回预设的默认值(如代码中的 “未知”)。主要用于查询文本块对应的来源页码。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
| key | 任意可哈希类型(如 str) | 要查询的键(代码中为 text_content.strip() 处理后的文本) | 是 |
| default | 任意类型 | 当键不存在时返回的默认值(代码中为 “未知”) | 否(默认返回 None) |
str.strip():Python 字符串的内置方法,用于移除字符串两端的空白字符(如空格、换行符 \n、制表符 \t 等)。默认移除两端空白,也可指定要移除的字符集。返回处理后的新字符串,原字符串不变。
| 参数名 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
| chars | str | 可选参数,指定要从字符串两端移除的字符集。若未指定,默认移除空白字符(空格、\n、\t 等) | 否 |
集合.add():集合(set)的内置方法,用于向集合中添加元素。若元素已存在于集合中,则不重复添加(保持集合元素的唯一性)。
| 参数名 | 类型 | 说明 |
|---|---|---|
| element | 任意可哈希类型 | 要添加到集合中的元素 |
from langchain_community.llms import Tongyi# 设置查询问题
# query = "客户经理被投诉了,投诉一次扣多少分?"
query = "客户经理每年评聘申报时间是怎样的?"
if query:# 示例:如何加载已保存的向量数据库# 注释掉以下代码以避免在当前运行中重复加载# 创建嵌入模型embeddings = DashScopeEmbeddings(model="text-embedding-v2",dashscope_api_key=os.getenv("BAILIAN_API_KEY"))# 从磁盘加载向量数据库loaded_knowledgeBase = load_knowledge_base("./vector_db", embeddings)# 使用加载的知识库进行查询docs = loaded_knowledgeBase.similarity_search(query)# 初始化对话大模型DASHSCOPE_API_KEY = os.getenv("BAILIAN_API_KEY")llm = Tongyi(model_name="deepseek-v3", dashscope_api_key="BAILIAN_API_KEY")# 加载问答链chain = load_qa_chain(llm, chain_type="stuff")# 准备输入数据input_data = {"input_documents": docs, "question": query}# 使用回调函数跟踪API调用成本with get_openai_callback() as cost:# 执行问答链response = chain.invoke(input=input_data)print(f"查询已处理。成本: {cost}")print(response["output_text"])print("来源:")# 记录唯一的页码unique_pages = set()# 显示每个文档块的来源页码for doc in docs:text_content = getattr(doc, "page_content", "")source_page = knowledgeBase.page_info.get(text_content.strip(), "未知")if source_page not in unique_pages:unique_pages.add(source_page)print(f"文本块页码: {source_page}")9.整体代码🚀
代码运行流程
代码运行流程树状图
├─ 1. 初始化与依赖准备
│ ├─ 导入必要库(os、logging、pickle、PyPDF2、langchain组件等)
│ └─ 定义核心函数(extract_text_with_page_numbers、process_text_with_splitter、load_knowledge_base)
│
├─ 2. PDF文本提取流程
│ ├─ 读取PDF文件:通过PyPDF2.PdfReader加载目标PDF(浦发银行考核办法.pdf)
│ └─ 提取文本与页码信息(调用extract_text_with_page_numbers函数)
│ ├─ 遍历PDF每页(enumerate(pdf.pages, start=1)获取页码和页面对象)
│ ├─ 提取单页文本(page.extract_text())
│ ├─ 累积总文本(text += extracted_text)
│ ├─ 记录每行页码(page_numbers.extend([当前页码] * 行数))
│ └─ 无文本页警告(logging.warning输出警告信息)
│
├─ 3. 文本处理与向量库创建流程(调用process_text_with_splitter函数)
│ ├─ 文本分割:使用RecursiveCharacterTextSplitter分割文本为块
│ │ ├─ 分割参数:分隔符[\n\n, \n, ., 空格]、chunk_size=512、chunk_overlap=128
│ │ └─ 输出:分割后的文本块列表(chunks)
│ │
│ ├─ 嵌入模型初始化:创建DashScopeEmbeddings(阿里百炼text-embedding-v2模型)
│ │ └─ 配置:模型名=text-embedding-v2、API密钥=环境变量BAILIAN_API_KEY
│ │
│ ├─ 构建向量库:通过FAISS.from_texts创建知识库(knowledgeBase)
│ ├─ 关联页码信息:创建{文本块: 页码}映射(page_info),绑定到knowledgeBase
│ │
│ └─ 向量库保存(若指定save_path="./vector_db")
│ ├─ 保存FAISS向量库到本地(knowledgeBase.save_local(save_path))
│ └─ 保存页码信息:通过pickle将page_info存入page_info.pkl
│
├─ 4. 查询方式1执行流程
│ ├─ 设置查询问题(如“客户经理每年评聘申报时间是怎样的?”)
│ ├─ 相似度搜索:调用knowledgeBase.similarity_search(query)获取相关文档块(docs)
│ │
│ ├─ 初始化大模型:创建ChatOpenAI实例(适配阿里百炼deepseek-v3模型)
│ │ ├─ 配置:API密钥=环境变量BAILIAN_API_KEY、base_url=阿里兼容接口
│ │ └─ 模型名=deepseek-v3
│ │
│ ├─ 构建问答链:通过load_qa_chain(chatLLM, chain_type="stuff")创建链
│ ├─ 执行问答:chain.invoke(input={"input_documents": docs, "question": query})
│ │ └─ 成本跟踪:通过get_openai_callback记录API调用成本
│ │
│ ├─ 输出结果:打印回答内容(response["output_text"])
│ └─ 溯源页码:通过knowledgeBase.page_info获取文档块对应页码,去重后输出
│
└─ 5. 查询方式2执行流程(基于加载的本地向量库)├─ 设置查询问题(同查询方式1)├─ 加载向量库(调用load_knowledge_base函数)│ ├─ 初始化嵌入模型(DashScopeEmbeddings,同步骤3)│ ├─ 加载FAISS向量库:FAISS.load_local("./vector_db", embeddings)│ └─ 加载页码信息:从page_info.pkl读取page_info并绑定到知识库│├─ 相似度搜索:调用loaded_knowledgeBase.similarity_search(query)获取文档块(docs)│├─ 初始化大模型:创建Tongyi实例(适配deepseek-v3模型)│ └─ 配置:模型名=deepseek-v3、API密钥=环境变量BAILIAN_API_KEY│├─ 构建问答链:通过load_qa_chain(llm, chain_type="stuff")创建链├─ 执行问答:chain.invoke(input={"input_documents": docs, "question": query})│ └─ 成本跟踪:通过get_openai_callback记录API调用成本│├─ 输出结果:打印回答内容(response["output_text"])└─ 溯源页码:通过loaded_knowledgeBase.page_info获取文档块对应页码,去重后输出import os
import logging
import pickle
from PyPDF2 import PdfReader
from langchain.chains.question_answering import load_qa_chain
from langchain_openai import OpenAI, ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.callbacks.manager import get_openai_callback
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from typing import List, Tupledef extract_text_with_page_numbers(pdf) -> Tuple[str, List[int]]:"""从PDF中提取文本并记录每行文本对应的页码参数:pdf: PDF文件对象返回:text: 提取的文本内容page_numbers: 每行文本对应的页码列表"""text = ""page_numbers = []for page_number, page in enumerate(pdf.pages, start=1):extracted_text = page.extract_text()if extracted_text:text += extracted_textpage_numbers.extend([page_number] * len(extracted_text.split("\n")))else:logging.warning(f"No text found on page {page_number}.")return text, page_numbers# ——————————————————————————————————————————————————————————————————————————————————————————def process_text_with_splitter(text: str, page_numbers: List[int], save_path: str = None) -> FAISS:"""处理文本并创建向量存储参数:text: 提取的文本内容page_numbers: 每行文本对应的页码列表save_path: 可选,保存向量数据库的路径返回:knowledgeBase: 基于FAISS的向量存储对象"""# 创建文本分割器,用于将长文本分割成小块text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", ".", " ", ""],chunk_size=512,chunk_overlap=128,length_function=len,)# 分割文本chunks = text_splitter.split_text(text)# logging.debug(f"Text split into {len(chunks)} chunks.")print(f"文本被分割成 {len(chunks)} 个块。")# 创建嵌入模型,OpenAI嵌入模型,配置环境变量 OPENAI_API_KEY# embeddings = OpenAIEmbeddings()# 调用阿里百炼平台文本嵌入模型,配置环境变量 DASHSCOPE_API_KEYembeddings = DashScopeEmbeddings(model="text-embedding-v2",dashscope_api_key=os.getenv("BAILIAN_API_KEY"))# 从文本块创建知识库knowledgeBase = FAISS.from_texts(chunks, embeddings)print("已从文本块创建知识库...")# 存储每个文本块对应的页码信息page_info = {chunk: page_numbers[i] for i, chunk in enumerate(chunks)}knowledgeBase.page_info = page_info# 如果提供了保存路径,则保存向量数据库和页码信息if save_path:# 确保目录存在os.makedirs(save_path, exist_ok=True)# 保存FAISS向量数据库knowledgeBase.save_local(save_path)print(f"向量数据库已保存到: {save_path}")# 保存页码信息到同一目录with open(os.path.join(save_path, "page_info.pkl"), "wb") as f:pickle.dump(page_info, f)print(f"页码信息已保存到: {os.path.join(save_path, 'page_info.pkl')}")return knowledgeBase# ——————————————————————————————————————————————————————————————————————————————————————————def load_knowledge_base(load_path: str, embeddings=None) -> FAISS:"""从磁盘加载向量数据库和页码信息参数:load_path: 向量数据库的保存路径embeddings: 可选,嵌入模型。如果为None,将创建一个新的DashScopeEmbeddings实例返回:knowledgeBase: 加载的FAISS向量数据库对象"""# 如果没有提供嵌入模型,则创建一个新的if embeddings is None:embeddings = DashScopeEmbeddings(model="text-embedding-v2",dashscope_api_key=os.getenv("BAILIAN_API_KEY"))# 加载FAISS向量数据库,添加allow_dangerous_deserialization=True参数以允许反序列化knowledgeBase = FAISS.load_local(load_path, embeddings, allow_dangerous_deserialization=True)print(f"向量数据库已从 {load_path} 加载。")# 加载页码信息page_info_path = os.path.join(load_path, "page_info.pkl")if os.path.exists(page_info_path):with open(page_info_path, "rb") as f:page_info = pickle.load(f)knowledgeBase.page_info = page_infoprint("页码信息已加载。")else:print("警告: 未找到页码信息文件。")return knowledgeBase# ——————————————————————————————————————————————————————————————————————————————————————————# 读取PDF文件
pdf_reader = PdfReader(r'F:\AI_BigModel\L1课件\第2章_RAG技术与应用/浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf')
# 提取文本和页码信息
text, page_numbers = extract_text_with_page_numbers(pdf_reader)
print(text)print(f"提取的文本长度: {len(text)} 个字符。")# 处理文本并创建知识库,同时保存到磁盘
save_dir = "./vector_db"
knowledgeBase = process_text_with_splitter(text, page_numbers, save_path=save_dir)# 处理文本并创建知识库
knowledgeBase = process_text_with_splitter(text, page_numbers)
print(knowledgeBase)print("————————————————————————————————————————————查询方式1:——————————————————————————————————————————————")# 设置查询问题
# query = "客户经理被投诉了,投诉一次扣多少分"
query = "客户经理每年评聘申报时间是怎样的?"
if query:# 执行相似度搜索,找到与查询相关的文档docs = knowledgeBase.similarity_search(query)# 初始化对话大模型chatLLM = ChatOpenAI(# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",api_key=os.getenv("BAILIAN_API_KEY"),base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",model="deepseek-v3")# 加载问答链chain = load_qa_chain(chatLLM, chain_type="stuff")# 准备输入数据input_data = {"input_documents": docs, "question": query}# 使用回调函数跟踪API调用成本with get_openai_callback() as cost:# 执行问答链response = chain.invoke(input=input_data)print(f"查询已处理。成本: {cost}")print(response["output_text"])print("来源:")# 记录唯一的页码unique_pages = set()# 显示每个文档块的来源页码for doc in docs:text_content = getattr(doc, "page_content", "")source_page = knowledgeBase.page_info.get(text_content.strip(), "未知")if source_page not in unique_pages:unique_pages.add(source_page)print(f"文本块页码: {source_page}")print("———————————————————————————————————————————查询方式2:———————————————————————————————————————————————")from langchain_community.llms import Tongyi# 设置查询问题
# query = "客户经理被投诉了,投诉一次扣多少分?"
query = "客户经理每年评聘申报时间是怎样的?"
if query:# 示例:如何加载已保存的向量数据库# 注释掉以下代码以避免在当前运行中重复加载# 创建嵌入模型embeddings = DashScopeEmbeddings(model="text-embedding-v2",dashscope_api_key=os.getenv("BAILIAN_API_KEY"))# 从磁盘加载向量数据库loaded_knowledgeBase = load_knowledge_base("./vector_db", embeddings)# 使用加载的知识库进行查询docs = loaded_knowledgeBase.similarity_search(query)# 初始化对话大模型DASHSCOPE_API_KEY = os.getenv("BAILIAN_API_KEY"),llm = Tongyi(model_name="deepseek-v3", dashscope_api_key="BAILIAN_API_KEY")# 加载问答链chain = load_qa_chain(llm, chain_type="stuff")# 准备输入数据input_data = {"input_documents": docs, "question": query}# 使用回调函数跟踪API调用成本with get_openai_callback() as cost:# 执行问答链response = chain.invoke(input=input_data)print(f"查询已处理。成本: {cost}")print(response["output_text"])print("来源:")# 记录唯一的页码unique_pages = set()# 显示每个文档块的来源页码for doc in docs:text_content = getattr(doc, "page_content", "")source_page = knowledgeBase.page_info.get(text_content.strip(), "未知")if source_page not in unique_pages:unique_pages.add(source_page)print(f"文本块页码: {source_page}")
小结:
Ⅰ、PDF文本提取与处理
使用PyPDF2库的PdfReader从PDF文件中提取文本在提取过程中记录每行文本对应的页码,便于后续溯源
使用RecursiveCharacterTextSplitter将长文本分割成小块,便于向量化处理
Ⅱ、向量数据库构建
使用OpenAIEmbeddings / DashScopeEmbeddings将文本块转换为向量表示
使用FAISS向量数据库存储文本向量,支持高效的相似度搜索为每个文本块保存对应的页码信息,实现查询结果溯源
Ⅲ、语义搜索与问答链
基于用户查询,使用similarity_search在向量数据库中检索相关文本块
使用文本语言模型和load_qa_chain构建问答链将检索到的文档和用户问题作为输入,生成回答
Ⅳ、成本跟踪与结果展示
使用get_openai_callback跟踪API调用成本
展示问答结果和来源页码,方便用户验证信息
五、三大有效提升RAG质量方法
1.数据准备阶段
Ⅰ、常见问题
-
数据质量差: 企业大部分数据(尤其是非结构化数据)缺乏良好的数据治理,未经标记/评估的非结构化数据可能包含敏感、过时、矛盾或不正确的信息。
-
多模态信息: 提取、定义和理解文档中的不同内容元素,如标题、配色方案、图像和标签等存在挑战。
-
复杂的PDF提取: PDF是为人类阅读而设计的,机器解析起来非常复杂。
Ⅱ、如何提升数据准备阶段的质量
① 构建完整的数据准备流程【数据质量部】
1.数据评估与分类
数据审计:全面审查现有数据,识别敏感、过时、矛盾或不准确的信息。
数据分类:按类型、来源、敏感性和重要性对数据进行分类,便于后续处理。
2.数据清洗
去重:删除重复数据
纠错:修正格式错误、拼写错误等
更新:替换过时信息,确保数据时效性
一致性检查:解决数据矛盾,确保逻辑一致
3.敏感信息处理
识别敏感数据:使用工具或正则表达式识别敏感信息,如个人身份信息
脱敏或加密:对敏感数据进行脱敏处理,确保合规。
4.数据标记与标注
元数据标记:为数据添加元数据,如来源、创建时间等
内容标注:对非结构化数据进行标注,便于后续检索和分析
5.数据治理框架
制定政策:明确数据管理、访问控制和更新流程
责任分配:指定数据治理负责人,确保政策执行
监控与审计:定期监控数据质量,进行审计
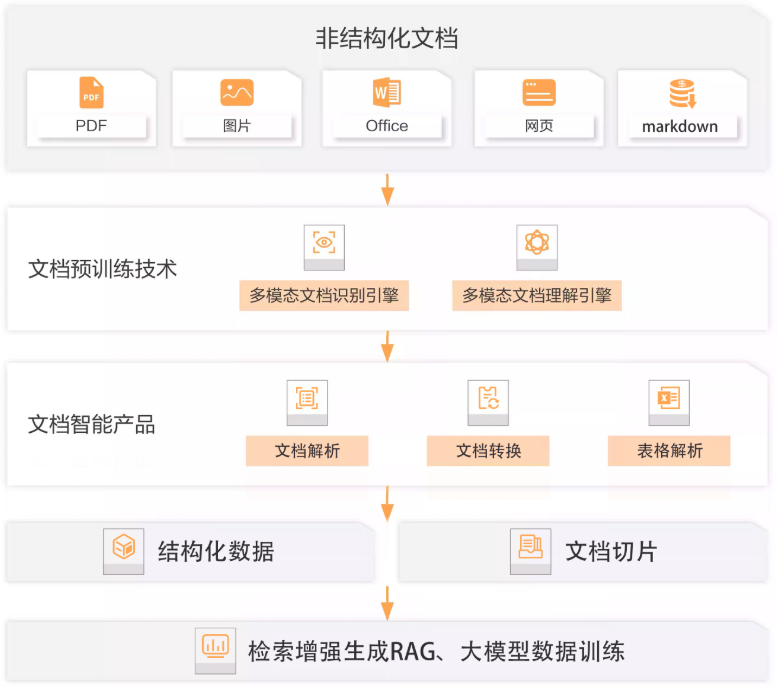
② 智能文档技术【复杂文档处理】
流程:
① 将不同格式文档统一使用多模态文档识别、理解引擎 —>
② 做文档解析,解析为一个doc tree,再将doc tree解析为一个text文本 —>
③ 在进行文档的切片 —>
④ 最终搭建知识库进行RAG
阿里文档智能:文档智能_文档AI_智能文档处理_数据智能-阿里云
微软 LayoutLMv3:文档智能多模态预训练模型LayoutLMv3:兼具通用性与优越性 - Microsoft Research
RAGFlow:https://github.com/infiniflow/ragflow
2.知识检索阶段
Ⅰ、常见问题
-
内容缺失: 当检索过程缺少关键内容时,系统会提供不完整、碎片化的答案 => 降低RAG的质量
-
错过排名靠前的文档: 用户查询相关的文档时被检索到,但相关性极低,导致答案不能满足用户需求,这是因为在检索过程中,用户通过主观判断决定检索“文档数量”。理论上所有文档都要被排序并考虑进一步处理,但在实践中,通常只有排名 top k 的文档才会被召回,而 k 值需要根据经验确定。
-
不在上下文中: 从数据库中检索出包含答案的文档,但未能包含在生成答案的上下文中。这种情况通常发生在返回大量文件时,需要进行整合以选择最相关的信息。
Ⅱ、如何提升知识检索阶段的质量
-
通过查询转换澄清用户意图(查询改写):明确用户意图,提高检索准确性。
-
采用混合检索和重排策略:确保最相关的文档被优先处理,生成更准确的答案。
① 通过查询转换澄清用户意图
场景:用户询问 “如何申请信用卡?”
问题:用户意图可能模糊,例如不清楚是申请流程、所需材料还是资格条件。
解决方法:通过查询转换明确用户意图。
实现步骤:
① 意图识别:使用自然语言处理技术识别用户意图。
例如:识别用户是想了解流程、材料还是资格。
② 查询扩展:根据识别结果扩展查询。
示例:
如果用户想了解流程,查询扩展为“信用卡申请的具体步骤”
如果用户想了解材料,查询扩展为“申请信用卡需要哪些材料”
如果用户想了解资格,查询扩展为“申请信用卡的资格条件”
③ 检索:使用扩展后的查询检索相关文档
示例:
用户输入:“如何申请信用卡?”
系统识别意图为
流程,扩展查询为信用卡申请的具体步骤检索结果包含详细的申请步骤文档,系统生成准确答案
② 混合检索的重排策略
场景:用户询问“信用卡年费是多少?”
问题:直接检索可能返回大量文档,部分相关但排名低,导致答案不准确。
解决方法:采用混合检索和重排策略。
实现步骤:
① 混合检索:结合关键词检索和语义检索。比如:关键词检索:“信用卡年费”。
示例:用户输入:“信用卡年费是多少?”
② 语义检索:使用嵌入模型检索与“信用卡年费”语义相近的文档。
示例:系统进行混合检索,结合关键词和语义检索。
③ 重排:对检索结果进行重排。
示例:重排后,最相关的文档(如“信用卡年费政策”)排名靠前。
④ 生成答案:从重排后的文档中生成答案。
示例:系统生成准确答案:“信用卡年费根据卡类型不同,普通卡年费为100元,金卡为300元,白金卡为1000元。”
3.答案生成阶段
Ⅰ、常见问题
-
未提取: 答案与所提供的上下文相符,但大语言模型却无法准确提取。这种情况通常发生在上下文中存在过多噪音或相互冲突的信息时。【推理模型能力不足,解决方案:SFT】
-
不完整: 尽管能够利用上下文生成答案,但信息缺失会导致对用户查询的答复不完整。格式错误:当prompt中的附加指令格式不正确时,大语言模型可能误解或曲解这些指令,从而导致错误的答案。
-
幻觉: 大模型可能会产生误导性或虚假性信息。
Ⅱ、如何提升答案生成阶段的质量
-
改进提示词模板
-
实施动态防护栏
① 改进提示词模板

如何对原有的提示词进行优化?
可以通过 DeepSeek-R1 或 QWQ 的推理链,对提示词进行优化:
-
信息提取:从原始提示词中提取关键信息。
-
需求分析:分析用户的需求,明确用户希望获取的具体信息。
-
提示词优化:根据需求分析的结果,优化提示词,使其更具体、更符合用户的需求。
② 实施动态防护栏
动态防护栏(Dynamic Guardrails)是一种在生成式AI系统中用于实时监控和调整模型输出的机制,旨在确保生成的内容符合预期、准确且安全。它通过设置规则、约束和反馈机制,动态地干预模型的生成过程,避免生成错误、不完整、不符合格式要求或含有虚假信息(幻觉)的内容。
在RAG系统中,动态防护栏的作用尤为重要,因为它可以帮助解决以下问题:
-
未提取:确保模型从上下文中提取了正确的信息。
-
不完整:确保生成的答案覆盖了所有必要的信息。
-
格式错误:确保生成的答案符合指定的格式要求。
-
幻觉:防止模型生成与上下文无关或虚假的信息。
-
示例:
场景1:防止未提取
用户问题:“如何申请信用卡?”
上下文:包含申请信用卡的步骤和所需材料。
动态防护栏规则:检查生成的答案是否包含“步骤”和“材料”。如果缺失,提示模型重新生成。
示例:
错误输出:“申请信用卡需要提供一些材料。”
防护栏触发:检测到未提取具体步骤,提示模型补充。(workflow+agent)
场景2:防止不完整
用户问题:“信用卡的年费是多少?”
上下文:包含不同信用卡的年费信息。
动态防护栏规则:检查生成的答案是否列出所有信用卡的年费。如果缺失,提示模型补充。
示例:
错误输出:“信用卡A的年费是100元。”
防护栏触发:检测到未列出所有信用卡的年费,提示模型补充。(workflow+agent)
场景3:防止幻觉
用户问题:“什么是零存整取?”
上下文:包含零存整取的定义和特点。
动态防护栏规则:检查生成的答案是否与上下文一致。如果不一致,提示模型重新生成。
示例:
错误输出:“零存整取是一种贷款产品。
防护栏触发:检测到与上下文不一致,提示模型重新生成。(workflow+agent)
如何实现动态防护栏技术?
事实性校验规则,在生成阶段,设置规则验证生成内容是否与检索到的知识片段一致。例如,可以使用参考文献验证机制,确保生成内容有可靠来源支持,避免输出矛盾或不合理的回答。
如何制定事实性校验规则?
当业务逻辑明确且规则较为固定时,可以人为定义一组规则,比如:
- 规则1:生成的答案必须包含检索到的知识片段中的关键实体(如“年费”、“利率”)。
- 规则2:生成的答案必须符合指定的格式(如步骤列表、表格等)。
- 实施方法:
- 使用正则表达式或关键词匹配来检查生成内容是否符合规则。
- 例如,检查生成内容是否包含“年费”这一关键词,或者是否符合步骤格式(如“1. 登录;2. 设置”)。
六、RAG在不同阶段提升质量的实践
-
数据准备环节,阿里云考虑到文档具有多层标题属性且不同标题之间存在关联性,提出多粒度知识提取方案,按照不同标题级别对文档进行拆分,然后基于Qwen14b模型和RefGPT训练了一个面向知识提取任务的专属模型,对各个粒度的chunk进行知识提取和组合,并通过去重和降噪的过程保证知识不丢失、不冗余。最终将文档知识提取成多个事实型对话,提升检索效果;
-
知识检索环节,哈啰出行采用多路召回的方式,主要是向量召回和搜索召回。其中,向量召回使用了两类,一类是大模型的向量、另一类是传统深度模型向量;搜索召回也是多链路的,包括关键词、ngram等。通过多路召回的方式,可以达到较高的召回查全率。
-
答案生成环节,中国移动为了解决事实性不足或逻辑缺失,采用FoRAG两阶段生成策略,首先生成大纲,然后基于大纲扩展生成最终答案。
七、反思
如果LLM可以处理无限上下文了,RAG还有意义吗?
-
效率与成本:LLM处理长上下文时计算资源消耗大,响应时间增加。RAG通过检索相关片段,减少输入长度。
-
知识更新:LLM的知识截止于训练数据,无法实时更新。RAG可以连接外部知识库,增强时效性。
-
可解释性:RAG的检索过程透明,用户可查看来源,增强信任。LLM的生成过程则较难追溯。
-
定制化:RAG可针对特定领域定制检索系统,提供更精准的结果,而LLM的通用性可能无法满足特定需求。
-
数据隐私:RAG允许在本地或私有数据源上检索,避免敏感数据上传云端,适合隐私要求高的场景。
-
结合LLM的生成能力和RAG的检索能力,可以提升整体性能,提供更全面、准确的回答。