LLM - 使用 SGLang 部署 Qwen3-32B 与 Qwen2.5-VL-32B-Instruct
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/150422211
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。
SGLang,即 Structured Generation Language for LLMs,用于大语言模型的结构化生成语言,是 Stanford & Berkeley 团队推出的大模型推理引擎,优势是高吞吐 + 可编程。与 vLLM 相比,SGLang 在以下场景表现更优,即:
- 多轮对话吞吐提升最高 5 倍:SGLang 的核心创新 RadixAttention 用 Radix 树把 KV 缓存的前缀做全局复用,结合 LRU 策略,让同一对话历史的 KV 缓存不再反复生成,在 Llama-7B 多轮对话测试中,吞吐量比 vLLM 高出 5 倍。
- 复杂控制流原生支持:vLLM 的推理流程相对静态,复杂逻辑要靠 Prompt 模板;而 SGLang 提供嵌入式 Python DSL (Domain Structure Language),在代码里写 if/loop/并行调用,构建 Agent 或多步推理工作流时代码量更少、可读性更高。
- 结构化输出零后处理:SGLang 内置正则约束解码,可一次性让模型吐出符合 JSON Schema 等格式的结果,省掉传统方案中的后处理脚本,而 vLLM 仍需外部解析校验。Structured Outputs For Reasoning Models
- 更长上下文、更低延迟:在 A100-7B、输入 8k Tokens 的实测中,SGLang 吞吐量领先 vLLM 约 22%,首字符延迟降低 27%,内存占用也减少近 10%。
当场景中,包含大量多轮对话、复杂流程编排、强格式约束,SGLang 以更少代码、更高吞吐和更低延迟完成部署。
SGLang 的 RadixAttention (基数注意力机制),如下:
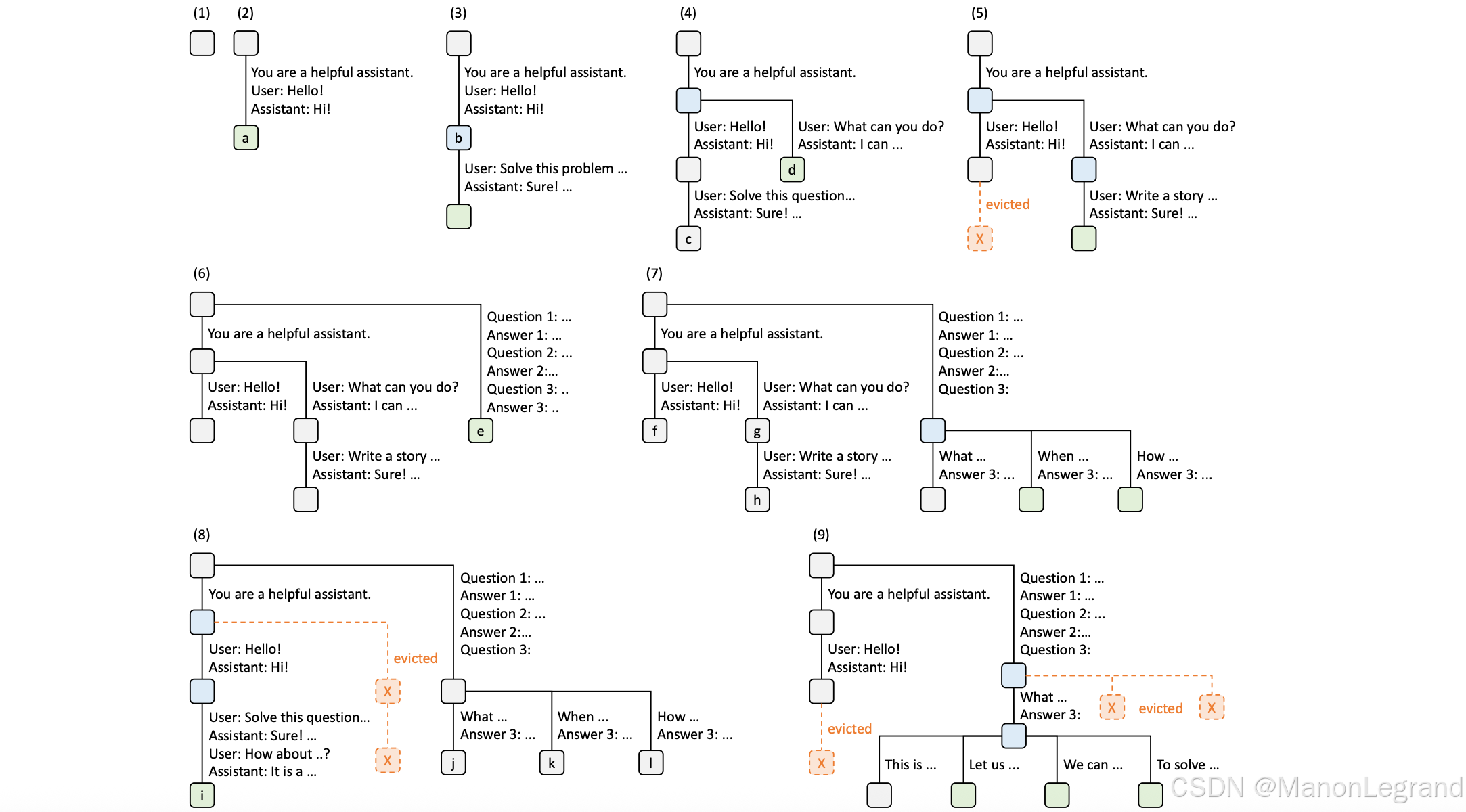
RadixAttention,基数树(Radix Tree) 是数据结构,作为传统**前缀树(Trie)**的空间高效替代方案。与普通树不同,基数树的边可由单个元素标记,还可以由长度可变的一整段元素序列来标记,显著提升效率。在系统中,使用基数树来维护 Token 序列与其对应 KV 缓存张量之间的映射。这些 KV 缓存张量以非连续的分页形式存储,每页大小恰好对应一个 Token。由于 GPU 内存很快就会被 KV 缓存占满,引入简单的 LRU 淘汰策略:优先淘汰最近最少使用的叶子节点。通过首先淘汰叶子节点,得以继续复用它们的公共祖先,直到这些祖先也变成叶子并最终被淘汰。
相关文档:
- Paper: SGLang: Efficient Execution of Structured Language Model Programs
- GitHub: https://github.com/sgl-project/sglang
- Qwen-SGLang: https://qwen.readthedocs.io/zh-cn/latest/deployment/sglang.html
1. 配置环境
使用 SGLang 的 Docker 版本是 v0.4.9,支持 H20-96G 显卡,实现大模型的快速部署,即:
sglang:0.4.9.post2
在 Docker 中:
- sglang 版本是 0.4.9.post2
- Python 版本是 Python 3.10.12
- PyTorch 版本是 2.7.1+cu126
- NVCC 版本是 9.0
也可以,独立安装 SGLang (不推荐),注意,需要使用 torch 的 2.8+ 版本,否则 flashinfer-python 不兼容。
pip install torch==2.8.0+cu126 torchvision==0.23.0+cu126 torchaudio==2.8.0+cu126 --index-url https://download.pytorch.org/whl/cu126 --force-reinstall
pip install "sglang[all]" # 需要与 PyTorch 2.8 版本相匹配
2. 启动服务
准备要使用的大模型 Qwen3-32B 与 Qwen2.5-VL-32B-Instruct,即:
cd ./modelscope_models/ modelscope download --model Qwen/Qwen3-32B --local_dir Qwen/Qwen3-32B
modelscope download --model Qwen/Qwen2.5-VL-32B-Instruct --local_dir Qwen/Qwen2.5-VL-32B-Instruct
直接启动 Qwen 大模型服务,具体参考 Qwen-SGLang,即:
python3 -m sglang.launch_server --model modelscope_models/Qwen/Qwen3-32B/ --trust-remote-code --tp 2 --host 0.0.0.0 --port 9002python3 -m sglang.launch_server --model modelscope_models/Qwen/Qwen2.5-VL-32B-Instruct/ --trust-remote-code --tp 2 --host 0.0.0.0 --port 9002 --chat-template qwen2-vl
注意:自定义端口号
--port 9002;Qwen2.5-VL-32B-Instruct,需要设置--chat-template qwen2-vl
多模态语言模型(Multimodal Language Models),参考:

启动日志,注意:
- 使用 BF16 加载的大模型参数,因为
--tp 2使用 2 个 GPU 卡,显存占用是 mem=62.42 GB,单卡是 31.46 GB 显存。 max_total_num_tokens=413827,整个系统 KV 缓存最多缓存的 Token 数量。chunked_prefill_size=8192,在 预填充阶段(prefill) 中,每次处理的最大 Token 是 8192 个。如果输入 Prompt 超长 (比如 >8192),系统将其 分块处理,避免一次性占用过多显存。max_prefill_tokens=16384,单个请求在预填充阶段最多允许处理 16384 个 Token,即chunked_prefill_size是 8192,max_prefill_tokens是 16384,即最多分两次 chunk 处理。max_running_requests=4096,系统最多同时处理 4096 个请求。context_len=40960,模型支持的最大 上下文长度 是 40960 个 Token,即输入 prompt + 已生成的输出,总长度不能超过这个值。available_gpu_mem=7.93 GB,当前 GPU 上 剩余的可用显存,用于动态分配新的 KV 缓存或临时张量。
Qwen3-32B 的日志,如下:
[2025-08-14 19:10:18 TP0] Load weight end. type=Qwen3ForCausalLM, dtype=torch.bfloat16, avail mem=63.28 GB, mem usage=30.59 GB.
[2025-08-14 19:10:18 TP1] KV Cache is allocated. #tokens: 413827, K size: 25.26 GB, V size: 25.26 GB
[2025-08-14 19:10:18 TP0] KV Cache is allocated. #tokens: 413827, K size: 25.26 GB, V size: 25.26 GB
[2025-08-14 19:10:18 TP0] Memory pool end. avail mem=11.91 GB
[2025-08-14 19:10:18 TP0] Capture cuda graph begin. This can take up to several minutes. avail mem=11.81 GB
[2025-08-14 19:10:18 TP0] Capture cuda graph bs [1, 2, 4, 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128, 136, 144, 152, 160, 168, 176, 184, 192, 200, 208, 216, 224, 232, 240, 248, 256]
Capturing batches (bs=1 avail_mem=7.94 GB): 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 35/35 [00:12<00:00, 2.79it/s]
[2025-08-14 19:10:31 TP1] Registering 4515 cuda graph addresses
[2025-08-14 19:10:31 TP0] Registering 4515 cuda graph addresses
[2025-08-14 19:10:31 TP0] Capture cuda graph end. Time elapsed: 12.66 s. mem usage=3.88 GB. avail mem=7.93 GB.
[2025-08-14 19:10:31 TP0] max_total_num_tokens=413827, chunked_prefill_size=8192, max_prefill_tokens=16384, max_running_requests=4096, context_len=40960, available_gpu_mem=7.93 GB
Qwen3 模型在预训练中的上下文长度最长为 32768 个 token (context-length)。为了处理显著超过 32,768 个 token 的上下文长度,应应用 RoPE 缩放技术。
Qwen2.5-VL-32B-Instruct 的日志,如下:
[2025-08-14 19:33:27 TP0] Load weight end. type=Qwen2_5_VLForConditionalGeneration, dtype=torch.bfloat16, avail mem=62.42 GB, mem usage=31.46 GB.
[2025-08-14 19:33:27 TP1] KV Cache is allocated. #tokens: 340276, K size: 20.77 GB, V size: 20.77 GB
[2025-08-14 19:33:27 TP0] KV Cache is allocated. #tokens: 340276, K size: 20.77 GB, V size: 20.77 GB
[2025-08-14 19:33:27 TP0] Memory pool end. avail mem=19.69 GB
[2025-08-14 19:33:27 TP0] Capture cuda graph begin. This can take up to several minutes. avail mem=19.12 GB
[2025-08-14 19:33:27 TP0] Capture cuda graph bs [1, 2, 4, 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128, 136, 144, 152, 160, 168, 176, 184, 192, 200, 208, 216, 224, 232, 240, 248, 256]
Capturing batches (bs=1 avail_mem=15.05 GB): 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████| 35/35 [00:14<00:00, 2.40it/s]
[2025-08-14 19:33:41 TP1] Registering 4515 cuda graph addresses
[2025-08-14 19:33:41 TP0] Registering 4515 cuda graph addresses
[2025-08-14 19:33:42 TP0] Capture cuda graph end. Time elapsed: 14.69 s. mem usage=4.11 GB. avail mem=15.00 GB.
[2025-08-14 19:33:42 TP0] max_total_num_tokens=340276, chunked_prefill_size=8192, max_prefill_tokens=16384, max_running_requests=2048, context_len=128000, available_gpu_mem=15.00 GB
Qwen3 使用 YaRN 扩展上下文长度,参考 Qwen - SGLang,即:
python -m sglang.launch_server --model-path Qwen/Qwen3-8B --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}' --context-length 131072
默认的 SGLang 的显存是全部占用,即:
Thu Aug 14 19:07:52 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.86.10 Driver Version: 570.86.10 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA H20 On | 00000000:CA:00.0 Off | 0 |
| N/A 39C P0 122W / 500W | 82649MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA H20 On | 00000000:D5:00.0 Off | 0 |
| N/A 34C P0 114W / 500W | 82649MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------++-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 189212 C sglang::scheduler_TP0 82640MiB |
| 1 N/A N/A 189213 C sglang::scheduler_TP1 82640MiB |
+-----------------------------------------------------------------------------------------+
3. 测试效果
大语言模型(LLM)的访问调用,如下:
"chat_template_kwargs": {"enable_thinking": false},关闭 Thinking 模式
即:
curl http://localhost:9002/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "Qwen/Qwen3-32B","messages": [{"role": "user", "content": "Give me a short introduction to large language models."}],"temperature": 0.6,"top_p": 0.95,"top_k": 20,"max_tokens": 32768
}'curl http://localhost:9002/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "Qwen/Qwen3-32B","messages": [{"role": "user", "content": "Give me a short introduction to large language models."}],"temperature": 0.7,"top_p": 0.8,"top_k": 20,"max_tokens": 8192,"presence_penalty": 1.5,"chat_template_kwargs": {"enable_thinking": false}
}'
视觉大语言模型(VLM)的访问调用,如下:
curl http://localhost:9002/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "Qwen/Qwen2.5-VL-32B-Instruct","messages": [{"role": "user","content": [{"type": "image_url","image_url": {"url": "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/dog.png"}},{"type": "text","text": "请简要描述图片是什么内容?"}]}],"temperature": 0.7,"stream": false
}'
因视觉输入,需要支持本地图像传输访问,使用 Base64 格式,即,使用情况脚本如下:
- 注意:Base64 的编码格式,即
data:image/png;base64,$BASE64_DATA
curl -s "https://sf-maas-uat-prod.oss-cn-shanghai.aliyuncs.com/dog.png" | base64 | awk '{printf "%s",$0}' > dog_base64.txtBASE64_DATA=$(cat dog_base64.txt)curl http://localhost:9002/v1/chat/completions -H "Content-Type: application/json" -d "{\"model\": \"Qwen/Qwen2.5-VL-32B-Instruct\",\"messages\": [{\"role\": \"user\",\"content\": [{\"type\": \"image_url\",\"image_url\": {\"url\": \"data:image/png;base64,$BASE64_DATA\"}},{\"type\": \"text\",\"text\": \"请简要描述图片是什么内容?\"}]}],\"temperature\": 0.7,\"stream\": false
}"
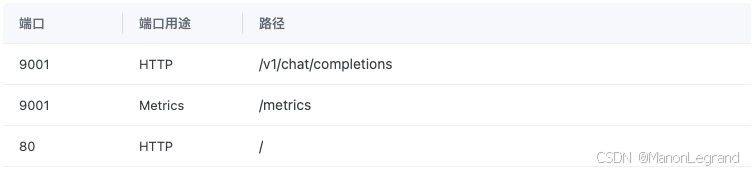
4. Metrics (指标)
启动 --enable-metrics,显示 Metrics 指标,即:
python3 -m sglang.launch_server --model modelscope_models/Qwen/Qwen3-32B/ --trust-remote-code --tp 2 --host 0.0.0.0 --port 9001 --enable-metrics
配置 Metrics 端口 与 HTTP 端口一致,显示 SGLang 框架指标,如下:
参考:
- 知乎 - SGLang:LLM推理引擎发展新方向
- 知乎 - 使用sglang在服务器docker中部署deepseek