深入Amazon DynamoDB:高效、无缝的数据存储解决方案
在现代应用程序的开发中,如何高效地处理海量数据成为了企业面临的一大挑战,作为亚马逊云科技提供的完全托管型NoSQL数据库,DynamoDB为开发者带来了前所未有的性能、可扩展性和灵活性。无论是高并发的在线交易系统,还是需要实时数据处理的物联网应用,DynamoDB都能提供低延迟和高吞吐量,确保应用程序的顺畅运行。今天本文将深入探讨Amazon DynamoDB的功能,了解它如何助力数据管理和业务创新。
目录
初识Amazon DynamoDB
全局表构建应用程序
交易日志和行情的应用
写在最后
新用户可获得高达 200 美元的服务抵扣金
亚马逊云科技新用户可以免费使用亚马逊云科技免费套餐(Amazon Free Tier)。注册即可获得 100 美元的服务抵扣金,在探索关键亚马逊云科技服务时可以再额外获得最多 100 美元的服务抵扣金。使用免费计划试用亚马逊云科技服务,最长可达 6 个月,无需支付任何费用,除非您选择付费计划。付费计划允许您扩展运营并获得超过 150 项亚马逊云科技服务的访问权限。
初识Amazon DynamoDB
Amazon DynamoDB:一项无服务器的 NoSQL 数据库服务可以通过它来开发任何规模的现代应用程序,作为无服务器数据库,DynamoDB的特点是只需按使用量为其付费,可以做到缩减到零,没有冷启动,没有版本升级,没有维护窗口,没有修补,也没有停机维护。
DynamoDB提供一系列广泛的安全控制措施和合规性标准,对于全球分布式应用程序,DynamoDB全局表是一个多区域、多活动数据库,具有99.999%的可用性 SLA 和更高的弹性,托管备份、时间点恢复等功能有助于确保DynamoDB的可靠性,借助DynamoDB流可以构建无服务器的事件驱动型应用程序,从 网址 我们可以知道其具备的优势:

Amazon DynamoDB按行业提供了不同的解决方案,特别适合需要高吞吐量、低延迟和弹性扩展的应用场景,无论是处理大规模数据的金融系统、支持高并发的零售平台还是海量数据存储的物联网应用。DynamoDB都能提供强大的支持,每个行业通过DynamoDB的可扩展性、安全性和高可用性,能够确保数据存储与管理的高效性,并为创新和业务增长提供坚实基础,如下图所示:

如果你想了解更多关于Amazon DynamoDB方面的内容,可以访问 网址 来查看更多知识和内容:
全局表构建应用程序
尽管成千上万的用户在成功使用 Amazon DynamoDB 全局表最终一致性功能,但我们发现对于更强的韧性需求正在浮现。许多组织发现DynamoDB的多可用区架构和最终一致的全局表能够满足其需求,但诸如支付处理系统和金融服务等关键应用的需求则更高,对于这些应用而言,在罕见的全区域性事件中,客户要求恢复点目标(RPO)为零,这意味着可以指示应用程序从任何区域读取最新数据。您的跨区域应用程序无论处于何处,都需要访问相同的数据。
接下来我们可以使用新的Amazon DynamoDB全局表功能,它提供多区域强一致性(MRSC),可实现零 RPO。该功能首次在 AWS re:Invent 2024 上以预览形式公布,它简化了构建具有高度韧性的全球应用程序的过程,以下是使用现有的空 DynamoDB 表来启用 MRSC 的方法:
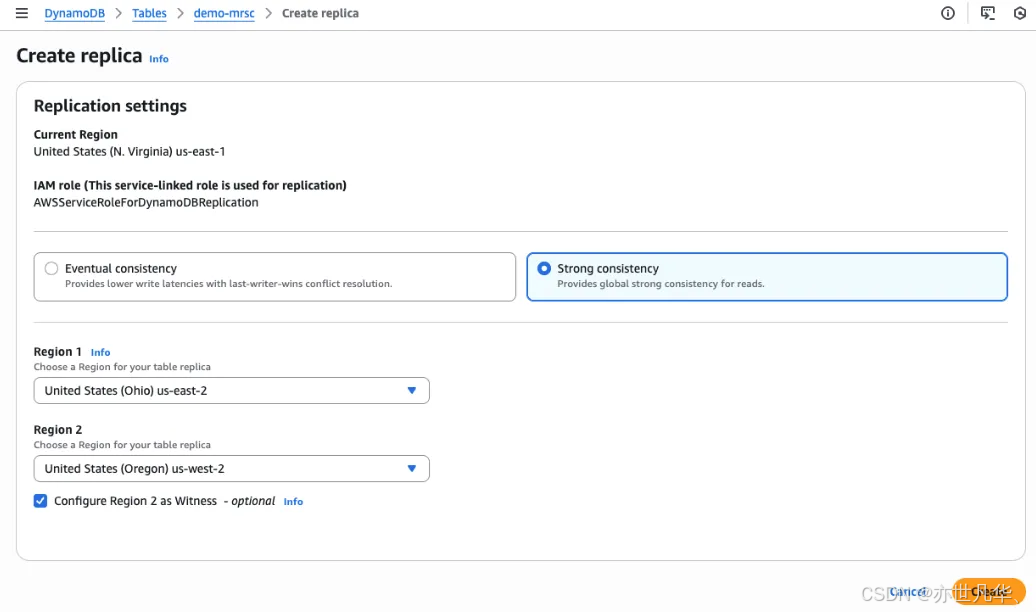
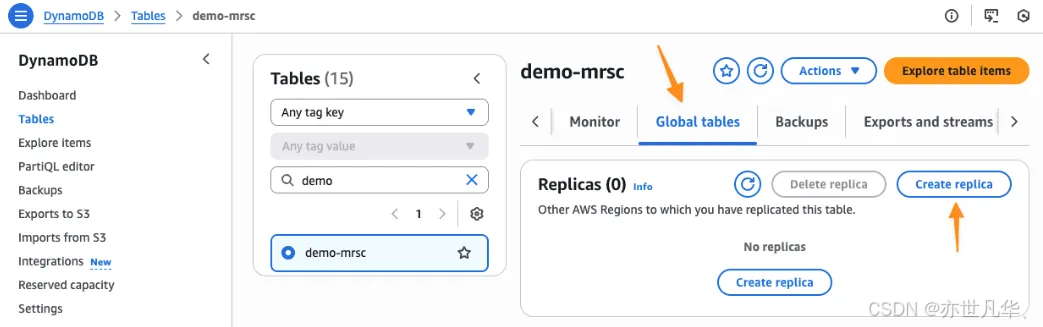
借助 MRSC,DynamoDB可以给应用程序提供最高级别的韧性,如果某个区域的应用程序处理过程出现中断,可以将流量重定向到包含 MRSC 副本的另一个区域,并且可以知晓将处理最新的数据,要开始使用MRSC,需要从一个现有的不包含任何数据的DynamoDB表中创建一个全局表,导航到我的现有表,选择全局表选项卡,然后选择创建副本:
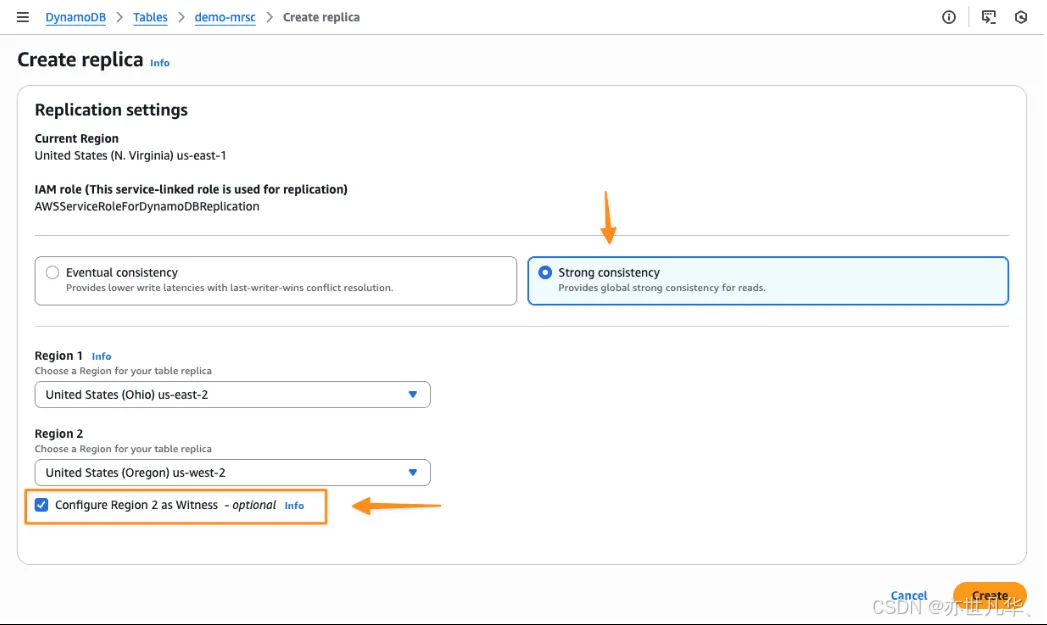
MRSC可用性架构需要三个区域,可以使用三个完整副本或者两个副本和一个见证副本来配置 MRSC,见证副本仅包含复制的变更数据从而提供所需的可用性,无需维持整个表数据的完整副本,下图展示了如何使用两个副本和一个见证副本来配置MRSC,要改为使用三个完整副本来配置 MRSC,可以清除将区域 2 配置为见证副本:
如果需要以编程方式更新现有表,我可以使用 Amazon Q CLI 来生成所需的命令,具体提示符如下:
> Hey Q! Update my existing DynamoDB table called "demo-mrsc" in us-east-1 with multi-Region strong consistency across us-east-2 with witness in us-west-2 Regions
片刻之后,Q CLI 将会回传以下命令:
> To update your DynamoDB table with multi-Region strong consistency, you'll need to use the update-table command with the appropriate parameters.Here's how you would do it:aws dynamodb update-table \ --table-name demo-mrsc \ --replica-updates '[{"Create": {"RegionName": "us-east-2"}}]' \ --global-table-witness-updates '[{"Create": {"RegionName": "us-west-2"}}]' \ --multi-region-consistency STRONG \ --region us-east-1处理完成后可以查看MRSC全局表的状态,可以看到我已经为 DynamoDB 全局表配置了见证副本,见证副本可以降低成本,同时仍能提供多区域强一致性带来的韧性优势:
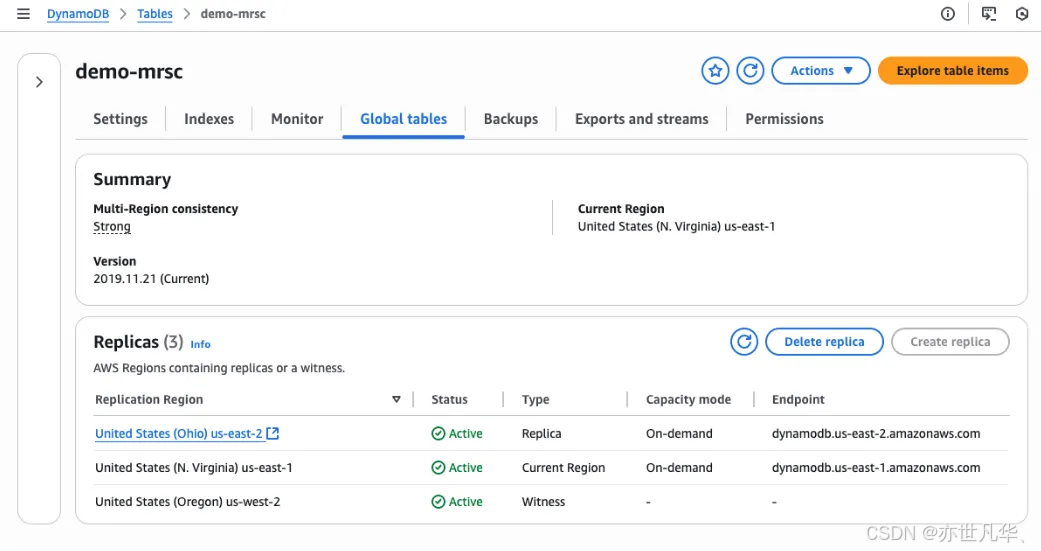
然后在应用程序中可以使用ConsistentRead来读取具有高度一致性的数据,以下是一个 Python 示例,对于需要最强韧性的操作,可以使用 ConsistentRead=True。对于那些不太关键的操作,如果最终一致性是可以接受的,则可以省略此参数,以提高性能并降低成本:
import boto3# Configure the DynamoDB client for your region
dynamodb = boto3.resource('dynamodb', region_name='us-east-2')
table = dynamodb.Table('demo-mrsc')pk_id = "demo#test123"# Read with strong consistency across regions
response = table.get_item(Key={'PK': pk_id},ConsistentRead=True
)print(response)交易日志和行情的应用
对于事务性严格要求的在线交易,一般采用 SQL 关系型数据库,保证金融交易事务的完整性和安全性。但在面对高并发查询和大规模数据存储时,往往难以满足实时性要求。因此,金融企业在设计数据库架构时,需要在数据一致性、查询性能和扩展能力之间做出权衡,选择适合高吞吐交易日志存储的解决方案。
NoSQL 数据库可以解决以上问题,在性能方面多个客户实践证明,在几十几百 TB 大规模数据量下,在读写请求达到几十万/秒时,仍然能保持毫秒级别的读写延迟。相对于传统的 SQL 数据库,Amazon DynamoDB 巨大的性能优势在此类场景下表现得淋漓尽致,以下是 Amazon DynamoDB 在交易日志场景下的表设计例子:

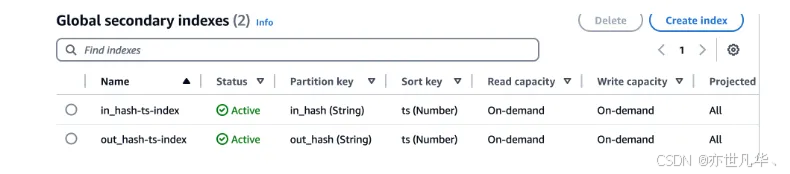
查询时,按照交易查询(主键),可以迅速查询到某个交易下的数据。此外,用户需要查询自己的交易,可以根据买卖方 id 创建二级索引,以加速查询:
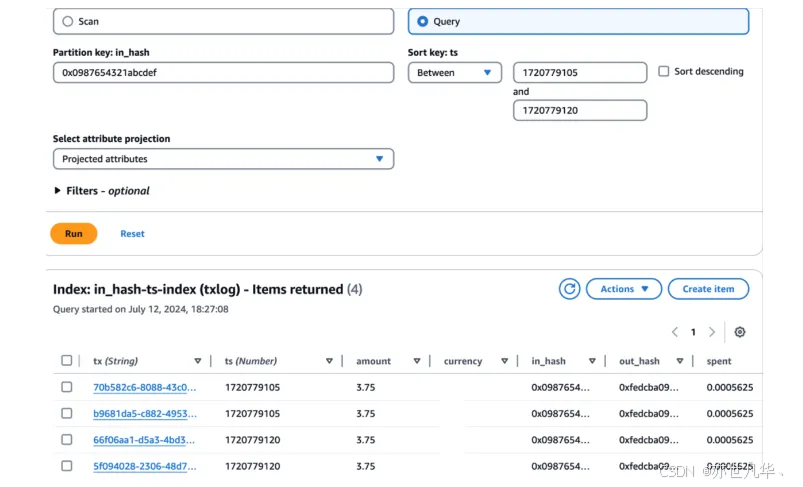
以下查询获取某个买方从 2024-07-12 18:11:45 到 2024-07-12 18:12:00 的交易记录,时间已经转换为 Unix 时间:
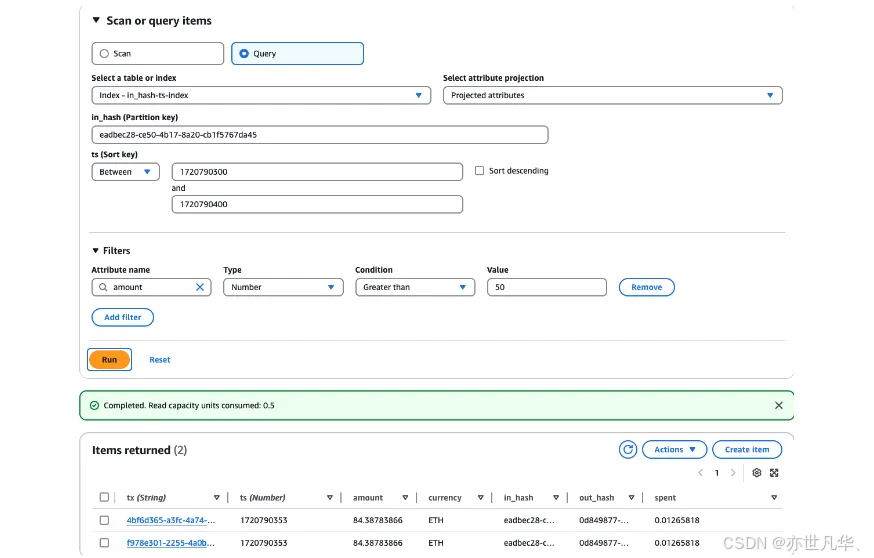
除了以上查询,还可以只根据买方或者卖方 id,不限制时间范围,查询所有交易。如果此用户交易很多,可能会消耗更多 DynamoDB 读容量,返回结果过大还需要分页。索引根据业务需要,选择合适的属性投影,减少容量消耗。另外,还可以根据某个字段过滤查询。例如,查询用户在某个时间范围内,金额大于 50 的交易。此查询使用全局二级索引,查询主键:买入用户+时间范围,加上过滤:amount > 50,如下图所示:
实际测试中,即使在请求量很高的情况下,仍然可以达到很低的查询延迟(通常<100ms)以下是写入延迟的指标,稳定在 3ms 左右:
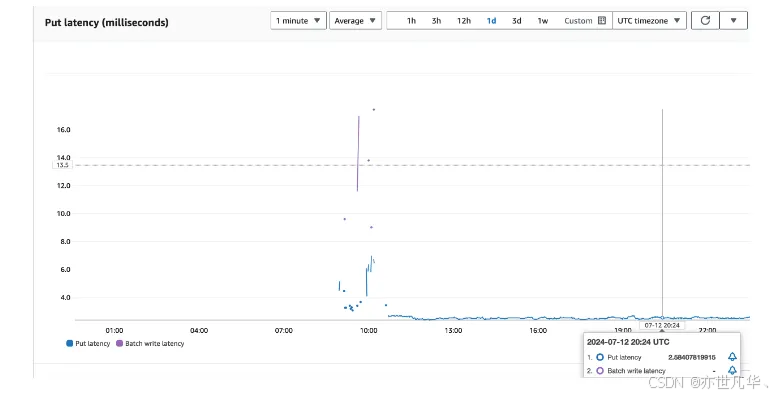
查询可以根据 Code+ 时间范围,获取 TICK 数据,并且以 TICK 数据计算 K 线数据,时间窗口可以变化,如某个证券在 1 分钟内的 K 线行情:
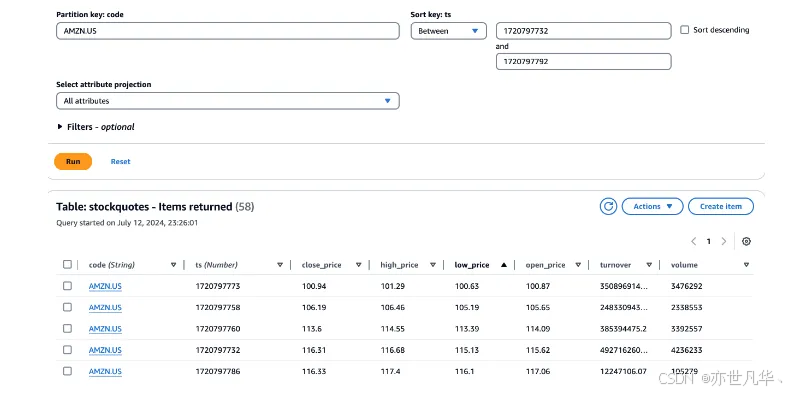
DynamoDB 获取出时间范围内的数据后,在应用程序使用聚合函数(min, max, sum)计算出 K 线图所需要的数据:
# Query the DynamoDB table for the stock data within the one-minute intervalresponse = table.query(KeyConditionExpression=boto3.dynamodb.conditions.Key('code').eq(stock_code + '.US') & boto3.dynamodb.conditions.Key('ts').between(current_time, next_time - 1),ProjectionExpression='open_price, close_price, high_price, low_price, volume, turnover',ScanIndexForward=True)if response['Items']:open_price = response['Items'][0]['open_price']close_price = response['Items'][-1]['close_price']high_price = max(item['high_price'] for item in response['Items'])low_price = min(item['low_price'] for item in response['Items'])volume = sum(item['volume'] for item in response['Items'])turnover = sum(item['turnover'] for item in response['Items'])输出 K 线数据结果,包含这段时间的开盘价、收盘价、最高价、最低价、成交量、换手:
{'timestamp': 1720797732, 'open': 115.62, 'close': 243.48, 'high': 294.84, 'low': 100.63, 'volume': Decimal('139436419'), 'turnover': 26287578456.22}写在最后
Amazon DynamoDB作为一款高度可扩展、全托管的 NoSQL 数据库服务,专为需要处理高并发、低延迟的大规模应用而设计。无论是在金融、零售、物联网、游戏、医疗还是社交媒体等行业,DynamoDB 都凭借其卓越的性能和灵活性,为企业提供了强大的数据管理能力。其自动扩展功能、内建的高可用性设计,以及与其他亚马逊云科技服务的深度集成,使得开发者可以专注于构建创新的应用,而不必担心数据库的管理和维护:

在未来随着数据需求的不断增长,DynamoDB将继续在推动行业创新、提升业务效率和确保系统稳定性方面发挥关键作用,如果你的应用场景需要高吞吐量和低延迟,DynamoDB无疑是一个值得考虑的理想选择。通过选择DynamoDB你不仅能够轻松应对现代应用程序的挑战,还能够确保企业在数据驱动时代的持续竞争力:

如果你觉得DynamoDB对你有帮助的话,可以去尝试一下:地址
以上就是本文的全部内容啦。最后提醒一下各位工友,如果后续不再使用相关服务,别忘了在控制台关闭,避免超出免费额度产生费用~