图解软件知识库体系
建立软件知识库体系的核心目标是实现知识沉淀、高效复用、降低协作成本、加速新人成长,其内容需要覆盖软件开发全生命周期的核心知识,并按 “理论 - 实践 - 经验 - 工具” 分层结构化。以下是一套完整的软件知识库体系框架,包含具体内容模块及作用说明:
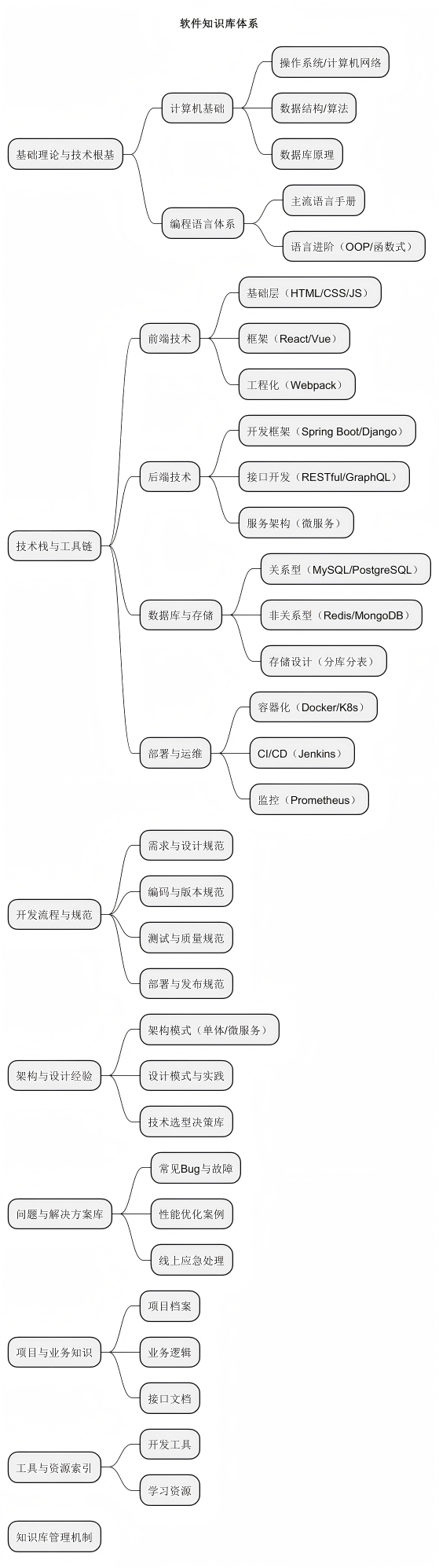
@startmindmap
title 软件知识库体系
* 基础理论与技术根基
** 计算机基础
*** 操作系统/计算机网络
*** 数据结构/算法
*** 数据库原理
** 编程语言体系
*** 主流语言手册
*** 语言进阶(OOP/函数式)
* 技术栈与工具链
** 前端技术
*** 基础层(HTML/CSS/JS)
*** 框架(React/Vue)
*** 工程化(Webpack)
** 后端技术
*** 开发框架(Spring Boot/Django)
*** 接口开发(RESTful/GraphQL)
*** 服务架构(微服务)
** 数据库与存储
*** 关系型(MySQL/PostgreSQL)
*** 非关系型(Redis/MongoDB)
*** 存储设计(分库分表)
** 部署与运维
*** 容器化(Docker/K8s)
*** CI/CD(Jenkins)
*** 监控(Prometheus)
* 开发流程与规范
** 需求与设计规范
** 编码与版本规范
** 测试与质量规范
** 部署与发布规范
* 架构与设计经验
** 架构模式(单体/微服务)
** 设计模式与实践
** 技术选型决策库
* 问题与解决方案库
** 常见Bug与故障
** 性能优化案例
** 线上应急处理
* 项目与业务知识
** 项目档案
** 业务逻辑
** 接口文档
* 工具与资源索引
** 开发工具
** 学习资源
* 知识库管理机制
@endmindmap一、基础理论与技术根基
(作用:为所有开发相关人员提供 “底层认知”,确保对技术本质的理解一致)
1. 计算机基础
- 核心概念:操作系统(进程 / 线程、内存管理、文件系统)、计算机网络(TCP/IP、HTTP/HTTPS、DNS、缓存机制)、数据结构(数组、链表、树、哈希表等)、算法(排序、查找、动态规划等)。
- 延伸:编译原理基础(解释器 / 编译器、语法分析)、数据库原理(ACID、事务、索引机制)。
2. 编程语言体系
- 主流语言手册:Python/Java/JavaScript/C++ 等的语法、特性、适用场景(如 “Python 适合快速开发,Java 适合企业级应用”)。
- 语言进阶:面向对象(封装 / 继承 / 多态)、函数式编程、异常处理、内存管理(垃圾回收机制)。
二、技术栈与工具链
(作用:聚焦 “具体技术如何用”,提供实操指南,避免重复踩坑)
1. 前端技术
- 基础层:HTML/CSS/JavaScript(ES6 + 特性)、DOM/BOM 操作。
- 框架与库:React/Vue/Angular 的核心原理、组件通信、状态管理(Redux/Vuex)、路由配置(React Router/Vue Router)。
- 工程化:Webpack/Vite 构建配置、ESLint/Prettier 代码规范、模块化(CommonJS/ES Module)。
- 扩展:移动端适配(响应式布局、Flex/Grid)、跨端开发(Flutter/React Native)、前端性能优化(懒加载、缓存策略)。
2. 后端技术
- 开发框架:Spring Boot(Java)、Django/Flask(Python)、Express(Node.js)的核心配置、依赖注入、中间件使用。
- 接口开发:RESTful API 设计规范、GraphQL 使用、接口文档工具(Swagger/OpenAPI)。
- 服务架构:微服务(Spring Cloud/Dubbo)、服务注册与发现(Eureka/Nacos)、API 网关(Gateway/Kong)。
3. 数据库与存储
- 关系型数据库:MySQL(索引优化、事务隔离级别、分库分表)、PostgreSQL(JSON 支持、高级查询)。
- 非关系型数据库:Redis(缓存策略、数据结构、持久化)、MongoDB(文档设计、查询优化)、Elasticsearch(全文检索、分词配置)。
- 存储设计:数据库建模(ER 图)、读写分离、缓存穿透 / 击穿 / 雪崩解决方案。
4. 部署与运维技术
- 容器化:Docker(镜像构建、容器编排)、Kubernetes(Pod/Service/Ingress 配置)。
- CI/CD:Jenkins/GitLab CI 的流水线配置(代码拉取→编译→测试→部署)、自动化脚本(Shell/Python)。
- 监控与日志:Prometheus+Grafana(指标监控)、ELK(日志收集与分析)、告警机制配置。
三、开发流程与规范
(作用:统一团队协作标准,减少沟通成本,确保代码质量与项目可控)
1. 需求与设计规范
- 需求分析:用户故事模板、需求评审 checklist(如 “是否明确用户场景?是否有边界条件?”)。
- 设计文档:PRD(产品需求文档)模板、技术设计文档(TDD)模板(含架构图、接口设计、数据库表结构)。
- 原型与 UI:Axure/Figma 原型交付标准、UI 切图规范、前端与设计协作流程。
2. 编码与版本规范
- 编码规范:各语言代码风格(如 Java 的 Google 编码规范、JavaScript 的 Airbnb 规范)、命名规则(类 / 函数 / 变量)、注释要求(类注释、复杂逻辑注释)。
- 版本控制:Git 操作规范(分支管理:master/develop/feature/hotfix;提交信息格式:“类型:描述”,如 “feat: 新增用户登录接口”)、代码合并流程(PR/MR 评审标准)。
3. 测试与质量规范
- 测试类型:单元测试(Junit/Pytest)、集成测试、接口测试(Postman/JMeter)、UI 测试(Selenium)的用例设计与执行标准。
- 质量门禁:代码覆盖率要求(如≥80%)、静态代码分析(SonarQube 规则配置)、Bug 分级标准(P0-P3 定义及修复时效)。
4. 部署与发布规范
- 环境划分:开发环境(dev)、测试环境(test)、预生产环境(staging)、生产环境(prod)的配置差异与访问权限。
- 发布流程:灰度发布 / 蓝绿发布操作步骤、回滚预案(如 “发布后 15 分钟内出现 P0 级问题立即回滚”)、发布记录模板(版本号、变更内容、执行人)。
四、架构与设计经验
(作用:沉淀 “为什么这么设计” 的决策逻辑,避免重复设计低效方案)
1. 架构模式
- 经典架构:单体架构、微服务架构、分布式架构的适用场景与优缺点(如 “用户量≤10 万可用单体,≥100 万考虑微服务”)。
- 架构组件:消息队列(Kafka/RabbitMQ)的使用场景(解耦 / 异步 / 削峰)、分布式锁(Redis/ZooKeeper)的实现与避坑。
2. 设计模式与实践
- 设计模式:23 种经典设计模式的应用场景(如 “单例模式用于工具类,工厂模式用于对象创建”)、反模式(如过度设计、紧耦合)。
- 系统设计案例:高并发场景(秒杀系统)、高可用场景(服务降级 / 熔断)、大数据场景(分库分表)的设计方案与演进过程。
3. 技术选型决策库
- 选型维度:列出 “技术选型 checklist”(如性能、社区活跃度、团队熟练度、成本)。
- 选型案例:记录历史项目的技术栈选型原因(如 “为什么用 PostgreSQL 而非 MySQL?因需支持 JSON 复杂查询”)、踩坑总结(如 “早期用 MongoDB 存储结构化数据,后期查询性能差,迁移至 MySQL”)。
五、问题与解决方案库
(作用:快速解决重复问题,沉淀 “踩坑经验”,减少排查时间)
1. 常见 Bug 与故障
- 分类整理:按技术栈划分(前端 Bug:跨域问题、内存泄漏;后端 Bug:空指针、接口超时;数据库 Bug:死锁、索引失效)。
- 解决方案:每个问题附 “现象 + 排查步骤 + 根因 + 修复方案”(如 “MySQL 死锁:现象是事务超时,排查用 show engine innodb status,修复需调整 SQL 执行顺序”)。
2. 性能优化案例
- 各环节优化:前端(首屏加载优化:懒加载 + CDN)、后端(接口响应优化:缓存 + SQL 优化)、数据库(查询优化:索引调整 + 分页优化)、服务器(负载均衡 + 资源扩容)。
- 数据支撑:附优化前后的指标对比(如 “优化前接口响应 300ms,优化后 50ms,通过 Redis 缓存热点数据实现”)。
3. 线上应急处理
- 应急预案:列出常见故障(服务器宕机、数据库挂掉、接口雪崩)的处理流程(如 “数据库宕机:1. 切换从库;2. 联系 DBA 修复主库;3. 同步数据”)。
- 复盘记录:每次线上问题的复盘报告(含时间线、影响范围、根因分析、改进措施)。
六、项目与业务知识
(作用:让团队快速理解 “业务是什么”,避免技术与业务脱节)
1. 项目档案
- 项目概述:每个项目的背景、目标用户、核心功能、里程碑时间线。
- 架构文档:项目技术架构图(组件关系、数据流)、部署架构图(服务器分布、网络拓扑)。
2. 业务逻辑
- 核心流程:用流程图 / 文字描述业务主线(如 “电商下单流程:选品→结算→支付→发货→确认收货”)。
- 业务术语:定义行业术语与内部缩写(如 “CRM:客户关系管理系统;UAT:用户验收测试”)。
- 接口文档:项目所有接口的详细说明(请求参数、响应格式、错误码、调用示例),推荐用 Swagger 自动生成并同步至知识库。
七、工具与资源索引
(作用:聚合高效工具与学习资源,降低 “找工具” 的时间成本)
1. 开发工具
- 工具清单:IDE(IntelliJ IDEA、VS Code)及插件推荐、调试工具(Chrome DevTools、Postman)、画图工具(ProcessOn、Draw.io)。
- 配置教程:常用工具的个性化配置(如 “VS Code 代码格式化配置”“Git 全局用户名设置”)。
2. 学习资源
- 书籍推荐:按领域分类(如 “计算机网络:《TCP/IP 详解》;前端:《React 设计模式与最佳实践》”)。
- 课程与社区:优质在线课程(Coursera、极客时间)、技术社区(Stack Overflow、掘金)的使用指南。
- 内部培训资料:团队分享的 PPT、视频录像、技术博客链接。
八、知识库管理机制
(作用:确保知识 “活起来”,而非静态文档)
- 责任人制度:每个模块指定 1-2 名负责人,负责更新与审核(如 “前端技术模块由前端组长负责”)。
- 更新频率:明确更新触发条件(如 “新功能上线后 3 天内更新项目文档”“解决线上问题后 24 小时内补充故障库”)。
- 检索与权限:用知识库工具(如 Confluence、语雀、Notion)实现关键词检索,按角色设置权限(如 “新人可看基础文档,核心架构文档仅核心成员可见”)。
总结
软件知识库体系的核心是 “从基础到实战,从技术到业务,从规范到经验” 的全链路覆盖,且需通过 “专人维护 + 定期更新” 保持活力。对于团队而言,初期可优先搭建 “技术栈工具链 + 开发规范 + 问题库” 这三个高频使用模块,再逐步完善其他部分;对于个人,则可聚焦自身技术领域,优先沉淀 “常用技术手册 + 踩坑记录”,再拓展到全体系。