分布式锁那些事
在并发编程中,当多个线程需要访问共享可变资源时,需要使用锁来保证线程安全。扩展到分布式系统中,当多个节点可能会同时访问相同的资源时,为了避免数据不一致和竞争条件的发生,也需要使用分布式锁来进行协调。
本篇主要对分布式锁的设计原则进行探讨,并对几种常用的解决方案做简要分析。
基于 Redis 的实现原理
基础方案
关于分布式锁介绍最多的应该就是基于 Redis 的实现了,在单节点场景下,可以通过如下命令获取分布式锁:
SET key value NX PX 30000
命令含义如下:
- NX(not exist) 表示只有在 key 不存在时才能设置成功,避免重复加锁。
- PX 表示过期时间为 30s,保证能及时释放锁。
- value 是一个全局唯一的随机数,保证在崩溃恢复时避免误删。
可以看到 Redis 提供的命令可以满足以下特性:
- 互斥性:通过 NX 保证 key 的唯一,从而保证互斥。
- 活性: PX 设置了锁的过期时间,保证锁一定会被释放掉,避免死锁。
- 安全性:通过全局唯一随机数,保证只有持有锁的客户端才能删除锁。
虽然有上述特性,但该方案存在单点故障问题,不满足高可用性。Redis 不是强一致性的存储服务,其主副本同步是异步的,没办法通过增加副本的方式满足上述需求,为此有人提出了 RedLock 算法来满足高可用。
RedLock 算法
Redlock 算法要求使用多个 Redis 节点(通常是 5 个)实现高可用的分布式锁服务。获取锁的步骤如下:
- 客户端获取当前的毫秒时间戳
- 使用相同的 key、value 按顺序从从每个节点获取锁。这一步需要设置一个相对于锁的过期时间较小的超时时间,比如锁的过期时间为 10s,我们可以设置超时时间为 5 ~ 50ms,避免客户端一直在等待获取锁。
- 只有在多数节点获取锁成功(比如 3 个节点加锁成功)以及总耗时小于锁的初始有效期时,才可以认为获取锁成功。
- 如果加锁成功,为了保证所有节点的锁能在同一时间失效,锁的过期时间为 初始过期时间减去加锁耗时。比如加第一个节点的锁时超时时间为 10s,加完耗时 5ms,那么第二个锁的超时时间应该是 10s-5ms = 9.995s,以此类推。
- 如果获取锁失败,会将所有实例的锁释放掉。
不知道大家是否有和笔者一样的感受,在学习这个算法时感觉非常绕。首先,RedLock 算法的实现依赖至少 5 个独立的 Redis 节点,运维相对麻烦。其次也是最重要的是,RedLock 算法本身是依赖于系统时钟的,而在分布式系统中,系统时钟和网络是最不可靠的两个因素,它并不能提供足够的安全性。
我们假设有 A、B、C、D、E 共 5 个 Redis 节点:
- 有客户端 1 和 2 来获取锁
- 客户端 1 从 A、B、C 获取到了锁。
- C 节点的系统时钟向前发生了偏移,这会导致 C 节点的锁提前过期。
- 客户端 2 从 C、D、E 节点成功获取锁。
- 客户端 1 和 2 都会持有锁。
可以看到,RedLock 算法并不能保证在分布式环境下的安全性。
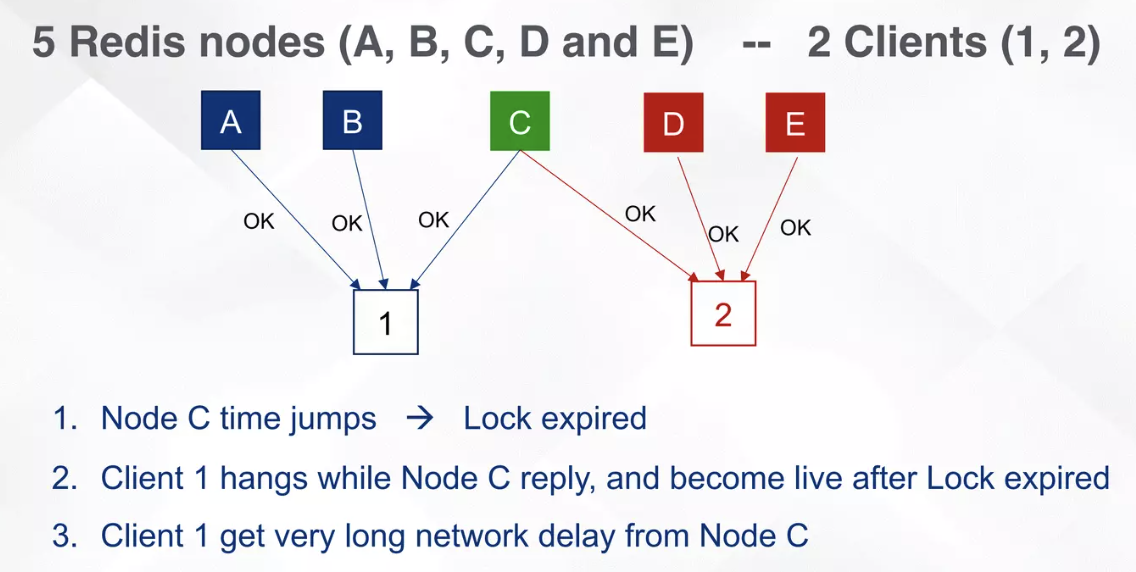
对于 RedLock 算法,《数据密集型应用系统设计》的作者 Martin Kleppmann 在其文章中 How to do distributed locking做了详细的分析。虽然 RedLock 算法的作者进行了一些反驳,但也承认对于时钟偏移的情况 RedLock 算法是无法解决的。
在笔者看来,Redis 本身并不是一个强一致性的存储服务,更多的是在缓存等数据准确性要求不高的场景中使用,本身不适合分布式锁这种对数据的一致性、服务的高可用性有极高要求的场景。RedLock 算法是为了基于 Redis 实现一个高可用分布式锁服务强行设计出的一个解决方案,因此整个方案显得非常不优雅。
分布式锁的设计思路
Redis 在其官方文档Redis 中提到分布式锁要满足安全性(Safety)和活性(Liveness),具体有三个要求:
- Mutual exclusion 互斥:在任何时刻,只有一个客户端持有锁。
- Deadlock free 无死锁:即使持有锁的客户端崩溃或发生分区,其他客户端也能获取锁。
- Fault tolerance 容错性:只要大多数 Redis 节点都启动,客户端就可以获取和释放锁。其实就是要求分布式锁服务要具备高可用。
除此之外一些其他特性也需要做一定的考虑:
- 同源性:加解锁只能由同一客户端执行。不能出现 A 加的锁被 B 解锁的情况。
- 高性能:加解锁的性能要好,这要求分布式锁服务具备低延迟和高吞吐量。
- 非阻塞:加锁不能无限期等待。
上述要求最核心的一条是要满足互斥性,这也是最难的。即使分布式锁服务能满足上述所有特性,也会因为程序本身的运行原因出现问题。Martin Kleppmann 在其文章中提出了一个典型的场景,下面是一段分布式锁的伪代码:
// THIS CODE IS BROKEN
function writeData(filename, data) {var lock = lockService.acquireLock(filename, timeout);if (!lock) {throw 'Failed to acquire lock';}try {var file = storage.readFile(filename);var updated = updateContents(file, data);storage.writeFile(filename, updated);} finally {lock.release();}
}
直观来看,代码看起来没什么问题。但实际运行是会出现如下情况:
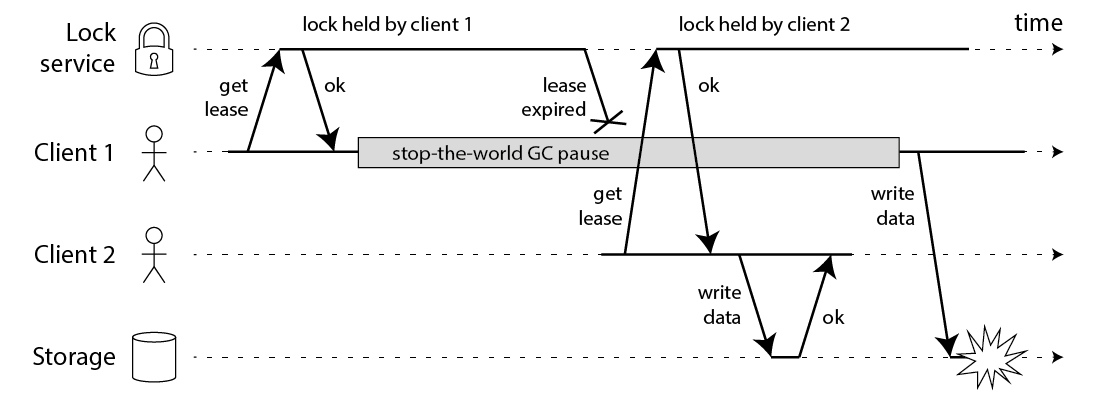
- 客户端 1 获取锁后执行任务
- 客户端 1 发生 GC,然后锁自动过期
- 客户端 2 获取到锁执行任务
- 客户端 1 GC 结束,认为自己还持有锁,因此继续执行其任务
此时客户端 1 和客户端 2 都持有锁执行任务,导致数据不一致。
基于此种情况,Martin Kleppmann 提出了一个解决方案,即引入一个单调递增隔离令牌(fence token)来保证只有一个客户端持有锁。具体来说,在获取锁时,客户端会同时获取一个唯一的令牌,并在执行任务时将该令牌附加到请求中。存储服务在处理请求时会校验令牌,确保只有持有最新令牌的客户端才能执行操作。
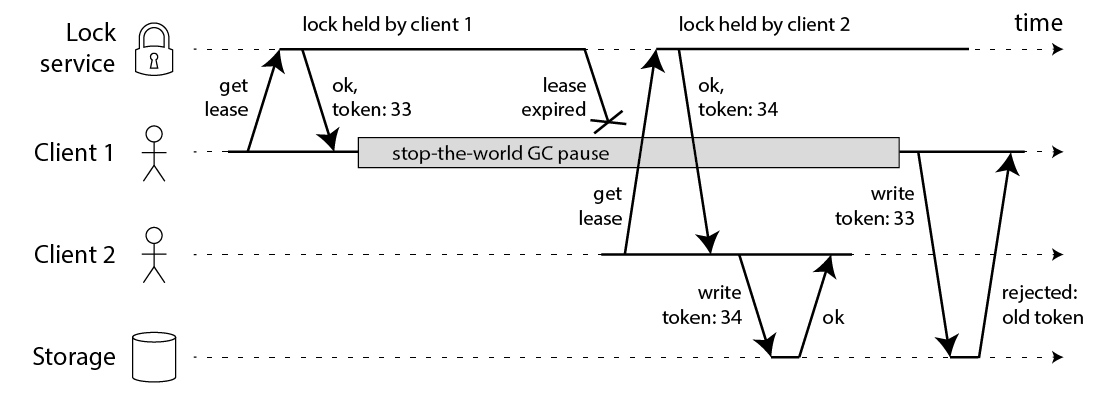
可以看到这本质上是一种类似乐观锁的机制,其要求生成锁的服务能够提供一个 token 令牌,同时读写数据时存储服务能够校验令牌。Zookeeper 的顺序节点的 zxid 是单调递增的,符合这一要求,这也是 Martin Kleppmann 所推荐的实现方案。
基于 Zookeeper 的实现原理
Zookeeper 组织数据的方式类似于操作系统的文件系统,其存储数据的节点被称为 znode,使用类似文件路径的形式表示 parent/subnode。
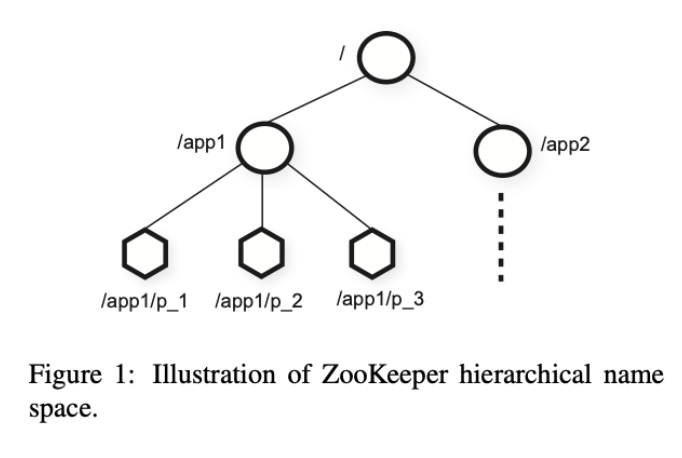
Zookeeper 的节点有两类:
- 正常节点(Regular):正常存储数据的节点,需求通过客户端读写来增删节点。
- 临时节点(Ephemeral):临时节点,客户端会话断开后会自动删除。
Zookeeper 还提供了一个 sequential 标签,用于在创建节点时标识其是否是顺序节点。如果是,zookeeper 会在节点名称后追加一个默认为 10 位的单调递增数字。下图是一个例子,我们使用 locknode/{id}- 作为前缀,生成的节点名称示例如下:

我们可以使用临时顺序(Ephemeral Sequential)节点和 Zookeeper 提供的 API 来实现分布式锁。一个典型的加锁流程如下:
- 调用 create() API,创建一个临时顺序节点,代表申请锁:
create(l + “/lock-”, EPHEMERAL|SEQUENTIAL)。 - 调用 getChildren() API,检查是否为最小子节点:
getChildren(l, false)。 - 如果是最小子节点,直接返回,表示获取锁成功,可以执行任务
- 如果不是,则调用 exists() API,监听其前一个节点是否存在:
exists(p, true)。 - 当监听的节点已经被删除时(代表其前一个节点已经释放锁),则重复步骤 2,尝试获取锁。
伪代码表示如下:
Lock
1 n = create(l + “/lock-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for watch event
6 goto 2
Unlock
1 delete(n)
可以看到,其核心思想是:
- 利用临时节点特性,采用类似 keepAlive 的机制而不是过期时间机制来保证锁失效,持有锁的客户端断开连接时,Zookeeper 会自动删除临时节点,从而保证释放锁。
- 利用顺序节点特性,生成单调递增的令牌。
- 利用顺序节点特性,每次只允许排号最小的客户端获取锁,其他客户端需要等待,保证互斥性。
- 利用 watch 机制避免惊群效应(herd effect)。
- zookeeper 自身就是高可用、强一致性的存储服务,能够满足分布式锁的高可用性和一致性要求。
MegaEase Cloud 平台就使用了 Zookeeper 来实现分布式锁服务,对于 Java 生态,spring-integration-zookeeper 和 Apache Curator 都提供了更高层次的 API 封装,简化了 Zookeeper 的使用,可以按需选择相应的方案。
基于 etcd 的实现原理
etcd 是一个基于 Raft 协议的高可用、强一致性的键值存储服务,相比 Zookeeper,etcd 更加轻量级,使用 HTTP/gRPC 作为通信协议,支持 JSON 格式的数据存储和查询,易于与现代云原生应用集成,具有更好的易用性和高性能。
Etcd 的一些机制赋予了其实现分布式锁的能力:
- Lease 租约机制:为 key-value 设置租约,租约到期后会将其自动删除;同时也支持续约。
- Revision 机制:每个 key 都会被分配一个递增的版本号,能够支持对 key 的历史版本进行访问。
- Watch 机制:支持对 key 的变化进行监听,能够及时感知锁的状态变化。
- Prefix 机制:支持对 key 的前缀进行操作,能够方便地管理一组相关的 key。
可以看到除了 Etcd 使用的是租约,即过期时间来控制锁的失效外,其他机制和 Zookeeper 的实现原理类似。
除了上述机制的基本 API,Etcd 在 3.2 版本中引入了分布式锁的支持,在 3.5 版本提供了官方指导,其提供了 lock 命令使用示例如下:
$ export ETCDCTL_API=3
$ etcdctl lock my-lock
my-lock/694d98ad9bc42105
在实际项目中,我们可以根据相关语言提供的库,比如 Go 语言的 etcd/client/v3/concurrency 包、Java 的 jetcd 包来简化分布式锁的实现。