【DDIA】第九章:一致性与共识
1. 章节介绍
本章聚焦分布式系统中一致性与共识这一核心问题,探讨在网络延迟、节点崩溃、分区等故障场景下,如何确保数据副本的一致性及节点间的共识达成。通过分析不同一致性模型(如最终一致性、线性一致性)、顺序保证机制(因果关系、全序广播)及分布式事务协议(如两阶段提交),揭示构建容错系统的底层逻辑与实践权衡,为设计高可靠分布式系统提供理论与技术支撑。
| 核心知识点 | 面试频率 |
|---|---|
| 线性一致性 | 高 |
| 全序广播 | 高 |
| 两阶段提交(2PC) | 中 |
| 共识算法(Paxos/Raft) | 高 |
| 因果一致性 | 中 |
| 最终一致性 | 低 |
| 分布式锁实现 | 中 |
2. 知识点详解
2.1 一致性保证
2.1.1 最终一致性(收敛)
- 定义:停止写入后,经过一段时间,所有副本最终收敛到相同值。
- 特点:
- 弱保证,不承诺收敛时间。
- 适用于对实时一致性要求低的场景(如社交网络动态)。
- 问题:高并发或故障时易出现读写不一致,增加开发复杂度。
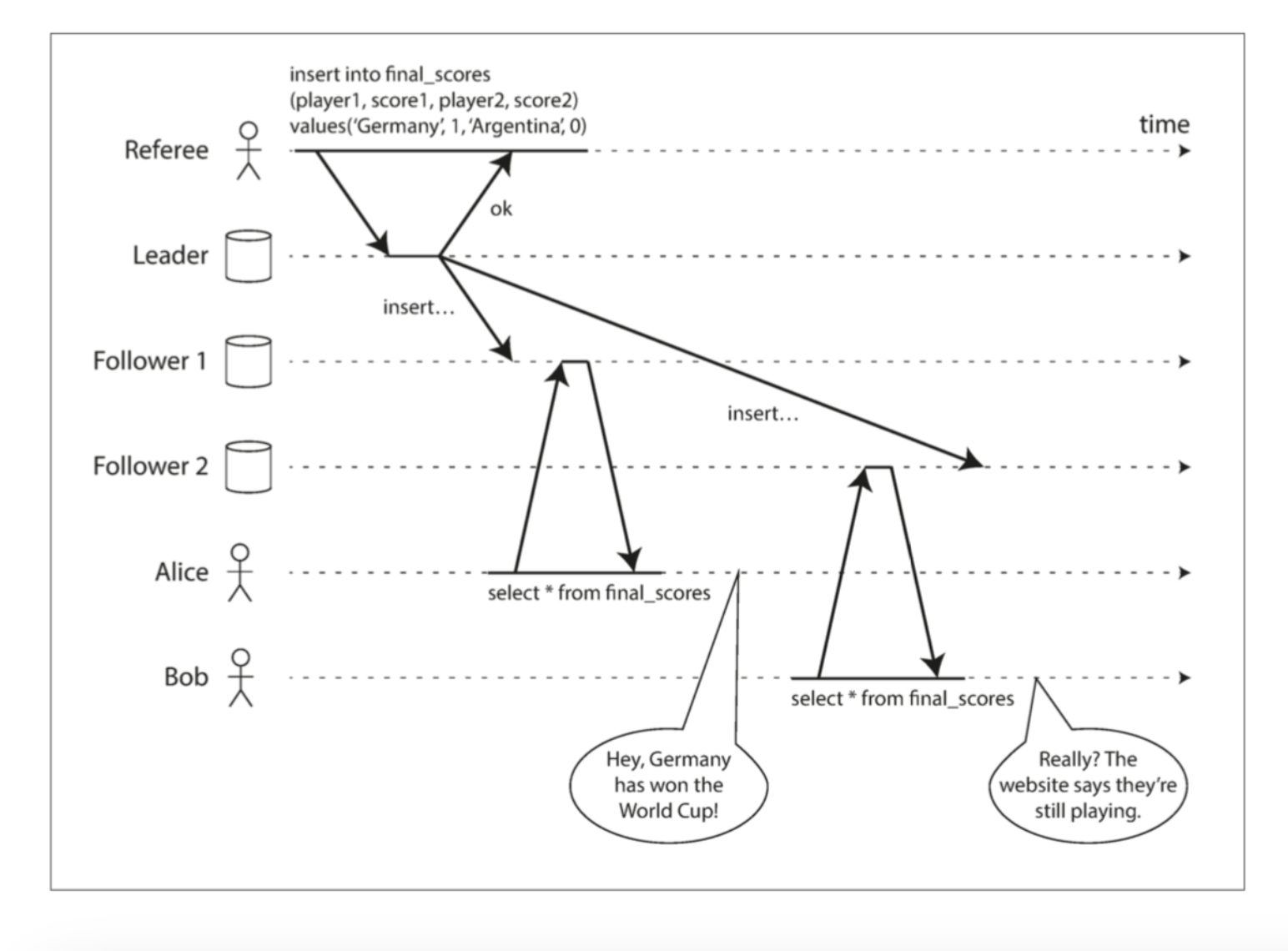
2.1.2 线性一致性(强一致性)
- 定义:系统表现为单一数据副本,所有操作原子性生效,读取需返回最新写入值。
- 关键特征:
- 操作按时间顺序推进,不可回溯(如读取不能返回比之前更旧的值)。
- 提供“新鲜度保证”,符合单线程程序的直觉。
- 实现方式:
- 单主复制(需确保 leader 唯一性及同步复制)。
- 共识算法(如 ZooKeeper 的 Zab 协议)。
- 应用场景:
- 分布式锁(避免脑裂)。
- 唯一性约束(如用户名注册)。
- 代价:
- 性能受网络延迟限制。
- 网络分区时需牺牲可用性(如 CAP 权衡)。
# 线性一致性读写模拟(单主复制)
class LinearizableStore:def __init__(self):self.value = 0self.lock = threading.Lock() # 确保操作原子性def write(self, v):with self.lock:self.value = v # 写入时加锁,确保原子性def read(self):with self.lock:return self.value # 读取时加锁,确保获取最新值
2.2 顺序保证
2.2.1 因果关系与因果一致性
- 因果关系:事件存在“因→果”依赖(如问题发布先于回答),定义偏序(并发事件无顺序)。
- 因果一致性:系统服从因果顺序,比线性一致性弱但性能更优。
- 实现:通过版本向量或兰伯特时间戳追踪因果依赖。
2.2.2 全序广播
- 定义:消息按相同顺序可靠传递到所有节点,满足“可靠交付”和“全序交付”。
- 特性:
- 消息顺序不可篡改,送达后顺序固化。
- 等价于状态机复制(所有节点按相同顺序执行操作)。
- 应用:数据库复制、分布式事务、领导选举。
2.3 分布式事务与共识
2.3.1 两阶段提交(2PC)
- 流程:
- 协调者发送“准备”请求,参与者反馈是否可提交。
- 所有参与者同意则发送“提交”,否则发送“中止”。
- 问题:
- 协调者崩溃时,参与者进入“存疑”状态,持有锁阻塞其他事务。
- 阻塞问题(非容错)。
2.3.2 容错共识算法(如 Raft)
- 核心思想:通过“领导者选举”和“日志复制”确保多数节点达成一致。
- 关键机制:
- 任期(Term):避免脑裂,每个任期只有一个 leader。
- 日志复制:leader 向 follower 同步日志,需多数确认。
- 优势:解决 2PC 的阻塞问题,容忍少数节点故障。
# Raft 领导者选举核心逻辑(简化)
class RaftNode:def __init__(self, node_id):self.node_id = node_idself.term = 0self.state = "follower" # follower/candidate/leaderself.vote_count = 0def request_vote(self, candidate_term):if candidate_term > self.term:self.term = candidate_termself.vote_count = 1return True # 投票给 candidatereturn Falsedef start_election(self, nodes):self.state = "candidate"self.term += 1self.vote_count = 1 # 给自己投票for node in nodes:if node != self and node.request_vote(self.term):self.vote_count += 1if self.vote_count > len(nodes) // 2:self.state = "leader" # 获得多数票,成为 leader
2.4 协调服务(如 ZooKeeper)
- 核心功能:
- 线性一致的原子操作(如 CAS)。
- 全序操作日志(zxid 标识顺序)。
- 临时节点(用于失效检测)。
- 应用:分布式锁、服务发现、配置管理。
3. 章节总结
本章围绕分布式系统的一致性与共识展开,核心结论包括:
- 一致性模型从弱到强为:最终一致性 → 因果一致性 → 线性一致性,强一致性需牺牲性能与可用性。
- 全序广播是实现线性一致性和共识的基础,等价于状态机复制。
- 2PC 是分布式事务的经典方案,但存在阻塞问题;容错共识算法(如 Raft)通过多数投票解决容错问题。
- 协调服务(如 ZooKeeper)基于共识算法,提供高可靠的分布式协调能力。
4. 知识点补充
4.1 相关知识点
- CAP 定理:分布式系统无法同时保证一致性(C)、可用性(A)和分区容错性(P),需在网络分区时权衡 C 与 A。
- BASE 理论:最终一致性的工程实践总结,包括基本可用(Basic Availability)、软状态(Soft State)、最终一致性(Eventual Consistency)。
- Paxos 与 Raft 区别:Paxos 理论严谨但复杂,Raft 以易理解为目标,将流程拆分为选举、日志复制等阶段。
- 脑裂问题:多主节点场景下,节点因网络分区误认为自己是唯一 leader,导致数据冲突,需通过共识算法避免。
- 最终一致性实现策略:读修复、反熵同步、版本控制(如 Dynamo 的向量时钟)。
4.2 最佳实践:基于 ZooKeeper 实现分布式锁
分布式锁需满足互斥性、容错性和安全性。使用 ZooKeeper 实现的步骤如下:
- 创建临时节点:客户端在
/locks目录下创建临时有序节点(如lock-00000001),临时节点确保客户端崩溃后自动释放锁。 - 获取锁逻辑:
- 客户端创建节点后,检查自己是否为
/locks下序号最小的节点,若是则获得锁。 - 若不是,监听序号更小的前一个节点,前节点删除时触发重新检查。
- 客户端创建节点后,检查自己是否为
- 释放锁:完成操作后删除自身节点,或客户端崩溃后由 ZooKeeper 自动删除。
优势:避免死锁(临时节点特性),支持公平锁(按序号获取),容忍节点故障。适用于分布式任务调度、资源竞争场景(如秒杀系统的库存控制)。
4.3 编程思想指导:一致性与性能的权衡艺术
在分布式系统设计中,一致性与性能的权衡是核心思想。需根据业务场景选择合适的模型:
- 明确一致性需求:金融交易需线性一致性(如转账),而社交动态可接受最终一致性。
- 拆分读写路径:读多写少场景下,用主从复制(主写从读),通过异步复制提升读性能,牺牲部分一致性。
- 引入中间层:使用缓存(如 Redis)分担读压力,但需处理缓存与数据库的一致性(如过期时间、更新策略)。
- 分区与副本策略:按业务维度分区(如用户 ID 哈希),降低单节点负载;副本数根据容错需求配置(3 副本可容忍 1 节点故障)。
- 故障预案:设计降级策略(如网络分区时只读本地副本),避免雪崩效应;通过监控及时发现一致性异常(如副本延迟超标)。
例如,电商系统的商品详情页:采用最终一致性,主库写入后异步同步到从库和 CDN,优先保证读性能;而订单支付则使用线性一致性,通过共识算法确保资金安全。
5. 程序员面试题
5.1 简单题
题目:解释线性一致性与最终一致性的核心区别。
答案:
- 线性一致性:系统表现为单一副本,写入后所有读取必须返回最新值,提供实时一致性。
- 最终一致性:副本可能暂时不一致,停止写入后经一段时间收敛到相同值,不保证实时性。
- 核心区别:线性一致性强调节点状态实时统一,最终一致性允许短期不一致但保证长期收敛。
5.2 中等难度题
题目:比较两阶段提交(2PC)与三阶段提交(3PC)的优缺点。
答案:
-
2PC 流程:准备阶段(协调者收集投票)→ 提交/中止阶段(执行决定)。
优点:实现简单,确保原子性。
缺点:协调者崩溃时参与者阻塞,无法容错网络分区。 -
3PC 改进:引入“预提交”阶段,参与者在准备后进入预提交状态,协调者需广播“预提交”和“提交”两次指令。
优点:减少阻塞概率,网络分区时可超时中止。
缺点:依赖严格的超时机制,实际环境中(网络延迟不稳定)仍可能出现一致性问题,实现复杂。 -
结论:3PC 理论上优化了 2PC 的阻塞问题,但实际中因环境复杂性,仍以 2PC 为主流(如 XA 事务)。
题目:全序广播如何保证消息传递的可靠性和顺序性?
答案:
全序广播通过以下机制保证可靠性和顺序性:
-
可靠性:
- 消息持久化:发送方将消息写入本地日志,确保崩溃后可重发。
- 重试机制:接收方未确认时,发送方持续重试,直至所有节点确认接收。
-
顺序性:
- 全局序列号:每个消息分配唯一序列号(如基于共识算法生成),节点按序列号排序处理。
- 因果一致性保障:通过兰伯特时间戳或版本控制,确保因果依赖的消息按顺序传递。
例如,Raft 算法中,leader 为每个消息分配递增日志索引,follower 严格按索引顺序复制日志,从而实现全序广播。
5.3 高难度题
题目:Raft 算法如何保证日志的安全性(即所有节点最终达成一致日志)?
答案:
Raft 通过以下机制保证日志安全性:
-
领导者选举约束:
- 候选者需获得多数节点投票才能成为 leader。
- 投票时,节点仅给日志至少与自身一样新的候选者投票(“日志完整性”检查),避免旧日志节点成为 leader。
-
日志复制机制:
- Leader 向 follower 发送包含日志项和任期的 AppendEntries 请求,follower 仅在日志项的前任匹配自身日志时才接受。
- 不匹配时,leader 回溯日志并重试,直至 follower 日志与 leader 一致。
-
Commit 确认:
- 日志项需被多数节点复制后,leader 才标记为 committed,并通知所有节点应用该日志。
- 新 leader 需先提交当前任期的日志项,才能提交前任任期的日志,避免旧日志被覆盖。
这些机制确保无论节点故障或网络分区,最终所有节点的日志都会收敛到一致状态。
题目:在网络分区场景下,如何设计一个兼顾可用性和数据一致性的分布式缓存系统?
答案:
设计方案如下:
-
分区策略:按 key 哈希分片,每个分片有主副本(负责写入)和多个从副本(负责读取)。
-
一致性保证:
- 写入操作:仅主副本处理,同步复制到至少一个从副本(确保分区时主副本所在分区仍有可用副本)。
- 读取操作:正常情况下读从副本(提升性能),网络分区时,若主副本所在分区不可达,允许读本地从副本(牺牲一致性换可用性)。
-
分区恢复机制:
- 分区修复后,主副本通过反熵机制同步缺失数据到其他分区的副本。
- 使用版本向量标记数据版本,解决冲突(如取最新版本或合并)。
-
降级策略:
- 检测到分区时,自动切换为“本地优先”模式,限制跨分区操作(如禁止聚合查询)。
- 记录分区期间的“脏数据”,恢复后通过后台任务校验一致性(如与数据库比对)。
该方案在分区时优先保证可用性(本地读写),恢复后通过异步同步修复一致性,适合电商商品缓存等场景(允许短期不一致,但需最终正确)。