Query通过自注意力机制更新(如Transformer解码器的自回归生成)的理解
今天调试代码发现,streampetr的自注意力–> 交叉注意力后,query的梯度消失了。
突然意识到,query是通过前向进行的更新,而不是依靠反向传播的梯度计算。
student
self.use_checkpoint and self.training
self_attn: True False False
self_attn梯度状态: False False False
cross_attn: False True True
self.use_checkpoint and self.training
self_attn: True False False
self_attn梯度状态: False False False
cross_attn: False True True
self.use_checkpoint and self.training
self_attn: True False False
self_attn梯度状态: False False False
cross_attn: False True True
self.use_checkpoint and self.training
self_attn: True False False
self_attn梯度状态: False False False
cross_attn: False True True
self.use_checkpoint and self.training
self_attn: True False False
self_attn梯度状态: False False False
cross_attn: False True True
self.use_checkpoint and self.training
self_attn: True False False
self_attn梯度状态: False False False
cross_attn: False True True
一共有六层tranformer,
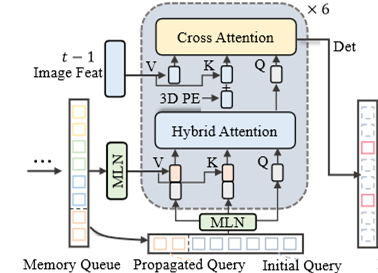
for layer in self.operation_order:if layer == 'self_attn':if temp_memory is not None:temp_key = temp_value = torch.cat([query, temp_memory], dim=0)temp_pos = torch.cat([query_pos, temp_pos], dim=0)else:temp_key = temp_value = querytemp_pos = query_posprint("self_attn:", query.requires_grad, temp_key.requires_grad,temp_value.requires_grad) query = self.attentions[attn_index](query,temp_key,temp_value,identity if self.pre_norm else None,query_pos=query_pos,key_pos=temp_pos,attn_mask=attn_masks[attn_index],key_padding_mask=query_key_padding_mask,**kwargs)attn_index += 1identity = queryprint("self_attn梯度状态:", query.requires_grad, temp_key.requires_grad, temp_value.requires_grad)elif layer == 'norm':query = self.norms[norm_index](query)norm_index += 1elif layer == 'cross_attn':print("cross_attn:", query.requires_grad, key.requires_grad,value.requires_grad) query = self.attentions[attn_index](query,key,value,identity if self.pre_norm else None,query_pos=query_pos,key_pos=key_pos,attn_mask=attn_masks[attn_index],key_padding_mask=key_padding_mask,**kwargs)attn_index += 1identity = queryelif layer == 'ffn':query = self.ffns[ffn_index](query, identity if self.pre_norm else None)ffn_index += 1思考1:交叉注意力中query没有梯度
在交叉注意力中,Query通常来自目标序列(如解码器的隐藏状态),而Key/Value来自源序列(如CNN骨干网络提取的图像特征)。若Query的梯度被截断(requires_grad=False),其更新方式也就不是通过计算输出特征后的损失了!
因为:考虑到更新机制的数学表达
- 梯度回传路径:
交叉注意力的输出损失 ( \mathcal{L} ) 对Key/Value的梯度为:
∂L∂K=∂L∂O⋅∂O∂K,∂L∂V=∂L∂O⋅∂O∂V \frac{\partial \mathcal{L}}{\partial K} = \frac{\partial \mathcal{L}}{\partial O} \cdot \frac{\partial O}{\partial K}, \quad \frac{\partial \mathcal{L}}{\partial V} = \frac{\partial \mathcal{L}}{\partial O} \cdot \frac{\partial O}{\partial V} ∂K∂L=∂O∂L⋅∂K∂O,∂V∂L=∂O∂L⋅∂V∂O
其中 ( O ) 为注意力输出。Query的梯度被显式截断(( ∂L∂Q=0\frac{\partial \mathcal{L}}{\partial Q} = 0∂Q∂L=0))。
Query更新需要依靠自注意力路径:在解码器中,Query可先通过自注意力更新(如Transformer解码器的自回归生成),再作为交叉注意力的输入。
好处和坏处是什么?
| 机制 | 梯度来源 | 更新方式 | 典型应用 |
|---|---|---|---|
| 交叉注意力直接梯度 | Q/K/V均参与 | 端到端反向传播 | 普通Transformer编码器-解码器 |
| 间接路径(自注意力/MLN) | 自注意力或时序损失 | 递归或隐式优化 | StreamPETR、DualAD |
| 特征适配(K/V更新) | 仅K/V梯度 | 源序列特征适配固定Query | 多模态融合任务 |
思考2:如何实现自回归?
在Transformer架构中,Query(Q)通过自注意力机制更新的过程是解码器实现自回归生成的核心环节。
自注意力机制的基本原理
自注意力机制通过计算序列内部元素间的动态权重,实现对上下文信息的动态聚焦。具体流程如下:
- 线性变换生成Q/K/V:
输入序列通过三个独立的线性层分别生成Query(Q)、Key(K)、Value(V)矩阵。其中:- Q:表示当前需要计算注意力的位置(如解码器中已生成的token)。
- K/V:提供序列中所有位置的上下文信息(编码器输出或解码器历史token)
- 注意力权重计算:
通过Q与K的点积计算相似度,缩放后应用Softmax得到注意力权重:
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中 ( d_k ) 为Key的维度,缩放因子用于防止点积结果过大导致梯度不稳定。 - 加权聚合Value:
注意力权重与V矩阵相乘,生成当前Query的上下文感知表示。
自注意力机制中的Query更新原理
自注意力机制通过计算序列内部元素间的动态权重,直接调整Query的表示。其关键步骤如下:
- Query生成:当前解码器位置的隐藏状态(或输入序列的嵌入向量)通过线性变换生成Query向量(Q)。
- 注意力权重计算:Q与所有Key(K)向量计算点积相似度,经Softmax归一化后得到注意力权重。这些权重决定了当前Query需要从哪些位置的Value(V)向量中聚合信息。
- 加权聚合:注意力权重与V向量加权求和,生成更新后的Query表示。这一步骤本质上是基于上下文信息的动态重构,而非依赖梯度下降。
示例:
在解码器生成序列时,第( t )步的Query ( Q_t )会通过自注意力聚合前( t-1 )步的历史信息(如已生成的词),从而更新为 ( Q_t’ )。这一更新仅依赖前向计算,无需反向传播。
无需损失计算的更新场景
以下两种情况中,Query的更新不依赖损失函数:
- 自回归生成(如GPT):解码器通过掩码自注意力逐步生成序列,每一步的Query基于历史信息更新,用于预测下一个词。此时Query的更新由注意力权重动态驱动,而非损失梯度。
- KV Cache机制:在推理阶段,模型通过缓存历史Key/Value(KV Cache)复用计算结果,新生成的Query直接与缓存交互,更新自身表示。这一过程完全在前向传播中完成。
数学表达:
更新后的Query ( QnewQ_{\text{new}}Qnew )可表示为:
Qnew=softmax(QKTdk)V
Q_{\text{new}} = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V
Qnew=softmax(dkQKT)V
其中( Q, K, V )均来自当前或历史状态,无梯度参与。
与反向传播更新的区别
| 更新方式 | 依赖梯度 | 更新触发条件 | 典型场景 |
|---|---|---|---|
| 自注意力前向更新 | 否 | 序列内部交互 | 推理阶段、自回归生成 |
| 反向传播更新 | 是 | 损失函数回传 | 训练阶段参数优化 |
自注意力更新更注重即时上下文适配,而反向传播更新侧重于长期参数优化。
Query通过自注意力机制的更新是一种前向传播过程,依赖序列内部的动态交互而非损失梯度。这种机制在Transformer的解码器自回归生成、KV Cache推理等场景中至关重要,实现了高效且上下文敏感的序列建模。