DDIA第五章:无主复制(去中心化复制)详解
1. 章节介绍
无主复制(也称为去中心化复制)是分布式数据库中一种重要的副本管理策略,其核心特点是不存在固定的主节点,每个副本节点均可独立接受写入请求,并通过异步方式将数据复制到其他节点。这种架构旨在解决主从复制中的单点故障问题,提升系统可用性和容错能力,尤其适用于网络不稳定、节点频繁故障的场景(如边缘计算、分布式存储系统)。
核心知识点及面试频率如下:
| 核心知识点 | 面试频率 |
|---|---|
| 无主复制的基本原理 | 中 |
| 读写策略(NWR模型) | 高 |
| 反熵机制(数据同步) | 中 |
| 版本向量(Version Vector) | 高 |
| 冲突检测与解决策略 | 高 |
| 无主复制的适用场景 | 中 |
2. 知识点详解
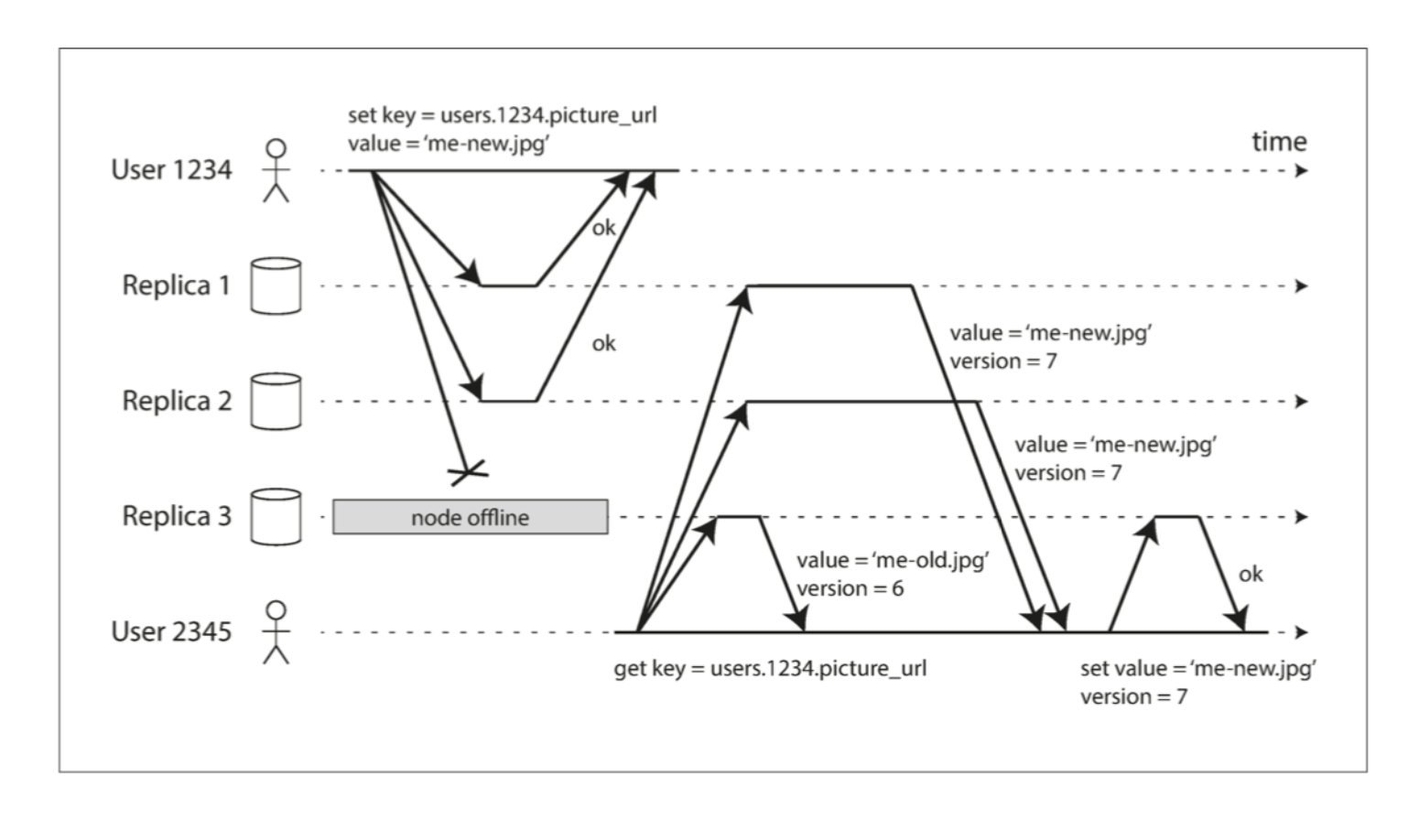
2.1 无主复制的基本原理
- 无固定主节点:所有副本节点地位平等,均可处理读写请求,避免主从复制中“主节点故障导致写入不可用”的问题。
- 异步复制:节点接受写入后,不会立即等待其他节点同步完成,而是异步将数据发送到其他副本,因此写入延迟低(不受网络延迟影响)。
- 副本自治:每个节点维护本地数据副本,通过复制协议(如Gossip协议)与其他节点交换数据,最终达成一致性(通常是最终一致性)。
2.2 读写策略(NWR模型)
无主复制中,通过配置“N、W、R”参数控制一致性与可用性的平衡:
-
N:数据的总副本数(如将数据复制到3个节点,N=3)。
-
W:写入成功的确认数(即至少需要W个节点成功写入,才返回写入成功)。
-
R:读取时查询的节点数(即至少从R个节点读取数据,取结果合并)。
-
核心原则:若需保证强一致性,需满足 W + R > N(确保读取节点与写入节点存在交集);若优先可用性,可降低W或R(如W=1、R=1,允许临时不一致)。
示例:
若N=3,W=2,R=2,则W+R=4>3,读取时至少能从2个节点中获取最新数据(因写入已在2个节点生效),可保证读取一致性;若W=1,R=1,则写入和读取均最快,但可能读取到旧数据。
2.3 反熵机制(数据同步)
用于解决节点间数据不一致问题(因异步复制可能导致节点故障、网络延迟等),分为两种方式:
- 全量反熵:定期对比所有节点的完整数据,同步差异(开销大,适用于数据量小的场景)。
- 增量反熵:基于操作日志(如写入、删除记录)同步增量数据,仅传输变化部分(常用,如Cassandra的Gossip协议)。
2.4 版本向量(Version Vector)
用于追踪数据的多版本历史,是检测写入冲突的核心机制:
- 定义:每个数据项的版本向量是一个数组,其中每个元素对应一个节点的“版本号”(如
(node1:2, node2:1)表示node1对该数据修改了2次,node2修改了1次)。 - 工作原理:
- 节点写入数据时,先递增自身在版本向量中的版本号(如node1写入后,版本向量从
(node1:1)变为(node1:2))。 - 复制数据时,版本向量随数据一起传输。
- 读取或合并数据时,通过比较版本向量判断是否存在冲突:
- 若向量A中所有节点的版本号均 ≤ 向量B,则A是B的旧版本(无冲突);
- 若向量A和B存在彼此不包含的版本号(如A:
(node1:2), B:(node2:2)),则存在冲突。
- 节点写入数据时,先递增自身在版本向量中的版本号(如node1写入后,版本向量从
2.5 冲突检测与解决策略
由于异步复制和并发写入,不同节点可能对同一数据产生冲突版本,需通过以下策略解决:
- 最后写入胜出(LWW):
- 基于时间戳判断,保留时间戳最新的版本(需依赖节点时钟同步,可能因时钟偏移导致错误)。
- 保留所有版本,由应用处理:
- 数据库存储所有冲突版本,返回给应用层,由业务逻辑决定如何合并(如合并用户编辑的文档)。
- 自动合并:
- 对可合并的数据类型(如集合、计数器),自动合并冲突(如集合取并集,计数器取总和)。
- 使用CRDTs(无冲突复制数据类型):
- 特殊设计的数据结构(如OR-Set、G-Counter),确保任意并发修改均可合并为一致结果,无需额外冲突处理逻辑。
2.6 无主复制的适用场景
- 高可用性优先:如电商秒杀、社交消息,允许短暂不一致,但需保证服务不中断。
- 网络不稳定场景:如边缘计算(节点分布在不同地理位置,网络延迟高)。
- 节点频繁故障:如分布式存储系统(如Amazon DynamoDB),需通过多副本容错。
3. 章节总结
无主复制通过去中心化架构(无固定主节点)提升系统可用性,核心机制包括:
- 基于NWR模型平衡一致性与性能;
- 反熵机制保证节点数据最终一致;
- 版本向量检测冲突,配合LWW、CRDTs等策略解决冲突。
其优势是容错性强、写入延迟低,劣势是可能产生数据冲突,一致性较弱,适用于高可用优先的分布式场景。
4. 知识点补充
4.1 相关知识点补充
- CRDTs(无冲突复制数据类型):一种特殊数据结构,其操作满足“交换律、结合律、幂等律”,确保并发修改后无需复杂冲突处理即可合并为一致结果(如G-Counter用于分布式计数,支持多节点独立递增,合并时取总和)。
- Gossip协议:无主复制中常用的异步复制协议,节点随机与其他节点交换数据,类似“病毒传播”,确保数据最终扩散到所有节点(适用于大规模集群)。
- 最终一致性:无主复制的典型一致性模型,即经过足够时间后,所有节点的数据会趋于一致,但过程中可能存在短暂不一致。
- Hinted Handoff(暗示移交):当目标节点故障时,写入请求临时存储在“hint节点”,待故障节点恢复后再移交数据,减少数据丢失风险。
- 墓碑标记(Tombstone):删除操作不直接删除数据,而是标记为“墓碑”,避免因异步复制导致的“删除丢失”(如节点A删除数据,节点B未同步,若B先恢复写入,会导致数据“复活”)。
4.2 最佳实践
场景:社交应用的用户动态存储(需高可用,允许短暂不一致)。
- NWR配置:N=3(数据存3个节点),W=2(写入成功需2个节点确认),R=2(读取时查2个节点)。既保证写入可用性(1个节点故障不影响),又通过W+R>N确保读取到较新数据。
- 冲突处理:用户动态可能被并发编辑(如同时点赞和评论),使用CRDTs中的OR-Set存储点赞用户ID,合并时自动取并集,避免冲突。
- 反熵优化:采用增量反熵+Gossip协议,节点每10秒随机与1个节点交换最近100条操作日志,确保数据最终同步,同时降低网络开销。
此方案在节点故障或网络分区时仍能提供服务,且通过CRDTs减少应用层冲突处理成本,适合社交场景的高可用需求。
4.3 编程思想指导
在无主复制系统开发中,需贯彻“容错优先、最终一致”的设计理念:
- 数据结构设计:避免依赖强一致性的结构(如全局锁),改用支持异步合并的类型(如CRDTs)。例如,实现分布式计数器时,使用G-Counter而非普通整数,每个节点维护本地计数,合并时求和,避免并发写入覆盖。
- 网络容错:假设网络不可靠,写入时需超时重试(而非阻塞等待),并记录操作日志(用于故障恢复)。例如,用队列缓存待复制的操作,节点恢复后批量同步,避免数据丢失。
- 冲突预期:不试图完全消除冲突,而是设计轻量的检测与解决机制。例如,用版本向量标记数据版本,读取时若发现冲突,返回所有版本并附带元数据(如修改时间),由应用层根据业务逻辑选择或合并。
- 可扩展性:复制逻辑与业务逻辑解耦,通过配置NWR参数动态调整一致性级别。例如,为核心数据(如订单)设置W=3、R=3(强一致),为非核心数据(如日志)设置W=1、R=1(高可用)。
这种思想强调“接受不完美,通过机制弥补”,在分布式系统中可显著提升可用性和容错能力。
5. 程序员面试题
简单题
问题:无主复制与主从复制的核心区别是什么?
答案:
- 主从复制有固定主节点,仅主节点处理写入,从节点被动同步;无主复制无固定主节点,所有节点均可处理写入。
- 主从复制依赖主节点,主节点故障会导致写入不可用;无主复制无单点故障,节点故障不影响整体写入能力。
- 主从复制一致性较强(同步复制可保证强一致);无主复制通常是最终一致性,可能存在冲突。
中等难度题
问题1:如何利用版本向量检测两个数据版本是否存在冲突?请举例说明。
答案:
版本向量是 (节点ID: 版本号) 的集合,通过比较两个向量中所有节点的版本号判断:
- 若向量A中所有节点的版本号 ≤ 向量B对应节点的版本号,则A是B的旧版本(无冲突);
- 若存在节点在A中的版本号 > B,且存在节点在B中的版本号 > A,则存在冲突。
示例:
- 数据X在node1的版本向量为
(node1:2, node2:1); - 数据X在node2的版本向量为
(node1:1, node2:2)。
对比可知:node1的版本(2>1)和node2的版本(2>1)彼此不包含,因此存在冲突。
问题2:NWR模型中,W=1、R=N(N为副本数)的配置会导致什么结果?
答案:
- 写入性能:写入延迟极低(仅需1个节点确认),可用性高(即使N-1个节点故障,仍可写入)。
- 读取性能:读取需查询所有N个节点,延迟高,但能获取所有版本数据(便于冲突检测)。
- 一致性:W+R = 1 + N,若N≥2,则1+N > N(满足W+R>N),理论上可通过合并所有节点数据得到最新结果,但因写入仅1个节点确认,其他节点可能滞后,读取时需处理大量冲突。
- 适用场景:对写入延迟极敏感,可接受读取复杂(如日志收集系统)。
高难度题
问题1:CRDTs如何保证分布式环境下的无冲突合并?请以OR-Set(有序集合)为例说明。
答案:
CRDTs通过数学性质(交换律、结合律、幂等律)确保任意并发修改的合并结果一致,无需中心化协调。
OR-Set用于存储元素集合,支持“添加”和“删除”操作,其实现原理:
- 每个元素关联一个“标签集”(如
(元素值, 唯一标识符)),添加元素时生成新标签; - 删除元素时,标记其所有标签为“已删除”;
- 合并两个OR-Set时,保留所有未被标记删除的标签,且标签集取并集。
例如:
- 节点A添加元素"a",生成标签
(a, id1); - 节点B并发添加元素"a",生成标签
(a, id2); - 合并后,OR-Set包含
(a, id1)和(a, id2),即"a"被保留(符合“添加合并”)。
若节点A删除"a"(标记 id1 为删除),节点B添加"a"(生成 id3),合并后保留 id3(未删除),确保“删除不影响并发添加”,无冲突。
问题2:无主复制中,如何处理网络分区(脑裂)问题?
答案:
网络分区时,集群被分割为多个独立子网,无主复制需避免“分区内数据孤岛”和“分区恢复后的数据混乱”,解决方案包括:
- 分区内可用性优先:允许各分区独立处理写入(维持可用性),记录分区期间的操作日志(含版本向量)。分区恢复后,通过反熵机制合并所有分区的版本向量,用冲突解决策略(如CRDTs)合并数据。
- Quorum机制增强:配置W和R时,确保W > N/2(如N=5,W=3),则网络分区时最多只有一个子网包含≥W个节点,避免两个分区同时满足写入条件(减少冲突源头)。
- 节点权重与优先级:为节点分配权重,分区时仅高权重节点所在子网可处理写入,低权重节点进入只读模式,减少合并冲突。
- 分区检测与自动恢复:用分布式一致性协议(如SWIM)检测网络分区,分区恢复后触发全量反熵,优先同步分区期间的增量数据,确保最终一致性。
例如,Amazon DynamoDB采用方案1+2,通过N=3、W=2、R=2配置,分区时允许单节点写入(W=2可能不满足,实际降级为W=1),恢复后用版本向量合并,保证数据不丢失。