基于Python的海量电商用户行为分析与可视化【推荐算法、统计模型、聚类模型、电商指标维度分析】
文章目录
- ==有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主==
- 项目介绍
- 一、项目背景与研究意义
- 指标解释
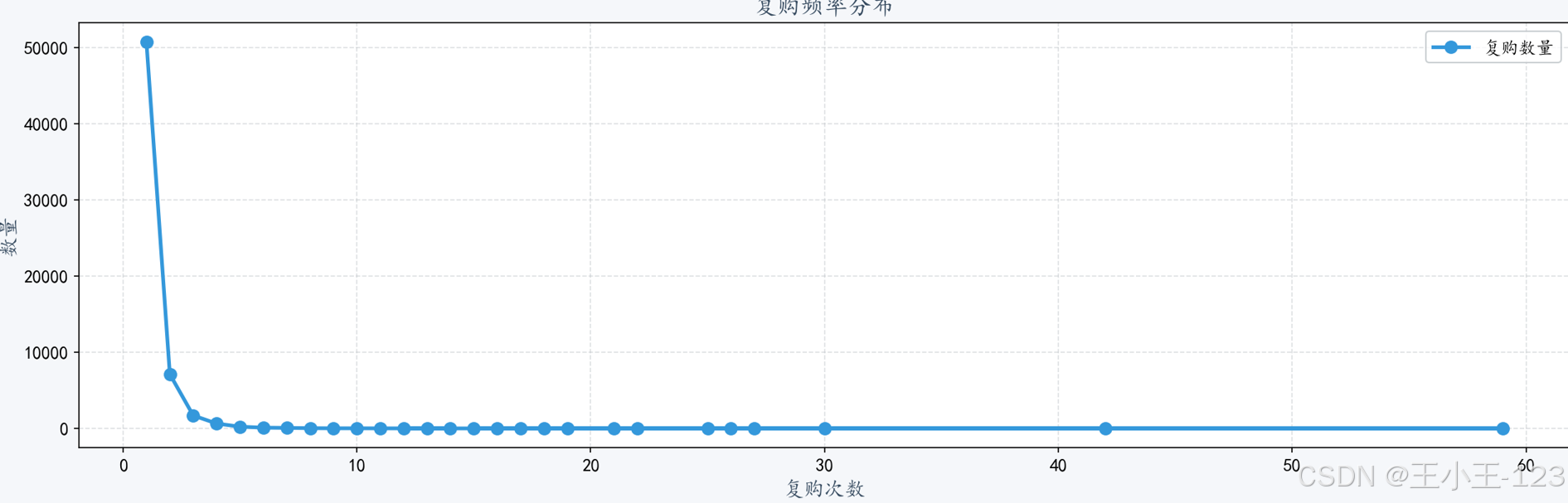
- 1. 复购率(Repurchase Rate)
- 2. 留存率(Retention Rate)
- 3. 跳失率(Bounce Rate)
- 4. AARRR漏斗模型(海盗模型)
- 二、研究目标
- 三、数据来源与处理
- 四、分析方法与技术实现
- (1)基于应用统计学的用户行为分析
- (2)运营指标评估
- (3)基于RFM模型的用户价值分层
- (4)基于LightFM的商品推荐
- 五、创新与亮点
- 六、应用价值与推广前景
- 七、结论与展望
- 每文一语
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
项目介绍
一、项目背景与研究意义
随着互联网经济的快速发展,电子商务已成为推动全球经济增长的重要力量。近年来,我国电商行业发展迅猛,根据商务部电子商务和信息化司的统计数据,2024年第一季度全国网上零售额达3.31万亿元,同比增长12.4%,充分说明电商市场规模的不断扩大和竞争的日益激烈。在这种背景下,电商平台积累了海量用户行为数据,这些数据记录了用户在平台上的浏览、搜索、收藏、加购、购买等全流程行为。
如何高效分析这些数据,洞察用户需求、优化运营策略,成为电商平台提升竞争力的关键。通过用户行为分析,电商平台不仅能够精准定位目标客户群,还能在商品推荐、活动策划、页面布局优化等方面提供有力的数据支撑,实现从“经验驱动”向“数据驱动”的转变。本项目正是基于这一现实需求,利用Python及相关数据分析与机器学习技术,对电商用户行为数据进行系统研究与分析,探索可行的精细化运营方案。
指标解释
1. 复购率(Repurchase Rate)
定义
复购率是指在一段时间内,有过购买行为的用户再次购买的比例,反映了用户对平台或产品的忠诚度和满意度。
公式
复购率=再次购买的用户数总购买用户数×100%复购率 = \frac{\text{再次购买的用户数}}{\text{总购买用户数}} \times 100\% 复购率=总购买用户数再次购买的用户数×100%
举例
假设上个月有 1000 个用户买过商品,其中 250 人在这个月又来买了东西,那么本月的复购率就是:
250/1000=25%250 / 1000 = 25\% 250/1000=25%
意义
- 高复购率 → 用户满意度高、产品有粘性
- 低复购率 → 用户流失严重,需要优化产品质量、价格、服务
电商应用
针对首次购买但未复购的用户,平台可以发优惠券、推送相关商品、做会员积分活动来提高复购率。
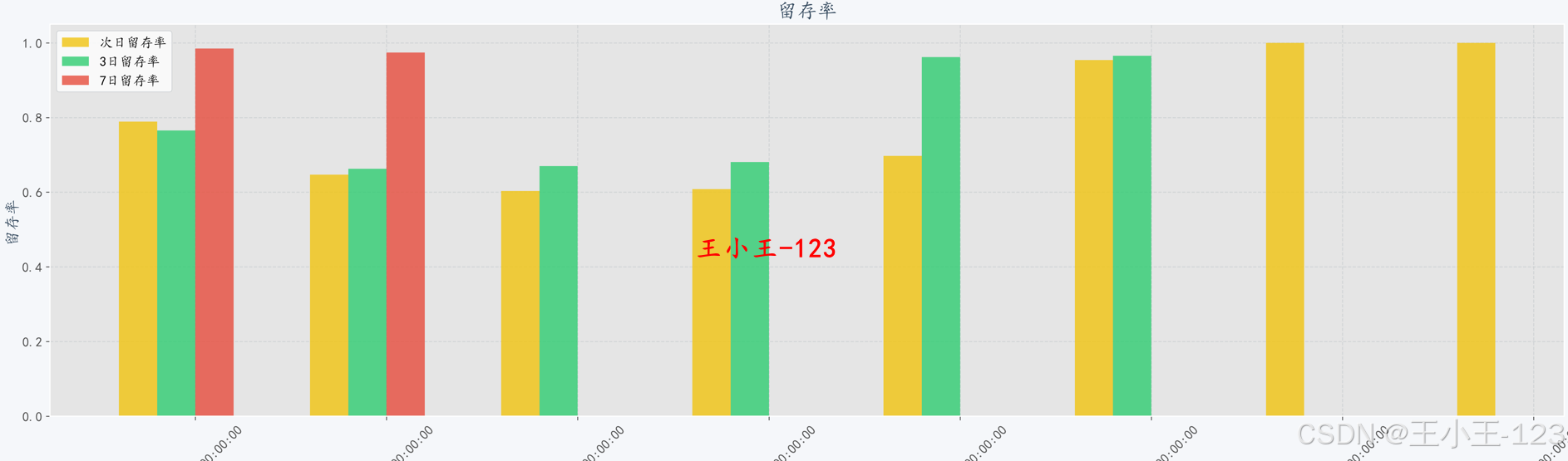
2. 留存率(Retention Rate)
定义
留存率是指在特定时间段内,继续使用产品或服务的用户比例,反映了用户的持续活跃度。
常见类型
- 次日留存:今天新增用户中,第二天还回来使用的比例
- 3日留存、7日留存:类似道理,只是时间窗口不同
公式
留存率=某日仍活跃的用户数初始用户数×100%留存率 = \frac{\text{某日仍活跃的用户数}}{\text{初始用户数}} \times 100\% 留存率=初始用户数某日仍活跃的用户数×100%
举例
一天新增 500 个用户,第二天还有 120 人继续使用:
次日留存率=120/500=24%次日留存率 = 120 / 500 = 24\% 次日留存率=120/500=24%
意义
- 高留存率 → 产品有持续吸引力
- 低留存率 → 产品体验、内容、运营承接有问题
电商应用
在用户首次下单后,第二天推送订单跟踪、相关推荐,提升次日留存。
3. 跳失率(Bounce Rate)
定义
跳失率是指用户访问某个页面后,没有进行任何进一步操作就离开的比例,常用于衡量页面的吸引力和用户体验。
公式
跳失率=只访问一个页面就离开的访问次数总访问次数×100%跳失率 = \frac{\text{只访问一个页面就离开的访问次数}}{\text{总访问次数}} \times 100\% 跳失率=总访问次数只访问一个页面就离开的访问次数×100%
举例
某商品详情页一共被访问 1000 次,有 700 次是用户看完就直接关闭页面:
跳失率=700/1000=70%跳失率 = 700 / 1000 = 70\% 跳失率=700/1000=70%
意义
- 高跳失率 → 页面内容不吸引人、加载慢、与用户预期不符
- 低跳失率 → 用户愿意继续浏览,有较好体验
电商应用
优化商品标题、图片、详情内容,提高页面相关性与吸引力,降低跳失率。
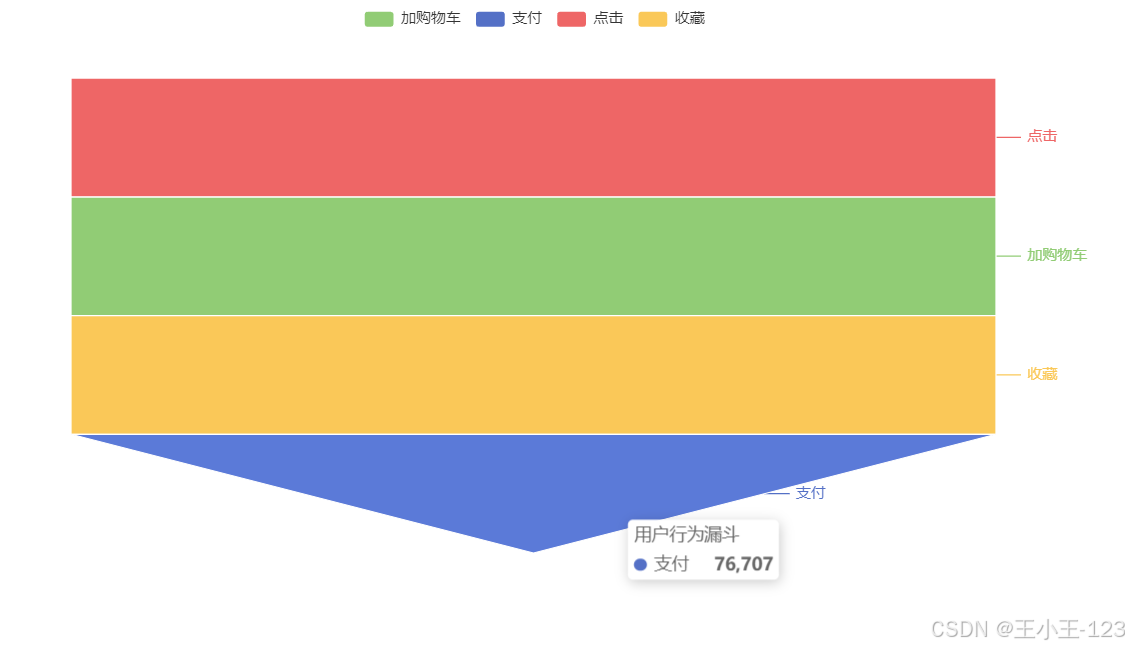
4. AARRR漏斗模型(海盗模型)
定义
AARRR 是一种用户生命周期分析模型,由 5 个阶段组成,形似漏斗,从获取用户到转化变现再到用户传播。
AARRR 分别代表:
- Acquisition(获取):用户是如何知道并来到平台的(广告、搜索、社交媒体等)
- Activation(激活):用户首次体验的效果(注册、首次购买、第一次加购等)
- Retention(留存):用户是否会继续回来使用(次日留存、周留存)
- Revenue(收入):用户是否为平台带来收入(付费、购买)
- Referral(传播):用户是否会推荐其他人使用(分享、邀请注册)
漏斗原理
每一步用户都会减少,比如:
- 10000 人看到广告 → 2000 人点击进入(获取)
- 2000 人中 500 人注册(激活)
- 500 人中 150 人次日回来(留存)
- 150 人中 80 人下单(收入)
- 80 人中 20 人分享(传播)
意义
- 帮助企业找到用户流失最多的环节
- 有针对性地优化运营策略
电商应用
如果在“加购 → 付款”环节掉了很多人,可以做限时优惠或简化支付流程来提升转化率。
二、研究目标
本项目的核心目标是利用数据分析和机器学习技术,对阿里巴巴天池平台提供的百万级用户行为数据进行处理与挖掘,完成以下任务:
- 数据预处理:对原始数据进行清洗、缺失值和异常值处理、时间戳转换等操作,确保数据的完整性与准确性。
- 用户行为分析:通过统计分析方法,对用户在不同时间维度、不同行为类型下的特征进行分析,发现用户活跃规律与消费习惯。
- 运营指标评估:利用复购率、留存率、AARRR漏斗模型等指标,识别用户流失环节与转化瓶颈,提出优化建议。
- 用户价值分层:结合RFM模型与KMeans聚类算法,将用户按价值进行细分,制定差异化运营策略。
- 个性化商品推荐:基于LightFM模型构建推荐系统,通过隐式反馈数据为用户生成个性化商品推荐列表,提升转化率与用户粘性。
三、数据来源与处理
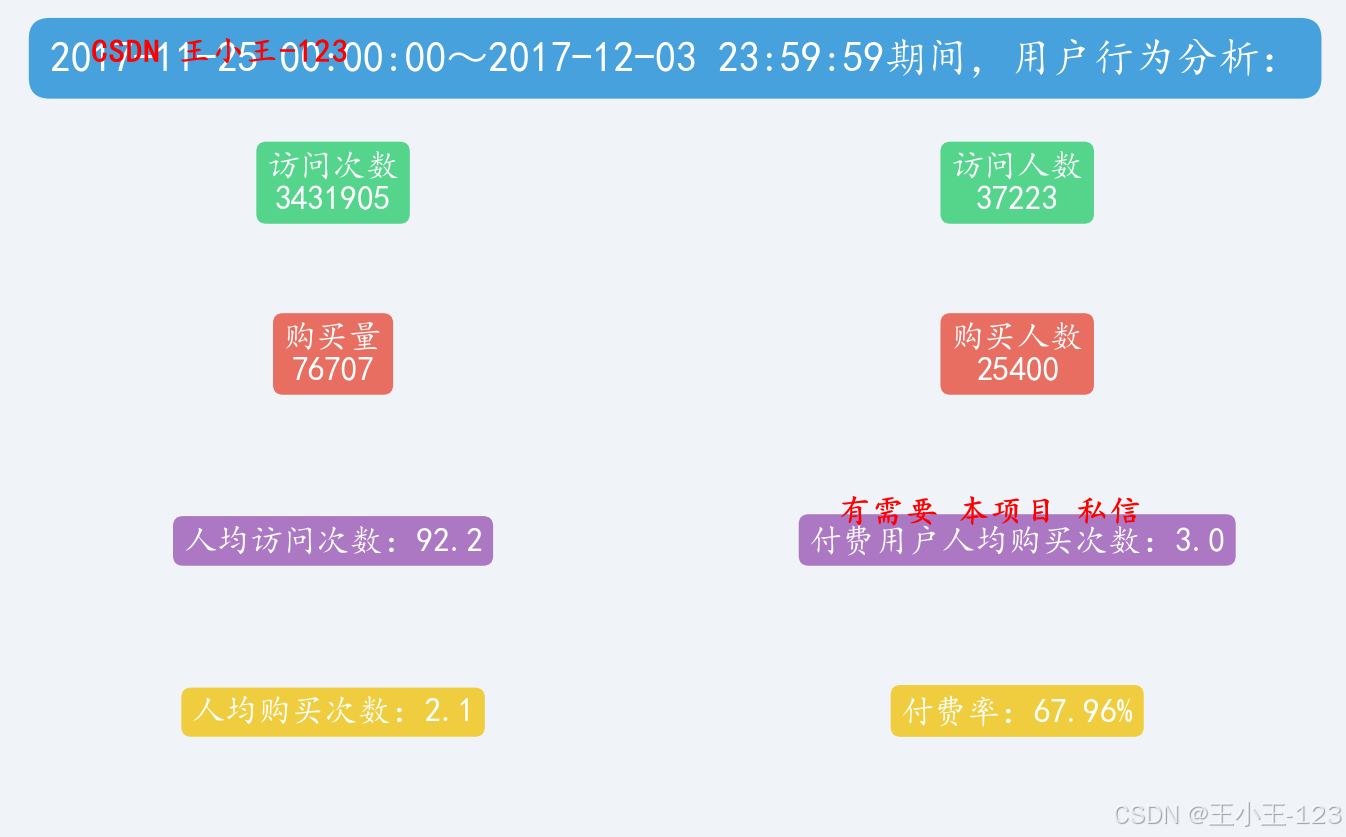
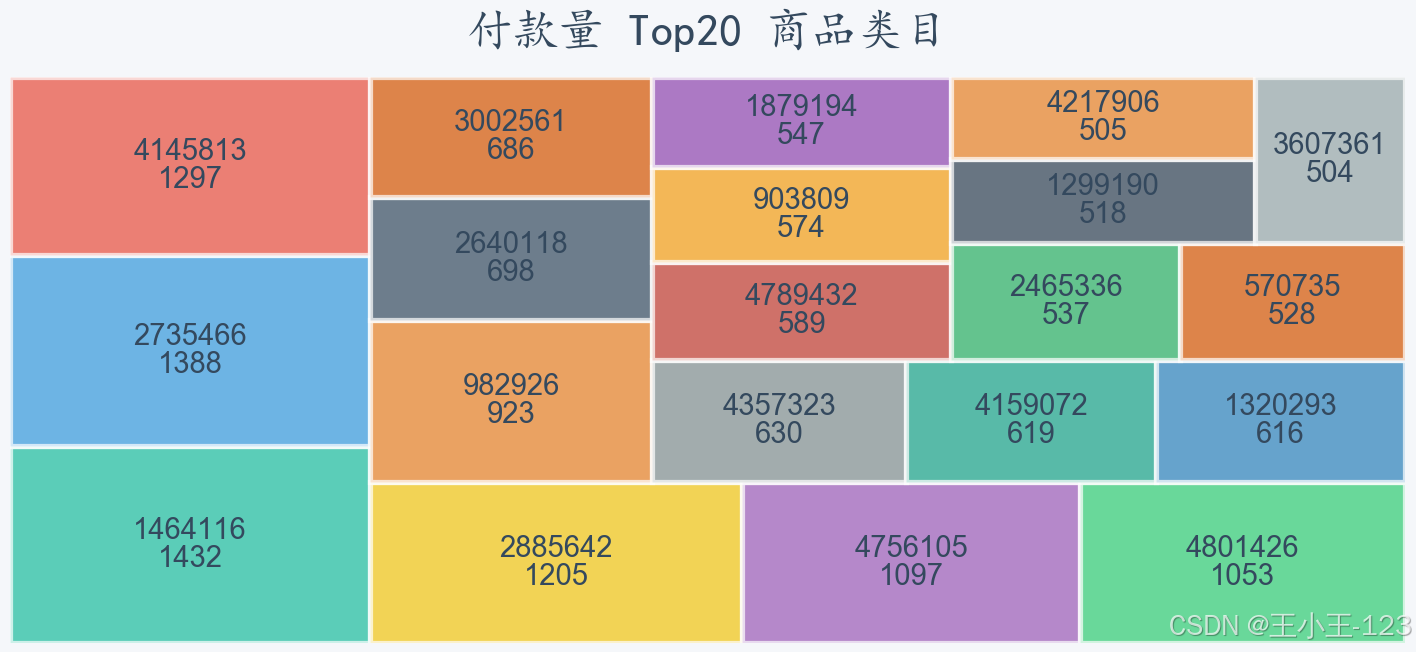
项目所用数据来自阿里巴巴天池平台,数据涵盖2017年11月25日至12月3日约一百万用户的行为记录,包括用户ID、商品ID、商品类目ID、行为类型(浏览、购买、加购、收藏)及行为发生时间戳等信息。
在数据预处理阶段,本项目利用Pandas和NumPy库进行以下操作:
- 缺失值与异常值检测:通过
isnull()和逻辑判断剔除不合逻辑的数据; - 重复值清理:使用
drop_duplicates()去除重复记录,确保行为唯一性; - 时间戳转换:借助
to_datetime()函数,将时间戳转为标准日期时间格式,为时间序列分析提供基础; - 数据范围筛选:删除超出研究周期的记录,保证分析结果的时效性与准确性。
经过处理后的数据结构清晰、逻辑合理,可直接用于后续分析与建模。
四、分析方法与技术实现
(1)基于应用统计学的用户行为分析
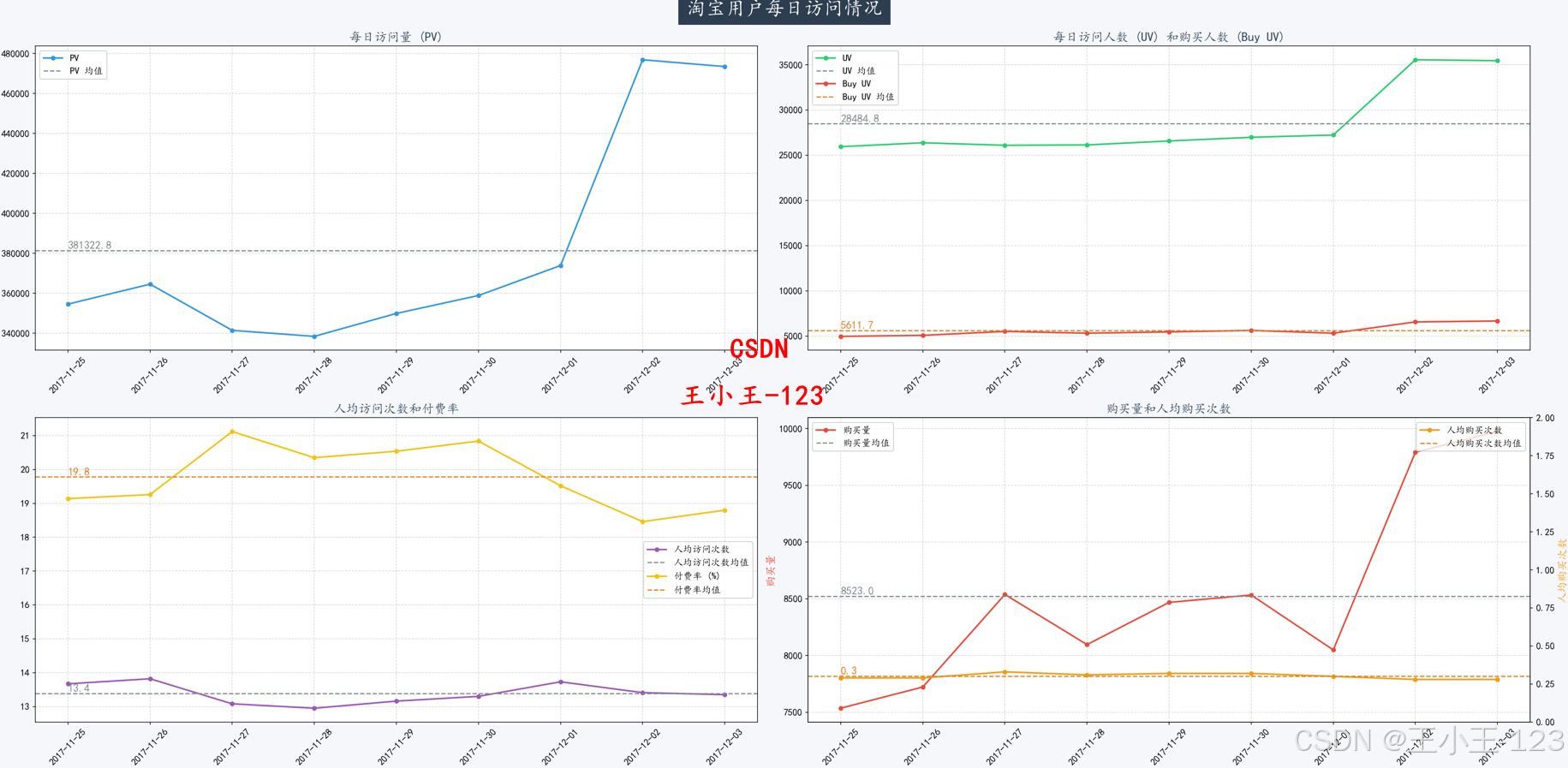
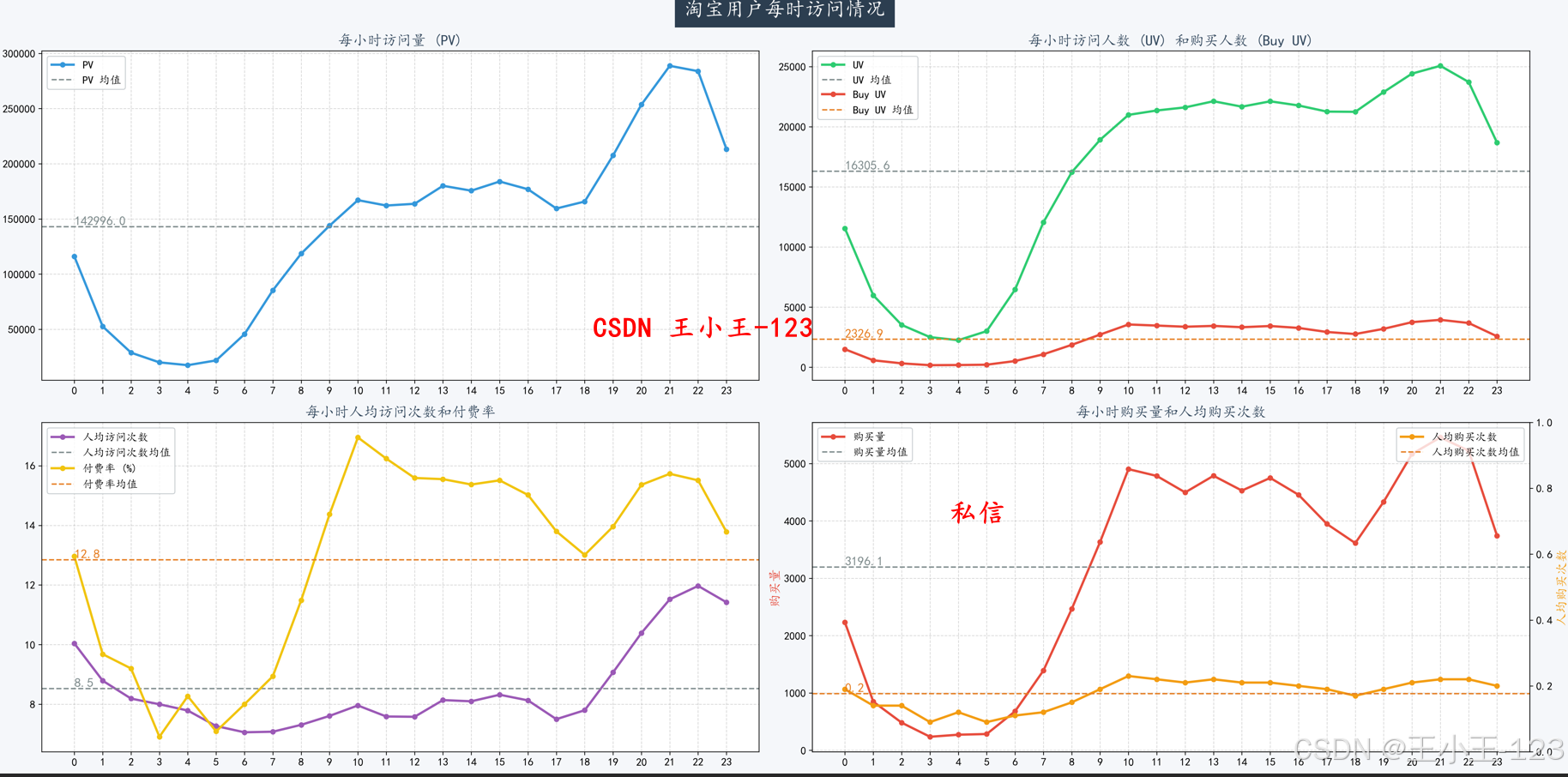
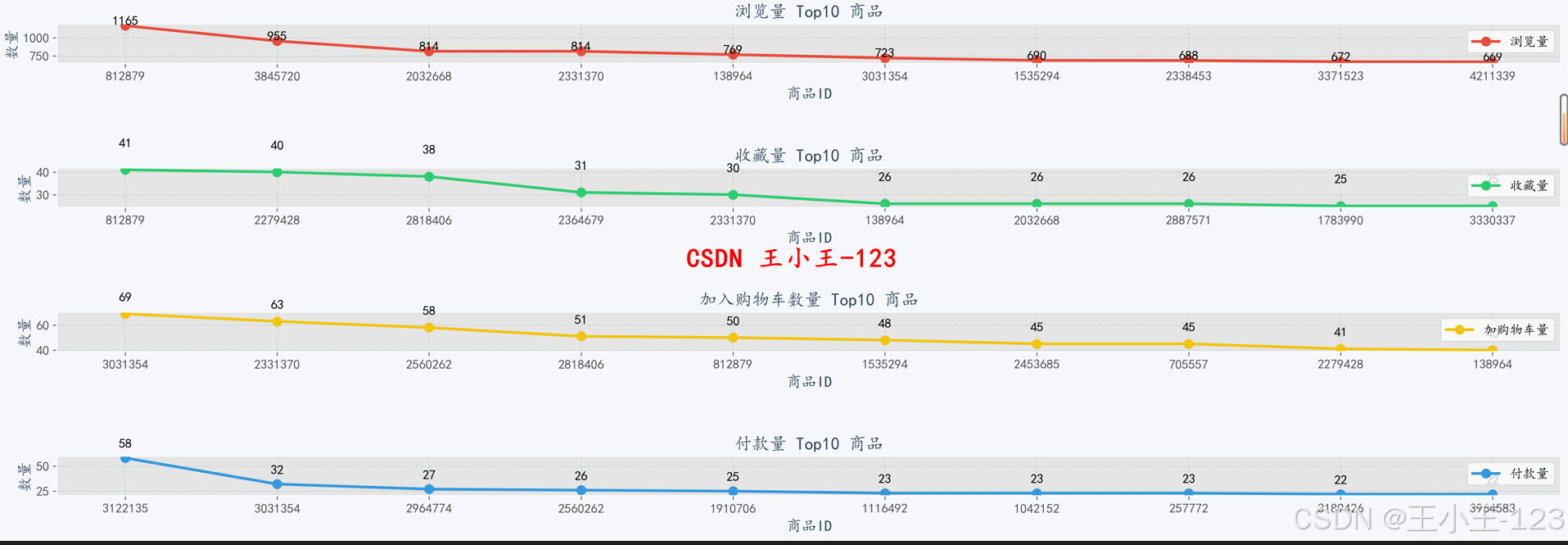
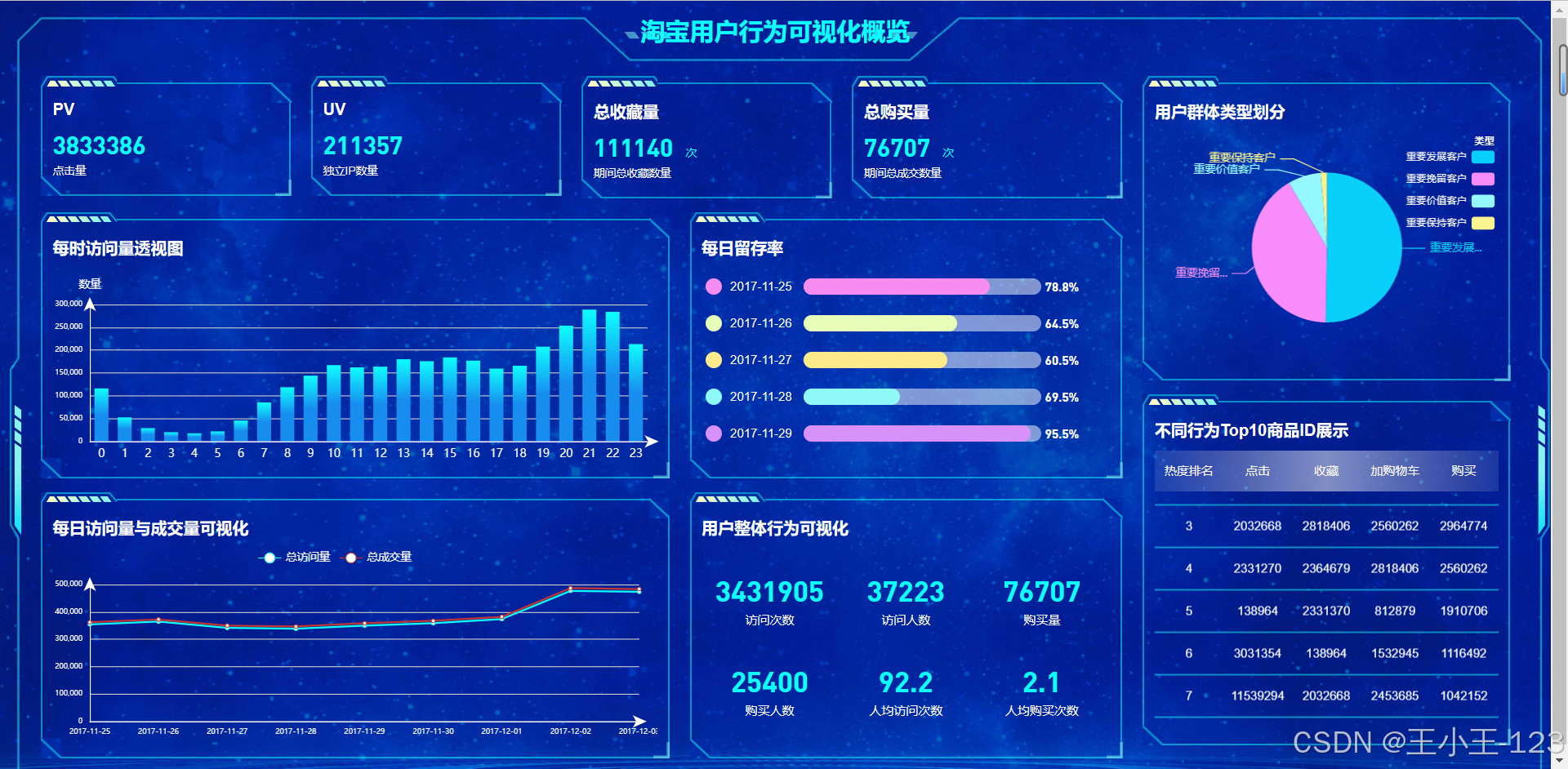
项目通过对日、小时、周等时间维度的PV(访问量)、UV(独立访客)、购买量等指标进行分析,揭示了用户活跃规律:
- 用户访问高峰集中在晚间20:00—22:00;
- 周末PV与UV显著高于工作日;
- 大型促销活动结束后平台流量会短期上升。
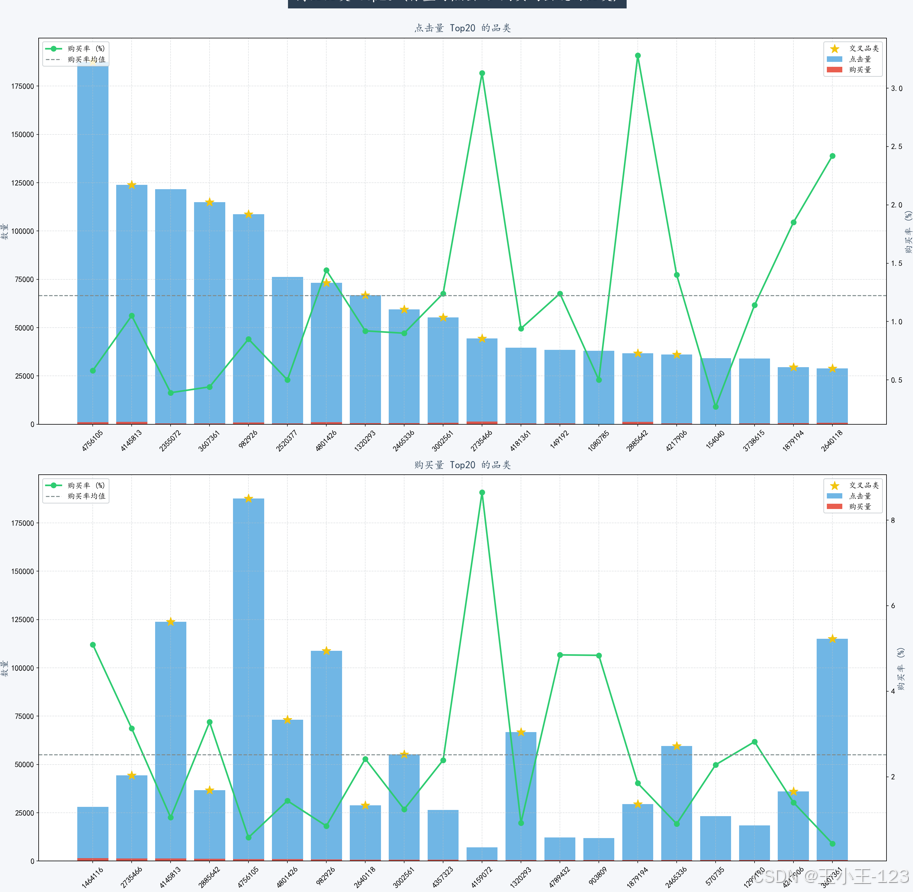
在行为类型分析中发现,加购行为量显著高于购买量,说明存在大量用户在“加购—付款”环节流失,平台可通过优惠券、限时折扣等方式刺激转化。
(2)运营指标评估
项目利用复购率分析发现,高频复购用户比例偏低,平台需提升商品品质与用户体验来增强忠诚度。留存率分析显示,次日留存率波动较大,三日留存率提升不明显,表明平台在用户激活与持续留存方面存在不足。AARRR漏斗模型分析则揭示了点击到加购、收藏的转化率偏低,是主要的流失环节。
(3)基于RFM模型的用户价值分层
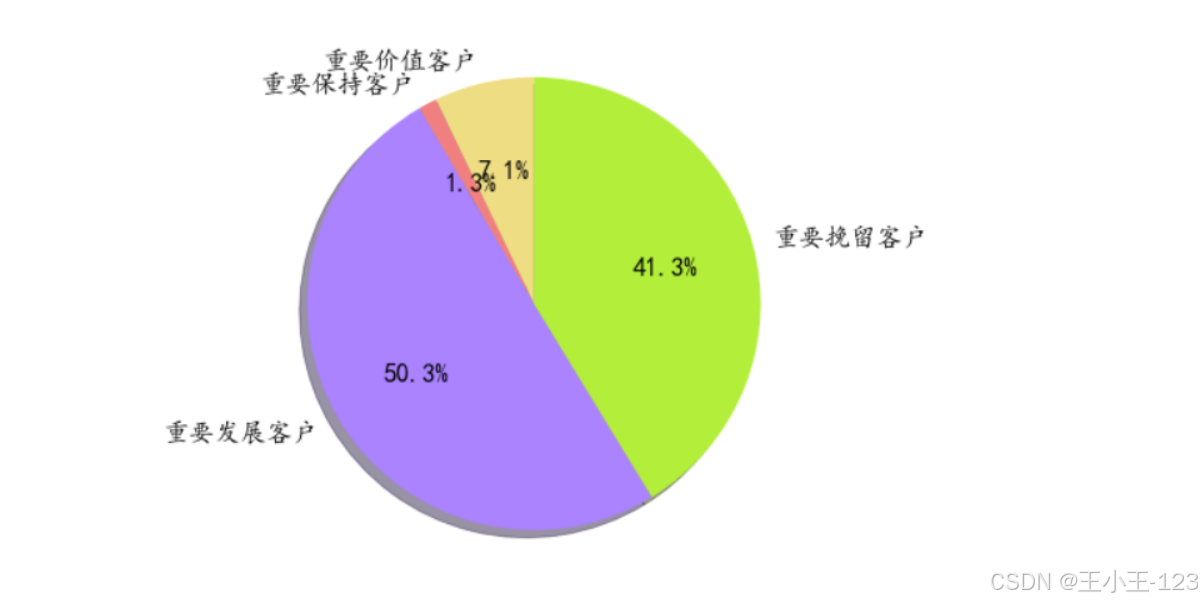
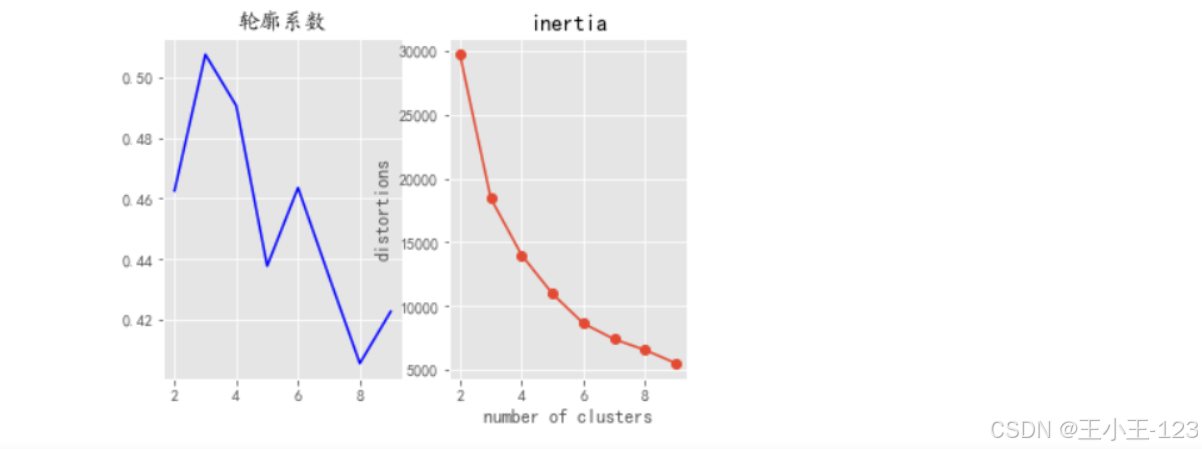
RFM模型结合KMeans聚类,将用户划分为高价值、中价值、低价值及流失用户四类:
- 高价值用户(高R、高F、高M):重点维护,提供专属优惠与活动;
- 中价值用户(高R、中F、中M):通过品牌宣传与运营活动提升忠诚度;
- 低价值与流失用户:利用召回策略和再营销手段进行挽回。
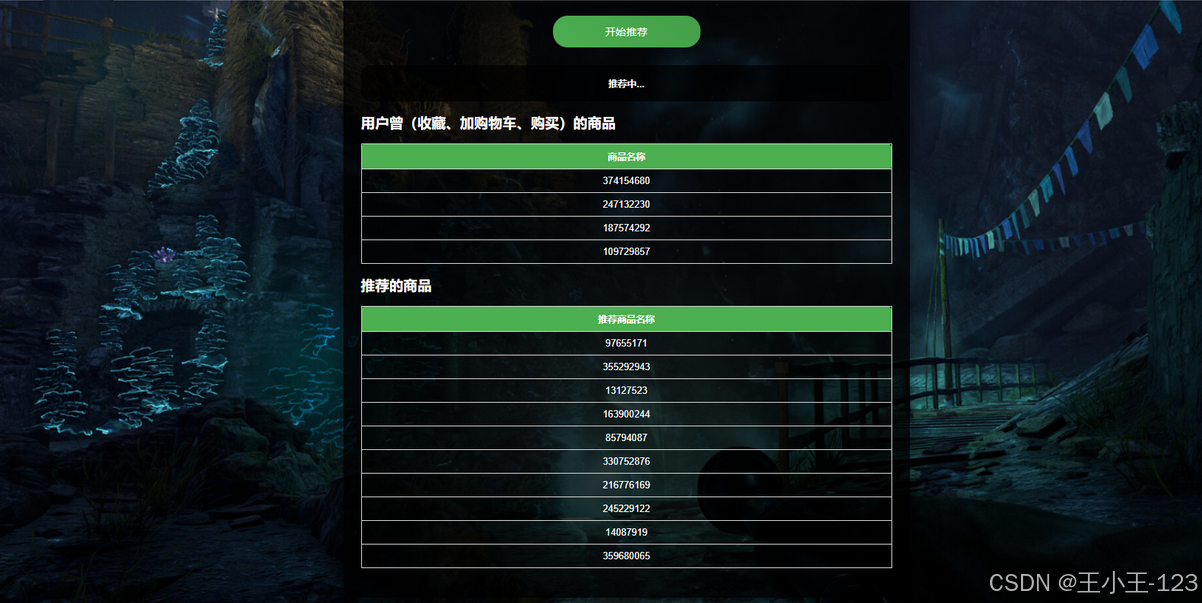
(4)基于LightFM的商品推荐
项目基于用户的浏览、收藏、加购、购买等隐式反馈数据,构建了LightFM推荐模型。该模型融合了协同过滤与内容特征,可有效处理数据稀疏性和冷启动问题。通过对行为赋予权重并构建交互矩阵,模型能够生成与用户历史兴趣高度相关的推荐结果,实现个性化推荐。
五、创新与亮点
- 多层次分析框架:从数据预处理、统计分析、机器学习到推荐系统,实现了完整的用户行为分析流程。
- 结合运营实践的分析指标:除常规统计外,引入复购率、留存率、AARRR漏斗等指标,直接指向电商运营中的关键问题。
- RFM模型与聚类结合:不仅停留在理论分析层面,还利用聚类实现自动化用户分群,为运营提供可执行的策略建议。
- 个性化推荐落地:使用LightFM模型结合隐式反馈数据,在缺乏商品文本信息的情况下依然能提供有效推荐。
六、应用价值与推广前景
本项目的研究成果可直接应用于电商平台的用户运营与推荐系统优化:
- 运营团队可基于行为分析结果制定促销节奏与内容投放策略;
- 产品经理可参考留存与转化分析优化用户体验与流程设计;
- 技术团队可在此基础上拓展多模态推荐系统,提升推荐准确率与用户满意度。
随着数据规模与多样性的不断增加,该分析框架可扩展至跨平台用户行为整合、舆情情感分析、个性化营销等更多场景,帮助电商平台实现精细化运营和可持续增长。
七、结论与展望
本项目实现了从数据获取、处理到建模与推荐的全流程分析,验证了Python及其生态在电商用户行为分析中的高效性与实用性。未来的工作可在以下方向深化:
- 引入更长周期与更丰富的数据特征,提升分析的全面性与准确性;
- 融合深度学习与多模态数据(文本、图像、视频)优化推荐效果;
- 探索联邦学习等隐私保护计算框架,实现跨平台用户行为共享分析。
通过持续优化与技术迭代,本项目的分析与推荐框架有望成为电商行业的数据驱动型用户运营的标杆方案。

每文一语
在学习中进步