[java八股文][Mysql面试篇]架构
MySQL主从复制了解吗
MySQL 的主从复制依赖于 binlog ,也就是记录 MySQL 上的所有变化并以二进制形式保存在磁盘上。复制的过程就是将 binlog 中的数据从主库传输到从库上。
这个过程一般是异步的,也就是主库上执行事务操作的线程不会等待复制 binlog 的线程同步完成。
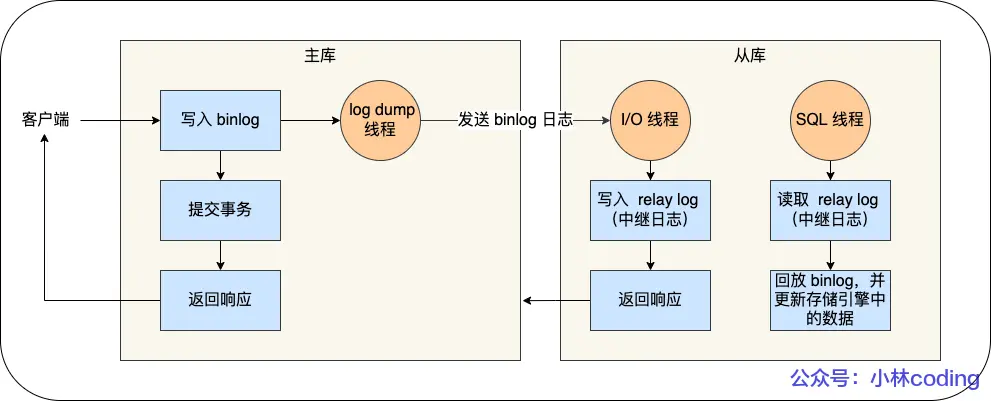
MySQL 集群的主从复制过程梳理成 3 个阶段:
- 写入 Binlog:主库写 binlog 日志,提交事务,并更新本地存储数据。
- 同步 Binlog:把 binlog 复制到所有从库上,每个从库把 binlog 写到暂存日志中。
- 回放 Binlog:回放 binlog,并更新存储引擎中的数据。
具体详细过程如下:
- MySQL 主库在收到客户端提交事务的请求之后,会先写入 binlog,再提交事务,更新存储引擎中的数据,事务提交完成后,返回给客户端“操作成功”的响应。
- 从库会创建一个专门的 I/O 线程,连接主库的 log dump 线程,来接收主库的 binlog 日志,再把 binlog 信息写入 relay log 的中继日志里,再返回给主库“复制成功”的响应。
- 从库会创建一个用于回放 binlog 的线程,去读 relay log 中继日志,然后回放 binlog 更新存储引擎中的数据,最终实现主从的数据一致性。
在完成主从复制之后,你就可以在写数据时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响读请求的执行。
#主从延迟都有什么处理方法?
强制走主库方案:对于大事务或资源密集型操作,直接在主库上执行,避免从库的额外延迟。
#分表和分库是什么?有什么区别?
- 分库是一种水平扩展数据库的技术,将数据根据一定规则划分到多个独立的数据库中。每个数据库只负责存储部分数据,实现了数据的拆分和分布式存储。分库主要是为了解决并发连接过多,单机 mysql扛不住的问题。
- 分表指的是将单个数据库中的表拆分成多个表,每个表只负责存储一部分数据。这种数据的垂直划分能够提高查询效率,减轻单个表的压力。分表主要是为了解决单表数据量太大,导致查询性能下降的问题。
分库与分表可以从:垂直(纵向)和 水平(横向)两种纬度进行拆分。下边我们以经典的订单业务举例,看看如何拆分。
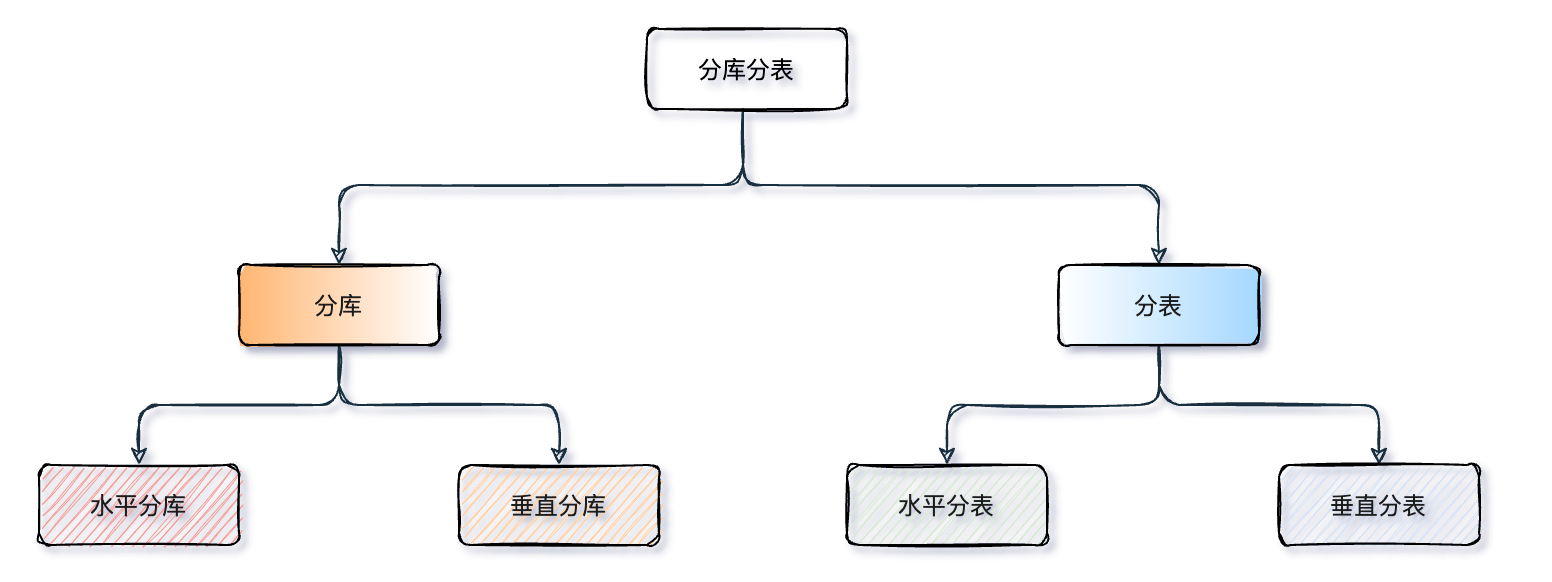
- 垂直分库:一般来说按照业务和功能的维度进行拆分,将不同业务数据分别放到不同的数据库中,核心理念 专库专用。按业务类型对数据分离,剥离为多个数据库,像订单、支付、会员、积分相关等表放在对应的订单库、支付库、会员库、积分库。垂直分库把一个库的压力分摊到多个库,提升了一些数据库性能,但并没有解决由于单表数据量过大导致的性能问题,所以就需要配合后边的分表来解决。
- 垂直分表:针对业务上字段比较多的大表进行的,一般是把业务宽表中比较独立的字段,或者不常用的字段拆分到单独的数据表中,是一种大表拆小表的模式。数据库它是以行为单位将数据加载到内存中,这样拆分以后核心表大多是访问频率较高的字段,而且字段长度也都较短,因而可以加载更多数据到内存中,减少磁盘IO,增加索引查询的命中率,进一步提升数据库性能。
- 水平分库:是把同一个表按一定规则拆分到不同的数据库中,每个库可以位于不同的服务器上,以此实现水平扩展,是一种常见的提升数据库性能的方式。这种方案往往能解决单库存储量及性能瓶颈问题,但由于同一个表被分配在不同的数据库中,数据的访问需要额外的路由工作,因此系统的复杂度也被提升了。
- 水平分表:是在同一个数据库内,把一张大数据量的表按一定规则,切分成多个结构完全相同表,而每个表只存原表的一部分数据。水平分表尽管拆分了表,但子表都还是在同一个数据库实例中,只是解决了单一表数据量过大的问题,并没有将拆分后的表分散到不同的机器上,还在竞争同一个物理机的CPU、内存、网络IO等。要想进一步提升性能,就需要将拆分后的表分散到不同的数据库中,达到分布式的效果。