ZKmall开源商城的容灾之道:多地域部署与故障切换如何守护电商系统
电商系统的稳定性就像空气 —— 平时感觉不到存在,一旦出问题就会让人窒息。一次服务器宕机可能意味着数万订单流失,一场网络中断甚至能引发用户信任危机。ZKmall 开源商城针对电商业务的高可用性需求,设计了一套完善的多地域部署与故障切换机制,通过 "异地多活" 架构和智能容灾策略,把系统故障的影响压到最小。不管是突发的自然灾害、机房断电,还是流量峰值导致的服务过载,都能快速切换到备用节点,确保核心交易流程不断档。
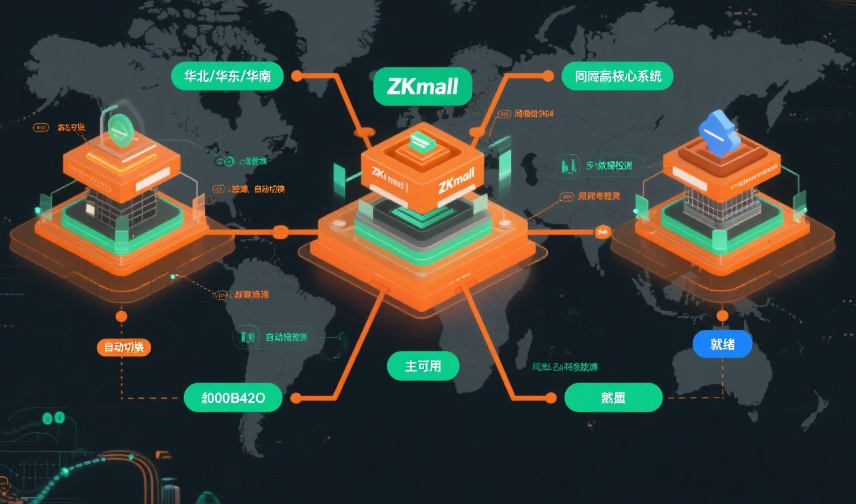
多地域部署架构:容灾的物理基础
容灾能力的核心在于 "不把所有鸡蛋放在一个篮子里"。ZKmall 的多地域部署架构通过在地理上分散的多个数据中心部署服务节点,从物理层面避免单点故障导致的系统瘫痪。
三层分布式部署模型
ZKmall 采用 "核心区 + 备份区 + 边缘节点" 的三层部署模型,兼顾性能与容灾:
核心区:部署在云计算厂商的主力地域(比如阿里云华东 1 区、腾讯云广州区),承担 80% 的日常流量。这个区域的集群配置最高,包含完整的业务服务(商品、订单、支付)、数据库主节点和缓存集群,能处理所有业务场景的实时请求。
备份区:选择与核心区距离适中(通常相隔 500 公里以上)的地域(比如阿里云华北 2 区、腾讯云上海区),部署和核心区一样的服务集群,但只承担 20% 的日常流量。备份区的数据库采用实时同步机制,和核心区保持数据一致,核心区出问题时能无缝接管全部业务。
边缘节点:在用户密集的区域(比如一线城市、海外重点市场)部署轻量节点,主要负责静态资源加速(商品图片、HTML/CSS)和简单查询请求(商品列表、促销活动),通过 CDN 与核心区联动,既提升访问速度,又分担核心区压力。
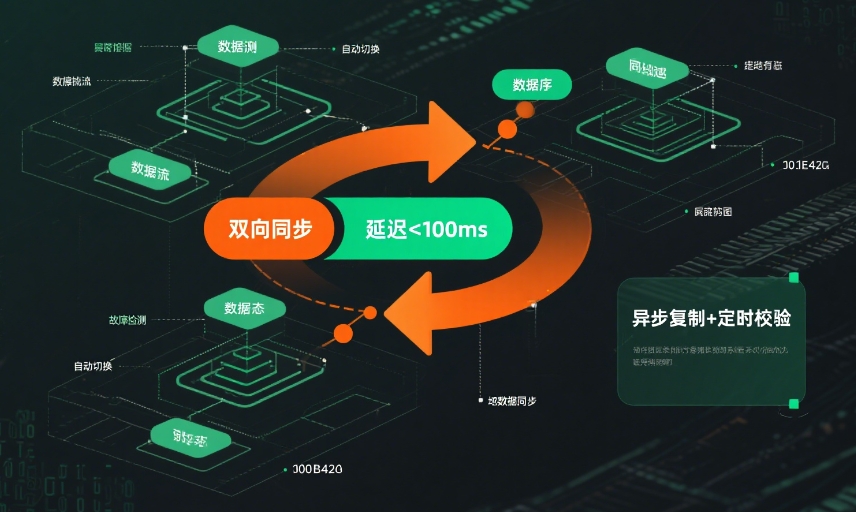
数据同步与一致性保障
多地域部署的关键挑战是确保各区域数据的一致性。ZKmall 通过分层同步策略解决这个问题:
核心业务数据:订单、支付、用户账户等关键数据采用 "主从同步 + 异步确认" 机制。核心区数据库写入数据后,同步到备份区的从库(延迟控制在 1 秒内),同时通过消息队列(RabbitMQ)发送数据变更通知,备份区服务收到通知后更新本地缓存,确保读写一致。
非核心数据:商品描述、评价、浏览历史等非实时数据采用 "定时增量同步",每 5 分钟同步一次变更内容。这类数据即使有短暂不一致,也不会影响核心交易,却能大幅降低同步成本。
静态资源:商品图片、视频、文档等通过对象存储(OSS)的跨区域复制功能,自动同步到各区域的存储节点,用户访问时由就近的 CDN 节点提供服务,既保证资源可用,又提升加载速度。
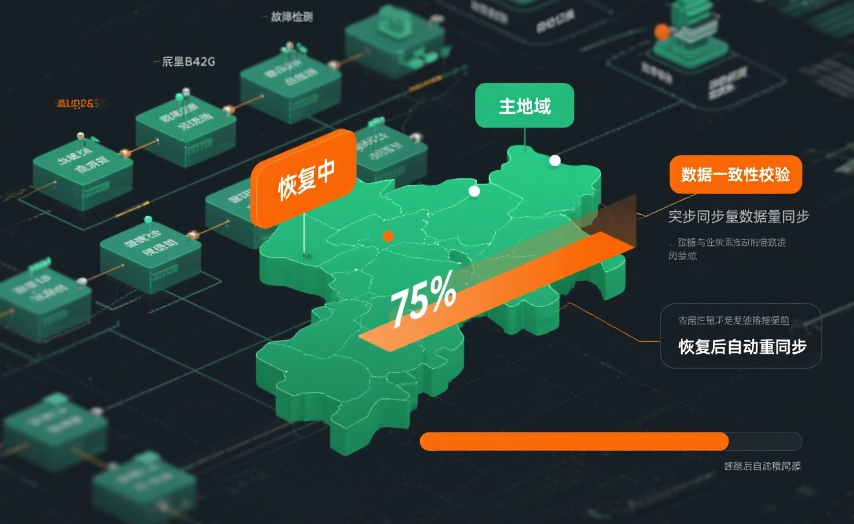
为了应对极端情况下的同步中断,ZKmall 设计了 "数据校验与补传" 机制:每小时对比核心区与备份区的数据哈希值,发现不一致时自动启动增量补传,确保数据最终一致。有家跨境电商在一次跨洋光缆故障中,靠这个机制在网络恢复后 30 分钟内完成了数据补传,没出现数据丢失。
流量调度策略
合理分配各区域的流量,是发挥多地域部署优势的关键。ZKmall 的智能流量调度系统根据三个维度动态分配请求:
地域就近原则:通过 DNS 解析把用户请求引导到最近的服务节点。比如北京用户优先分配到华北区,广州用户优先分配到华南区,海外用户分配到对应的边缘节点,平均减少 30% 的网络延迟。
负载均衡原则:实时监控各区域的服务器负载(CPU 使用率、内存占用、请求响应时间),某区域负载超过 70% 时,自动把部分流量转移到负载较低的区域。促销活动期间,这个机制能有效避免单区域因流量峰值而崩溃。
故障规避原则:通过健康检查(每 10 秒一次)发现异常节点(比如接口响应超时、错误率上升),立即把流量切换到其他正常节点,直到故障恢复。有家平台在 "双 11" 期间,靠这个机制自动规避了 12 次节点级故障,用户完全没感觉到。
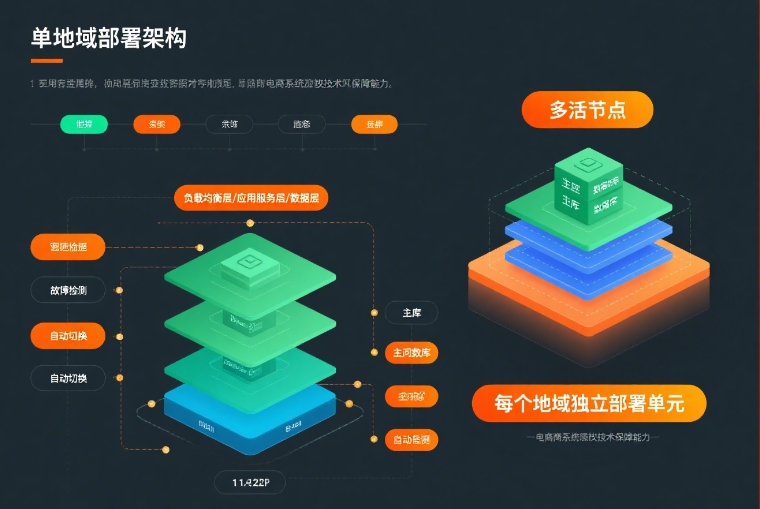
故障切换机制:从检测到恢复的全自动化流程
即使部署了多地域节点,也需要高效的故障切换机制才能实现真正的容灾。ZKmall 把故障切换拆成 "检测 - 评估 - 切换 - 恢复" 四个环节,全程自动化完成,不用人工干预。
多层级故障检测
ZKmall 从三个层面监测系统健康状态,确保故障早发现:
基础设施层:监控服务器 CPU、内存、磁盘 IO、网络带宽等指标,设置阈值告警(比如 CPU 持续 5 分钟超过 85%)。
应用服务层:通过 Spring Boot Actuator 暴露服务健康检查接口,监控各微服务的存活状态、接口响应时间、错误率。核心服务(比如支付服务)的错误率超过 1% 时立即触发预警。
业务链路层:通过分布式追踪系统(SkyWalking)监控完整业务流程(比如 "下单 - 支付 - 发货")的成功率,链路成功率低于 99.9% 时,分析定位故障节点。
检测系统采用 "多源确认" 机制,避免误判:同一故障需要至少两个独立监测节点确认(比如基础设施监控和应用服务监控同时报警),才会触发后续的切换流程。有家平台靠这个机制把故障误判率控制在 0.1% 以下,减少了不必要的流量波动。
分级故障响应策略
不同级别的故障需要不同的应对方案。ZKmall 把故障分为三级,对应差异化的切换策略:
节点级故障(单个服务器或服务实例故障):自动把该节点的流量转移到同区域的其他正常节点,同时启动备用实例(通过容器编排工具 Kubernetes),恢复集群规模。这种切换 1 分钟内就能完成,用户几乎感觉不到。
区域级故障(某一区域整体不可用,比如机房断电):立即把该区域的所有流量切换到备份区,同时更新 DNS 解析和负载均衡配置,引导新请求直接访问备份区。核心业务的切换 5 分钟内完成,非核心业务 15 分钟内完成。
全局级故障(多区域同时受影响,比如大规模网络攻击):启动 "核心功能降级" 模式,只保留订单、支付等最核心的服务,关闭推荐、评价、社区等非必要功能,集中资源保障交易通道畅通。有家平台在一次 DDoS 攻击中,靠这个模式维持了支付功能的正常运行,损失减少 60%。
自动切换与人工干预结合
ZKmall 的故障切换以自动化为主,但保留人工干预通道,应对复杂情况:
全自动切换:节点级故障和明确的区域级故障(比如机房断网)由系统自动完成切换,不用人工操作。切换过程中,系统会通过短信、邮件、企业微信通知运维团队,但不中断切换流程。
半自动化切换:故障原因不明确(比如数据同步异常)或可能影响数据一致性时,系统会触发告警并等待人工确认,运维人员可以通过后台一键执行切换,或选择其他应对方案。
手动强制切换:极端情况下,运维人员可以绕过自动检测机制,通过控制台强制启动故障切换,适合预判到潜在风险(比如台风来临前主动切换到内陆节点)。
核心场景容灾保障:聚焦电商关键流程
电商系统的容灾不能 "一刀切",需要重点保障对业务影响最大的核心场景。ZKmall 针对支付、订单、商品展示等关键流程设计了专项容灾方案。
支付流程容灾
支付环节一旦中断,直接导致交易失败和用户流失。ZKmall 从三个层面保障支付连续性:
多支付渠道冗余:同时接入多家支付服务商(比如微信支付、支付宝、银联),某一渠道出故障时,自动切换到其他可用渠道。例如微信支付接口超时,系统会立即隐藏微信支付选项,只展示支付宝和银联,用户不用重新下单就能完成支付。
支付状态确认机制:支付请求发送后,没收到明确结果(比如网络中断),系统会通过异步回调、主动查询(每 30 秒一次)等方式确认支付状态,避免 "用户已付款但订单未确认" 的情况。有家平台靠这个机制解决了 3% 的支付状态模糊问题,挽回了大量订单。
支付记录本地缓存:用户支付操作会在本地浏览器 / 小程序中缓存记录,即使服务端暂时不可用,用户也能通过缓存信息查询支付状态,避免重复支付。
订单系统容灾
订单系统是电商的 "账本",其可用性直接关系到业务连续性。ZKmall 的订单容灾方案包括:
订单分库分表:按用户 ID 哈希值把订单数据分散存储在多个数据库分片,单个分片故障只影响部分用户,不会导致整体订单系统瘫痪。
订单状态本地闭环:每个区域的订单服务可以独立处理从创建到完成的全流程,即使和其他区域断开连接,也能保证本区域订单的正常流转。网络恢复后,再同步跨区域的订单关联数据(比如合并订单、跨仓调拨)。
离线订单缓存:极端情况下(比如核心数据库不可用),系统会把订单暂时存储在本地磁盘(采用日志格式),数据库恢复后批量写入,确保订单不丢失。有家生鲜平台在一次数据库故障中,靠这个机制保存了 2000 多个离线订单,恢复后全部正常处理。
商品展示容灾
商品无法正常展示会导致用户无法下单,影响前端流量转化。ZKmall 的商品展示容灾方案包括:
静态化与缓存:把商品详情页预渲染为静态 HTML,缓存在 CDN 和边缘节点,即使后端服务故障,用户还能查看商品信息(无法下单但可浏览)。
降级展示策略:服务压力过大时,自动简化商品页面,只展示名称、价格、库存等核心信息,隐藏评价、推荐、关联商品等非必要内容,减少服务器计算压力。
默认库存保护:商品库存查询服务故障时,系统自动展示 "库存充足"(实际库存需后续校验),避免因库存显示异常导致用户放弃购买。有家平台在流量峰值期间,靠这个策略减少了 15% 的潜在流失。
容灾演练与持续优化
容灾能力不是一蹴而就的,需要通过定期演练发现问题并持续优化。ZKmall 建立了完善的容灾演练机制,确保故障发生时系统能按预期响应。
常态化容灾演练
ZKmall 建议商家每月进行一次容灾演练,模拟不同级别的故障场景:
桌面推演:运维团队定期梳理故障应急预案,通过讨论和流程走查发现预案中的漏洞。比如模拟 "核心区数据库崩溃" 场景,检查从故障检测到切换至备份区的每个步骤是否清晰,责任人是否明确。
技术演练:在非高峰时段(比如凌晨 2-4 点)实际触发故障(比如关闭某区域的服务器、切断网络连接),观察系统是否能自动切换,记录切换时间和数据一致性情况。有家电商通过技术演练发现,备份区的部分插件没及时更新,导致切换后部分功能不可用,随后建立了插件版本同步机制。
实战演练:每季度进行一次全链路实战演练,模拟真实故障对业务的影响。比如在促销活动前,故意把 30% 的流量切换到备份区,检验备份区的承载能力和业务连续性。有家平台通过实战演练,把区域级故障的切换时间从 15 分钟缩短到 8 分钟。
容灾能力评估指标
通过量化指标评估容灾体系的有效性,持续改进:
RTO(恢复时间目标):衡量系统从故障发生到恢复正常运行的时间。ZKmall 的目标是:节点级故障 RTO≤1 分钟,区域级故障 RTO≤10 分钟,全局级故障 RTO≤30 分钟。
RPO(恢复点目标):衡量故障导致的数据丢失量。ZKmall 的目标是:核心数据 RPO≤1 秒(最多丢失 1 秒内的数据),非核心数据 RPO≤5 分钟。
故障覆盖率:评估系统能自动应对的故障类型比例。通过持续优化,目标是覆盖 90% 以上的常见故障(比如服务器宕机、网络中断、数据库异常)。
业务影响度:量化故障对业务的影响,比如订单损失率、用户投诉率、营收损失等。优秀的容灾体系应将区域级故障的订单损失率控制在 5% 以内。
持续优化机制
容灾体系需要根据业务发展和技术演进不断优化:
定期复盘:每次故障或演练后,召开复盘会议,分析问题原因(比如切换时间过长、数据同步延迟),制定改进措施。有家平台在一次演练后发现,备份区的部分插件没及时更新,导致切换后部分功能不可用,随后建立了插件版本同步机制。
技术迭代:跟踪云计算和分布式系统的新技术(比如多云部署、Serverless 架构),把成熟的技术应用到容灾体系中。例如引入云厂商的 "异地多活" 托管服务,进一步降低自建容灾的复杂度。
业务适配:随着业务拓展(比如新增跨境业务、直播电商),同步升级容灾方案。例如开展海外业务后,在目标市场部署新的备份区,优化跨境数据同步策略。
容灾能力是电商的核心竞争力
在用户对系统稳定性期待越来越高的今天,容灾能力已不再是 "可选配置",而是电商平台的核心竞争力之一。ZKmall 的多地域部署与故障切换机制,通过 "预防(多地域部署)- 监测(多层级检测)- 响应(分级切换)- 恢复(数据同步)" 的全流程设计,为商家提供了可落地的容灾解决方案。
对中小商家来说,这套机制能帮助他们以可控成本建立基础容灾能力,避免因一次意外故障而一蹶不振;对大型平台来说,能支撑其业务全球化布局,在不同地区提供稳定的服务体验;对跨境电商来说,则能应对复杂的国际网络环境和地域风险,保障全球业务的连续性。
容灾的终极目标不是消灭故障,而是将故障的影响控制在可接受范围。ZKmall 的实践表明,通过合理的架构设计和自动化机制,即使发生故障,也能让用户 "感知不到" 或 "影响最小化",这正是电商系统在激烈竞争中赢得用户信任的关键。