基于Hadoop的汽车价格预测分析及评论情感分析可视化系统
文章目录
- ==有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主==
- 一、项目背景
- 二、项目目标
- 三、系统架构
- 四、功能模块
- 五、创新点
- 六、应用价值与前景
- 每文一语
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
一、项目背景
近年来,中国二手车交易市场发展迅猛。2023 年全国二手车交易量已突破 1800 万辆,交易额超过 1.2 万亿元,年复合增长率保持在 12%以上。二手车市场与新车相比,更依赖多维度数据的综合评估,包括车辆品牌、车型、年份、里程、环保标准、维修记录、市场行情以及用户评论等。然而,行业仍面临多项核心问题:
- 数据分散与异构:数据来源广泛,包括二手车交易平台、4S 店系统、维修保险机构、社交媒体评论等,涵盖结构化、半结构化和非结构化数据。
- 价格与口碑缺乏量化分析:传统人工定价无法综合评估车辆技术状态与市场口碑,容易造成估值偏差。
- 处理效率低:面对日均百万级交易与评论数据,传统单机分析系统在性能、扩展性和容错性方面存在明显瓶颈。
- 可视化与决策支持不足:大多数系统以静态报表形式呈现结果,缺乏实时性与交互性,无法满足经销商与消费者的即时查询与分析需求。
随着 Hadoop 等大数据技术的成熟,分布式架构在处理 PB 级别数据、支持多源异构数据整合和高效分析方面展现出巨大优势。本项目正是在此背景下提出,旨在构建一个覆盖数据采集、预处理、存储、分析(含情感分析)、可视化的全流程二手车大数据分析系统,实现行业数据的高效整合、深度挖掘与多维展示。
二、项目目标
本项目的主要目标是设计并实现一套基于 Hadoop 的二手汽车大数据分析系统,功能包括:
-
多源数据采集与整合
通过 Python 爬虫、Flume 等工具采集并传输交易平台车辆信息,涵盖品牌、车型、年份、里程、售价、环保标准、首付比例等关键字段。 -
分布式存储与管理
利用 HDFS 存储结构化与非结构化数据,并通过 Hive 构建数据仓库实现主题化管理与多维度查询。 -
数据清洗与标准化
完成重复记录去除、缺失值填充、格式统一及噪声过滤,保证数据质量。 -
多维分析与情感挖掘
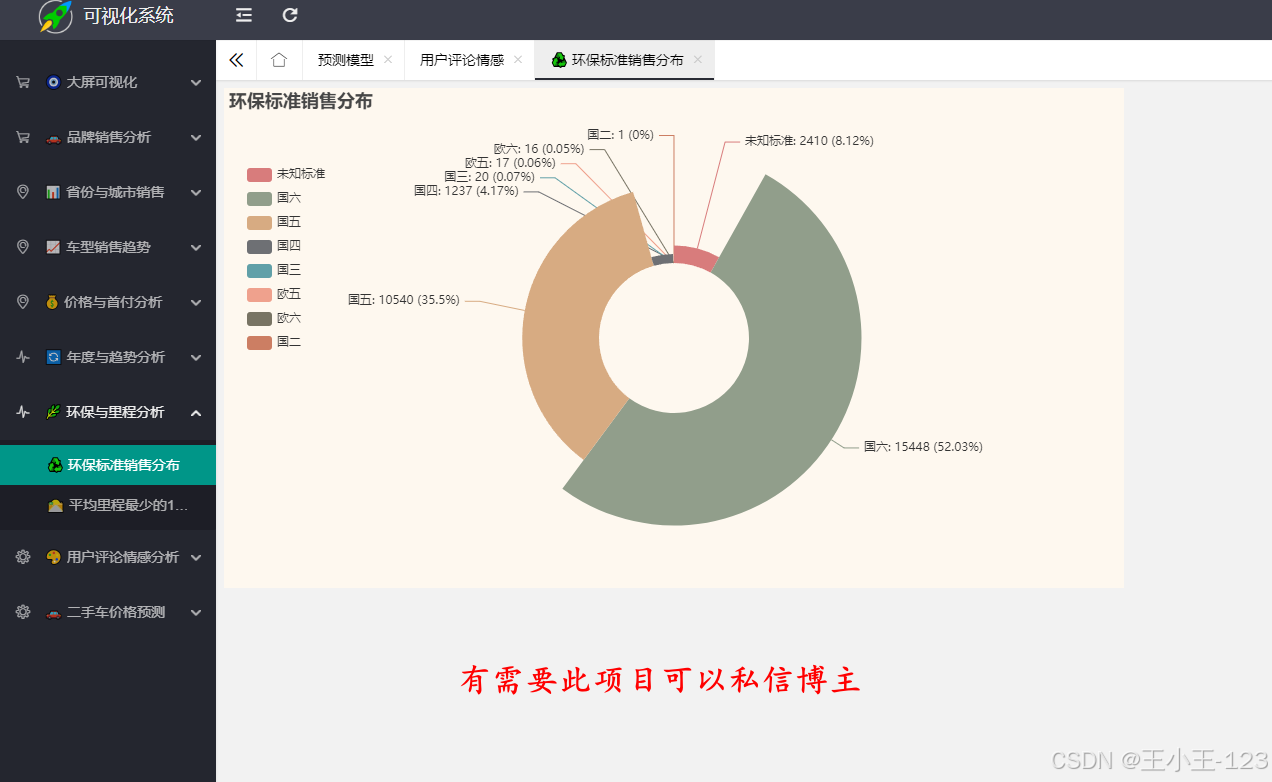
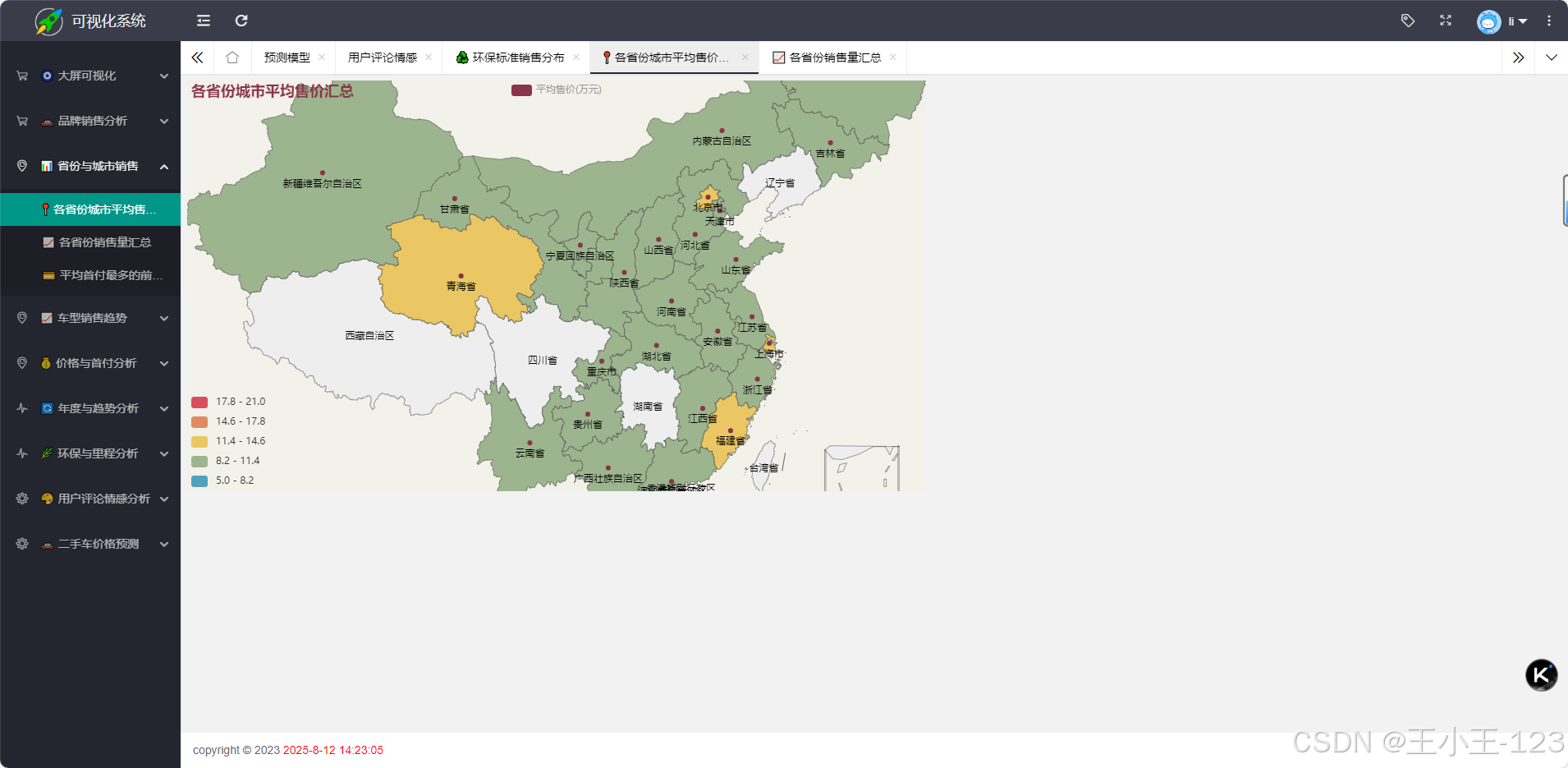
- 业务分析:品牌销量统计、城市价格分布、环保标准与价格关联性分析。
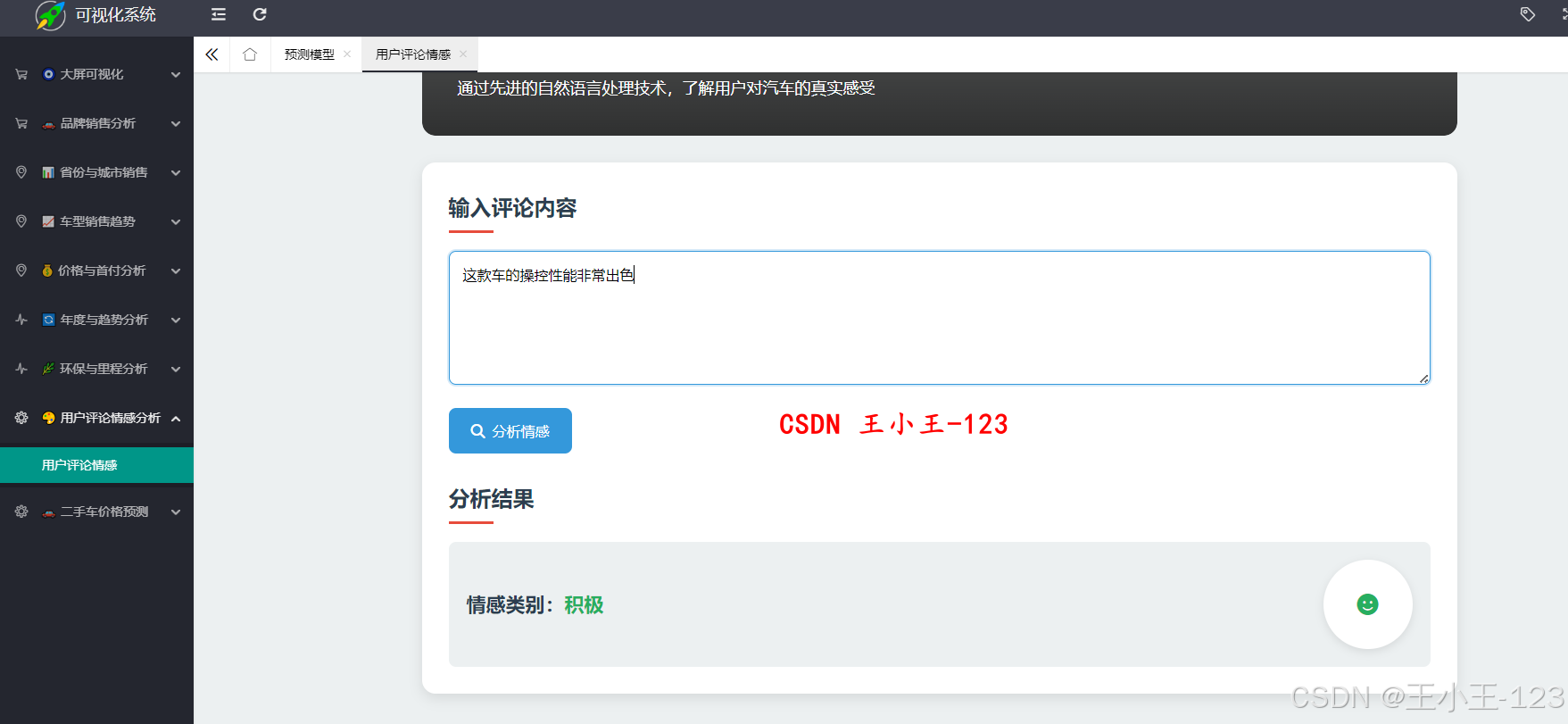
- 评论情感分析:基于分词与情感词典(或机器学习模型)识别用户评论中的正向、负向与中性情绪,评估市场口碑。
-
计算与预测
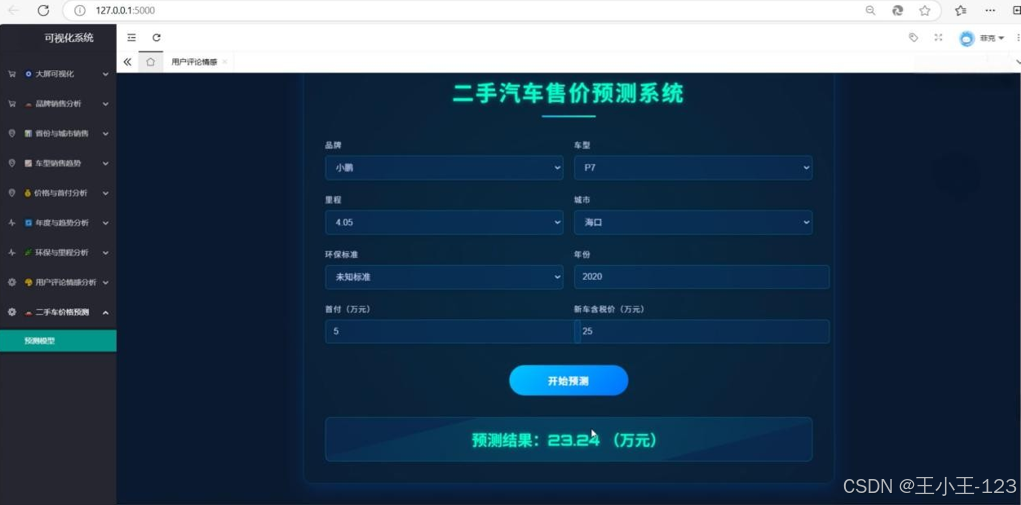
利用机器学习实现价格预测 -
交互式可视化
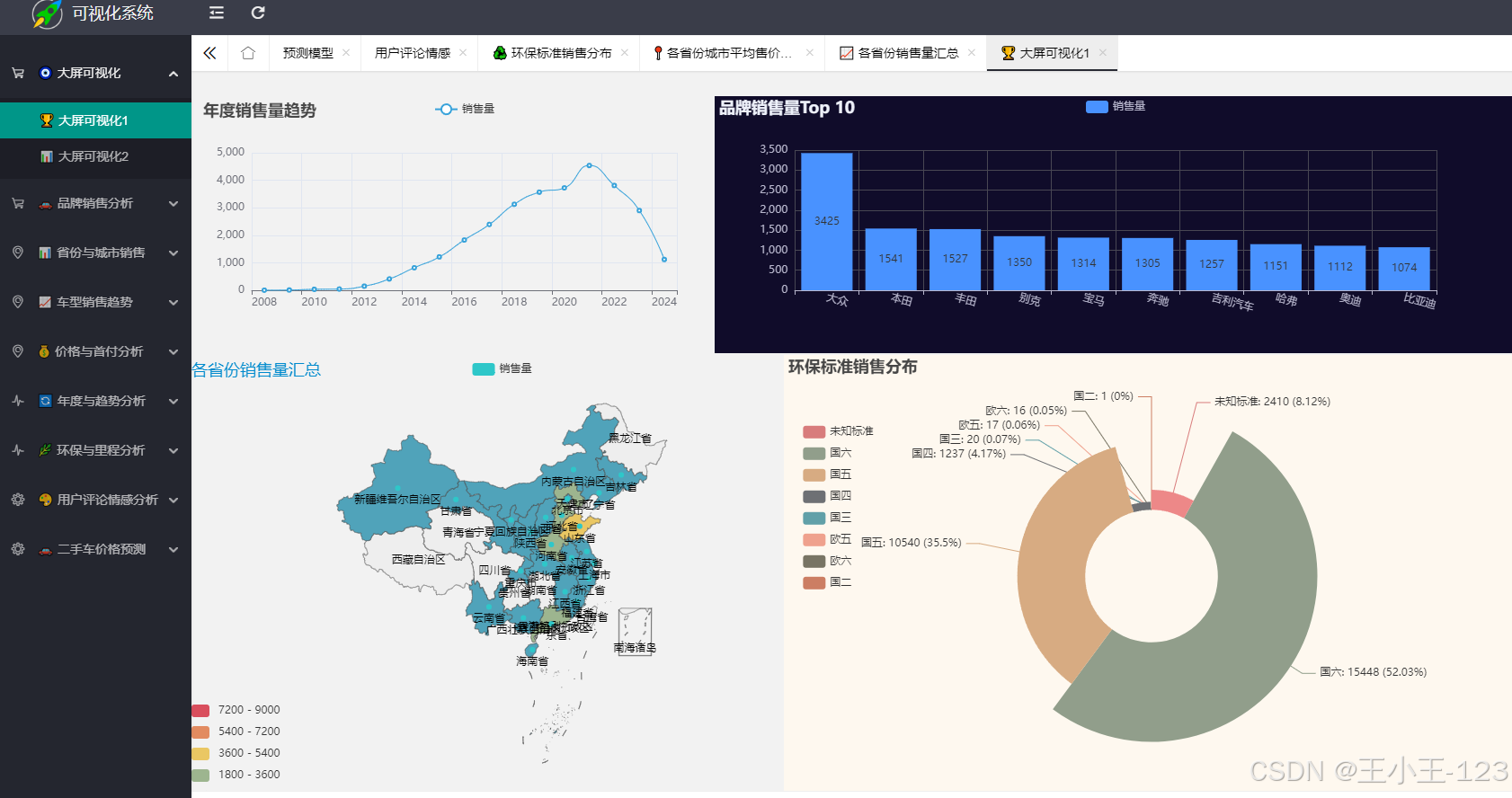
借助 ECharts 与 Flask,构建可交互的可视化大屏,提供热力图、趋势折线图、饼图以及评论情感分布图。
三、系统架构
系统采用分层架构,从数据源到用户界面形成闭环流程:
-
数据采集层
- 车辆信息:利用 Python Requests/Scrapy 爬虫抓取车辆交易数据。
- 用户评论:爬取交易平台或社交媒体评论文本,保留评论时间、内容、评分等元数据。
- Flume 用于实时日志与流数据传输。
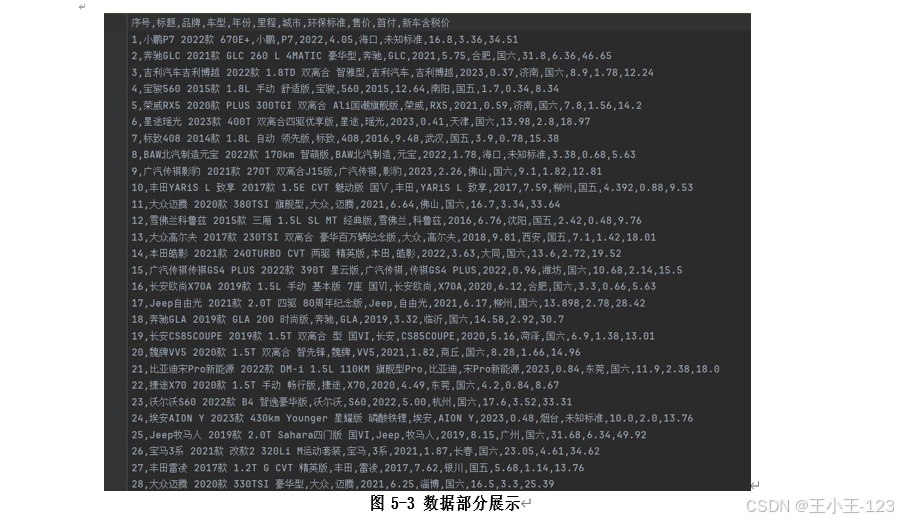
-
数据存储层
-
HDFS 存储清洗后的车辆数据与评论数据,冗余备份保证高可用性。
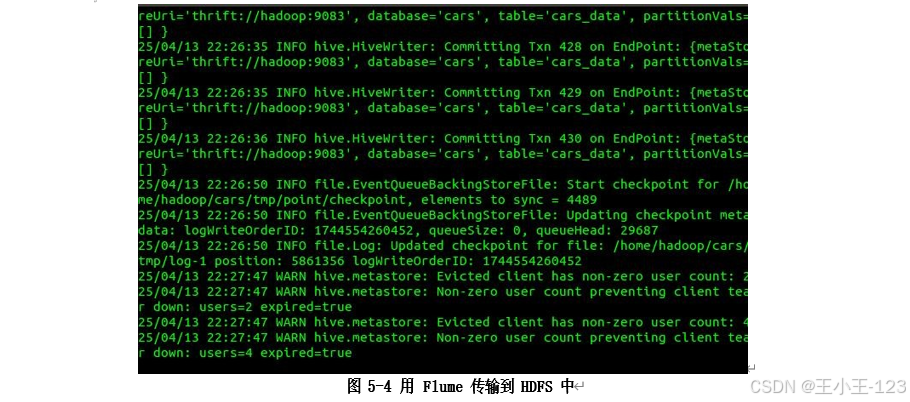
-
Hive 构建数据仓库,按业务主题(交易、价格、评论)建立事实表与维度表。
-
-
数据预处理层
- MapReduce 批量清洗与格式化数据,统一价格单位、时间格式等。
- 评论数据分词、去除停用词,为情感分析做准备。
-
数据分析层
- HiveQL 完成业务指标分析(品牌销量、价格分布等)。
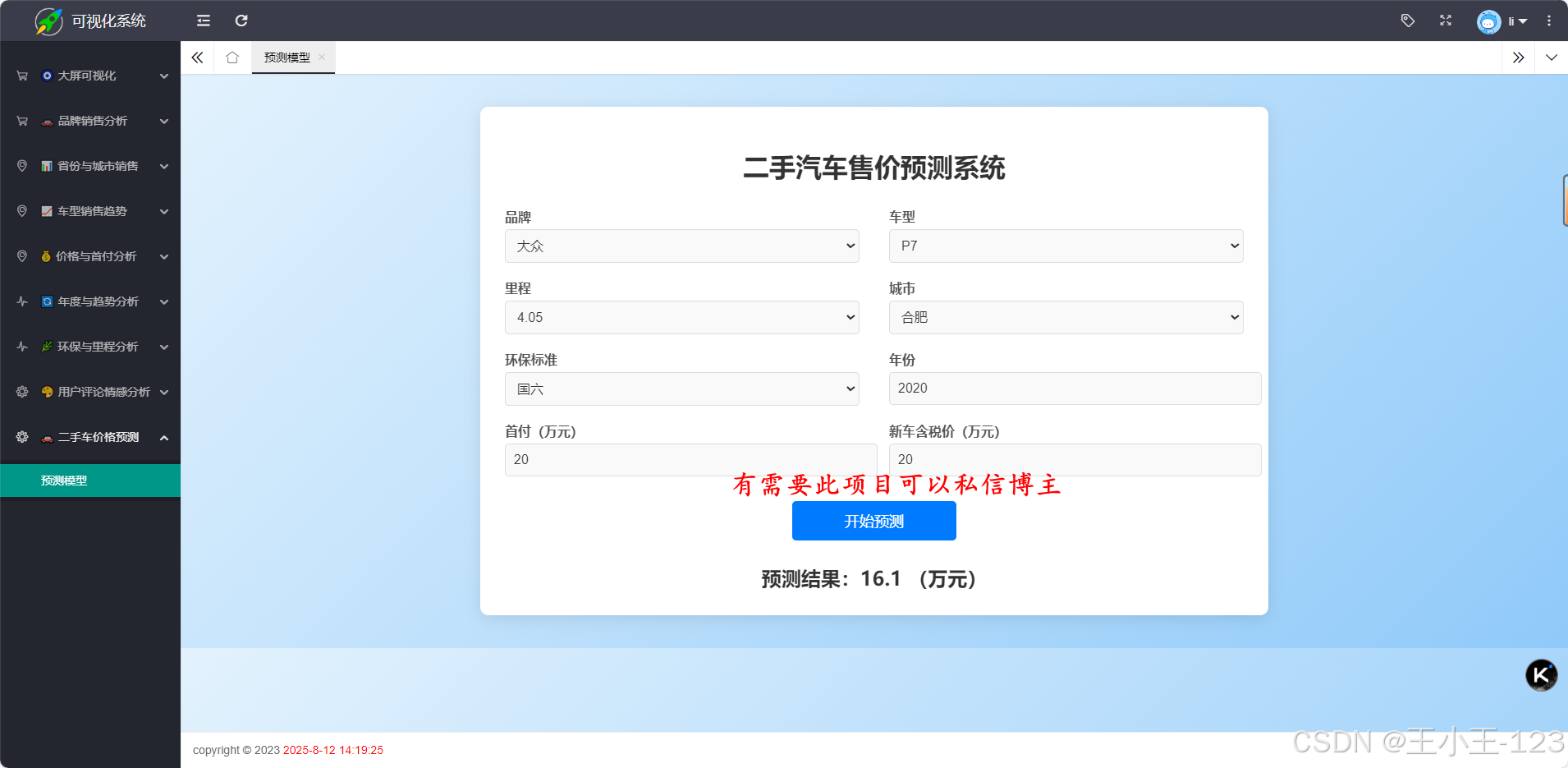
- 机器学习价格预测。
- 情感分析模块:基于情感词典或机器学习(如朴素贝叶斯、BERT 微调)对评论进行情绪分类,生成情感得分与分布。
-
可视化与交互层
- ECharts 绘制价格趋势、品牌占比、销售热力图。
- 评论情感分析结果通过饼图、词云等方式展示。
- Flask 提供用户查询、筛选、预测交互功能。
-
数据导出与集成层
- Sqoop 将 Hive 分析结果同步至 MySQL,提升查询性能并为可视化调用提供支持。
四、功能模块
-
数据采集模块(海量数据)
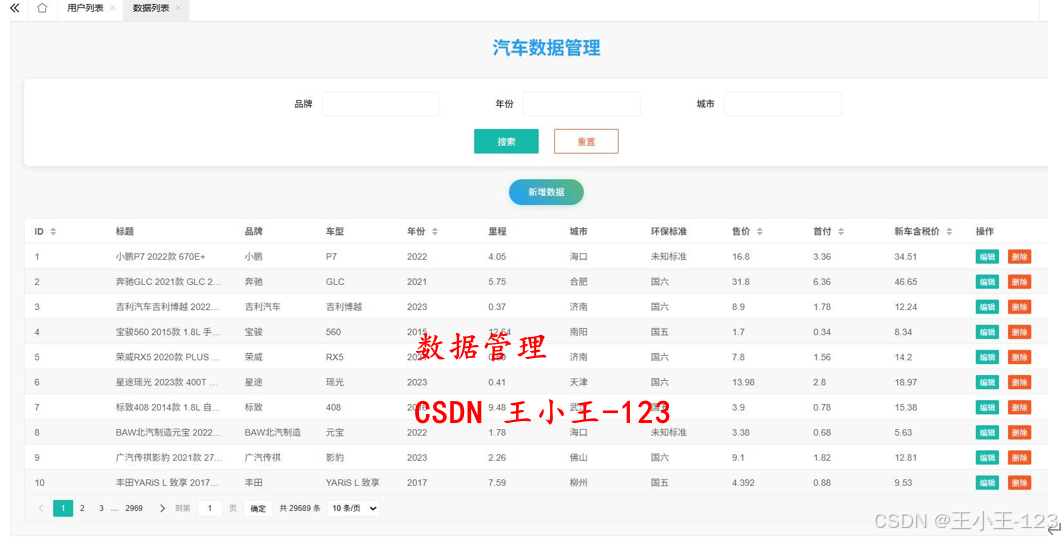
- 交易数据:品牌、车型、年份、里程、售价、环保标准等。
- 评论数据:用户评分、评论内容、时间、地区。
- 反爬策略:User-Agent 池、请求延时、Referer 模拟。
-
数据预处理模块(多维度数据预处理)
- 价格、里程单位统一(如“万公里”转为数值)。
- 缺失值填充与异常值剔除。
- 评论数据分词、去停用词、提取关键词。
-
情感分析模块(自然语言处理)
- 输出:整体口碑得分、情感分布比例(正向、中性、负向)。
-
数据分析模块
- 品牌销量、市场占比。
- 城市价格热力分析。
- 环保标准与价格关联性。
- 价格预测与趋势分析。
-
可视化展示模块
- ECharts 绘制交互式图表:热力图、趋势图、饼图、词云。
- 评论情感直观展现用户关注点与情绪倾向。
-
用户交互模块
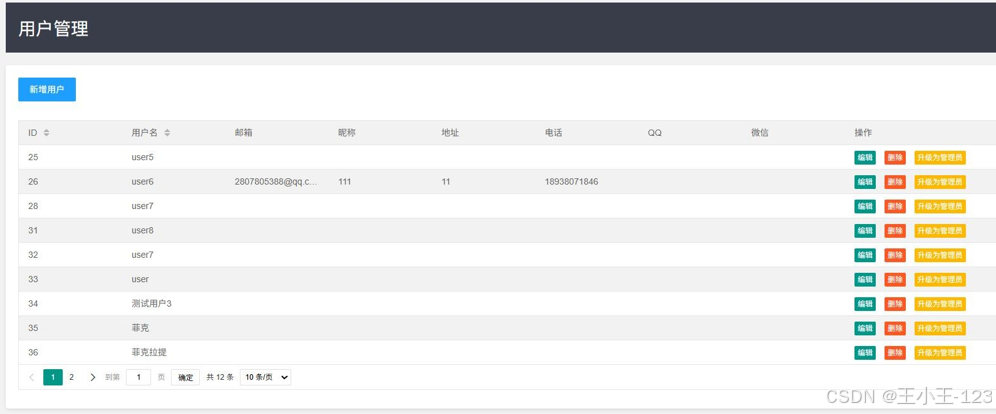
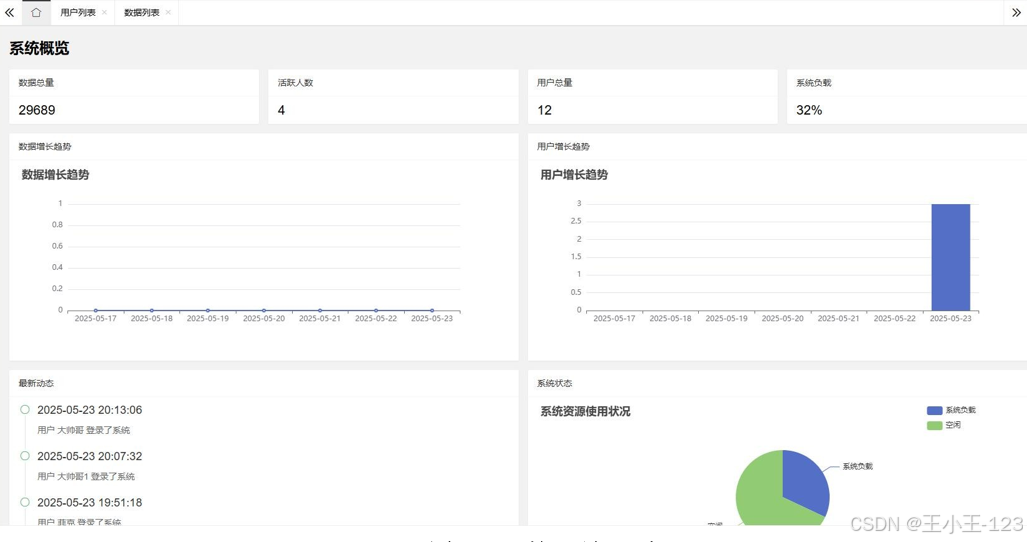
- 注册、登录、权限管理;
- 按条件筛选车辆,对数据进行增删改查
- 管理用户权限及信息
五、创新点
- 多源异构数据整合:交易数据与用户评论数据并行采集与处理,实现结构化与非结构化数据的统一管理。
- 情感分析融入业务决策:将用户情绪与交易数据结合,分析口碑与销量、价格之间的关系,为精准营销与定价优化提供依据。
- 混合计算架构:结合 Hadoop 批处理与 价格预测,兼顾历史分析与实时监控。
- 可扩展可视化平台:支持多终端访问与交互,情感分析结果可与价格、销量数据联动展示。
六、应用价值与前景
-
行业价值
- 为经销商提供基于价格与口碑的综合分析,优化库存与促销策略;
- 为消费者提供透明的车辆价格与口碑信息,提升购车信心。
-
技术价值
- 提供从采集、清洗、存储、分析到可视化的一体化大数据解决方案;
- 验证情感分析在汽车大数据场景下的应用可行性。
-
社会价值
- 提升二手车市场透明度,减少信息不对称;
- 促进循环利用与绿色出行。
-
未来拓展
- 引入深度学习模型(如BERT、ERNIE)提升情感分析准确率;
- 结合图像识别技术实现车况自动评估;
- 通过区块链实现车辆历史记录不可篡改的可信溯源;
- 拓展至新能源二手车电池健康评估与交易平台。

每文一语
静下来思考;然后开始行动