Apache SeaTunnel 新定位!迈向多模态数据集成的统一工具
在人工智能时代,数据不再是简单的数字和表格那么简单了。
你可能处理的是一张用户上传的商品图片、一段实时语音对话、一条点击事件日志,甚至是一段视频中的关键帧。这些都属于“多模态数据”——不同形式、不同结构、但承载着丰富语义的数据。
SeaTunnel,一个源自 Apache 的开源项目,最初只专注于结构化数据库之间的数据同步。但如今,它已经脱胎换骨,完成了跨越式的产品升级:
从传统 ETL 工具演化为 “面向 AI 时代的多模态数据集成工具”(Unified Multimodal Data Integration Tool)

这不仅是一个口号,而是架构的革新、插件生态的升级、以及对 AI 场景的深度适配。
本文将带你了解:SeaTunnel 是如何一步步迈向“多模态”,又是如何赋能今天的 AI 数据体系。
为什么要支持多模态数据?
曾经我们做数据同步,只需要处理订单表、用户表、销售表。
但现在呢?
- 推荐系统需要处理商品图像、用户评论、点击行为。
- 工厂车间的设备监控,不仅采集温度、电压,还采集视频流和图片元信息。
- 金融风控模型,要融合用户身份文本、日志轨迹、OCR 提取的合同文字……
这些都属于多模态场景。结构化、非结构化、流式、向量化数据交织共存,一个统一工具来整合这些数据的需求愈发迫切。
SeaTunnel 的重新定位,就是为了解决这个问题:
无论你是 AI 工程师、数据开发者、架构师,都需要一个能吃下“所有数据形态”的接入工具。
SeaTunnel 的多模态能力从哪里来?
SeaTunnel 本质上是一个“可编排的异构数据流处理引擎”,架构上由三部分组成:
- Source:数据源输入(Kafka、MySQL、File、WebSocket...)
- Transform:中间处理(字段映射、格式清洗、分支处理...)
- Sink:输出目标(ClickHouse、Milvus、Kafka、对象存储...)
我们来一个个拆开看。
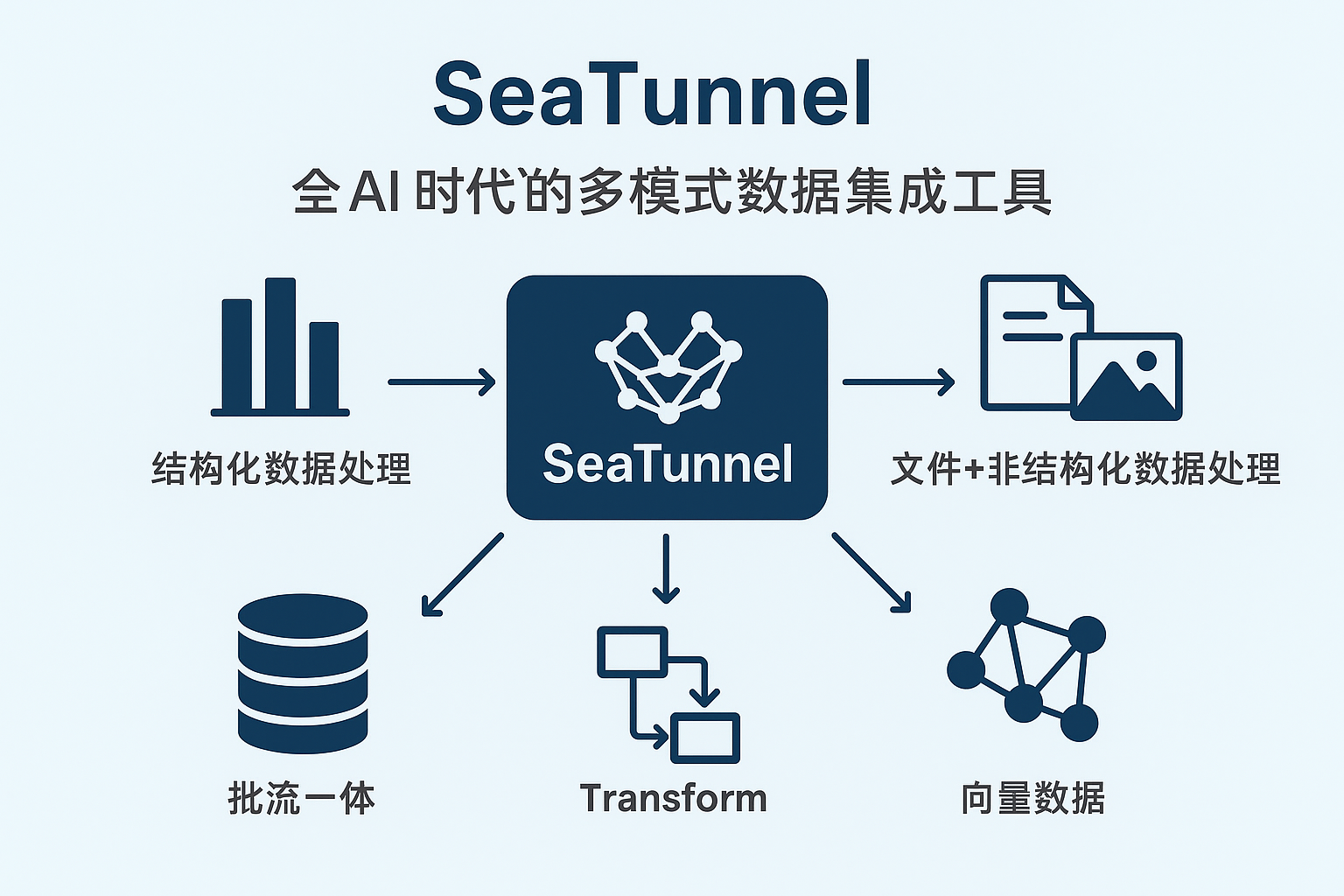
一、结构化数据?那是 SeaTunnel 的老本行
从最早的 MySQL 到如今支持超过 100 种数据源,SeaTunnel 对结构化数据的支持已经不再是问题:
- JDBC 通用支持(MySQL / PostgreSQL / Oracle / SQL Server / DB2)
- 批量和增量同步
- 支持主键合并、分区抽取、断点续传
- 支持 Iceberg / Hudi / Delta Lake 等湖格式
如果你的场景仍然是“表到表”,SeaTunnel 不输任何一款传统 ETL 工具。
二、文件 + 非结构化:图像/日志/PDF 的元信息接入
SeaTunnel 支持对以下文件类型的解析:
- 文本文件(CSV、JSON、Log、INI)
- 表格类文件(Excel、Parquet、ORC)
- 二进制文件(图像、PDF、文档)
通过 FileSource + binary 模式,你可以轻松获取:
- 文件名、文件路径、上传时间
- 文件大小、修改时间、扩展名(通过外部处理脚本提取)
这些字段虽然看起来“不起眼”,但恰恰是构建图像搜索、日志分析等系统的元基础。
SeaTunnel 支持通过插件方式将这些信息结构化成 SeaTunnelRow,供后续使用。
三、实时流?SeaTunnel 本就是流批一体
SeaTunnel 支持完整的流式调度架构:
- Kafka、Pulsar、RocketMQ、RabbitMQ、WebSocket 全支持
- 通过 Hazelcast 做状态管理,支持 Exactly-Once 和断点恢复
- 每秒处理百万级消息不在话下
你可以同时处理 Kafka 中的点击流、MySQL 中的订单表、S3 中的商品图像信息,一起构建向量检索输入源。
四、向量数据?SeaTunnel 已原生支持!
SeaTunnel 在 2.3 版本之后,加入了对向量数据库的原生支持:
- Milvus Sink(支持写入向量数据,指定维度)
- PGVector Sink(将嵌入向量写入 PostgreSQL)
- OpenSearch Sink(写入向量字段)
只需配置:
sink {Milvus {url = "http://127.0.0.1:19530"token = "username:password"batch_size = 1000}
}
无需写 SDK,无需调用 REST 接口,配置即生效。
五、Transform:灵活构建字段级语义处理链路
SeaTunnel 提供丰富的 Transform 插件,帮助用户在结构化数据转换阶段完成字段标准化、内容映射、表达式增强等操作。
当前支持的 Transform 插件包括:
FieldMapper Transform:字段映射与重命名Filter Transform:条件过滤(支持 SQL 表达式)Replace Transform:字符串替换与清洗Split Transform:字段按分隔符切割JsonPath Transform:支持从嵌套 JSON 中提取字段Sql Transform:基于 SeaTunnel SQL 的表达式计算能力
通过这些插件,用户可以完成复杂字段派生、数据标准化、类型转换、嵌套结构展开等多种场景需求,是构建 AI 语义底座的重要组成部分。
未来版本中,SeaTunnel 社区正在积极探索更多“可编程 Transform”的插件能力,如:
- 支持与模型推理服务对接的 HTTP 调用变换
- 嵌入式表达式引擎优化
- 更高阶的 Map/Reduce 类流式变换语义
这些特性将持续增强 SeaTunnel 在多模态处理中的表现力。
无论是字段清洗还是特征增强,SeaTunnel 的 Transform 插件为 AI 时代的数据预处理链路提供了坚实支撑。
多模态链路示例:图像 + 文本 + 行为流 → 向量库
构建图文推荐系统,只需要三条链路:
商品图像(S3) → FileSource → 预处理服务(CLIP) → MilvusSink
商品描述(MySQL)→ JDBCSource → 预处理服务(BERT)→ MilvusSink
用户行为流(Kafka)→ KafkaSource → ClickHouseSink
最终你将得到:
- 图像向量库
- 文本向量库
- 实时行为日志流
你就可以在下游实现:
- 相似图文推荐
- 用户向量 + 商品向量召回
- 实时热点商品识别
全部基于 SeaTunnel 完成。
社区正在推进的下一步:全链路 AI 数据底座
SeaTunnel 目前已在 WhaleStudio 可视化工具中支持多模态任务配置。
未来,社区正在推进:
- 多模态数据血缘分析(来源追踪 / AI链路识别)
- 多模态数据质量检查(字段一致性 / 缺失监测)
- 与 LangChain / RAG 结合的检索增强任务模板
- 向量库 + 大模型双向同步能力(向量更新 / LLM 推理)
你能想象的 AI 数据流,SeaTunnel 社区正在逐一落地。
写在最后:SeaTunnel,为结构而生,为多模态而进化
SeaTunnel 已不再是传统 ELT 工具。
它已经蜕变成
- 一个连接数据世界和语义世界的桥梁
- 一个低代码、插件式、场景丰富的 AI 数据流接入工具
- 一个面向向量时代、支持多模态任务的统一引擎
官网:Apache SeaTunnel | Apache SeaTunnel
GitHub:https://github.com/apache/seatunnel
如果你正在构建 AI 多模态系统,不妨看看 SeaTunnel 是不是你缺失的那块拼图。