SQL 基础查询语句详解
SQL(Structured Query Language,结构化查询语言)是操作关系型数据库的标准语言,而查询语句是 SQL 中最核心、最常用的部分。无论是数据提取、报表生成还是数据分析,都离不开基础查询的灵活运用。本文将系统讲解 SQL 基础查询语句的语法、用法及实战案例,帮助初学者快速入门。
一、SQL 查询的基本结构
SQL 查询的核心是SELECT语句,基本结构如下:
SELECT 列名1, 列名2, ... -- 要查询的列(*表示所有列)
FROM 表名 -- 数据来源的表
[WHERE 条件] -- 筛选行的条件(可选)
[GROUP BY 列名] -- 按列分组(可选,通常配合聚合函数)
[HAVING 分组条件] -- 筛选分组后的结果(可选)
[ORDER BY 列名 [ASC|DESC]]; -- 排序(可选,ASC升序,DESC降序)这是一个 “从大到小” 的筛选过程:先确定数据源(FROM),再筛选行(WHERE),然后可能分组(GROUP BY),最后确定输出的列(SELECT)和排序(ORDER BY)。
二、基础查询:SELECT 与 FROM
1. 查询所有列
使用*表示查询表中所有列(不推荐在生产环境使用,效率低且依赖表结构):
-- 查询student表所有学生的信息
SELECT * FROM student;2. 查询指定列
指定需要的列名,多个列用逗号分隔,结果只包含这些列:
-- 查询student表中学生的姓名和年龄
SELECT sname, age FROM student;3. 列别名(AS)
用AS给列起别名,使结果更易读(AS可省略):
-- 查询学生姓名(别名“学生姓名”)和年龄(别名“年龄”)
SELECT sname AS 学生姓名, age 年龄 FROM student;三、条件筛选:WHERE 子句
WHERE用于筛选符合条件的行,支持多种运算符:
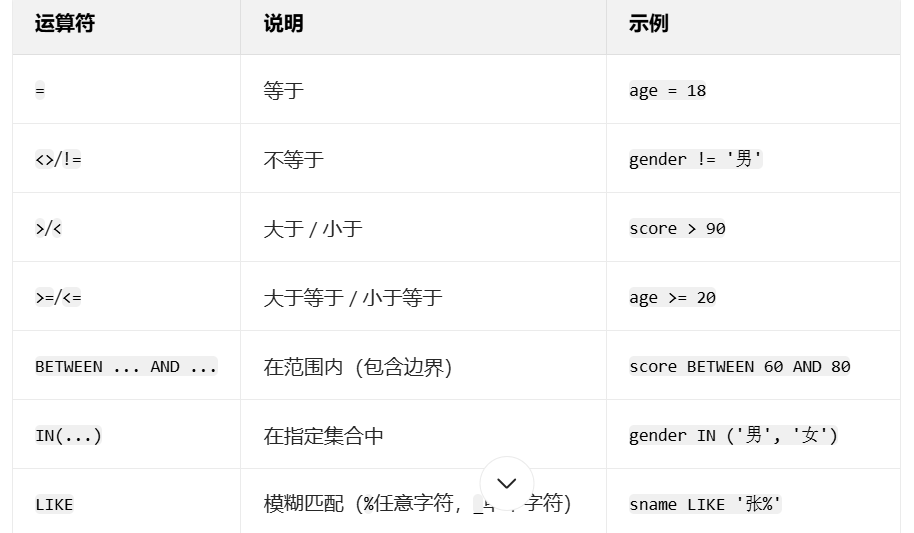

示例:
-- 1. 查询年龄大于18的学生
SELECT sname, age FROM student WHERE age > 18;-- 2. 查询成绩在60到80之间的学生(包含60和80)
SELECT sname, score FROM student WHERE score BETWEEN 60 AND 80;-- 3. 查询姓张的学生(“张%”表示以张开头的姓名)
SELECT sname FROM student WHERE sname LIKE '张%';-- 4. 查询性别为男且年龄大于20的学生
SELECT sname, gender, age FROM student WHERE gender = '男' AND age > 20;四、排序:ORDER BY 子句
ORDER BY用于对结果按指定列排序,默认升序(ASC),可指定DESC降序:
-- 1. 按年龄升序排列(从小到大)
SELECT sname, age FROM student ORDER BY age;-- 2. 按成绩降序排列(从高到低),成绩相同则按年龄升序
SELECT sname, score, age FROM student ORDER BY score DESC, age ASC;注意:ORDER BY必须放在查询语句的最后(LIMIT除外)。
五、去重:DISTINCT
DISTINCT用于去除查询结果中的重复行,放在列名前:
-- 查询所有学生的性别(去重,只显示“男”和“女”)
SELECT DISTINCT gender FROM student;-- 注意:DISTINCT作用于后面所有列的组合
SELECT DISTINCT gender, age FROM student; -- 去除“性别+年龄”都相同的行六、聚合函数:对数据进行统计
聚合函数用于对一组数据进行计算并返回单一结果,常用函数如下:
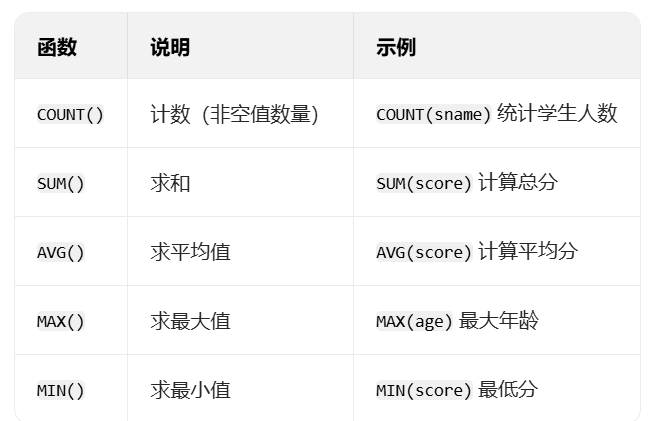
示例:
-- 1. 统计学生总人数(COUNT(*)包含null,COUNT(列)不包含null)
SELECT COUNT(*) AS 总人数 FROM student;-- 2. 计算所有学生的平均成绩
SELECT AVG(score) AS 平均成绩 FROM student;-- 3. 查询最高成绩和最低成绩
SELECT MAX(score) AS 最高分, MIN(score) AS 最低分 FROM student;七、分组查询:GROUP BY 与 HAVING
GROUP BY用于按指定列对数据分组,每组单独应用聚合函数;HAVING用于筛选分组后的结果(类似WHERE,但可作用于聚合函数)。
示例:
-- 1. 按性别分组,统计每组的人数
SELECT gender AS 性别, COUNT(*) AS 人数
FROM student
GROUP BY gender;-- 2. 按班级分组,查询平均分大于80的班级(HAVING筛选分组结果)
SELECT class AS 班级, AVG(score) AS 平均分
FROM student
GROUP BY class
HAVING AVG(score) > 80; -- HAVING可直接使用聚合函数-- 3. 先筛选年龄>18的学生,再按性别分组统计人数(WHERE在GROUP BY前)
SELECT gender AS 性别, COUNT(*) AS 人数
FROM student
WHERE age > 18 -- 先筛选行
GROUP BY gender; -- 再分组区别:WHERE在分组前筛选行,不能使用聚合函数;HAVING在分组后筛选组,可使用聚合函数。
八、 LIMIT:限制查询结果数量
LIMIT用于返回指定行数的结果,常用于分页查询(放在语句最后):
-- 1. 查询前5名学生的信息
SELECT * FROM student LIMIT 5;-- 2. 从第3行开始,查询5条记录(索引从0开始,第3行即索引2)
SELECT * FROM student LIMIT 2, 5; -- 第一个参数:起始索引;第二个参数:行数九、实战案例:综合运用
1、场景与表结构说明
为便于理解,先明确案例涉及的 4 张核心表(学生成绩管理系统常用表):
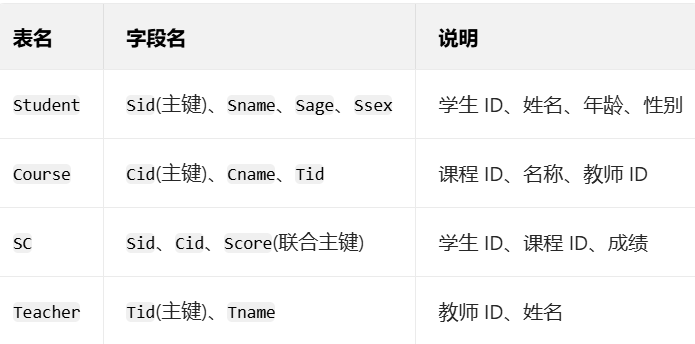
2、10 个经典查询案例详解
案例 1:查询 "01" 课程比 "02" 课程成绩高的学生信息及课程分数
问题分析:需同时获取同一学生的两门课程成绩并比较,需通过自连接将SC表中两门课程的成绩关联到同一学生。
SELECT s.*, sc1.Score AS '01课程分数', sc2.Score AS '02课程分数'
FROM Student s
JOIN SC sc1 ON s.Sid = sc1.Sid AND sc1.Cid = '01' -- 关联01课程成绩
JOIN SC sc2 ON s.Sid = sc2.Sid AND sc2.Cid = '02' -- 关联02课程成绩
WHERE sc1.Score > sc2.Score; -- 筛选01成绩更高的学生
关键点:
- 对
SC表进行两次自连接(分别别名sc1、sc2),分别匹配 01 和 02 课程; - 连接条件需同时指定
Cid,确保获取对应课程的成绩; - 最终通过
WHERE筛选出 01 课程成绩更高的记录。
案例 2:查询同时存在 "01" 课程和 "02" 课程的情况
问题分析:需找到同时选修了两门课程的学生,核心是 “同时存在”,可通过分组统计课程数量实现。
-- 方法1:分组筛选(推荐,高效)
SELECT Sid
FROM SC
WHERE Cid IN ('01', '02') -- 只关注01和02课程
GROUP BY Sid
HAVING COUNT(DISTINCT Cid) = 2; -- 确保两门课程都存在-- 方法2:自连接(适合需要展示成绩时)
SELECT sc1.Sid, sc1.Score AS '01成绩', sc2.Score AS '02成绩'
FROM SC sc1
JOIN SC sc2 ON sc1.Sid = sc2.Sid
WHERE sc1.Cid = '01' AND sc2.Cid = '02';
关键点:
COUNT(DISTINCT Cid)用于避免同一课程被重复计数(如学生重修同一课程);- 自连接方式更直观,适合需要同时展示两门课程成绩的场景。
案例 3:查询存在 "01" 课程但可能不存在 "02" 课程的情况(不存在时显示为 null)
问题分析:需包含所有选修 01 课程的学生,无论是否选修 02 课程,未选修则用null填充,左连接是最佳选择。
SELECT sc1.Sid, sc1.Score AS '01成绩', sc2.Score AS '02成绩' -- 未选修02时显示null
FROM SC sc1
LEFT JOIN SC sc2 ON sc1.Sid = sc2.Sid AND sc2.Cid = '02' -- 左连接02课程
WHERE sc1.Cid = '01'; -- 只筛选01课程的记录
关键点:
LEFT JOIN保证左表(01 课程)的所有记录被保留;- 连接条件
sc2.Cid = '02'必须写在ON后(而非WHERE),否则会过滤掉null记录(WHERE会排除sc2.Cid为null的行)。
案例 4:查询不存在 "01" 课程但存在 "02" 课程的情况
问题分析:需筛选 “选修 02 课程但未选修 01 课程” 的学生,核心是 “排除存在 01 课程的记录”。
-- 方法1:NOT EXISTS子查询(逻辑清晰)
SELECT *
FROM SC sc2
WHERE sc2.Cid = '02' -- 存在02课程AND NOT EXISTS ( -- 不存在01课程SELECT 1 FROM SC sc1 WHERE sc1.Sid = sc2.Sid AND sc1.Cid = '01');-- 方法2:左连接+筛选null(性能更优)
SELECT sc2.*
FROM SC sc2
LEFT JOIN SC sc1 ON sc2.Sid = sc1.Sid AND sc1.Cid = '01'
WHERE sc2.Cid = '02' AND sc1.Sid IS NULL; -- 01课程无匹配
关键点:
NOT EXISTS用于判断 “不存在满足条件的记录”,子查询只需返回 “是否存在”(用SELECT 1即可,无需实际数据);- 左连接后筛选
sc1.Sid IS NULL,表示右表(01 课程)无匹配,即未选修 01 课程。
案例 5:查询平均成绩≥60 分的同学的学生编号、姓名和平均成绩
问题分析:需按学生分组计算平均成绩,筛选出平均值≥60 的记录,需关联学生表获取姓名。
SELECT s.Sid, s.Sname, AVG(sc.Score) AS '平均成绩'
FROM Student s
JOIN SC sc ON s.Sid = sc.Sid -- 关联成绩表
GROUP BY s.Sid, s.Sname -- 按学生分组(注意:GROUP BY需包含SELECT中所有非聚合列)
HAVING AVG(sc.Score) >= 60; -- 筛选平均成绩≥60的学生
关键点:
AVG(sc.Score)计算平均成绩,GROUP BY按学生分组(Sid是主键,可唯一标识学生);HAVING用于筛选聚合后的结果(WHERE无法直接使用聚合函数,需用HAVING)。