精读:《DEEP OC-SORT: MULTI-PEDESTRIAN TRACKING BY ADAPTIVE RE-IDENTIFICATION》
文章目录
- ABSTRACT
- 1. INTRODUCTION
- 2. RELATED WORKS
- 第一小节:基于运动的多目标跟踪 (Motion-based Multi-Object Tracking)
- 第二小节:基于外观的多目标跟踪 (Appearance-based Multi-Object Tracking)
- 3. METHODS
- 图1:Deep OC-SORT 算法流程图精读
- 3.1. Preliminary: OC-SORT
- 3.2. Camera Motion Compensation (CMC)
- **核心动机:为什么需要 CMC?**
- 3.3. Dynamic Appearance
- 3.4. Adaptive Weighting
ABSTRACT
第一句:
“Motion-based association for Multi-Object Tracking (MOT) has recently re-achieved prominence with the rise of powerful object detectors.”
- 精读分析: 这句话首先点明了论文研究的大背景。多目标跟踪(MOT)领域中,一个核心任务是如何将不同帧中的同一个物体关联起来(association)。传统上,这依赖于对物体运动的预测。作者指出,随着近年来物体检测器(如YOLO、Faster R-CNN等)变得越来越强大和精准,单纯依赖运动信息进行关联的跟踪方法又重新变得重要和有效。这为后续提出在该基础上进行改进奠定了基调。
第二句:
“Despite this, little work has been done to incorporate appearance cues beyond simple heuristic models that lack robustness to feature degradation.”
- 精读分析: 这句话指出了当前研究领域的空白和痛点。虽然基于运动的方法很有效,但它们很少能很好地融入物体的“外观信息”(比如一个人的穿着颜色、体型等)。即便有些工作尝试融合外观,也大多采用简单的启发式模型(simple heuristic models)。这些简单模型的缺点是“缺乏鲁棒性”(lack robustness),尤其是在“特征退化”(feature degradation)的情况下,例如当物体变得模糊、被部分遮挡或者光照变化剧烈时,外观特征不再可靠,简单的模型就很容易出错。
第三句:
“In this paper, we propose a novel way to leverage objects’ appearances to adaptively integrate appearance matching into existing high-performance motion-based methods.”
- 精读分析: 这是对本文核心贡献的概括。针对上述问题,作者提出了一个创新的解决方案。关键词是“自适应地(adaptively)”整合外观匹配。这意味着他们的方法不是简单地、一成不变地使用外观信息,而是能够根据情况动态调整。他们选择在一个高性能的运动跟踪方法的基础上进行改进,而不是另起炉灶。
第四句:
“Building upon the pure motion-based method OC-SORT, we achieve 1st place on MOT20 and 2nd place on MOT17 with 63.9 and 64.9 HOTA, respectively.”
- 精读分析: 这句话具体说明了他们的基础模型和取得的成果。
- 基础模型: 他们的方法建立在 OC-SORT 这个纯粹基于运动的跟踪器之上。这表明他们的工作是一种改进和增强,而非完全原创的架构。
- 成果: 他们用关键指标和排名来展示其方法的优越性。HOTA(Higher Order Tracking Accuracy)是目前MOT领域一个非常重要且全面的评估指标,它同时衡量了检测、关联和定位的准确性。在两个主流的行人跟踪基准 MOT17 和 MOT20 上,他们的方法分别取得了第二名和第一名的优异成绩,并给出了具体的HOTA分数(64.9和63.9),这极具说服力。
第五句:
“We also achieve 61.3 HOTA on the challenging DanceTrack benchmark as a new state-of-the-art even compared to more heavily-designed methods.”
- 精读分析: 为了进一步证明方法的泛化能力和鲁棒性,作者在一个更具挑战性的数据集 DanceTrack 上进行了测试。这个数据集的难点在于,所有舞者的外观都非常相似,这使得依赖外观信息的方法极易失败。而他们的模型即使在这种极端情况下,依然取得了新的“业界最佳”(state-of-the-art, SOTA)性能,甚至超过了那些设计得更复杂的(heavily-designed)方法。这强有力地证明了他们“自适应”策略的有效性。
1. INTRODUCTION
第一句:
“With the success of advanced object detectors and motion-based association algorithms, the effective integration of visual appearance with motion-based matching remains relatively under-explored beyond simple moving average models.”
- 精读分析: 这句话与摘要的第一句类似,但提供了更多细节。
- 背景: 再次强调,强大的物体检测器和基于运动的关联算法(引用了等前沿工作)已经很成功了。
- 问题/空白: 核心问题在于如何有效地将“视觉外观”(visual appearance)和“基于运动的匹配”(motion-based matching)结合起来。作者指出,这个方向的研究还“相对不充分”(relatively under-explored)。
- 现有方法的局限: 作者直接点明了现有融合方法的不足之处,即它们大多停留在“简单的移动平均模型”(simple moving average models)。这是一种比较初级的更新策略,比如一个物体的外观特征被简单地认为是它过去几帧外观特征的平均值。这种方法不够智能,无法应对复杂情况。
第二句 & 第三句:
“In this work, we start from a recent pure motion-based tracking algorithm OC-SORT and improve the tracking robustness by incorporating visual appearance with a novel approach. Bounding box-level visual features from strong embedding models still contain significant noise due to occlusion, motion blur, or objects of similar appearance.”
- 精读分析: 这两句明确了工作的起点和面临的核心挑战。
- 起点: 再次明确,本文工作是基于 OC-SORT 的改进。目标是提升其“跟踪鲁棒性”(tracking robustness)。
- 方法: 通过一种“新颖的方法”(novel approach)来融入视觉外观。
- 核心挑战: 这里深入解释了为什么融合外观信息很困难。即使我们用很强的深度学习模型(strong embedding models)去提取一个检测框(Bounding box)内的视觉特征,这些特征仍然会包含大量的“噪声”(significant noise)。噪声的来源主要有三个:
- 遮挡(occlusion): 物体被部分挡住,提取到的特征不完整。
- 运动模糊(motion blur): 物体或相机快速移动,图像模糊,特征质量下降。
- 外观相似的物体(objects of similar appearance): 比如一群穿着同样制服的人,外观特征几乎一样,极易混淆。
- 这部分解释了为什么摘要里提到的“自适应”策略是必要的。因为特征是不可靠的,所以必须智能地判断何时使用、以及多大程度上使用这些特征。
第四句 & 第五句:
“We propose a dynamic and adaptive heuristic-based model to incorporate the visual appearance with motion-based cues in a single stage for object association. Without fine-grained semantics, such as instance segmentation, we improve the accuracy of using visual comparison among objects for association.”
- 精读分析: 这两句阐述了他们提出的模型的关键特性。
- 模型特性: 他们提出了一个“动态和自适应的、基于启发式的模型”(dynamic and adaptive heuristic-based model)。
- Dynamic and adaptive(动态和自适应): 再次强调模型的智能性,能够根据实时情况调整策略。
- Heuristic-based(基于启发式): 这表明模型可能不是一个端到端(end-to-end)训练出来的黑盒子,而是包含了一套精心设计的规则和逻辑。这通常意味着更好的可解释性和效率。
- Single stage(单阶段): 这是一个重要的技术细节。一些方法可能会分两步走:先用运动模型匹配一批,没匹配上的再用外观模型匹配。而“单阶段”意味着将运动和外观两种信息融合在一个统一的框架下,一次性完成匹配决策,通常更优雅和高效。
- 技术范畴: 作者特意指出,他们的方法并不依赖“细粒度的语义信息,例如实例分割”(Without fine-grained semantics, such as instance segmentation)。实例分割能为每个物体提供一个像素级的精确轮廓,可以提取到更干净的外观特征,但其计算成本非常高。作者在这里强调,他们的方法仅使用成本更低的边界框(Bounding Box),就在视觉比较的准确性上取得了提升,这体现了其方法的实用性和高效性。
- 模型特性: 他们提出了一个“动态和自适应的、基于启发式的模型”(dynamic and adaptive heuristic-based model)。
第六句 & 第七句:
“In addition to the contribution of more effectively adding appearance cues to motion-based object association, we integrate camera motion compensation, boosting performance by complementing the object-centric motion model. Our method provides a new and effective baseline model for future works.”
- 精读分析: 这里提出了论文的第二个关键贡献。
- 另一个贡献: 除了更有效地融合外观线索外,他们还集成了“相机运动补偿”(camera motion compensation, CMC)。
- 作用: 传统的运动模型通常是“以物体为中心的”(object-centric),即它只建模物体自身的运动。但是,如果相机在移动(比如手持拍摄),那么物体在画面上的运动轨迹其实是“自身运动”和“相机运动”的叠加。CMC的作用就是要把相机运动的这部分剥离掉,从而让运动预测更加准确,以此来“补充”(complementing)原有的模型。这极大地增强了算法在非静止镜头场景下的性能。
- 定位: 作者将他们的方法定位为一个“新的、有效的基线模型”(new and effective baseline model),希望后续的研究者可以在此基础上继续发展。
最后三句:
“It sets a new state-of-the-art among all published works on MOT17, MOT20, and DanceTrack benchmarks. As our focus is to introduce visual appearance to OC-SORT, we name our method Deep OC-SORT. We note that the adaptive way we incorporate visual appearance with the motion-based method is newly designed, instead of a straightforward adaptation of what DeepSORT does upon SORT.”
- 精读分析: 这部分是收尾,总结成果、命名并强调创新性。
- 成果: 重申了在三个关键数据集上取得了SOTA(state-of-the-art)的成绩。
- 命名: 解释了名称的由来。因为核心工作是为OC-SORT引入了基于深度学习(Deep Learning)的外观特征,所以借鉴了著名的 DeepSORT 的命名方式,取名为 Deep OC-SORT。
- 强调创新性(非常关键): 作者特意用最后一句话将自己的工作与 DeepSORT 区分开来。SORT 是一个早期的运动跟踪器,而 DeepSORT 在其上增加了外观模型和一套匹配逻辑。作者在这里强调,他们不是简单地把 DeepSORT 的那套方法“直接照搬”(straightforward adaptation)到 OC-SORT 上。他们融合外观信息的方式,即那个“自适应的方式”(the adaptive way),是“全新设计的”(newly designed)。这清晰地划清了界限,强调了自己方法论上的原创性。
2. RELATED WORKS
第一小节:基于运动的多目标跟踪 (Motion-based Multi-Object Tracking)
第一句:
“Given the rapid improvement of object detectors, many modern end-to-end MOT models still underperform against classic motion model-based tracking algorithms.”
- 精读分析: 这句话非常有力,提出了一个反直觉但关键的观点。它说,许多现代的、复杂的“端到端”(end-to-end)模型,在性能上反而不如那些“经典的”、基于运动模型的跟踪算法。这为“跟踪-检测分离”(tracking-by-detection)的范式提供了强有力的辩护。作者在暗示:与其构建一个庞大而复杂的单一网络,不如将问题分解,先用最好的检测器做好检测,再用高效的算法做关联,效果可能更好。
第二句:
“The Kalman filter is the foundation of the most famous line of tracking-by-detection methods.”
- 精读分析: 点出了这类方法的“技术基石”——卡尔曼滤波器(Kalman filter)。这是一个经典的信号处理工具,能够根据一系列不完全和包含噪声的测量,对系统的状态(在这里就是指物体的速度、位置等)做出最优估计。
第三句:
“Among this line of work, SORT uses a linear motion assumption to associate tracks by IoU.”
- 精读分析: 介绍了这个流派的“开山鼻祖”——SORT 算法。它有两个关键特点:
- 线性运动假设(linear motion assumption): 假设物体在短时间内做匀速直线运动。这是一个非常强的简化假设,当物体做变速或曲线运动时,预测就会不准。
- 通过IoU关联(associate by IoU): 匹配的依据是卡尔曼滤波器预测的边界框和当前帧检测到的边界框之间的交并比(Intersection over Union)。方法简单、速度快。
第四句:
“ByteTrack is recently proposed to fix missing predictions by using low-confidence candidates in association, achieving good performance by balancing the detection quality and tracking confidence.”
- 精读分析: 介绍了对SORT的一个关键改进——ByteTrack。它解决了SORT的一个核心痛点:SORT会直接丢弃所有低置信度的检测结果。ByteTrack则认为,这些低置信度的检测框可能不是背景,而是一个被遮挡的真实物体。因此,ByteTrack会保留这些低置信度检测框,并在高置信度匹配完成后,用它们来进行第二次匹配,从而“救回”那些被遮挡的物体。
第五句:
“More recently, OC-SORT improves the robustness of tracking in non-linear motion scenarios and relieves the influence from object occlusion or disappearance by more heavily relying on detections directly.”
- 精读分析: 最后引出了本文所基于的模型——OC-SORT。这是对SORT和ByteTrack的进一步发展。它的主要贡献有两点:
- 提升非线性运动场景的鲁棒性: 改进了SORT的线性运动假设,能更好地处理复杂运动。
- 减轻遮挡和消失的影响: 它的核心思想(Observation-Centric,以观测为中心)是,当一个物体的运动预测与实际观测(即检测框)出现偏差时,它会更相信新的观测,而不是固执地相信已经不准的运动模型。这有效避免了卡尔曼滤波器在物体长时间丢失后误差累积过大的问题。
第二小节:基于外观的多目标跟踪 (Appearance-based Multi-Object Tracking)
这一节讨论的是利用物体的视觉特征(长相、颜色等)来进行跟踪的方法。
第一句 & 第二句:
“Visual identification is a straightforward cue to associate targets over time. DeepSORT is one of the earliest to use deep visual features for object association.”
- 精读分析: 首先说明这个方法的思想非常直观——靠“看脸”来认人。然后介绍了这个流派的经典之作——DeepSORT。它就是在SORT的基础上,额外增加了一个深度学习模型,用来提取物体的外观特征(Re-ID特征),在匹配时同时考虑运动(IoU)和外观(特征相似度)。
第三句 & 第四句:
“Since then more methods have improved upon integrating visual information by training discriminative appearance models in an end-to-end manner. More recently, the rise of transformers has started another wave of using appearance for multi-object tracking, where the task of object association is modeled as a query matching problem.”
- 精读分析: 描述了DeepSORT之后的发展。一方面,出现了端到端训练的、能学习到更有区分度的外观特征的模型。另一方面,最新的浪潮是Transformer的应用。它将跟踪问题建模成一个“查询匹配问题”:将每个已存在的轨迹看作一个“查询(query)”,用这个查询去当前帧的所有检测结果中寻找最匹配的“键(key)”,这是一种更全局、更灵活的匹配方式。
第五句 & 第六句(转折与批判):
“However, appearance-based methods are observed to be less effective when the objects of interest have similar appearance or are occluded. Despite having more complicated architectures, these methods fail to outperform simple motion association algorithms that leverage strong detectors.”
- 精读分析: 这是本节最关键的部分,作者话锋一转,指出了纯外观方法的致命缺陷。
- 根本弱点: 当物体外观相似(如DanceTrack里的舞者)或被遮挡时,外观特征本身就不可靠了,这类方法自然会失效。
- 性能瓶颈: 作者一针见血地指出,尽管这些方法架构复杂(complicated architectures),但它们的最终性能,往往还比不过那些架构简单、但使用了强大检测器的运动跟踪算法。这与第一小节的开篇形成了完美的呼应和论证。
第七句(收尾与铺垫):
“Some recent attempts to add appearance cues to motion-based methods use simple moving averages for appearance embedding updates, achieving moderate success.”
- 精读分析: 在批判了纯外观方法后,作者又回到了“融合”的思路上来。他承认,已经有一些工作尝试将外观信息加入到运动模型中。但他对这些工作的评价是:
- 方法简单: 它们用的是“简单的移动平均”(simple moving averages)来更新外观特征。
- 效果有限: 只取得了“中等的成功”(moderate success)。
这就在读者心中建立了一个预期:既然现有融合方法简单且效果一般,那么一定有更好的、更智能的融合方法存在。这就为作者在下一章介绍自己“新颖的”、“自适应的”方法做好了完美的铺垫。
3. METHODS
引文内容分析:
“In this section, we describe the three modules of Deep OCSORT: Camera Motion Compensation (CMC), Dynamic Appearance (DA) and Adaptive Weighting (AW). The algorithm pipeline is illustrated in Figure 1.”
- 精读分析: 这段开场白非常直接,它告诉我们本章将详细介绍构成 Deep OC-SORT 的三个核心创新模块:
- CMC (Camera Motion Compensation): 相机运动补偿。
- DA (Dynamic Appearance): 动态外观。
- AW (Adaptive Weighting): 自适应加权。
- 同时,它指引我们参考图1,这张图是整个算法流程的可视化表示。因此,理解这张图是理解整个方法的关键。
图1:Deep OC-SORT 算法流程图精读
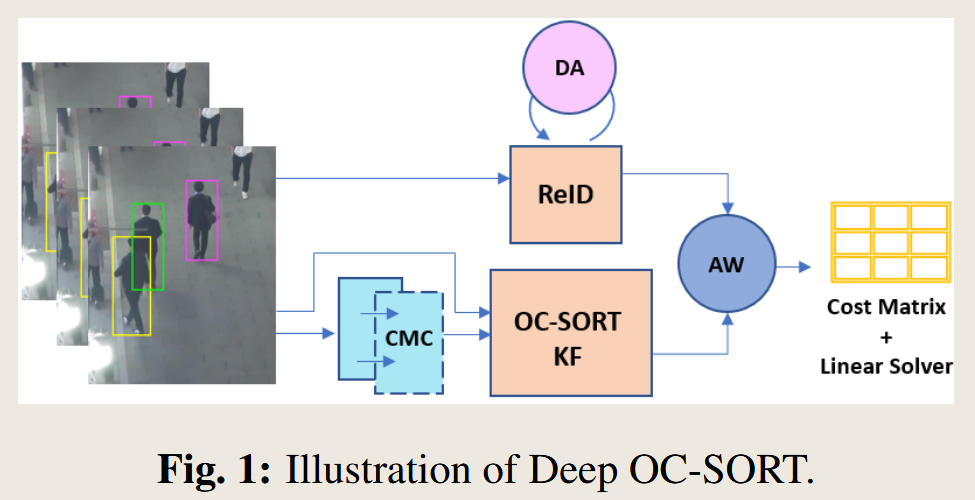
- 输入 (Input - 左侧图像序列):
- 流程的起点是连续的视频帧。在每一帧中,一个强大的物体检测器已经识别出了潜在的目标,并用边界框(Bounding Box)将它们框出(图中的黄、绿、品红框)。这些检测结果是算法需要处理的原始数据。
- 双分支处理 (Two-branch Processing):
- 从输入可以看出,数据流向了两个并行的分支,分别处理运动信息和外观信息。
- 分支一:运动模型 (Motion Branch - 下方通路)
- CMC (相机运动补偿): 首先,视频帧序列被送入CMC模块。这个模块的作用是估计相机自身的移动。
- OC-SORT KF (OC-SORT 卡尔曼滤波器): 经过CMC校正后的信息,被送入OC-SORT的核心——卡尔曼滤波器(KF)。KF会根据已有的轨迹(tracks)预测出每个物体在当前帧的理论位置。这个预测结果就是运动线索。
- 分支二:外观模型 (Appearance Branch - 上方通路)
- ReID (重识别模型): 同时,当前帧的检测框被送入一个ReID模型。这个模型的功能是为每个检测框提取一个高维度的特征向量(embedding),这个向量就代表了这个物体的“外观”。
- DA (动态外观): ReID模块上方有一个指向自己的循环箭头,并标注了DA。这形象地表示了“动态外观”模块的作用:它不是每次都用全新的外观特征,而是会根据历史特征和当前特征进行动态更新。这使得每个轨迹的外观表示更加稳定和鲁棒。ReID模型最终输出的是外观线索。
- 融合 (Fusion - 中间圆形AW模块):
- AW (自适应加权): 两个分支的输出——运动线索(来自OC-SORT KF)和外观线索(来自ReID)——汇集到了AW模块。这是整个系统的“决策中枢”。它不是简单地将两种线索相加,而是会自适应地决定在当前情况下,应该更相信运动模型还是外观模型,并为它们赋予不同的权重。例如,如果一个物体的外观特征非常独特,AW就会加大外观线索的权重。
- 输出与决策 (Output & Decision - 右侧):
- Cost Matrix (代价矩阵): AW模块的输出是一个代价矩阵。这个矩阵的行代表已有的轨迹,列代表当前帧的检测框。矩阵中的每个值 C(i, j) 代表将轨迹 i 和检测 j 匹配到一起的“代价”有多大(代价越小,代表越匹配)。
- Linear Solver (线性求解器): 最后,这个代价矩阵被送入一个线性求解器(如匈牙利算法)。求解器的任务是找到一个全局最优的分配方案,使得总代价最小。求解器的输出就是最终的匹配结果,从而完成了这一帧的跟踪。
3.1. Preliminary: OC-SORT
第一句 & 第二句:
“Our work is built upon the recent Kalman-filter-based tracking algorithm OC-SORT, which is an extension of SORT.”
- 精读分析: 这两句开宗明义,直接点明了技术传承关系。
- 基础: 我们的工作是建立在 OC-SORT 之上的。
- 定位OC-SORT: OC-SORT本身是基于卡尔曼滤波器的,并且它是经典算法 SORT 的一个“扩展”(extension)或“演进版”。
- 这就建立了一个清晰的技术链条:SORT -> OC-SORT -> Deep OC-SORT (本文工作)。
第三句 & 第四句:
“SORT relies on the linear motion assumption of object tracking and leverages the Kalman filter to associate predictions from an object detector with the position estimates from the motion model by IoU. When the video frame rate is high, the linear motion assumption can be effective for object displacement on adjacent video frames.”
- 精读分析: 这里简要回顾了 SORT 的工作原理及其适用场景。
- 核心原理: SORT 依赖于两个基本点:
- 线性运动假设 (linear motion assumption): 假设物体做匀速直线运动。
- IoU 匹配: 使用卡尔曼滤波器(motion model)预测物体下一帧的位置,然后计算这个预测框与真实检测框的交并比(IoU),IoU最高的则认为是匹配成功。
- 适用场景: 作者很客观地指出了这种简单方法的有效范围——当视频帧率很高时。因为帧间时间间隔极短,物体的位移很小,用线性运动来近似是可以接受的。
- 核心原理: SORT 依赖于两个基本点:
第五句(转折):
“However, when tracking targets disappear under occlusion, the missed measurements during Kalman filter updates compound error quadratically over time in the Kalman filter’s parameters.”
- 精读分析: 这是本节最关键的一句话,它指出了 SORT 乃至所有基于卡尔曼滤波器的跟踪方法的核心痛点。
- 问题场景: 当目标因为被**遮挡(occlusion)**而消失时,检测器就无法提供新的测量值(missed measurements)。
- 后果: 此时,卡尔曼滤波器只能依靠自己的模型来“盲猜”物体的位置。如果没有新的观测来校正,这种预测的误差会随着时间的推移以二次方级别累积(compound error quadratically)。这意味着,一个物体丢失的时间越长,卡尔曼滤波器对其位置的预测就会错得越离谱。当物体再次出现时,由于预测位置和真实位置相差太远(导致IoU为0),SORT就无法将其与原有的轨迹重新关联起来,从而导致跟踪失败(ID Switch)。
第六句:
“OC-SORT proposes three modules to help resolve the motion-model based error: OCM (observation-centric momentum), OCR (observation-centric recovery), and OOS (observation-centric online smoothing).”
-
精读分析: 这句话直接给出了 OC-SORT 针对上述问题的解决方案。OC-SORT 的核心思想是“以观测为中心 (Observation-Centric)”,它引入了三个专门的模块来修正由运动模型带来的误差:
- OCM (Observation-Centric Momentum - 观测中心动量): 这个模块修正了速度的估计,使其更多地依赖于近期的观测,而不是长期的模型预测。
- OCR (Observation-Centric Recovery - 观测中心恢复): 这是一个关键模块。当一个轨迹长时间丢失后,OC-SORT会认为其速度估计已经完全不可信。当它重新出现并匹配上时,OCR会利用这个新的观测来“重置”或“恢复”其运动状态,而不是继续使用那个充满错误的旧状态。
- OOS (Observation-Centric Online Smoothing - 观测中心在线平滑): 这个模块用于处理由于检测抖动等原因造成的轨迹漂移问题。
- 通过这三大模块,OC-SORT 极大地提升了在遮挡、非线性运动等复杂场景下的鲁棒性,因为它不再盲目信任已经“过时”的运动模型,而是更倾向于相信“眼见为实”的检测结果。
最后两句:
“We invite the reader to refer to its paper for details. We inherit the overall pipeline of OC-SORT, including the Hungarian algorithm to associate matches from a cost matrix.”
- 精读分析:
- 引导阅读: 作者在这里非常明智,没有浪费篇幅去复述 OC-SORT 的全部细节,而是直接建议感兴趣的读者去阅读原始论文。这保持了本文的焦点。
- 继承关系: 最后一句明确了继承的具体内容。他们继承了 OC-SORT 的整体流程(overall pipeline),这其中就包括了最终使用**代价矩阵(cost matrix)和匈牙利算法(Hungarian algorithm)**来完成匹配决策的步骤。这为后续章节介绍他们如何构建一个新的、融合了外观信息的代价矩阵做好了铺垫。
3.2. Camera Motion Compensation (CMC)
核心动机:为什么需要 CMC?
第一句话就点明了动机:
“As OC-SORT is highly dependent on the detection quality, we introduce CMC to more accurately localize objects from frame to frame in moving scenes.”
- 精读分析:
- OC-SORT的弱点: 作者坦言,OC-SORT 作为一个“以观测为中心”的算法,它非常依赖于检测的质量。这意味着检测框的位置必须尽可能准确。
- 问题场景: 在“移动场景 (moving scenes)”中,即相机本身在移动(如平移、旋转、缩放),物体在图像上的位置变化是它自身运动和相机运动的叠加。如果不加区分,OC-SORT 的运动模型就会被相机的运动所“欺骗”,导致对物体位置的预测出现巨大偏差,从而影响跟踪的准确性。
- CMC的目标: 因此,引入 CMC 的目的就是为了在算法层面“抵消”掉相机的运动,从而更准确地定位 (localize) 物体,让运动模型只专注于物体自身的真实运动。
核心思想:如何实现 CMC?
“Given a scaled rotation matrix Mt = stRt and a translation Tt where Mt ∈ R2×2 and Tt ∈ R2×1, we apply them to OC-SORT’s three components respectively:”
- 精读分析:
- 数学工具: 作者使用了一个2D仿射变换来对相机的运动进行建模。这个变换由两部分组成:
- Mt: 一个 2x2 的矩阵,它包含了旋转 (Rotation Rt) 和缩放 (scale st) 的信息。
- Tt: 一个 2x1 的向量,它代表了平移 (Translation) 的信息。
- 实现方式: 通过一些计算机视觉技术(如光流法、特征点匹配等,论文在4.2节提到使用OpenCV的VidStab模块),可以估计出从前一帧到当前帧的 Mt 和 Tt。
- 应用目标: 得到这个变换之后,作者将其分别应用到 OC-SORT 的三个关键模块(OOS, OCM, OCR)以及卡尔曼滤波器的核心状态上。
- 数学工具: 作者使用了一个2D仿射变换来对相机的运动进行建模。这个变换由两部分组成:
具体实现:CMC 如何作用于 OC-SORT?
作者将应用分成了四个部分来讲解:
1. OOS + CMC (在线平滑的补偿):
- 原文大意: OOS模块通过在“最后一次已知测量值”处进行线性插值来更新卡尔曼滤波器。CMC的作用就是先对这个“最后一次已知测量值”的中心点 c 进行坐标变换 (c ← Mt*c + Tt),然后再进行插值。
- 精读解读: OOS 的作用是平滑轨迹。它的起点是物体最后一次被观测到的位置。如果相机移动了,这个起点在新的坐标系下就已经不准了。CMC 先把这个起点校正到“如果相机没动,它现在应该在的位置”,然后再进行平滑。这从源头上保证了轨迹平滑的准确性。
2. OCM + CMC (动量估计的补偿):
- 原文大意: OCM模块使用过去3个边界框来计算角速度。CMC对这些历史边界框的角点 pi 进行变换 (pi ← Mt*pi + Tt)。
- 精读解读: OCM 用来估计物体的旋转。如果相机自身发生了旋转,那么屏幕上所有物体的边界框都会跟着旋转,这会产生一个虚假的“角速度”。CMC通过对过去用于计算的边界框进行“反向”变换,消除了相机旋转带来的影响,从而计算出物体自身真实的角速度。
3. OCR + CMC (恢复机制的补偿):
- 原文大意: OCR模块在处理一个长期未被观测的物体时,会参考其“最后一次可见的边界框位置”。CMC在每一帧都对这个历史位置进行变换 (pi ← Mt*pi + Tt) 来更新它。
- 精读解读: 这是至关重要的一步。一个物体丢失了10帧,相机在这10帧内持续移动。如果不做补偿,它“最后可见的位置”在当前帧看来就是一个完全错误的位置。CMC的作用就像一个“GPS修正器”,不断告诉算法:“虽然那个物体10帧前在A点,但考虑到我(相机)的移动,它现在应该约等于在B点”。这极大地提高了找回丢失目标(Re-ID)的成功率。
4. 直接修正卡尔曼滤波器状态 (Equation 1):
- 这是最核心的数学部分,直接对卡尔曼滤波器的状态向量 x 和协方差矩阵 P 进行修正。
- x[0 : 2] ← Mtx[0 : 2] + Tt:
- x[0:2] 是状态向量中的中心点坐标 [xc, yc]。这行代码对中心点应用了完整的仿射变换,校正其位置。
- x[4 : 6] ← Mtx[4 : 6]:
- x[4:6] 是状态向量中的速度 [ẋc, ẏc]。注意:这里只乘以了 Mt,没有加 Tt! 这是因为相机的平移(translation)改变了物体的位置,但不直接改变其速度。而相机的旋转/缩放(rotation/scale)则会改变物体速度向量的方向和大小,所以需要用 Mt 来旋转/缩放速度向量。
- P[0 : 2, 0 : 2] ← Mt*P[0 : 2, 0 : 2]Mt^T 和 P[4 : 6, 4 : 6] ← MtP[4 : 6, 4 : 6]*Mt^T:
- P 是协方差矩阵,代表了对状态估计不确定性的度量。根据线性代数,当你用一个矩阵 M 变换一个随机变量 x 时,它的协方差矩阵 P 会变成 MPM^T。这里正是对位置和速度的不确定性进行了正确的、符合数学原理的传播。
3.3. Dynamic Appearance
问题背景:传统的EMA方法及其缺陷
“In previous work, the deep visual embedding used to describe a tracklet is given by an Exponential Moving Average (EMA)… This requires a weighting factor α to adjust the ratio of the visual embedding from historical and current time steps.”
- 精读分析: 作者首先介绍了“先前工作”中通用的做法——指数移动平均 (EMA)。
- 公式 (2) et = α*et−1 + (1 − α)*enew 非常清晰地解释了EMA:
- et: 轨迹在当前帧 t 的新外观特征。
- et−1: 轨迹在上一帧 t-1 的旧外观特征(历史信息)。
- enew: 当前帧新匹配上的检测框的外观特征(新观测)。
- α: 一个固定的权重因子,通常是一个接近1的常数(比如0.9)。
- EMA的缺陷:
这种方法的核心缺陷在于 α 是一个常数。这意味着,无论新匹配上的检测框 enew 的质量如何(是非常清晰,还是因遮挡、模糊而质量很差),它在更新历史特征时所占的比重 (1 - α) 都是固定不变的。
这就导致了一个严重问题:如果一个高质量的轨迹,匹配上了一个低质量的“脏”特征,这个“脏”特征依然会以固定的权重污染掉原有的好特征,导致轨迹的“相貌”逐渐变得模糊不清,在后续的匹配中更容易出错。
核心思想:让权重 α “动”起来
“We propose to modify the α of the EMA on a per-frame basis, depending on the detector confidence. This flexible α allows selectively incorporating appearance information into a track’s model only in high-quality situations.”
- 精读分析: 这就是作者提出的解决方案——动态外观(DA)。
- 核心创新: 不再使用固定的 α,而是让 α 在每一帧都变成一个动态变化的 αt。
- “动”的依据: αt 的值取决于检测器的置信度 sdet。
- 基本逻辑: 作者做了一个非常合理且巧妙的假设——检测置信度可以作为外观特征质量的代理指标 (proxy)。一个高置信度的检测,通常意味着物体清晰、无遮挡,其外观特征质量就好;反之,低置信度检测则可能对应着遮挡、模糊等情况,其特征质量就差。
- 最终目的: 通过这个灵活的 αt,算法可以智能地做到:只在高质量的情况下(即高置信度时)才将新的外观信息融入模型,而在低质量情况下则拒绝或减少其影响,从而避免“污染”。
具体实现:动态 αt 的数学公式
作者提出了公式 (3) 来计算动态的 αt:
αt = αf + (1 − αf) * (1 − (sdet − σ) / (1 − σ))
- 精读分析: 我们来拆解这个公式的各个部分:
- sdet (Detector Confidence): 检测器给出的置信度分数,是这个公式的核心输入。
- σ (Confidence Threshold): 一个预设的置信度阈值。在常规操作中,置信度低于 σ 的检测框会被直接丢弃。所以,sdet 的有效范围是 [σ, 1]。
- αf (Fixed Alpha): 作者设置的一个固定的基准权重,αf = 0.95。可以理解为在最理想情况下,历史信息所占的最小权重。
- (sdet − σ) / (1 − σ): 这是一个归一化操作。它将 [σ, 1] 区间内的 sdet 线性地映射到 [0, 1] 区间。
- 当 sdet = σ (最低可用置信度)时,该项为 0。
- 当 sdet = 1 (最高置信度)时,该项为 1。
- 分析公式行为:
- 当 sdet = 1 (质量最高时):
αt = αf + (1 - αf) * (1 - 1) = αf。此时 αt 取最小值 αf = 0.95。更新公式变为 et = 0.95et-1 + 0.05enew。新特征 enew 获得了最大的更新权重 (0.05)。 - 当 sdet = σ (质量最低时):
αt = αf + (1 - αf) * (1 - 0) = αf + 1 - αf = 1。此时 αt 取最大值 1。更新公式变为 et = 1et-1 + 0enew。新特征 enew 的权重为0,它被完全忽略,历史特征被完整保留。
- 当 sdet = 1 (质量最高时):
- 结论: αt 的值与 sdet 负相关。检测置信度越高,αt 越小(接近αf),新特征的发言权越大;置信度越低,αt 越大(接近1),历史特征的发言权越大。
3.4. Adaptive Weighting
好的,我们来精读 3.4 节 自适应加权 (Adaptive Weighting - AW)。这是 Deep OC-SORT 的第三个,也是最精巧的一个核心创新模块。
前面两个模块 CMC 和 DA 分别优化了运动输入和外观特征本身。而 AW 模块则聚焦于最终的决策环节:如何将运动代价(IoU)和外观代价(Ac)更智能地融合起来,以生成最终的代价矩阵 C?
问题背景:传统融合方法的局限性
“This is typically combined with the IoU cost matrix Ic as C = Ic + aw*Ac, with a linear sum assignment minimizing cost over -C.”
- 精读分析: 作者首先介绍了传统(典型)的融合方式。
- Ic: 基于 IoU 的代价矩阵(通常是 1 - IoU)。
- Ac: 基于外观相似度(如余弦相似度)的代价矩阵。
- aw: 一个全局的、固定的权重因子,用来平衡运动和外观的重要性。例如 aw=0.3。
- C = Ic + aw*Ac: 最终的代价矩阵是两者的加权和。
- 局限性: 这种方法的核心缺陷在于 aw 是一个全局常数。它意味着,对于所有的轨迹-检测对,外观信息所占的比重都是一样的。这显然是不合理的。
- 一个反例: 假设场景中有两个人,A 穿着鲜艳的红色外套,特征非常独特;B 穿着大众化的黑色T恤,特征非常普通。当匹配A时,我们应该更相信他的外观特征;而匹配B时,他的外观特征很容易和别人混淆,我们应该更相信他的运动轨迹。使用一个固定的 aw 无法体现这种差异。
核心思想:让权重 aw 也“动”起来
“Our Adaptive Weighting increases the weight of appearance features depending on the discriminativeness of appearance embeddings.”
- 精读分析: 这句话点明了 AW 模块的核心思想。
- 核心创新: 我们要根据**外观嵌入的“区分度”(discriminativeness)**来动态调整外观特征的权重。
- 基本逻辑:
- 如果一个轨迹的外观,与某个检测框的外观非常匹配,同时与其他所有检测框的外观都非常不匹配,那么我们就说这次匹配的“区分度”很高,我们就应该给这次匹配的外观得分一个更高的权重。
- 反之,如果一个轨迹的外观,与好几个检测框的外观都差不多,区分不出来,那么这次匹配的“区分度”就很低,我们就应该降低其外观得分的权重,更多地依赖运动(IoU)来做决策。
具体实现:自适应权重 wb(m, n) 的计算
作者没有直接修改全局的 aw,而是为每一个代价矩阵的元素 C[m, n] 增加了一个局部的、特定的权重增量 wb(m, n)。
Step 1: 衡量“区分度” zdiff (公式 4)
- ztrack_diff(Ac, m): 衡量轨迹 m 的区分度。
- max Ac[m, i]: 轨迹 m 与所有检测框匹配的最高分。
- max Ac[m, j] (j≠i): 轨迹 m 与所有检测框匹配的次高分。
- 它计算的是最高分和次高分之间的差值。这个差值越大,说明轨迹 m 对最佳匹配目标 i 的指向性越明确。
- zdet_diff(Ac, n): 衡量检测 n 的区分度。
- 它计算的是从检测框 n 的角度看,与它最匹配的轨迹和次匹配的轨迹之间的分数差异。
- min(…, ε): 这里用 ε (epsilon) 对这个差值做了一个封顶 (cap)。这是为了防止当最高分和次高分差距过大时,权重增长得没有限制,导致系统不稳定。ε 成为了一个控制权重增长上限的超参数。
Step 2: 计算局部权重增量 wb(m, n) (公式 5)
- wb(m, n) = [ztrack_diff(Ac, m) + zdet_diff(Ac, n)] / 2
- 精读分析: 最终的权重增量 wb(m, n) 是轨迹 m 的区分度和检测 n 的区分度的平均值。这意味着,只有当双向的区分度都高时(即轨迹 m “认定”了检测 n,同时检测 n 也“认定”了轨迹 m),这个权重增量 wb(m, n) 才会比较大。这是一个非常鲁棒的设计。
Step 3: 构建最终的代价矩阵 C (公式 6)
- C[m, n] = IoU[m, n] + [aw + wb(m, n)] * Ac[m, n]
- 注意:论文原文公式为 C[m, n] = IoU[m, n] + [aw + wb(m, n)] Ac[m, n],这里为了清晰,我把乘号写出来了。原文中 IoU[m,n] 可能代表的是代价 1-IoU。
- 精读分析: 这就是最终的融合公式。
- 外观矩阵 Ac[m, n] 的权重不再是固定的 aw,而是变成了一个动态的 [aw + wb(m, n)]。
- 对于那些具有高区分度的匹配对 (m, n),它们的 wb 值会很大,从而使得外观代价 Ac 在最终决策中占据主导地位。
- 对于那些模糊不清的匹配对,它们的 wb 值会很小(甚至为0),最终的权重就退化为全局的 aw,更多地依赖 IoU 来判断。
方法论的讨论
“We choose to measure the discriminativeness based on only the first and second-highest scores rather than probability distribution metrics like KL divergence, as the spread of values between lower-scoring matches are irrelevant. A true positive appearance match is indicated by one high score having a large distance from the next best match.”
- 精读分析: 这段话解释了作者为什么选择用“最高分-次高分”这种简单的方式来衡量区分度,而不是用更复杂的概率分布度量(如KL散度)。
- 理由: 作者认为,在匹配任务中,我们真正关心的只是“最佳匹配是否足够突出”。至于排在第三、第四、第五的匹配得分是多少,它们的分布如何,其实是“无关紧要的 (irrelevant)”。
- 核心洞察: “一个真正的正向外观匹配,其特征就是一个很高的得分,并且这个得分与下一个最佳匹配的得分有很大的距离。” 这句话精准地概括了该模块设计的核心直觉。
- 这种设计选择体现了奥卡姆剃刀原理——如无必要,勿增实体。用最简单有效的方式解决问题,而不是盲目追求模型的复杂性。