云原生环境 Prometheus 企业级监控实战
目录
一:基于kubernetes的Prometheus 介绍
1:环境简介
2:监控流程
3:Kubernetes 监控指标
二:Prometheus 的安装
1:从 Github 克隆项目分支
2:安装Prometheus Operator
3:0perator 容器启动起来后安装Prometheus stack
4:查看Prometheus 容器的状态
5:查看servicemonitors
6:修改grafana的service的类型为 NodePort
7:访问grafana
8:修改Prometheus 的Service 类型
9:访问Prometheus
10:查看监控目标
三:配置 Grafana Dashbord
1:添加数据源
(1)添加数据源
(2)数据源选择 Prometheus
(3)配置数据源
2:通过 Node id 导入监控模板
四:监控 MySQL 数据库
五:对接钉钉报警
一:基于kubernetes的Prometheus 介绍
1:环境简介
node-exporter + prometheus + grafana是一套非常流行的 Kubernetes 监控方案。它们的功能如下:
node-exporter:节点级指标导出工具,可以监控节点的 CPU、内存、磁盘、网络等指标,并暴露 Metrics 接口。
Prometheus:时间序列数据库和监控报警工具,可以抓取 Cadvisor 和 node-exporter 暴露的Metrics 接口,存储时序数据,并提供 PromQL 查询语言进行监控分析和报警。
Grafana:图表和 Dashboard 工具,可以査询 Prometheus 中的数据,并通过图表的方式直观展示Kubernetes 集群的运行指标和状态。
2:监控流程
| 组件/步骤 | 功能描述 | 部署方式 | 配置要点 | 相关指标示例 |
|---|---|---|---|---|
| 1. Node-exporter | 采集节点级硬件和系统指标(CPU、内存、磁盘、网络等) | DaemonSet(确保每个节点运行一个实例) | - 暴露端口:9100 - 数据路径: /metrics- 资源限制:建议0.5核/512MB内存 | node_cpu_seconds_totalnode_memory_MemAvailable_bytesnode_disk_io_time_seconds_total |
| 2. Cadvisor | 采集容器级资源使用指标(CPU、内存、文件系统、网络等) | 通常内置于Kubelet(默认启用) | - 数据端口:4194(旧版)或通过Kubelet的10255端口 - 数据路径: /metrics/cadvisor | container_cpu_usage_seconds_totalcontainer_memory_working_set_bytescontainer_network_receive_bytes_total |
| 3. Prometheus | 抓取、存储和告警时序数据 | 推荐使用Prometheus Operator部署 | - 配置ServiceMonitor自动发现监控目标- 存储卷配置(PV/PVC) - 告警规则文件: prometheus-rules.yaml | 通过PromQL查询如:sum(rate(container_cpu_usage_seconds_total[1m])) by (pod) |
| 4. Grafana | 可视化监控数据,提供仪表盘 | 推荐使用Grafana Operator或Deployment | - 数据源配置:Prometheus URL - 仪表盘JSON导入(如ID:315或自定义) - 持久化存储配置 | 常用仪表盘: - Kubernetes Cluster - Node Exporter Full - Pod Monitor |
| 5. Alertmanager | 接收Prometheus的告警并路由发送(邮件、Slack等) | 与Prometheus配套部署 | - 告警分组/抑制规则 - 接收器配置(如SMTP、Webhook) - 静默规则 | 告警规则示例:- alert: HighCPUUsage expr: node_cpu_usage > 90% for 5m |
| 配置项 | 示例/说明 |
|---|---|
| Prometheus抓取配置 | yaml<br>scrape_configs:<br> - job_name: 'node-exporter'<br> static_configs:<br> - targets: ['node-exporter:9100']<br> |
| ServiceMonitor示例 | yaml<br>apiVersion: monitoring.coreos.com/v1<br>kind: ServiceMonitor<br>metadata:<br> name: node-exporter<br>spec:<br> endpoints:<br> - port: web<br> selector:<br> matchLabels:<br> app: node-exporter |
| Grafana数据源 | 类型:Prometheus URL: http://prometheus-operated:9090 |
| 核心监控指标 | - 节点资源:node:node_cpu_utilisation:avg1m- Pod资源: sum(rate(container_cpu_usage_seconds_total[1m])) by (pod) |
3:Kubernetes 监控指标
K8S 本身的监控指标:
| 指标类型 | 具体指标示例 | 采集来源 | PromQL查询示例 | 应用场景 |
|---|---|---|---|---|
| CPU利用率 | - 节点CPU使用率 - Pod/容器CPU使用率 - CPU限用率(Throttling) | Node-exporter Cadvisor | node_cpu_seconds_total{mode="user"}sum(rate(container_cpu_usage_seconds_total[1m])) by (pod) | 资源调度优化 防止CPU过载 |
| 内存利用率 | - 节点内存可用量 - Pod/容器内存使用量 - OOM事件计数 | Node-exporter Cadvisor | node_memory_MemAvailable_bytescontainer_memory_working_set_bytes{pod="my-pod"} | 内存泄漏检测 资源配额管理 |
| 网络流量 | - 节点网络流入/流出 - Pod网络接收/发送字节数 | Node-exporter Cadvisor | rate(node_network_receive_bytes_total[1m])sum(rate(container_network_receive_bytes_total[1m])) by (pod) | 带宽瓶颈分析 网络异常监控 |
| 磁盘使用率 | - 节点磁盘剩余空间 - 磁盘IOPS - 容器写入字节数 | Node-exporter Cadvisor | node_filesystem_avail_bytes{mountpoint="/"}rate(container_fs_writes_bytes_total[5m]) | 存储扩容预警 IO性能优化 |
| Pod状态 | - Running/Pending/Failed Pod数量 - 容器重启次数 | Kube-state-metrics | kube_pod_status_phase{phase="Running"}kube_pod_container_status_restarts_total | 应用健康检查 异常Pod自动恢复 |
| 节点状态 | - Ready/NotReady节点数 - 节点资源分配率(CPU/内存) | Kube-state-metrics Node-exporter | kube_node_status_condition{condition="Ready"}(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes | 节点故障检测 集群扩缩容决策 |
| API服务指标 | - API请求延迟(分位数) - 5xx错误率 - 请求QPS | Kubernetes API Server | apiserver_request_duration_seconds_bucketrate(apiserver_request_total{code=~"5.."}[5m]) | API性能调优 权限滥用监控 |
| 集群组件指标 | - etcd写入延迟 - kubelet运行时错误 - kube-proxy丢包数 | 各组件内置Metrics接口 | histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket[5m]))kubelet_http_requests_total{code="500"} | 核心组件稳定性保障 集群故障根因分析 |
| 指标组 | 核心监控目标 | 告警阈值建议 |
|---|---|---|
| CPU/内存 | 避免资源耗尽导致Pod驱逐或节点宕机 | CPU > 80%持续5分钟 内存 > 90% |
| Pod状态 | 快速发现崩溃或频繁重启的Pod | 重启次数 > 3次/小时 |
| API Server | 确保集群控制平面响应及时 | P99延迟 > 1s 5xx错误率 > 1% |
| etcd | 保障分布式存储性能与一致性 | 写入延迟 > 500ms 存储空间 > 80% |
数据来源工具对比
-
Node-exporter:仅节点级指标(无K8S对象数据)。
-
Cadvisor:容器级资源指标(集成在Kubelet中)。
-
Kube-state-metrics:K8S对象状态(如Pod/Node/Deployment)。
-
组件Metrics:需单独配置(如etcd的
--metrics=extended)。
这些都是 Kubernetes集群运行状态的关键指标,通过Prometheus 等工具可以进行收集和存储,然后 在 Grafana 中设计相应的 Dashboard 进行可视化展示。当这些指标超出正常范围时,也可以根据阌值设置报警,保证 Kubernetes 集群和服务的稳定运行。
例如:
CPU 利用率超过 80%报警
内存利用率超过 90%报警
网络流量/磁盘空间突增报警
Pod/节点 NotReady 状态超过 18%报警
API Server 请求 LATENCY 超过 200ms 报警
etcd 节点 Down 报警等等。
这些报警规则的设置需要根据集群大小和服务负载进行评估。
二:Prometheus 的安装
1:从 Github 克隆项目分支
[root@k8s-master ~]#git clone -b \
release-0.10 https://github.com/prometheus-operator/kube-prometheus.git2:安装Prometheus Operator
Prometheus operator 是 core0s 开源的项目,它提供了一种 Kubernetes-native 的方式来运行和管理 Prometheus。Prometheus operator 可以自动创建、配置和管理 Prometheus 实例,并将其与Kubernetes 中的服务发现机制集成在一起,从而实现对 Kubernetes 集群的自动监控。
| 对比项 | Prometheus | Prometheus Operator |
|---|---|---|
| 定义 | 开源的监控系统,用于采集、存储和查询时序数据,支持告警。 | Kubernetes 的 Operator,用于自动化管理 Prometheus 及其相关组件(如 Alertmanager、Grafana)。 |
| 核心功能 | - 指标采集(Scrape) - 数据存储(TSDB) - 查询(PromQL) - 告警(Alertmanager) | - 自动化部署 Prometheus 实例 - 动态配置监控目标(ServiceMonitor/PodMonitor) - 管理 Prometheus 高可用 |
| 部署方式 | 需手动编写配置文件(prometheus.yml)并部署到 Kubernetes 或物理机/虚拟机。 | 通过 Kubernetes CRD(自定义资源)声明式管理,例如:kubectl apply -f prometheus-crd.yaml |
| 服务发现 | 需手动配置 scrape_configs 或依赖第三方工具(如 Consul)。 | 自动集成 Kubernetes 服务发现,通过 ServiceMonitor 或 PodMonitor 动态识别监控目标。 |
| 配置管理 | 修改配置后需重启 Prometheus 服务。 | 通过 Operator 监听 CRD 变更,动态更新配置,无需重启。 |
| 适用场景 | - 非 Kubernetes 环境 - 需要高度定制化监控的场景 | - Kubernetes 集群 - 需要快速部署和自动化管理的场景 |
| 扩展性 | 依赖手动扩展(如分片、联邦集群)。 | 支持多租户、多实例管理,通过 CRD 轻松扩展(如 Prometheus 和 ThanosRuler 资源)。 |
| 维护成本 | 较高(需手动处理配置、版本升级等)。 | 较低(Operator 自动处理生命周期管理)。 |
| 典型工具链 | 需单独部署 Alertmanager、Grafana 等组件。 | 集成全套监控栈(Prometheus + Alertmanager + Grafana),例如通过 kube-prometheus 项目一键部署。 |
安装方法如下:
![]()

1. --server-side 参数说明
| 项目 | 说明 |
|---|---|
| 作用 | 将 kubectl apply 的逻辑从客户端转移到 kube-apiserver,由服务端直接处理资源配置。 |
| 解决的问题 | - 所有权冲突(例如多用户同时修改资源) - 客户端计算的差异(如字段合并策略不一致)。 |
| 使用场景 | 大规模集群或需要严格避免资源冲突的场景。 |
| 命令示例 | kubectl apply --server-side -f manifest.yaml |
| 注意事项 | - 需 Kubernetes 1.16+ - 可能不兼容部分旧版 kubectl 行为。 |
2. Prometheus Operator 删除操作
| 项目 | 说明 |
|---|---|
| 删除命令 | kubectl delete --ignore-not-found=true -f manifests/setup |
| 作用 | 清理 Prometheus Operator 安装的 CRD 和命名空间等资源,--ignore-not-found 避免未找到资源时报错。 |
| 补充说明 | 需先删除 manifests/ 下的资源,再删除 manifests/setup/,否则可能残留 CRD 依赖的实例。 |
| 完整卸载流程 | bash<br>kubectl delete -f manifests/<br>kubectl delete -f manifests/setup/<br> |
3. Prometheus Operator 核心功能
| 项目 | 说明 |
|---|---|
| 主要职责 | - 自动创建和管理 Prometheus/Alertmanager 实例 - 监听 CRD(如 ServiceMonitor)动态配置监控目标。 |
| 优势 | 无需手动编辑 prometheus.yml,通过 Kubernetes 原生 API 实现声明式监控管理。 |
| 管理对象 | Prometheus、Alertmanager、ThanosRuler、ServiceMonitor、PodMonitor 等 CRD。 |
对比总结
| 特性 | --server-side 参数 | Prometheus Operator |
|---|---|---|
| 适用对象 | 所有 kubectl apply 操作 | 仅针对 Prometheus 生态组件 |
| 核心价值 | 解决资源冲突,提升配置一致性 | 自动化管理 Prometheus 及其监控目标 |
| Kubernetes 版本要求 | 1.16+ | 无特殊要求(依赖 CRD 功能) |
3:0perator 容器启动起来后安装Prometheus stack
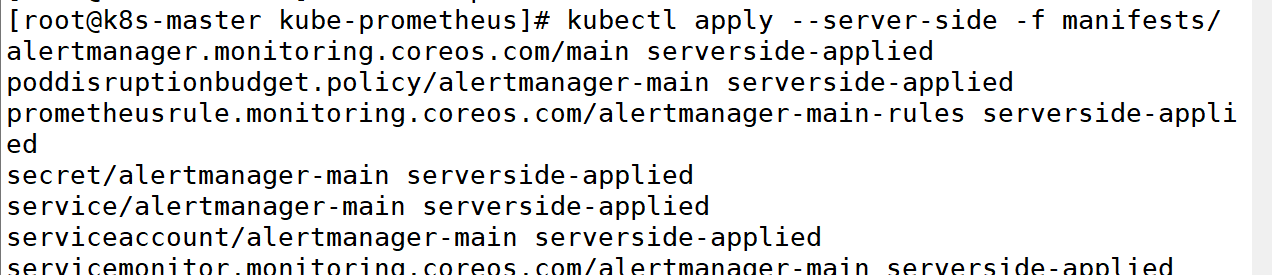
备注:
删除Prometheus stack
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
备注:
kube-prometheus-stack 是一个全家桶,提供监控告警组件alert-manager、grafana 等子组件。
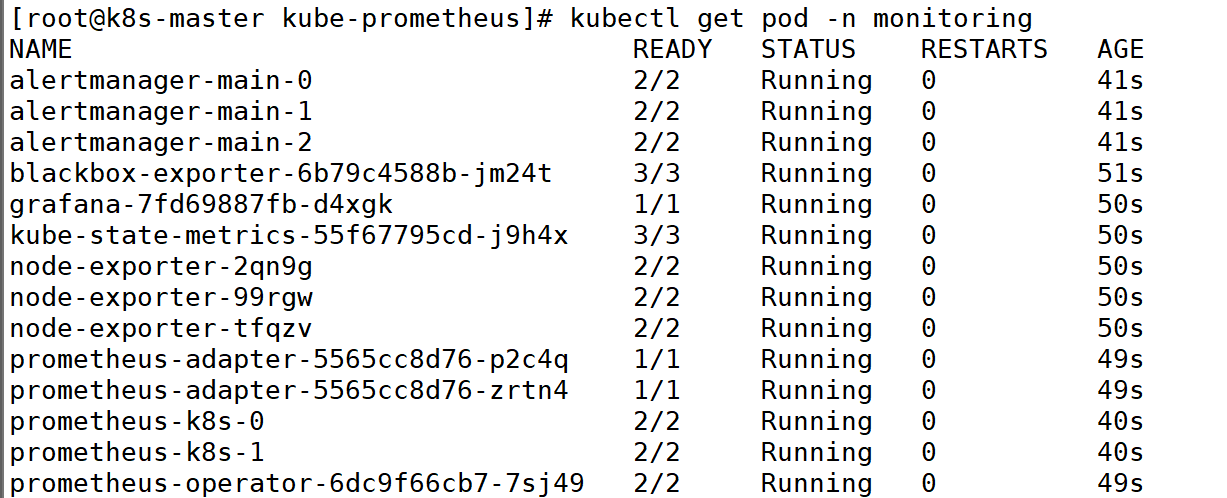
4:查看Prometheus 容器的状态
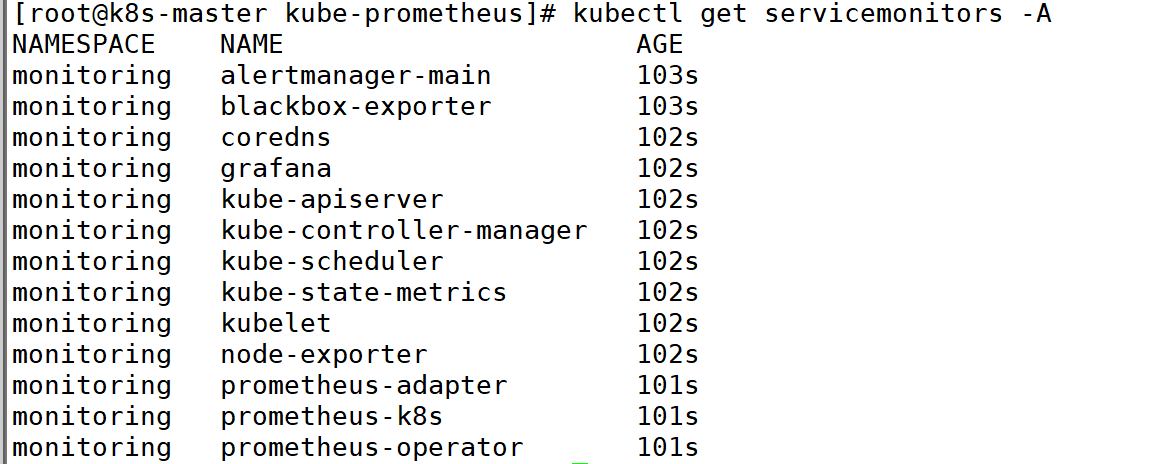
5:查看servicemonitors
servicemonitors 定义了如何监控一组动态的服务,使用标签选择来定义哪些 Service 被选择进行监控。这可以让团队制定一个如何暴露监控指标的规范,然后按照这些规范自动发现新的服务,而无需重新配置。
为了让 Prometheus 监控 Kubernetes 内的任何应用,需要存在一个 Endpoints 对象,Endpoints对象本质上是 IP 地址的列表,通常 Endpoints 对象是由 Service 对象来自动填充的,Service 对象通过标签选择器匹配 Pod,并将其添加到 Endpoints 对象中。一个 Service 可以暴露一个或多个端口,这些端口由多个 Endpoints 列表支持,这些端点一般情况下都是指向一个 Pod。
Prometheus Operator 引入的这个 ServiceMonitor 对象就会发现这些 Endpoints 对象,并配置 Prometheus 监控这些 Pod.ServiceMonitorspec的endpoints部分就是用于配置这些 Endpoints的哪些端口将被 scrape 指标的。
Prometheus Operator 使用 ServiceMonitor 管理监控配置。
ServiceMonitor 的创建方法如下:
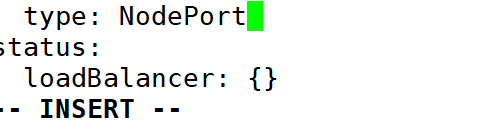
6:修改grafana的service的类型为 NodePort
注意:默认的type为ClusterIp 的类型



7:访问grafana
http://<K8s 集群任意节点的 IP>:32082
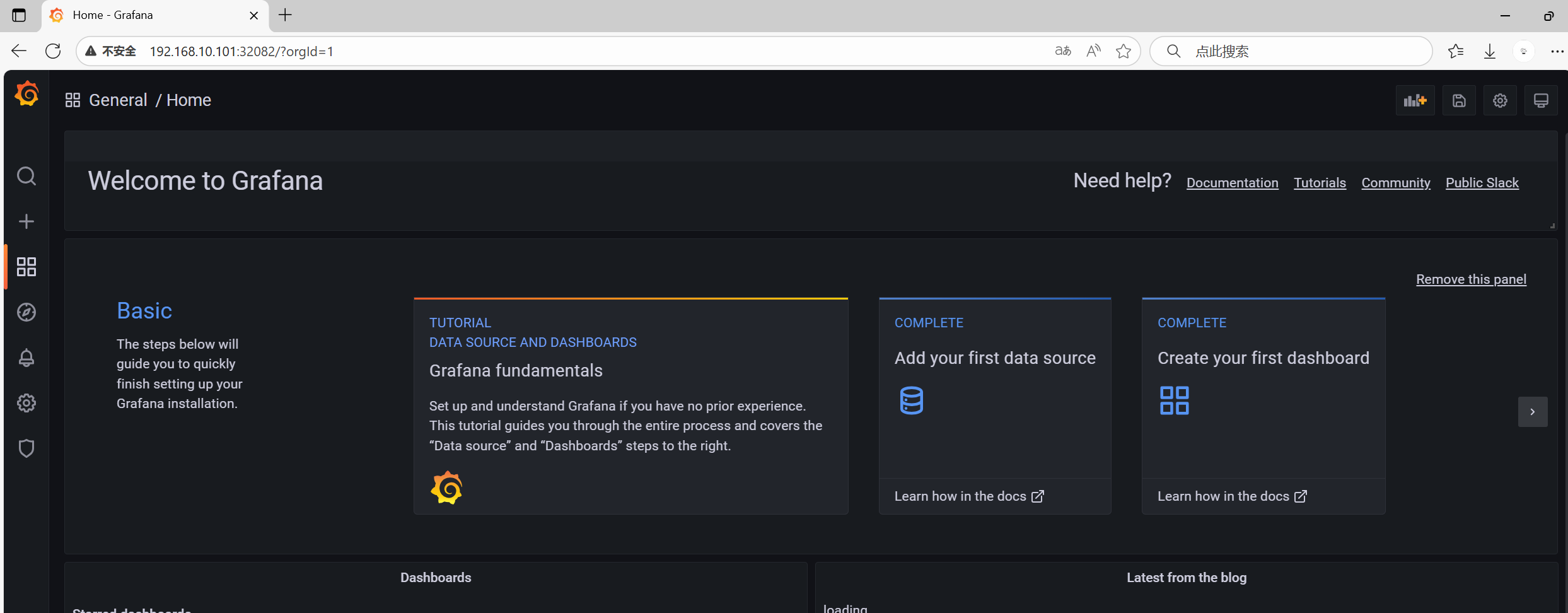
注意:
默认的登录账号密码为 admin/admin,第一次登陆会提示修改密码,不想修改可以点击 skip 跳过
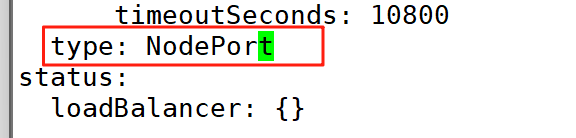
8:修改Prometheus 的Service 类型
将 type 类型修改为 NodePort,默认的是 ClusterIP



9:访问Prometheus
http://<K8s 集群任意节点的 IP>:32370
10:查看监控目标
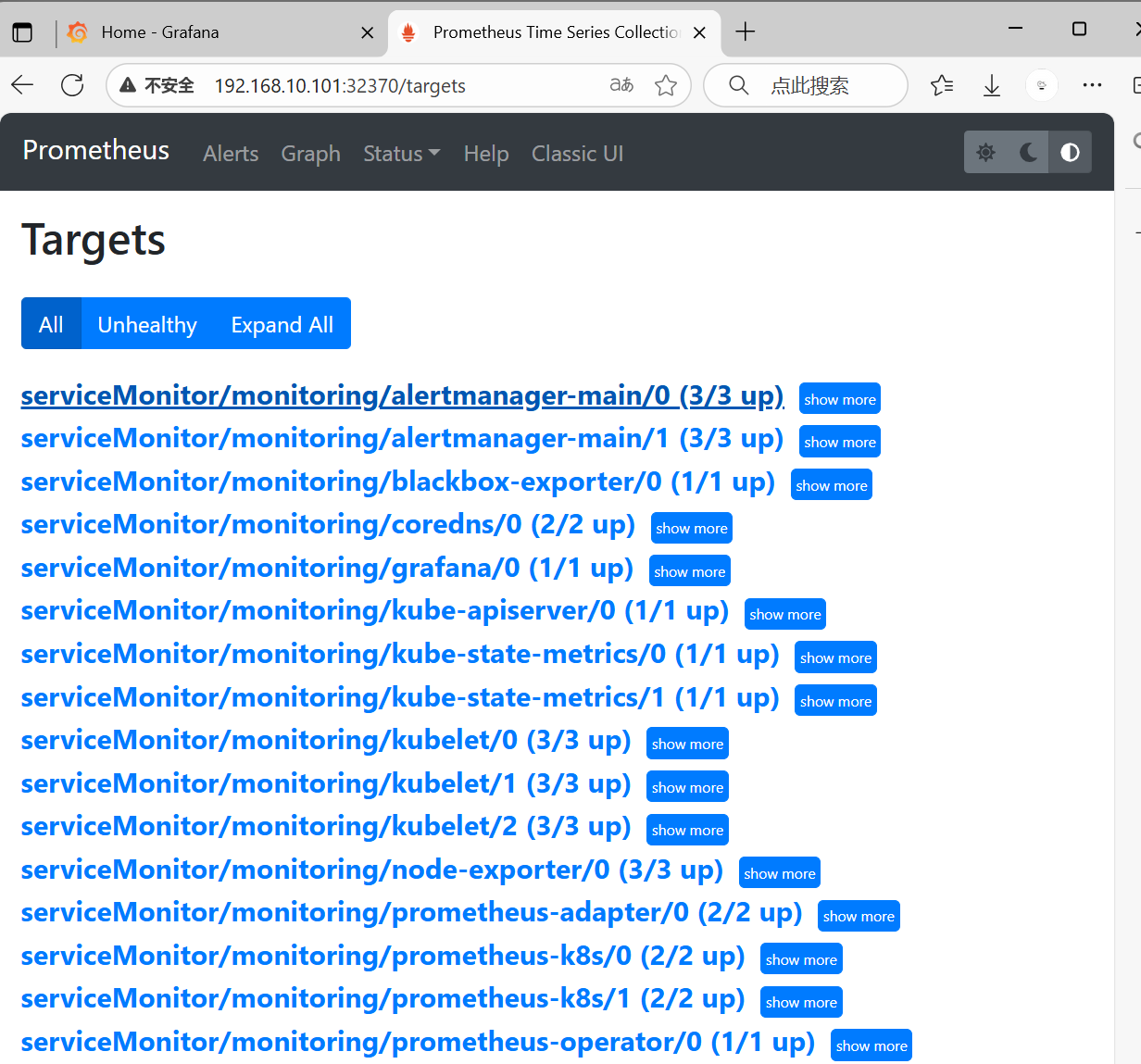
备注:
在 Prometheus 中一条告警规则有三个状态:
inactive:还未被触发;
pending:已经触发,但是还未达到for 设定的时间;
firing:触发且达到设定时间。
三:配置 Grafana Dashbord
1:添加数据源
注意:在本案例中,grafana已经有了Prometheus 的数据源,(1)(2)(3)步骤可以省去
(1)添加数据源
单击 Dashboards 按钮(四方块图标),选择“Add your first data source”
(2)数据源选择 Prometheus
鼠标放到 Prometheus 上,选择最右侧的“Select”按钮

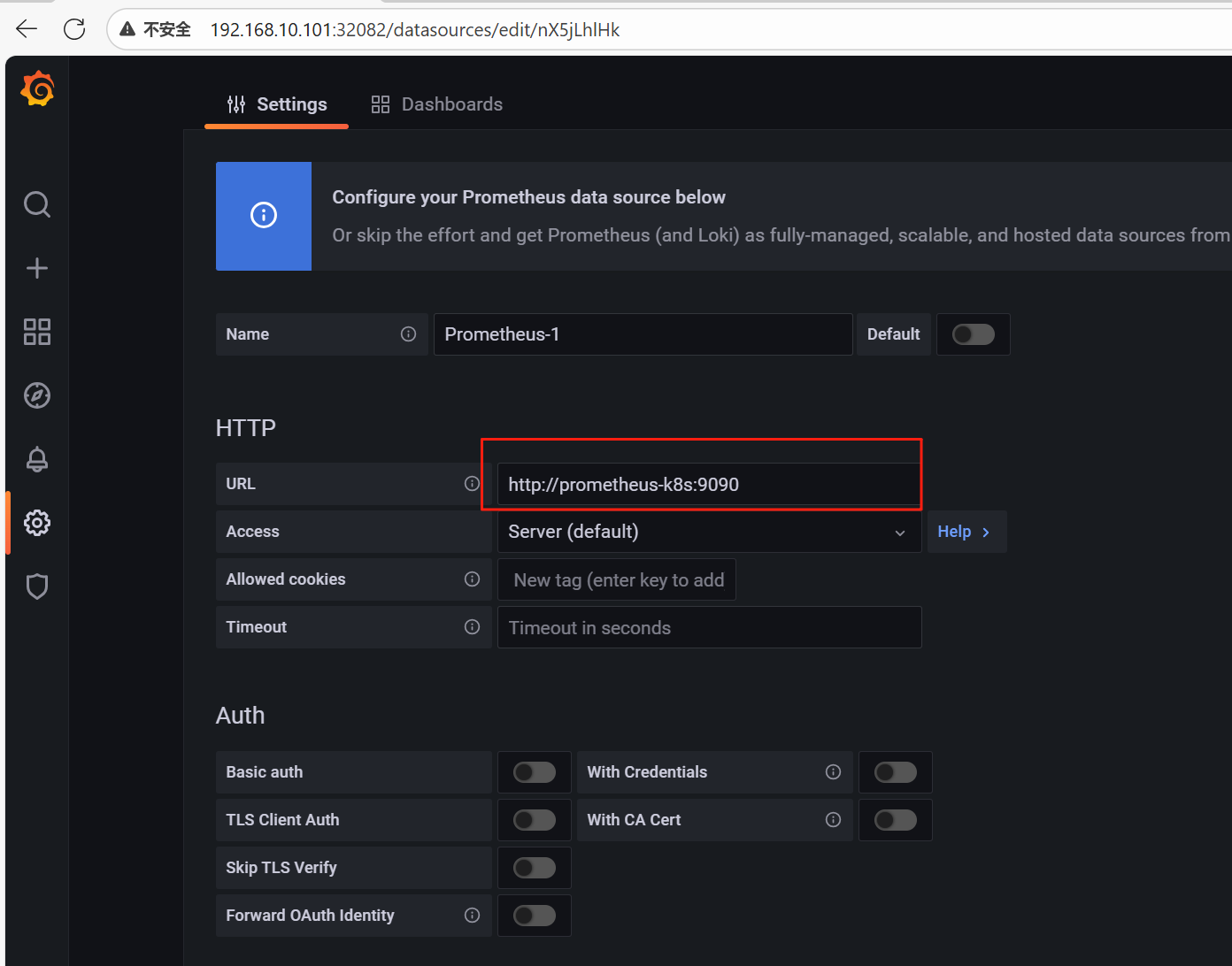
(3)配置数据源
HTTP 配置项下的 URL 填写“http://prometheus-k8s:9090”这里的 prometheus 是K8s 集群内
的 Service 名,也可以使用 IP 地址代替
然后点击页面底部的“Save & Test”按钮,保存并确定测试通过
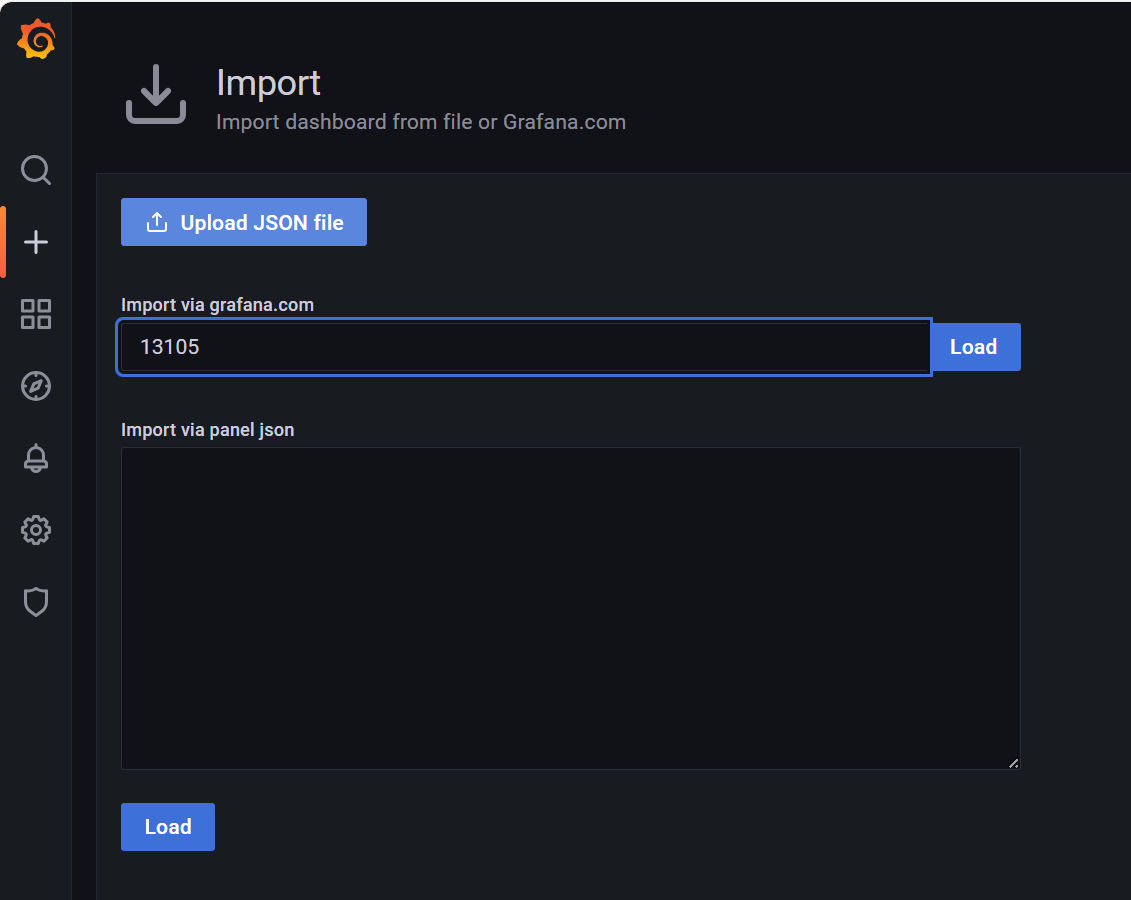
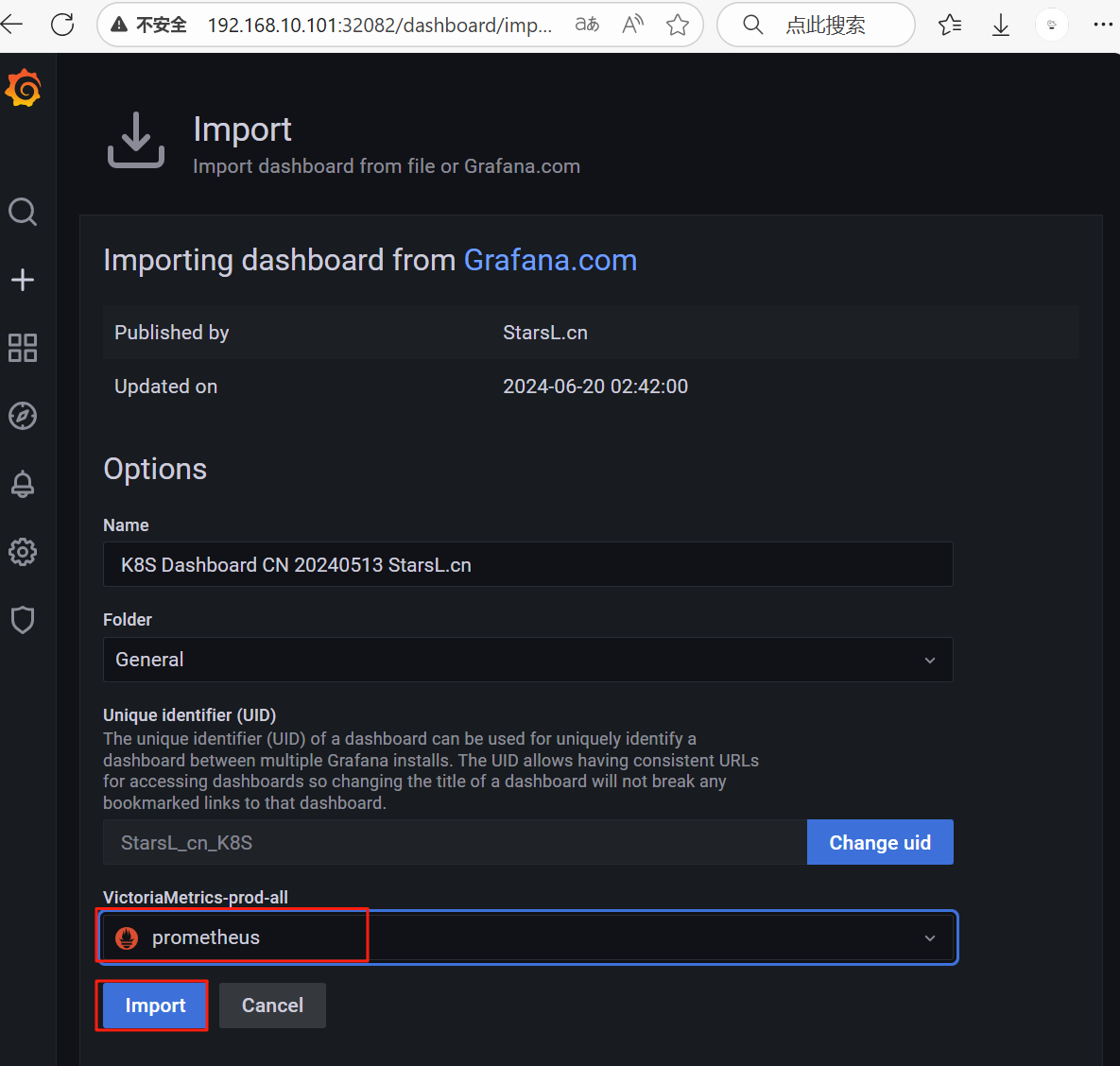
2:通过 Node id 导入监控模板
单击首页左侧搜索框下面的+的按钮。选择 import 按钮,输入监控模板 id:13105单击 Load 按钮加载即可,最后单击Import 按钮导入
完成上述步骤后,可以査看到 Node 节点在 Dashbord 监控页面展示情况
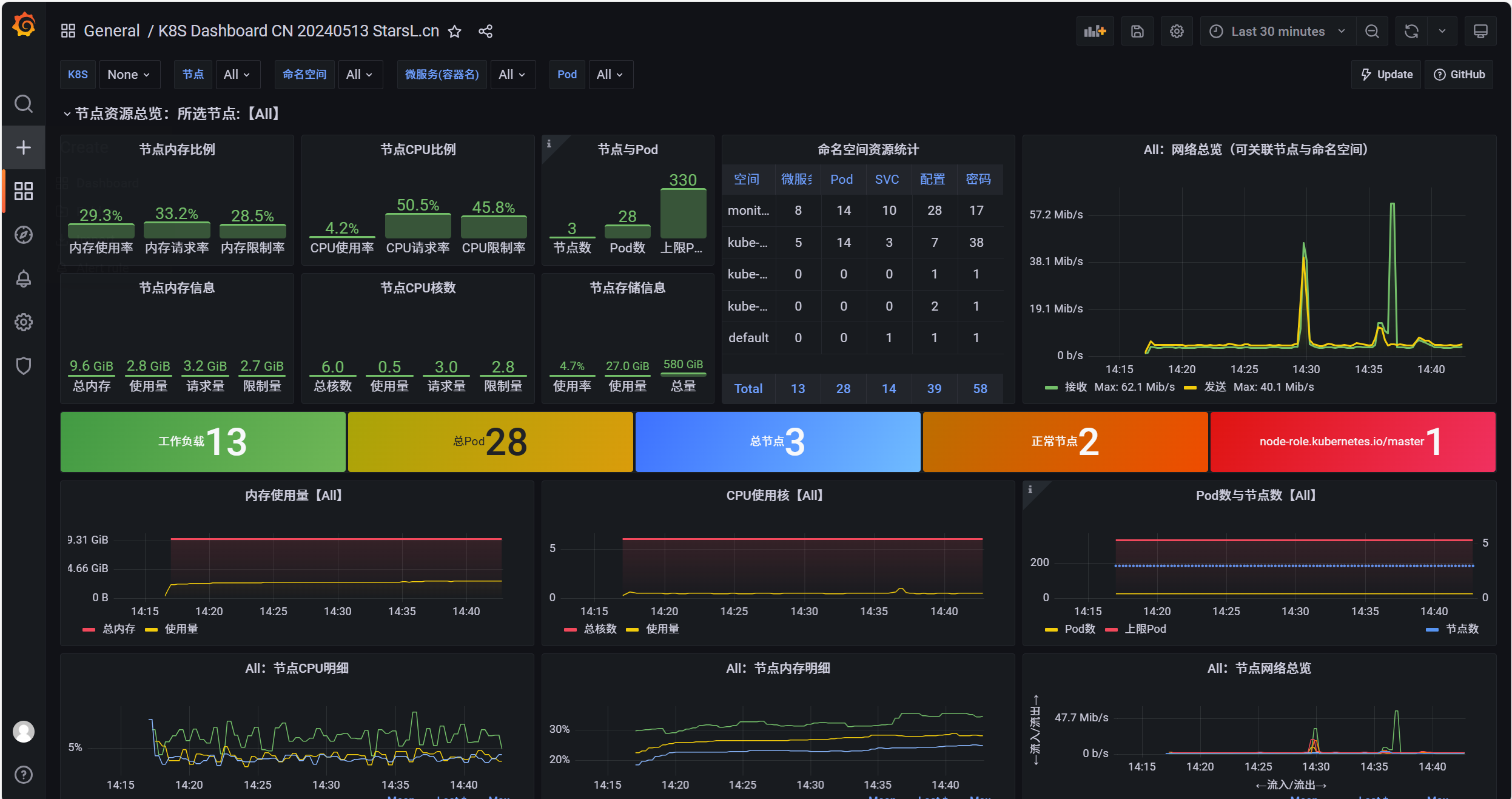
其他模板:
| 仪表盘名称 | 模板ID | 适用场景 | 数据源要求 | 特点 |
|---|---|---|---|---|
| Kubernetes Cluster | 7249 | 监控集群整体状态(节点/Pod/资源使用率) | Prometheus | 官方推荐,覆盖核心指标 |
| Docker Registry | 9621 | 监控私有Docker镜像仓库(存储用量、拉取次数等) | Prometheus + Docker Registry | 专为镜像仓库优化 |
| Docker and System Monitoring | 893 | 混合监控Docker容器及宿主机系统指标(CPU/内存/磁盘) | Prometheus + Node-exporter | 容器与节点指标联动 |
| K8S for Prometheus Dashboard 中文版 | 13105 | 中文界面的K8S监控(含Pod/Service/Ingress等) | Prometheus | 适合中文用户,指标全面 |
| Kubernetes Pods | 4686 | 聚焦Pod级别的资源使用(CPU/内存/网络) | Prometheus | 快速定位Pod异常 |
| Linux Stats with Node Exporter | 14731 | 监控Linux主机性能(进程/负载/磁盘IO/温度等) | Node-exporter | 深度系统级监控 |
模板对比建议
| 需求场景 | 推荐模板ID | 理由 |
|---|---|---|
| 快速查看集群健康状态 | 7249 | 官方维护,指标分类清晰 |
| 中文团队使用 | 13105 | 降低理解成本 |
| 深度主机监控 | 14731 | 覆盖硬件级指标(如CPU温度、磁盘健康) |
| 混合监控(容器+主机) | 893 | 一体化视图,避免切换仪表盘 |
四:监控 MySQL 数据库
在 Prometheus 的监控体系中,符合云原生设计理念的应用通常自带一个Metrics 接口,这使得Prometheus 能够直接抓取到应用的监控数据。然而,对于非云原生应用(如 MySOL、Redis、Kafka 等),由于它们并未原生暴露 Prometheus 所需的 Metrics 接口,因此我们需要借助 Exporter 来实现数据的采集和暴露。本案例将以 MySQL 为例,详细介绍如何通过 Exporter 实现对非云原生应用的监控,并将其集成到 Prometheus 监控体系中。
| 步骤 | 操作类型 | 命令/配置 | 说明 |
|---|---|---|---|
| 1 | 部署MySQL | kubectl create deploy mysql --image=mysql:5.7.23 | 创建MySQL Deployment,使用官方镜像5.7.23版本。 |
| 2 | 设置MySQL密码 | kubectl set env deploy/mysql MYSQL_ROOT_PASSWORD=pwd123 | 必须设置密码,否则Pod无法正常启动。 |
| 3 | 查看Pod状态 | kubectl get pod | 确认MySQL Pod状态为Running。 |
| 4 | 暴露MySQL Service | kubectl expose deploy mysql --type=NodePort --port=3306 | 通过NodePort暴露MySQL服务,外部可通过节点IP和随机端口(如31152)访问。 |
| 5 | 测试MySQL连接 | mysql -u root -ppwd123 -h 192.168.207.137 -P 31152 | 使用节点IP和映射端口连接MySQL,验证服务可用性。 |
| 6 | 创建监控用户 | GRANT ALL ON *.* TO 'exporter'@'%' IDENTIFIED BY 'exporter'; | 为MySQL Exporter创建专用用户,用于采集监控数据。 |
| 7 | 部署MySQL Exporter | kubectl create -f mysql-exporter.yaml | 使用自定义YAML部署Exporter,配置数据源为MySQL Service(mysql.default:3306)。 |
| 8 | 验证Exporter指标 | curl 10.109.16.46:9104/metrics | tail -1 | 检查Exporter是否正常输出Metrics数据(如promhttp_metric_handler_requests_total)。 |
| 9 | 配置ServiceMonitor | kubectl create -f mysql-sm.yaml | 定义Prometheus抓取规则,监控Exporter的Metrics接口(端口9104,间隔30s)。 |
| 10 | 检查Prometheus目标 | 访问Prometheus UI → Targets | 确认serviceMonitor/monitoring/mysql-exporter状态为UP。 |
| 11 | 导入Grafana仪表盘 | 在Grafana中导入模板 ID: 6239 | 可视化MySQL监控指标(如查询延迟、连接数、缓冲池使用率等)。 |
1. mysql-exporter.yaml
yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: mysql-exporternamespace: monitoring
spec:replicas: 1template:spec:containers:- name: mysql-exporterimage: registry.cn-beijing.aliyuncs.com/dotbalo/mysqld-exporterenv:- name: DATA_SOURCE_NAMEvalue: "exporter:exporter@(mysql.default:3306)/"ports:- containerPort: 9104
---
apiVersion: v1
kind: Service
metadata:name: mysql-exporternamespace: monitoring
spec:ports:- port: 9104targetPort: 9104selector:k8s-app: mysql-exporter2. mysql-sm.yaml (ServiceMonitor)
yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:name: mysql-exporternamespace: monitoring
spec:endpoints:- port: apiinterval: 30sselector:matchLabels:k8s-app: mysql-exporternamespaceSelector:matchNames:- monitoring五:对接钉钉报警
首先在钉钉群里面添加一个自定义机器人
为钉钉机器人添加关键字:FIRING
| 步骤 | 操作内容 | 命令/配置示例 | 说明 |
|---|---|---|---|
| 1 | 创建钉钉机器人 | 1. 钉钉群 → 设置 → 智能群助手 → 添加机器人 → 自定义 2. 设置关键词: FIRING | 需在机器人配置中添加关键词,否则消息无法发送。 |
| 2 | 下载并部署DingTalk Webhook | bash<br>wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v2.0.0/prometheus-webhook-dingtalk-2.0.0.linux-amd64.tar.gz<br>tar -xf prometheus-webhook-dingtalk-2.0.0.linux-amd64.tar.gz<br>mv prometheus-webhook-dingtalk-2.0.0.linux-amd64 /usr/local/dingtalk<br> | 解压并移动至/usr/local/dingtalk目录。 |
| 3 | 修改配置文件 | yaml<br># config.yml<br>targets:<br> webhook1:<br> url: "https://oapi.dingtalk.com/robot/send?access_token=YOUR_TOKEN"<br> secret: "YOUR_SECRET"<br> | 替换YOUR_TOKEN和YOUR_SECRET为机器人实际值,支持多Webhook配置。 |
| 4 | 启动服务 | bash<br>cat > /etc/systemd/system/prometheus-webhook-dingtalk.service <<EOF<br>[Unit]<br>Description=Prometheus Webhook DingTalk<br>[Service]<br>ExecStart=/usr/local/dingtalk/prometheus-webhook-dingtalk<br>Restart=always<br>[Install]<br>WantedBy=multi-user.target<br>EOF<br>systemctl daemon-reload<br>systemctl start prometheus-webhook-dingtalk<br> | 通过Systemd管理服务,默认监听8060端口。 |
| 5 | 配置Alertmanager | yaml<br># alertmanager-secret.yaml<br>receivers:<br>- name: 'webhook'<br> webhook_configs:<br> - url: 'http://<DINGTALK_IP>:8060/dingtalk/webhook1/send'<br> send_resolved: true<br> | 修改alertmanager-secret.yaml,指定Webhook地址(IP为DingTalk服务所在节点)。 |
| 6 | 应用配置 | bash<br>kubectl delete -f alertmanager-secret.yaml<br>kubectl apply -f alertmanager-secret.yaml<br> | 更新Alertmanager配置后需重建Secret生效。 |
| 7 | 测试报警 | bash<br>kubectl scale deploy mysql --replicas=0<br> | 停止MySQL后,观察Prometheus触发TargetDown告警,钉钉接收消息。 |
| 8 | 验证告警状态 | 访问 http://<ALERTMANAGER_IP>:30586(NodePort端口) | 检查告警是否从Pending变为Firing,并确认钉钉消息格式。 |
1. DingTalk Webhook 配置 (config.yml)
yaml
targets:webhook1:url: "https://oapi.dingtalk.com/robot/send?access_token=6d07ddc122c69d0bb23a6212f2378b4da"secret: "SEC00000000000000000000" # 加签密钥(可选)webhook2:url: "https://oapi.dingtalk.com/robot/send?access_token=another_token"message:title: '{{ template "legacy.title" . }}'text: '{{ template "legacy.content" . }}'2. Alertmanager 路由规则 (alertmanager-secret.yaml)
yaml
route:receiver: 'webhook'group_by: ['namespace']routes:- matchers: ['severity = critical']receiver: 'webhook'
receivers:
- name: 'webhook'webhook_configs:- url: 'http://192.168.207.137:8060/dingtalk/webhook1/send'send_resolved: true # 发送恢复通知
常见问题与解决
| 问题 | 原因/解决 |
|---|---|
| 钉钉未收到消息 | - 检查机器人关键词匹配(需包含FIRING)- 验证Webhook URL和Token是否正确。 |
| Alertmanager配置未生效 | 删除并重建Secret:kubectl delete/create -f alertmanager-secret.yaml。 |
| Webhook服务无法访问 | - 检查防火墙规则(开放8060端口)- 确认服务状态: systemctl status prometheus-webhook-dingtalk。 |
告警状态说明
| 状态 | 含义 |
|---|---|
Inactive | 监控正常,无告警触发。 |
Pending | 告警已触发但未满足持续时间阈值,等待确认。 |
Firing | 告警已确认并发送至Alertmanager,钉钉将接收通知。 |