【Kafka系列】第三篇| 在哪些场景下会选择使用 Kafka?
回答时既要明确场景,更要讲清「为什么是 Kafka」—— 结合其核心特性(高吞吐、持久化、多副本、分区机制)拆解,说服力更强。
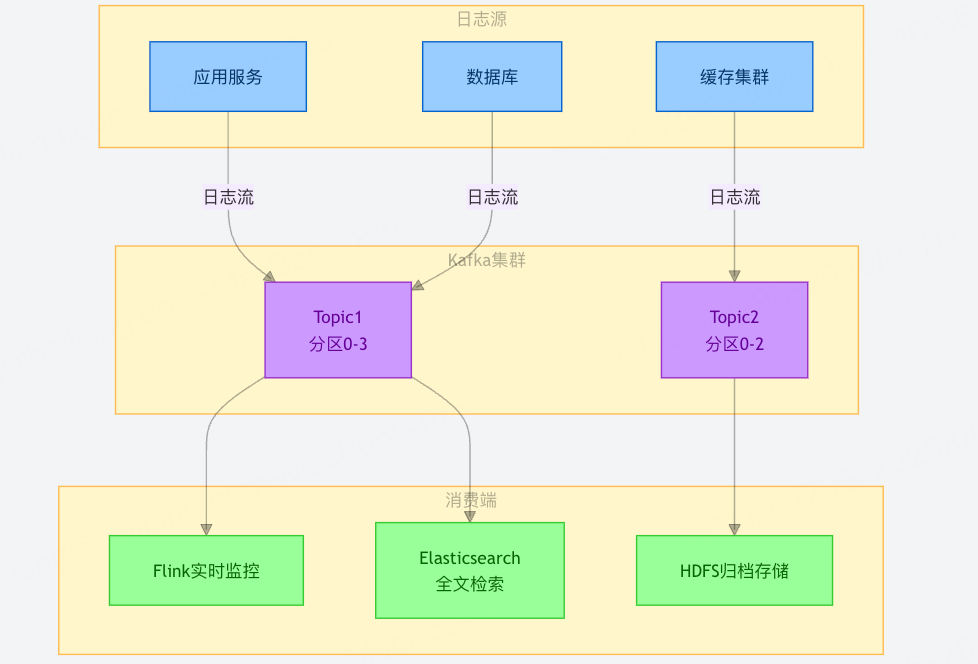
1. 日志收集:海量异构日志的「统一管道」
适用场景:分布式系统中,多服务(如微服务集群、数据库、缓存)产生的日志需要集中存储和分析(例如用 ELK 栈做日志检索,或导入 Hadoop 做离线分析)。
为什么选 Kafka:
高吞吐能力:单节点可支撑每秒数十万条日志写入,轻松应对服务集群的爆发式日志(比如电商大促时,订单服务日志量骤增 10 倍)。
多消费端适配:通过不同消费组,可同时向 Flink(实时日志监控)、Elasticsearch(全文检索)、HDFS(归档存储)分发数据,实现「一次采集,多场景复用」。
持久化保障:日志数据写入后会持久化到磁盘,即使下游服务暂时故障,也不会丢失数据(对比 Redis 内存存储,更适合海量日志的长期留存)。
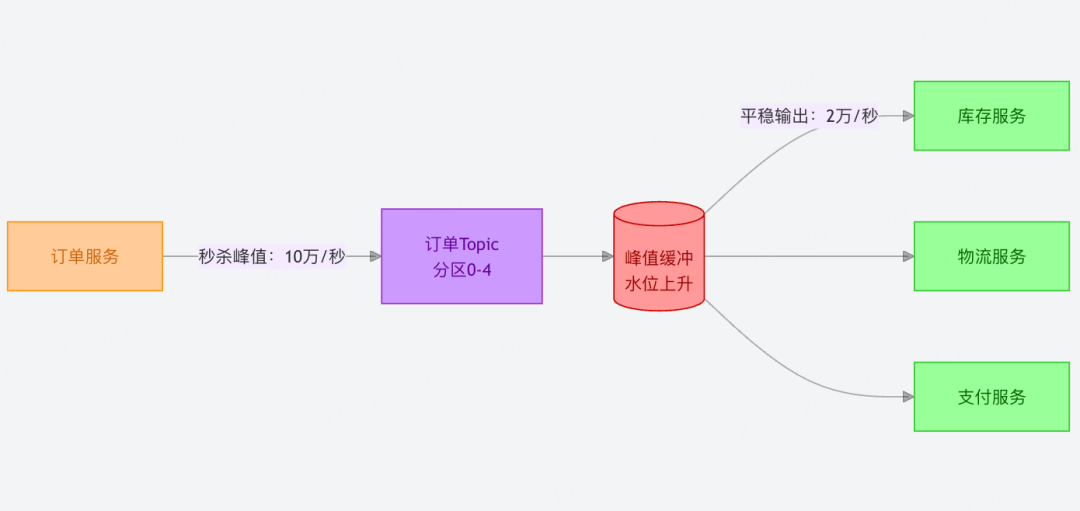
2. 高并发消息系统:解耦 + 削峰的「缓冲枢纽」
适用场景:分布式系统中模块间的异步通信(如电商的订单生成→库存扣减→物流通知链路),尤其适合存在流量波动的场景。
为什么选 Kafka:
削峰填谷:比如秒杀场景,瞬时下单请求可能达到每秒 10 万次,Kafka 可暂存请求,让下游库存服务按每秒 2 万次的能力平稳消费,避免服务被压垮。
彻底解耦:生产者(订单服务)和消费者(库存、物流服务)无需感知对方存在,哪怕物流服务临时升级,订单服务仍可正常写入消息,恢复后再消费。
支持重试与回溯:消息持久化特性允许消费者失败后重新拉取,避免传统 RPC 调用中「一次失败即丢数据」的问题。
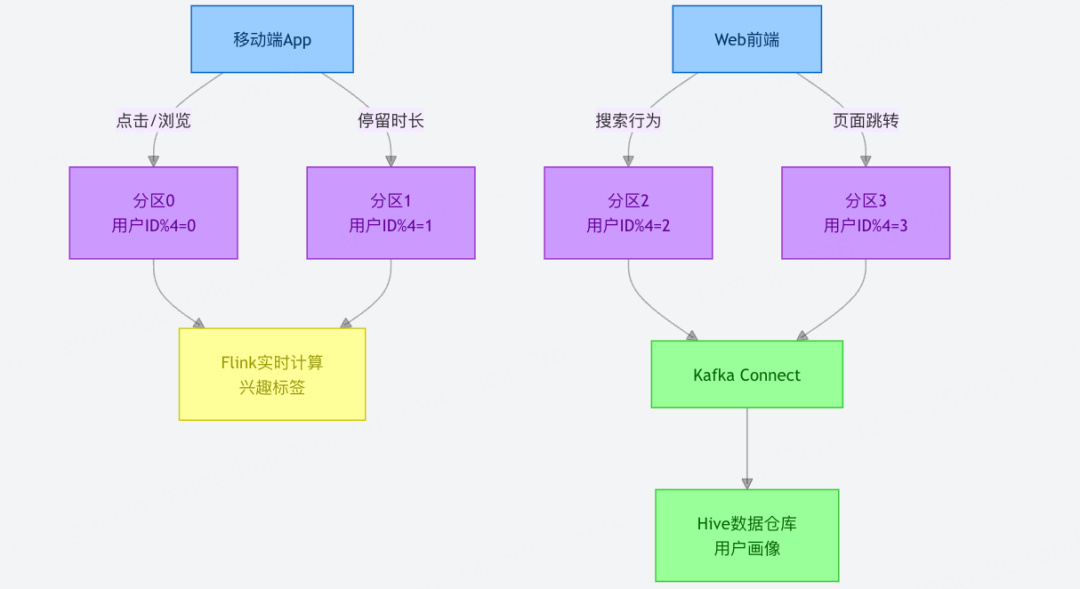
3. 用户行为跟踪:实时与离线分析的「数据桥梁」
适用场景:记录用户在 App / 网站的行为(点击、浏览、停留时长等),用于实时推荐(如首页动态信息流)和离线用户画像(如周度活跃用户分析)。
为什么选 Kafka:
高写入性能:支持每秒百万级用户行为数据写入(比如千万 DAU 产品的峰值时段),且延迟控制在毫秒级,不影响用户体验。
实时 + 离线兼容:写入 Kafka 的数据,可通过 Flink 实时计算用户实时兴趣标签(用于推荐),同时通过 Kafka Connect 同步到数据仓库(如 Hive),供离线团队做漏斗分析、留存率计算。
分区有序性:按用户 ID 哈希分区,可保证单个用户的行为序列在同一分区内有序,便于后续分析用户行为路径(对比 RabbitMQ,分区级有序更适合大规模用户场景)。
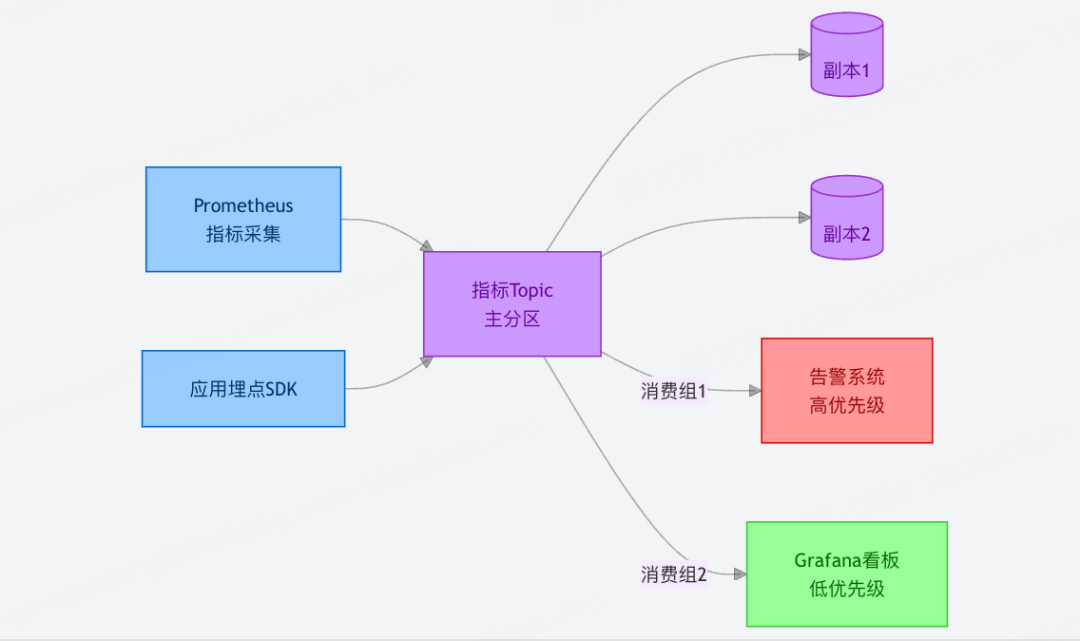
4. 运营指标监控:高可靠的「指标传输带」
适用场景:收集分布式系统的监控指标(如接口响应时间、错误率、服务器 CPU 使用率),用于实时告警(如错误率超阈值触发短信通知)和可视化看板(如 Grafana 大盘)。
为什么选 Kafka:
多副本防丢失:监控数据一旦丢失可能导致告警漏报,Kafka 的多副本机制(默认 3 副本)可保证数据在节点故障时不丢失。
多消费组隔离:告警系统(高优先级,需实时)和数据看板(低优先级,可延迟)可通过不同消费组独立消费,互不干扰。
5. 流式计算:实时数据处理的「最佳数据源」
适用场景:基于实时数据流的计算场景(如实时风控、动态定价、物联网传感器数据处理),常与 Spark Streaming、Flink 搭配。
为什么选 Kafka:
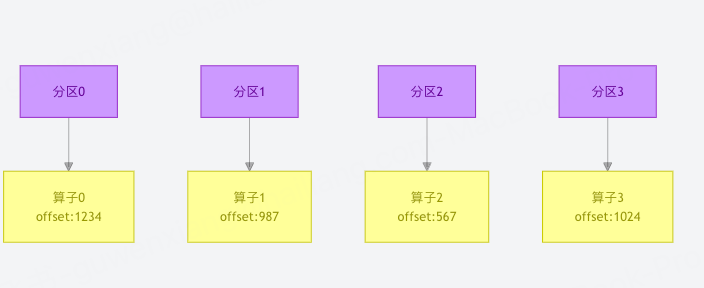
分区与计算并行:Kafka 的分区机制可与计算框架的并行度完全对齐(例如 8 个分区对应 Flink 的 8 个并行算子),实现数据分片处理,大幅提升计算效率。
低延迟 + 可回溯:毫秒级数据传输延迟满足实时性需求,同时支持通过 offset 回溯历史数据,便于计算任务重启或重跑(对比传统消息队列,更适合流式计算的容错需求)。
总结:Kafka 的「场景适配公式」
当业务满足以下 1 个或多个条件时,优先选 Kafka:
数据量大(日均 TB 级),需要高吞吐支撑;
需持久化存储,且不允许数据丢失;
多消费端并存(实时 + 离线、高优 + 低优);
与流式计算框架协同。
记住:技术选型的核心是「场景特性与工具能力的匹配」,讲清这一点,比罗列场景更能打动面试官。