Java 虚拟机运行时数据区组成详解
文章目录
- 程序计数器
- 栈
- 栈帧
- 局部变量表
- 操作数栈
- 帧数据
- 堆
- 方法区
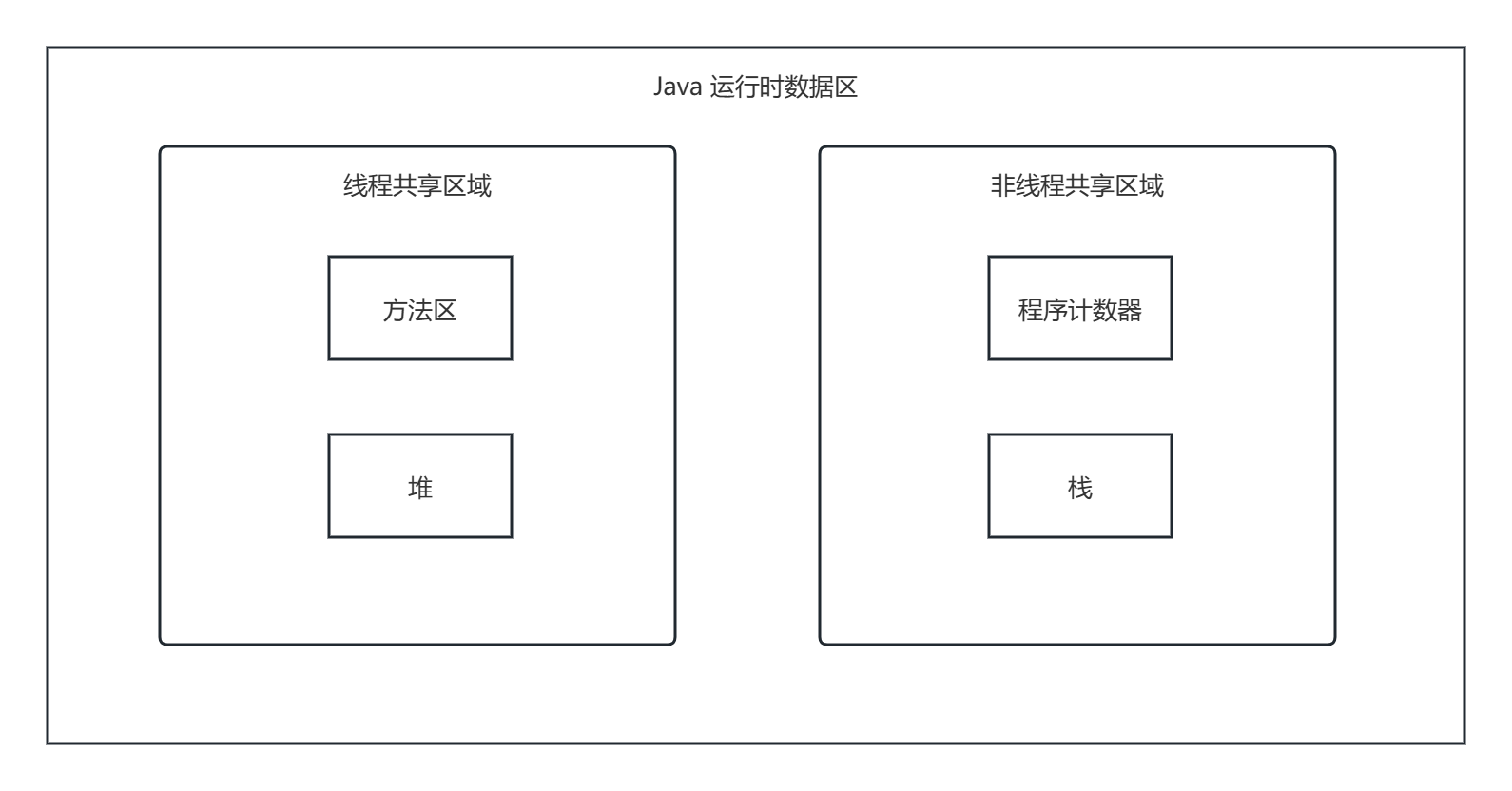
JAVA 虚拟机的运行时数据区指的是 JAVA 虚拟机在运行 Java 程序过程中管理的内存区域。在《Java 虚拟机规范》中,明确规定了运行时数据区每一部分的作用,运行时数据区的组成部分有程序计数器、堆、栈(可再细分为 Java 虚拟机栈与本地方法栈)、方法区。
运行时数据区可分为线程共享与线程不共享两个部分的组成。线程共享是指所有线程共享同一块内存空间中的内容;而线程不共享则是指当每一个线程在 JVM 中被创建后,都独立享有一块内存空间,线程之间的内存空间互不影响。在 JAVA 虚拟机中,线程共享的区域有方法区和堆,而非线程共享的区域有程序计数器和栈。
以下是 JVM 运行时数据区的内存结构图:
程序计数器
程序计数器(Program Counter Register),又称 PC 寄存器,被用于存储当前线程的当前执行的字节码指令的内存地址。通常情况下,开发人员并不需要对程序计数器进行关注和做任何处理,程序计数器的一切操作为 Java 虚拟机自身掌控。
在 JVM 中,程序计数器属于线程私有,即每个线程都有属于自己的程序计数器,所以不存在线程安全问题。对于 JVM 中的线程而言,每个线程的程序计数器只存储一个固定长度的内存地址,在线程被创建时,该线程的程序计数器内存大小就被确定且不会发生变更,所以程序计数器也不会产生内存溢出问题。
例如,使用 64 位的操作系统,意味着其内存地址是 64 位(即 8 个字节),所以每次向程序计数器中放置的数据(即内存地址的值)大小也为 8 个字节。
字节码指令最初是被保存在字节码文件中,类加载器将字节码文件读取到内存后,字节码文件中的执行指令肯定也将会保存在内存中,所以每个指令都占有一个内存地址。内存中的字节码指令最终需要交给 JAVA 解释器解释执行,所以 JAVA 解释器必须明确当前需要执行的字节码指令在内存中的位置,此时则需要程序计数器提供该字节码指令的内存地址。解释器从程序计数器中获取字节码指令的内存地址,以进行后续的解释和执行。
在加载阶段,虚拟机将字节码文件中的指令读取到内存之后,会将字节码文件中的偏移量转换为内存地址。例如,值为 0 的偏移量被替换为值为 0x000001f248c072c0 的内存地址。每一条字节码指令都会拥有一个内存地址。
在代码执行过程中,程序计数器会记录下一行字节码指令的地址。执行完当前指令之后,虚拟机的执行引擎根据程序计数器执行下一行指令。
程序计数器的作用:
- 程序计数器可以控制程序指令的执行,实现分支、跳转、异常等复杂逻辑;
- 在多线程执行情况下,Java 虚拟机需要通过程序计数器记录 CPU 切换前解释执行到哪一句指令并继续解释执行。
栈
栈的细分
在《Java 虚拟机规范》中,栈被分为 Java 虚拟机栈和本地方法栈两个部分:
- Java 虚拟机栈(Java Virtual Machine Stack):Java 虚拟机栈采用栈的数据结构(先进后出)来管理方法调用中的基本数据,随着线程创建而创建,而回收则会在线程的销毁时执行。由于方法可能会在不同线程中执行,所以每个线程都会包含一个自己的虚拟机栈。
- 本地方法栈(Native Method Stack):本地方法栈用于保存使用 C++ 等非 Java 语言实现的本地方法。本地方法栈和 Java 虚拟机栈的功能类似,它们都用于支持方法的调用和执行,但本地方法栈专门用于管理本地方法的栈帧。
在 HotSpot 虚拟机中,Java 虚拟机栈与本地方法栈使用同一栈空间,该栈空间中可能同时包含 Java 方法的栈帧与本地方法的栈帧。
栈的作用
Java 虚拟机栈的主要作用是支持方法的调用、执行并存储方法调用的信息和方法执行过程中的临时数据。
栈内存溢出问题
对于 Java 虚拟机栈中的栈帧而言,如果栈帧过多,可能会导致 Java 虚拟机栈所占用的实时内存超过 Java 虚拟机给栈分配的最大内存,此时将会造成 Java 虚拟机栈内存溢出。Java 虚拟机栈内存溢出时会抛出 java.lang.StackOverflowError 的异常报错。
栈的默认内存大小
在不指定栈大小的情况下,Java 虚拟机将为每个线程创建一个具有默认内存大小的栈。而默认内存大小取决于操作系统及计算机的体系结构,例如,在 64 位操作系统上,栈内存的默认大小通常被设置为 1 MB。而在 32 位操作系统上,栈内存的默认大小通常被设置为 256 KB。而在 Windows 操作系统上,栈内存的大小基于操作系统的默认值。
设置栈内存大小
通过 JVM 参数 -Xss 或 -XX:ThreadStackSize 可以手动设置栈的大小,如 -Xss2m 或 -XX:ThreadStackSize=2048 表示设置栈的大小为 2MB,可以指定的单位有 K/k、M/m 和 G/g,在不指定单位的情况下,-Xss JVM 参数的单位默认为字节,其中 K/k 单位在实际使用中较多。
需要注意的是,HotSpot Java 虚拟机对栈大小有最大值与最小值的要求,如果栈大小的设置范围超出了最大值或最小值的限制,则通过 JVM 参数设置栈的大小将不生效。另外,不指定单位的情况下,通过默认单位设置的值必须是 1024 的倍数。
如果方法中的局部变量过多、操作数栈过深会影响栈内存的大小,在相同栈内存大小的情况下,则能够容纳的栈帧数量将变少。一般情况下,工作中即便使用了递归操作,栈深度最多也只能到几百,不会出现栈内存溢出。所以此参数可以手动指定为 -Xss256k 以节省内存。
栈帧
Java 虚拟机栈由一系列栈帧组成,栈帧是虚拟机栈的基本组成单位,它随着方法的调用和执行动态地入栈和出栈。每当一个方法被调用,Java 虚拟机会创建一个新栈帧(Stack Frame),并将该栈帧压入当前线程的 Java 虚拟机栈中。
栈帧的组成包括局部变量表、操作数栈、帧数据。对于局部变量表与操作数栈,基本上每类虚拟机都是按照《Java 虚拟机规范》实现的,而对于帧数据,每类虚拟机都能自定义自己的组成部分。
局部变量表
局部变量表的作用是在运行过程中存放实例方法的 this 对象、方法参数(其存放顺序与方法中参数定义的顺序一致)、方法体中声明的局部变量。编译为字节码文件后,就可以确认局部变量表中的内容。
字节码文件中的局部变量表
表内容:
| 字段 | 说明 |
|---|---|
| Nr. | 局部变量表中的编号 |
| 起始PC | 从指定字节码指令开始生效的范围 |
| 长度 | 从指定字节码指令开始生效范围的长度 |
| 序号 | 槽的起始编号 |
Java 虚拟机通过局部变量表控制每个局部变量可以访问的范围,如果在超出局部变量表定义指定局部变量范围的情况下,访问指定局部变量,则指令会被 Java 虚拟机判断为有误,Java 虚拟机将拒绝执行该指令。局部变量表提高了一定的安全性。
通过字节码文件中的局部变量表,Java 虚拟机也可以知道需要为在某个方法的栈帧中需要为局部变量开辟多大的内存空间。
栈帧中的局部变量表
栈帧中的局部变量表是一个数组,数组中的每一个位置称之为局部变量槽(Local Variable Slot),long 与 double 类型占用两个槽,其他类型占用一个槽。
实例方法中的序号为 0 的位置存放的是 this 对象(当前调用方法的对象),运行时会在内存中存放实例对象的地址。
操作数栈
操作数栈(Operand Stack)是栈帧中虚拟机在执行指令过程中用于存放临时数据的一块区域。它是一种栈式的数据结构,如果一条指令将一个值压入操作数栈,则后面的指令可以弹出并使用该值。
在编译期就可以确定操作数栈的最大深度,从而执行时正确的分配内存大小。
帧数据
帧数据主要包含动态链接、方法出口、异常表的引用。
-
动态链接:当前类的字节码指令引用了其他类的属性或者方法时,需要将符号引用(编号)转换成对应的运行时常量池中的内存地址。动态链接就保存了编号到运行时常量池的内存地址的映射关系。
-
方法出口:方法在正常或异常结束时,当前栈帧会被弹出,同时程序计数器应该指向上一个栈帧中下一个指令的地址。所以在当前栈帧中,需要存储此方法出口的地址。
-
异常表:存放代码中异常的处理信息,包含 try 代码块和 catch 代码块执行后跳转到的字节码指令位置。
字节码文件中异常表的字段 说明 Nr. 异常表中的编号 起始 PC 异常处理代码在字节码中的偏移量的起始位置 结束 PC 异常处理代码在字节码中的偏移量的结束位置 跳转 PC 异常处理代码在字节码中的偏移量的跳转位置 捕获类型 捕获的异常类型
堆
堆内存是用于存储对象实例的内存区域,创建出的对象都存在于堆内存中,堆内存通常是 Java 程序内存中最大的一块内存区域。栈中的局部变量表可以存放堆中对象的引用。静态变量也可以存放堆对象的引用,通过静态变量就可以实现对象在线程之间的共享。JDK 7 及之后的版本中,静态变量也被存放于堆的 Class 对象中。
堆内存大小存在上限,当达到上限后将抛出异常 java.lang.OutOfMemoryError: Java heap space。
堆内存需要关注三个值,分别是:
| 名称 | 说明 |
|---|---|
used | 当前已经使用的堆内存 |
total | Java 虚拟机已经分配的可用堆内存 |
max | Java 虚拟机可以分配的最大堆内存 |
随着堆中对象的增多,当 total 可以使用的内存即将不足时,Java 虚拟机会继续分配内存给堆,total 值将会逐渐变大,但不能超过 max。需要注意的是,并不是当 used = max = total 时就会发生堆内存溢出,堆内存溢出的具体情况与 JVM 垃圾回收机制有关。
如果不设置任何 Java 虚拟机参数,max 默认是系统内存的 1/4,total 默认是系统内存的 1/64。在实际应用中一般都需要设置 total 和 max 的值:
- 设置初始的 total 值格式为:
-Xms内存大小 - 设置 max 值格式为:
-Xmx内存大小
设置 -Xms 与 -Xmx 参数默认单位为字节,可以指定的单位有 K/k、M/m 和 G/g,如果不指定单位,通过默认字节单位设置值,那么值必须是 1024 的倍数。需要注意的是,-Xmx 参数的值必须大于 2 MB,-Xms 参数的值必须大于 1 MB。
arthas 可以通过 dashboard 命令(手动指定刷新频率语法格式为 dashboard -i 刷新频率(毫秒),不指定默认 5 秒刷新一次)或 memory 命令以观察堆内存 used、total 和 max 值的具体情况:
arthas 中显示的 heap 堆大小与设置的值不一样,例如设置 -Xmx1g -Xms1g 参数启动,但 arthas 中的 total 与 max 值却为 981 M,原因是 arthas 中的 heap 堆内存使用了 JMX 技术内存获取方式,这种方式与垃圾回收器有关,计算的是可以分配对象的内存,而不是整个内存。虽然设置 -Xmx1g -Xms1g 为堆参数,但是 1g 的内存并不是全部都能够被使用的。
在实际开发中,Java 服务端程序一般建议将 -Xmx 参数与 -Xms 参数设置为相同的值,这样在程序启动之后可使用的总内存就是最大内存,而无需向 Java 虚拟机再次申请,减少了申请并分配内存时间上的开销,同时也不会出现内存过剩之后堆回收的情况。-Xmx 和 -Xms 具体设置的值与实际的应用程序环境有关。
方法区
方法区用于存放基础信息的位置,线程共享,主要包含三部分内容:
- 类的元信息:保存了所有类的基本信息(InstanceKlass 对象),在类的加载阶段完成。实际上 Java 虚拟机在底层实现上,InstanceKlass 对象只存放方法和常量池的引用,真正的方法与常量池则是使用一块单独的内存区域存放。
- 运行时常量池:保存了字节码文件中的常量池内容。字节码文件中通过编号查表的方式找到常量,这种常量池称为静态常量池。当常量池加载到内存中后,可以通过内存地址快速定位到常量池中的内容,这种常量池被称为运行时常量池。常量池会在类的加载阶段读取到内存中,此时常量池就从原来的静态常量池变成运行时常量池,而运行时常量池中的每个常量数据都可以通过内存地址去访问。
- 字符串常量池(JDK 7及之前版本存放于方法区):保存了字符串常量。字符串常量池是除类的元信息、运行时常量池之外的一块内存区域。在 JDK 早期的设计中,字符串常量池属于运行时常量池的一部分,且存储位置也与运行时常量池一致。后续做出了调整,将字符串常量池和运行时常量池做了拆分:
- JDK 7 之前,运行时常量池包含字符串常量池,运行时常量池位于永久代中;
- JDK 7 时,字符串常量池的位置从方法区中调整为堆中,运行时常量池中除了字符串常量池的其他内容都还在永久代中;
- JDK 8 之后,元空间代替永久代,字符串常量池位于堆中,运行时常量池位于元空间中。
在 JDK 6 及之前版本中,永久代中还被用于存放静态变量。
堆内存与字符串常量池的经典案例:
String s1 = new String("abc"); // 存放于堆内存中
String s2 = "abc"; // 存放于字符串常量池中
System.out.println(s1 == s2); // false
String a = "1"; // 存放于字符串常量池
String b = "2"; // 存放于字符串常量池
String c = "12"; // 存放于字符串常量池
String d = a+b; // 存放于堆内存
System.out.println(c == d); // false
上例中,
a+b的动作通过字节码文件中的字节码指令分析得知实现的原理是会创建一个新的StringBuilder对象,并将a和b的内容追加到其中,最后通过toString方法将其转换为一个新的String对象,即变量d,所以输出为false。
String a = "1"; // 存放于字符串常量池
String b = "2"; // 存放于字符串常量池
String c = "12"; // 存放于字符串常量池
String d = "1"+"2"; // 存放于字符串常量池
System.out.println(c == d); // true
上例中,
"1"+"2"的动作通过字节码文件中的字节码指令分析得知实现的原理是直接获取字符串常量池中的 “1”、“2” 后,放入操作数栈中直接将 “+” 进行了去除,所以String d = "1"+"2";与String c = "12";是相同的。字符串常量池中已经存在了 “12”,所以输出为true。
方法区是《Java 虚拟机规范》中设计出来的虚拟概念,每款 Java 虚拟机在实现上都各有不同。Hotspot 设计如下:
- JDK 7 及之前的版本将方法区存放在堆区域中的永久代空间,堆的大小由虚拟机参数
-XX:MaxPermsize=值来控制; - JDK 8 及之后的版本将方法区存放在元空间中,元空间位于操作系统维护的直接内存中,默认情况下只要不超过操作系统承受的上限,可以一直分配。但是也可以使用
-XX:MaxMetaspaceSize=值将元空间最大大小进行限制,实际开发中一般将-XX:MaxMetaspaceSize的值设置为256M。
通过 arthas 的 memory 命令可以查看方法区内存情况,JDK 7 及之前版本查看 ps_perm_gen 属性,JDK 8 及之后版本查看 metaspace 属性。JDK 8 及之后版本中的 metaspace 属性的 max 值为 -1 表示在 JDK 8 及之后版本中方法区的内存大小是不受限的。
将类的字节码文件加载到内存中,当内存达到操作系统内存上限,将发生内存溢出:
- JDK 7 及之前版本将抛出
java.lang.OutOfMemoryError: PermGen space; - JDK 8 及之后版本将抛出
java.lang.OutOfMemoryError: Metaspace。
intern 方法的使用案例:
String s1 = new StringBuilder().append("think").append("123").toString(); System.out.println(s1.intern() == s1); String s2 = new StringBuilder().append("ja").append("va").toString(); System.out.println(s2.intern() == s2);JDK 6 中结果为 false、false,因为
s1.intern()返回的对象位于永久代的字符串常量池中,而s1的对象位于堆中。JDK 8 中结果为 true、false,因为
s1与s1.intern()都指向同一个对象。s1存放位于堆中的对象,而s1.intern()存放堆中对象的引用,这样设计的目的节省一定的空间(当堆中存在某字符串时,不会再将该字符串复制一份放入字符串常量池中,而是直接存放堆中字符串的引用)。