书生浦语第五期-L1G4-InternLM 论文分类微调实践(XTuner 版)
XTuner介绍
一句话介绍XTuner:
XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。
核心特点:
高效:支持在有限资源下微调大模型,如在8GB显存上微调7B参数模型,也支持多节点微调70B+模型;自动分发高性能算子加速训练;兼容DeepSpeed优化策略。
灵活:支持多种大语言模型(如InternLM、Llama、ChatGLM等)和多模态模型;支持多种数据格式;支持QLoRA、LoRA、全量参数微调等多种微调算法。
全能:支持增量预训练、指令微调与Agent微调;预定义多种对话模板;训练所得模型可无缝接入部署工具LMDeploy和评测工具OpenCompass。
解决问题:
解决大模型微调的资源门槛高、效率低的问题
解决多种模型架构和微调方法的兼容性问题
解决从
训练到部署的工作流程不连贯问题
适用场景:
在计算资源有限的情况下微调大语言模型
多模态模型(如LLaVA)的预训练与微调
领域特定模型的定制化训练
大模型的Agent能力训练
价值:
XTuner降低了大模型微调的技术和资源门槛,使研究人员和开发者能够高效地将通用大模型适配到特定领域或任务,同时保持高性能,并提供从训练到部署的完整解决方案。
安装依赖
conda activate /root/share/pre_envs/pytorch2.3.1cu12.1
pip install 'xtuner[deepspeed]' timm==1.0.9
pip install transformers==4.48.0
pip install modelscope
检测环境是否安装好:
xtuner list-cfg
微调模型
实现代码:
# Copyright (c) OpenMMLab. All rights reserved.
# —— 动态补丁:兼容 transformers>=4.48 ——
from transformers.cache_utils import DynamicCache # 1. 引入类
if not hasattr(DynamicCache, "get_max_length"): # 2. 判断是否缺失DynamicCache.get_max_length = DynamicCache.get_max_cache_shape # 3. 补一个别名
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook,DistSamplerSeedHook,IterTimerHook,LoggerHook,ParamSchedulerHook,
)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfigfrom xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (DatasetInfoHook,EvaluateChatHook,VarlenAttnArgsToMessageHubHook,
)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = "./internlm2_5-7b-chat"
use_varlen_attn = False# Data
alpaca_en_path = "/root/user/FinetuningPaper/sftdata.jsonl"#换成自己的数据路径
prompt_template = PROMPT_TEMPLATE.internlm2_chat
max_length = 1024
pack_to_max_length = True# parallel
sequence_parallel_size = 1# Scheduler & Optimizer
batch_size = 1 # per_device
accumulative_counts = 1
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 1
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03# Save
save_steps = 50
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)# Evaluate the generation performance during the training
evaluation_freq = 50
SYSTEM = SYSTEM_TEMPLATE.alpaca
evaluation_inputs = ["请给我介绍五个上海的景点", "Please tell me five scenic spots in Shanghai"]#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(type=AutoTokenizer.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,padding_side="right",
)model = dict(type=SupervisedFinetune,use_varlen_attn=use_varlen_attn,llm=dict(type=AutoModelForCausalLM.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,torch_dtype=torch.float16,quantization_config=dict(type=BitsAndBytesConfig,load_in_4bit=True,load_in_8bit=False,llm_int8_threshold=6.0,llm_int8_has_fp16_weight=False,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",),),lora=dict(type=LoraConfig,r=64,lora_alpha=16,lora_dropout=0.1,bias="none",task_type="CAUSAL_LM",),
)#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(type=process_hf_dataset,dataset=dict(type=load_dataset, path='json', data_files=alpaca_en_path),tokenizer=tokenizer,max_length=max_length,dataset_map_fn=alpaca_map_fn,template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length,use_varlen_attn=use_varlen_attn,
)sampler = SequenceParallelSampler if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(batch_size=batch_size,num_workers=dataloader_num_workers,dataset=alpaca_en,sampler=dict(type=sampler, shuffle=True),collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn),
)#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(type=AmpOptimWrapper,optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),accumulative_counts=accumulative_counts,loss_scale="dynamic",dtype="float16",
)# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [dict(type=LinearLR,start_factor=1e-5,by_epoch=True,begin=0,end=warmup_ratio * max_epochs,convert_to_iter_based=True,),dict(type=CosineAnnealingLR,eta_min=0.0,by_epoch=True,begin=warmup_ratio * max_epochs,end=max_epochs,convert_to_iter_based=True,),
]# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [dict(type=DatasetInfoHook, tokenizer=tokenizer),dict(type=EvaluateChatHook,tokenizer=tokenizer,every_n_iters=evaluation_freq,evaluation_inputs=evaluation_inputs,system=SYSTEM,prompt_template=prompt_template,),
]if use_varlen_attn:custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]# configure default hooks
default_hooks = dict(# record the time of every iteration.timer=dict(type=IterTimerHook),# print log every 10 iterations.logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),# enable the parameter scheduler.param_scheduler=dict(type=ParamSchedulerHook),# save checkpoint per `save_steps`.checkpoint=dict(type=CheckpointHook,by_epoch=False,interval=save_steps,max_keep_ckpts=save_total_limit,),# set sampler seed in distributed evrionment.sampler_seed=dict(type=DistSamplerSeedHook),
)# configure environment
env_cfg = dict(# whether to enable cudnn benchmarkcudnn_benchmark=False,# set multi process parametersmp_cfg=dict(mp_start_method="fork", opencv_num_threads=0),# set distributed parametersdist_cfg=dict(backend="nccl"),
)# set visualizer
visualizer = None# set log level
log_level = "INFO"# load from which checkpoint
load_from = None# whether to resume training from the loaded checkpoint
resume = False# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)# set log processor
log_processor = dict(by_epoch=False)
pretrained_model_name_or_path alpaca_en_path 只需要注意34和38行模型、数据位置就好了。
微调指令:
xtuner train internlm2_5_chat_7b_qlora_alpaca_e3_copy.py --deepspeed deepspeed_zero1
微调完成之后,需要进行两个步骤:首先将PTH格式的模型转换为HuggingFace格式,然后将adapter与基础模型合并。
将PTH格式转换为HuggingFace格式
cd #你的项目根目录
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf internlm2_5_chat_7b_qlora_alpaca_e3_copy.py ./work_dirs/internlm2_5_chat_7b_qlora_alpaca_e3_copy/iter_xx.pth ./work_dirs/hf
合并adapter和基础模型
cd #你的项目根目录
export MKL_THREADING_LAYER=GNU
xtuner convert merge ./internlm2_5-7b-chat ./work_dirs/hf ./work_dirs/merged --max-shard-size 2GB
之后检测微调之后模型和之前模型推理方面的不同:
之前: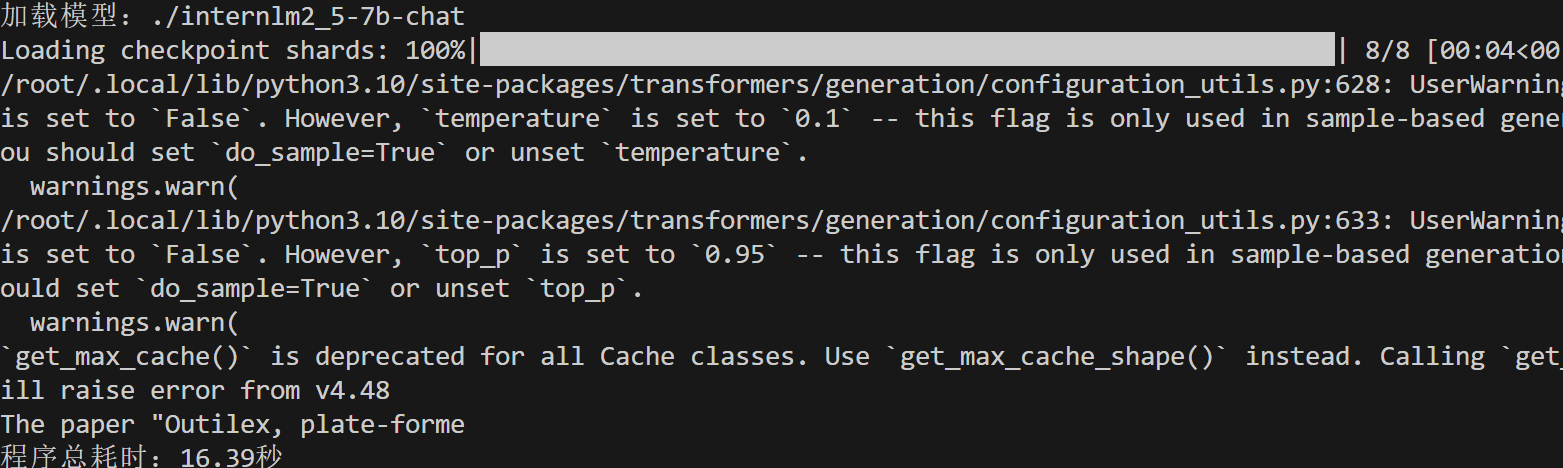
之后:
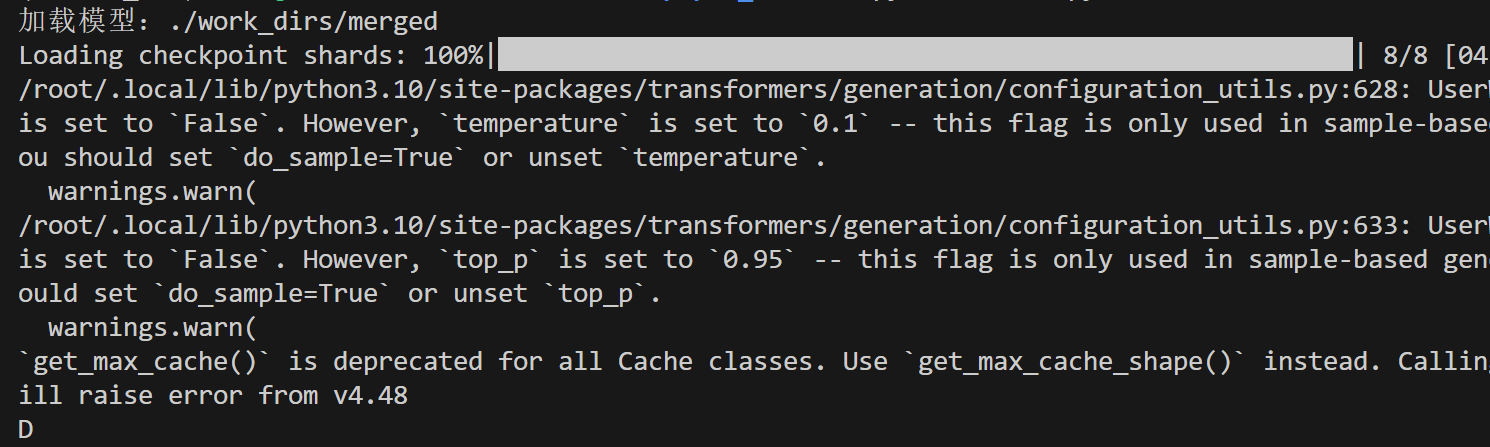
- 部署模型
pip install lmdeploy
python -m lmdeploy.pytorch.chat ./work_dirs/merged \--max_new_tokens 256 \--temperture 0.8 \--top_p 0.95 \--seed 0
提交模型并评测
将微调好的模型上传模型至 ModelScope 模型库 ,有 ① swift 指令 ② ModeScope 官方 Python SDK 两种方法,二选一即可。
ModelScope官方PythonSDK上传模型:
pip install modelscope使用Python SDK来上传模型
from modelscope.hub.api import HubApi
from modelscope.hub.constants import Licenses, ModelVisibility# 配置基本信息
YOUR_ACCESS_TOKEN = 'xxx(从modelscope获取,即上节的hub_token)'
api = HubApi()
api.login(YOUR_ACCESS_TOKEN)# 取名字
owner_name = 'xxx' # ModelScope 的用户名,需根据自己情况修改
model_name = 'xxx' # 为模型库取个响亮优雅又好听的名字,需根据自己情况修改
model_id = f"{owner_name}/{model_name}"# 创建模型库,若已通过6.1节的ModelScope网页端创建,此段代码可忽略
api.create_model(model_id,visibility=ModelVisibility.PUBLIC,license=Licenses.APACHE_V2,chinese_name=f"{owner_name}的论文分类打榜赛模型")# 上传模型
api.upload_folder(repo_id=f"{owner_name}/{model_name}",folder_path='/root/path/to/your/model', # 微调后模型的文件夹名称commit_message='upload model folder to repo', # 写点开心的上传信息
)将modelscope的hub_token和你存放模型的位置,放入代码
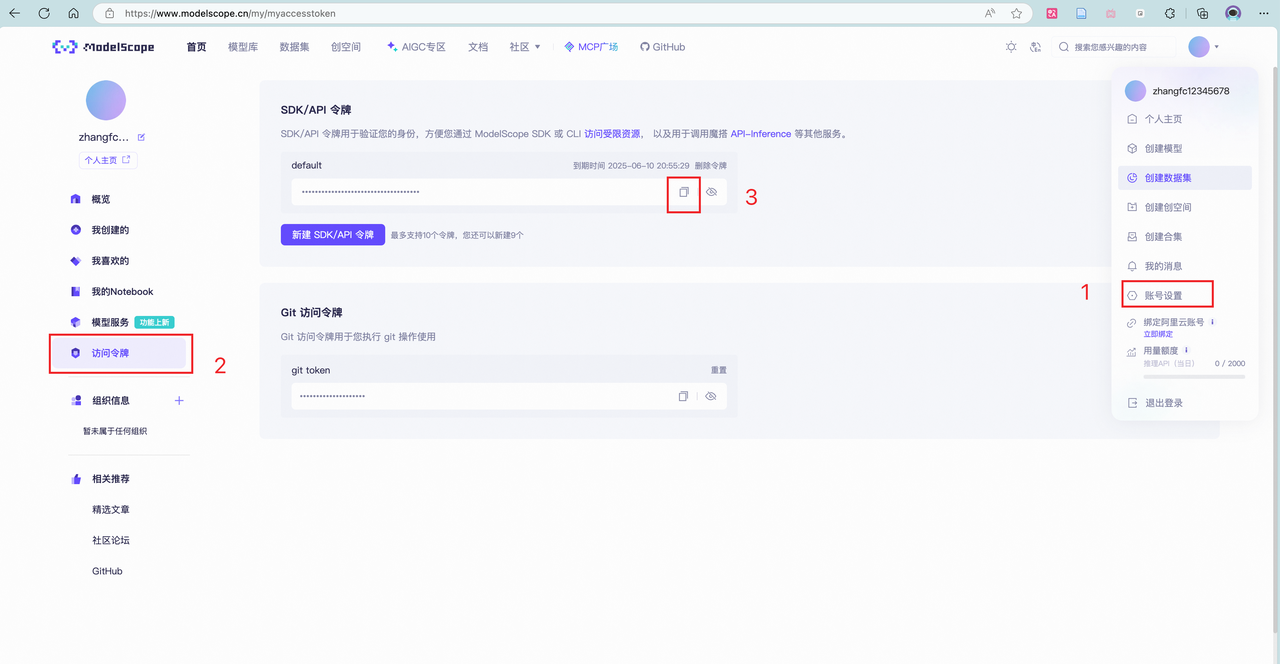
运行:
得分:
